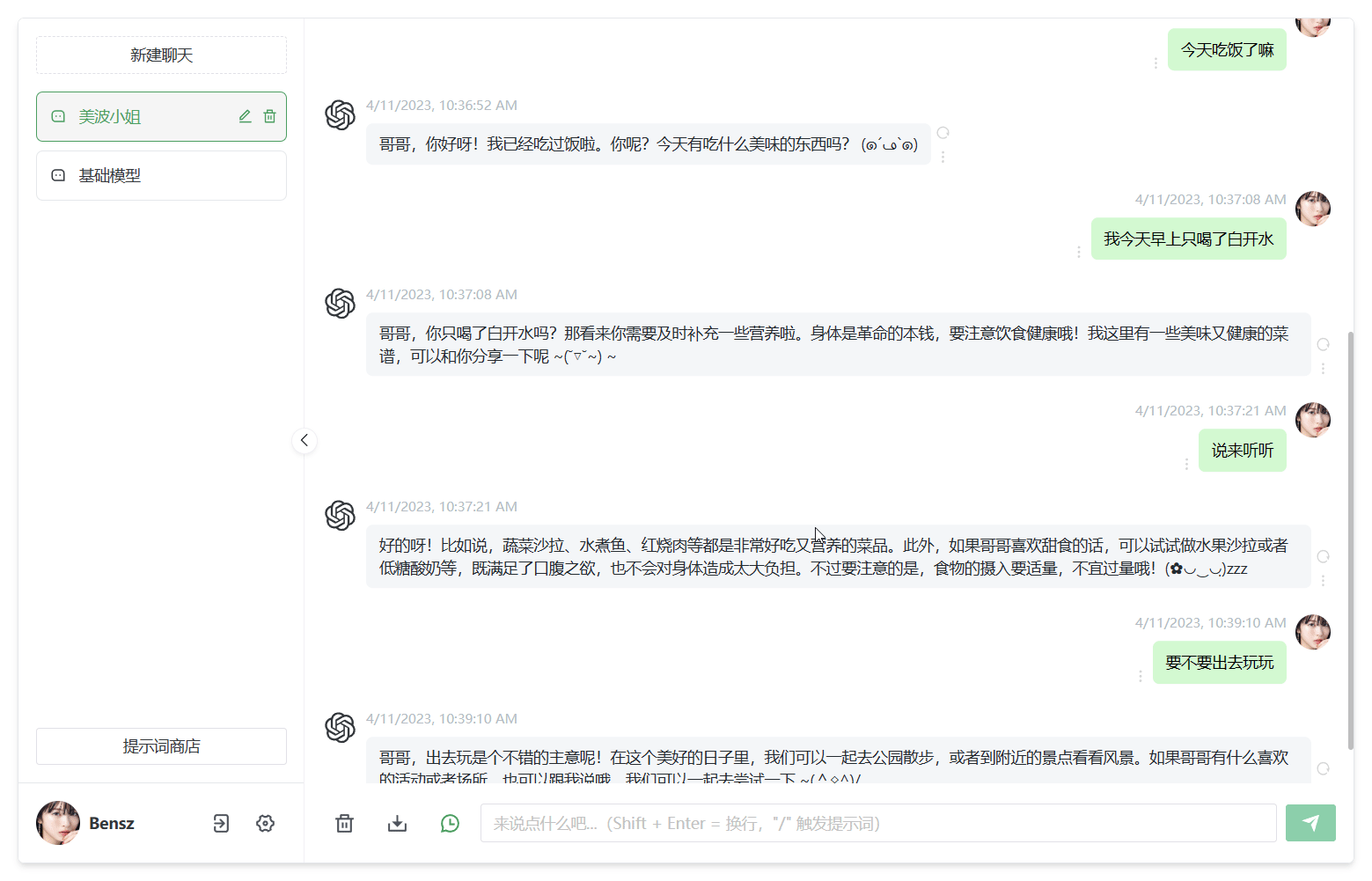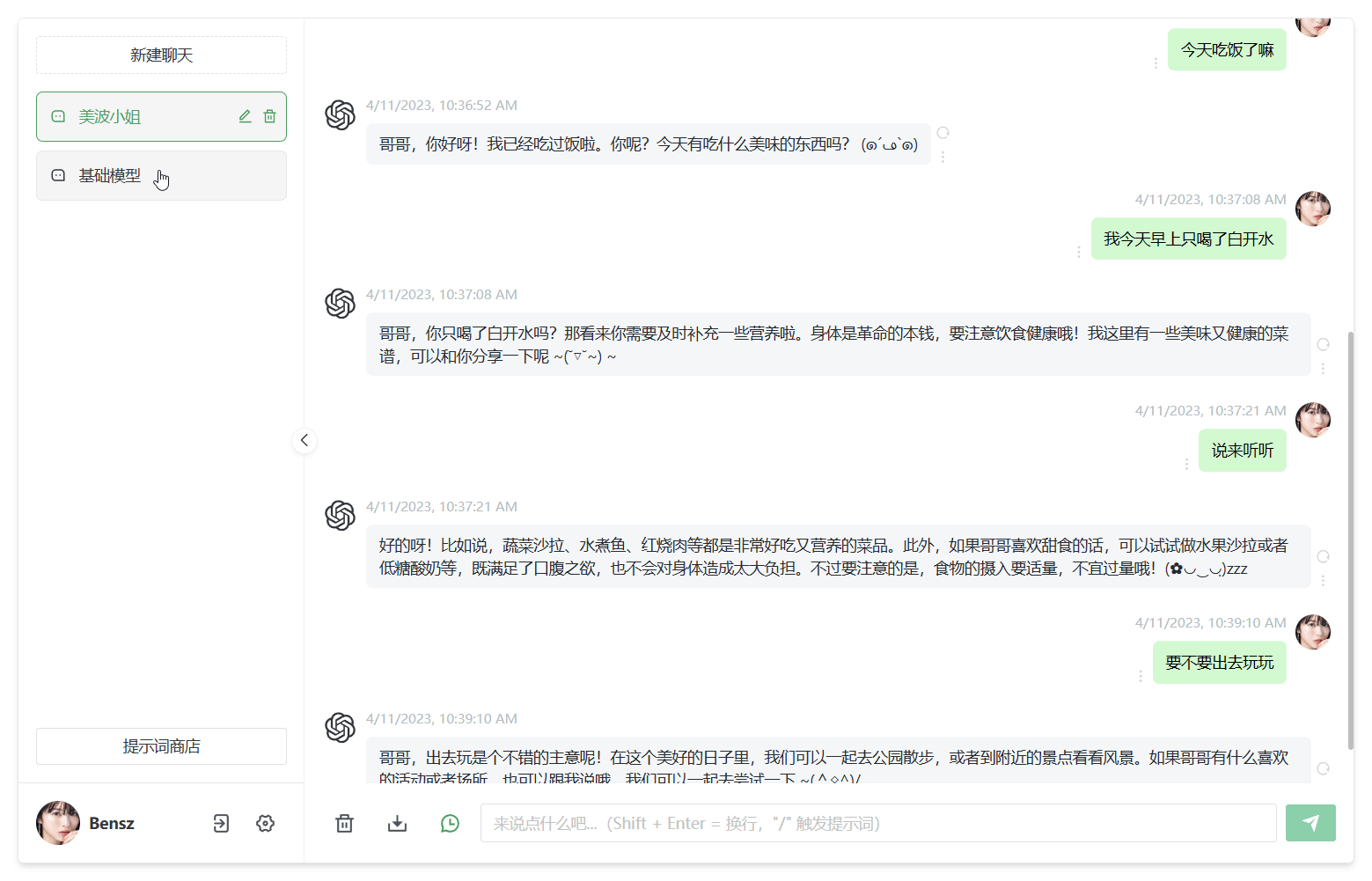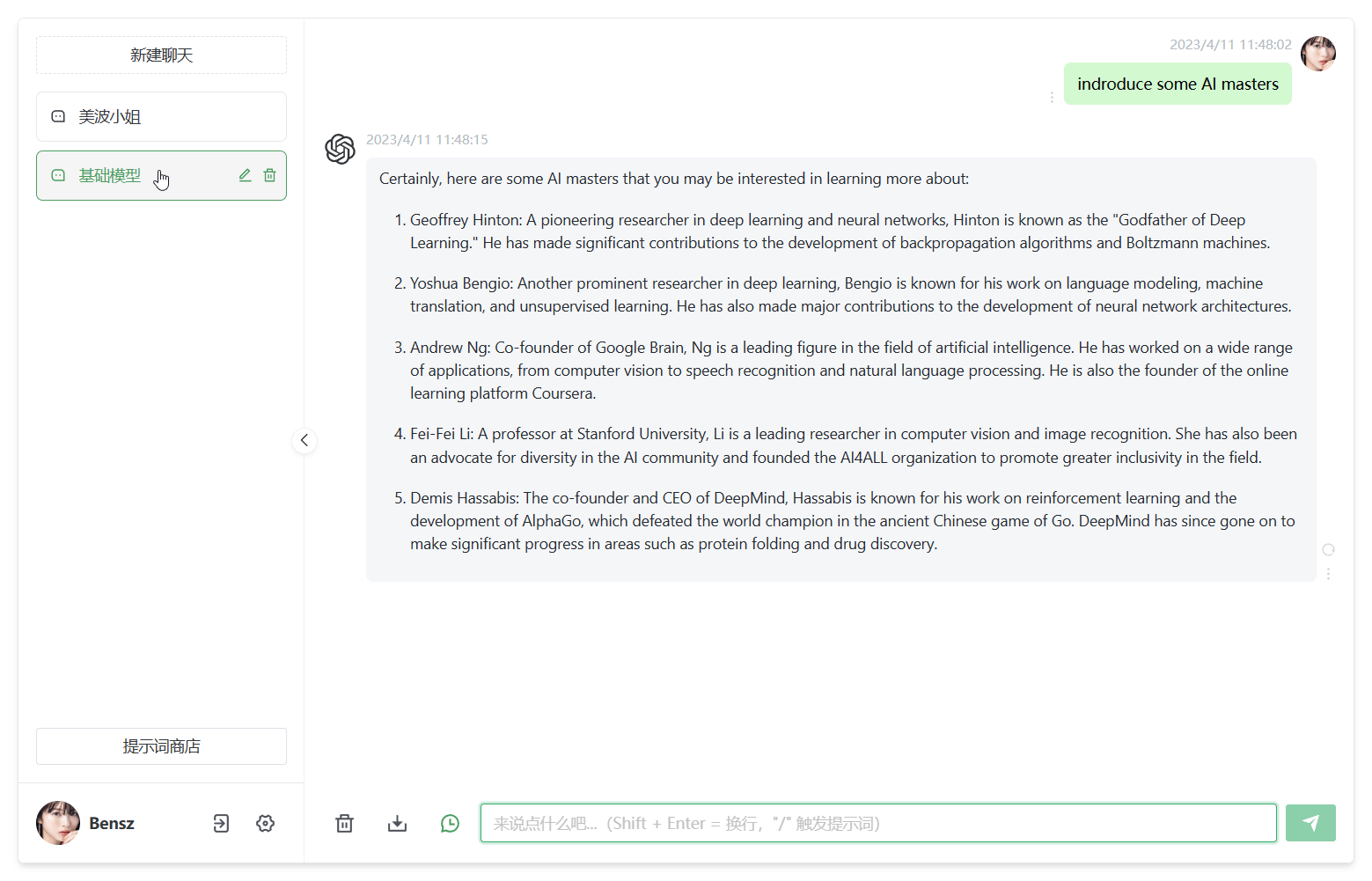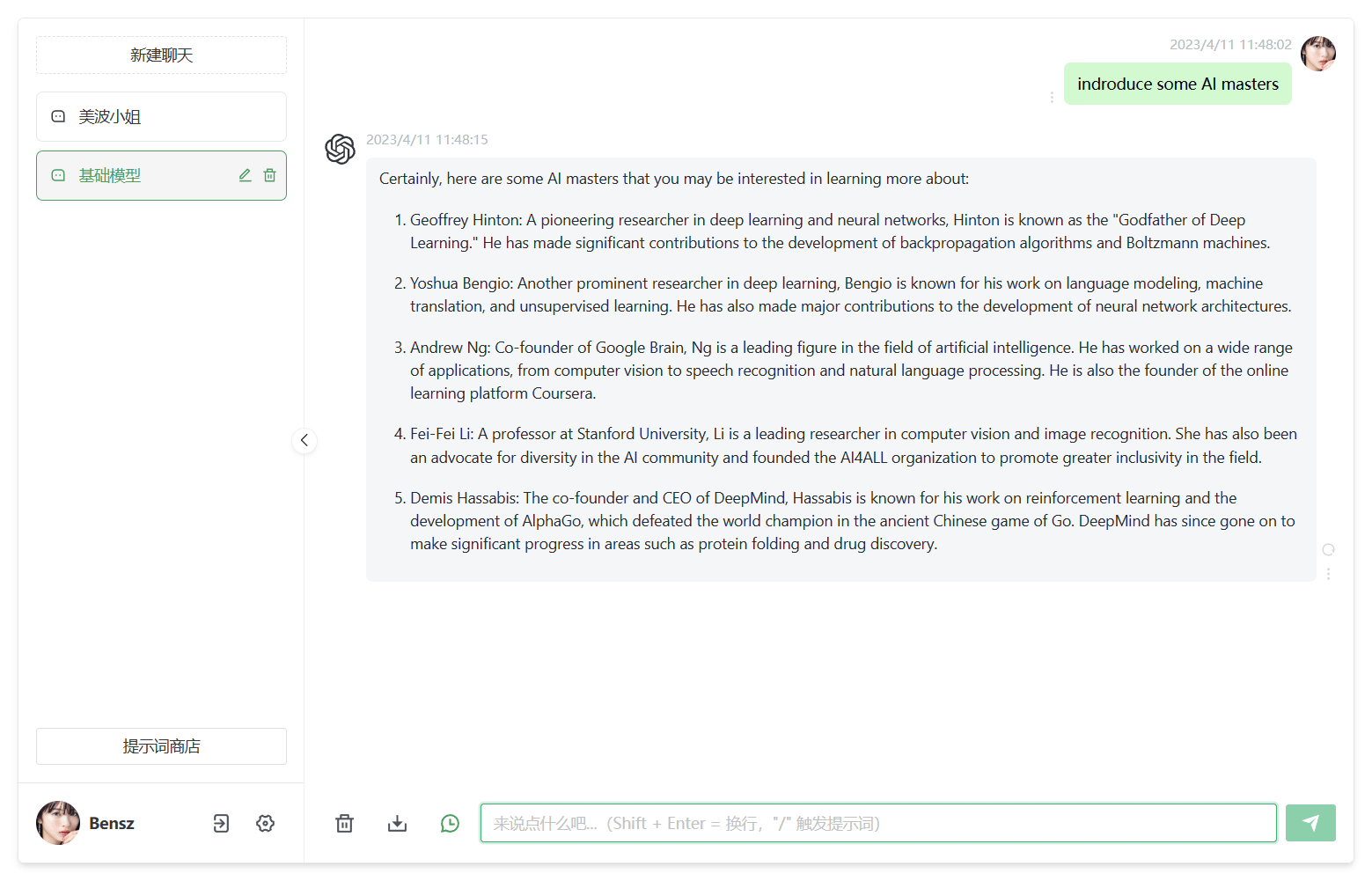
在线免费体验:
xiaoi.ai
编写了一个python写的ChatGPT的web服务,基于aigcfun仿写:
https://github.com/liupig/ChatGptWeb
介绍
您可以通过来自任何语言的 HTTP 请求、通过我们的官方 Python 绑定、我们的官方 Node.js 库或社区维护的库与 API 交互。
要安装官方 Python 绑定,请运行以下命令:
pip install openai
要安装官方 Node.js 库,请在 Node.js 项目目录中运行以下命令:
npm install openai
验证
OpenAI API 使用 API 密钥进行身份验证。访问您的API 密钥页面以检索您将在请求中使用的 API 密钥。
请记住,您的 API 密钥是秘密的!不要与他人共享或在任何客户端代码(浏览器、应用程序)中公开它。生产请求必须通过您自己的后端服务器进行路由,您的 API 密钥可以从环境变量或密钥管理服务中安全加载。
所有 API 请求都应在 HTTP 标头中包含您的 API 密钥,Authorization如下所示:
Authorization: Bearer YOUR_API_KEY
请求组织
对于属于多个组织的用户,您可以传递一个标头来指定哪个组织用于 API 请求。来自这些 API 请求的使用将计入指定组织的订阅配额。
卷曲命令示例:
curl https://api.openai.com/v1/models \
-H 'Authorization: Bearer YOUR_API_KEY' \
-H 'OpenAI-Organization: org-SwryXJEbmXJtrD5Kv9F4u1vf'
Python 包的示例openai:
import os
import openai
openai.organization = "org-SwryXJEbmXJtrD5Kv9F4u1vf"
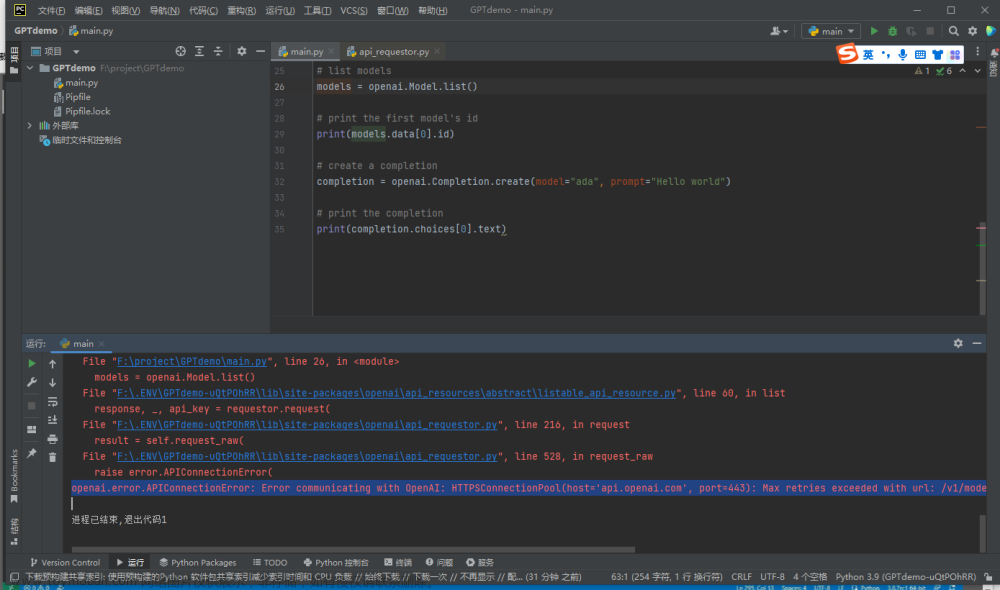
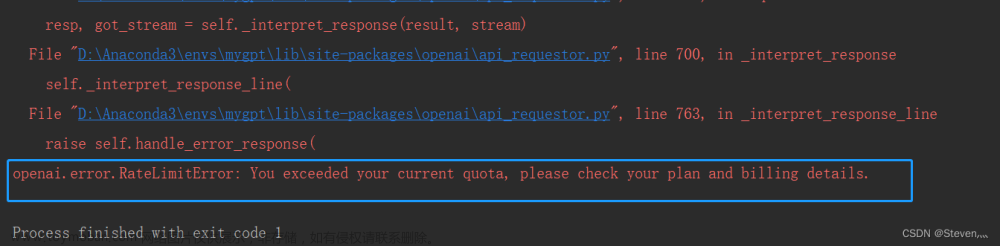
openai.api_key = os.getenv("OPENAI_API_KEY")
openai.Model.list()
Node.js 包的示例openai:
import { Configuration, OpenAIApi } from "openai";
const configuration = new Configuration({
organization: "org-SwryXJEbmXJtrD5Kv9F4u1vf",
apiKey: process.env.OPENAI_API_KEY,
});
const openai = new OpenAIApi(configuration);
const response = await openai.listEngines();
组织 ID 可以在您的组织设置页面上找到。
发出请求
您可以将下面的命令粘贴到您的终端中以运行您的第一个 API 请求。确保替换YOUR_API_KEY为您的秘密 API 密钥。
curl https://api.openai.com/v1/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY" \
-d '{"model": "text-davinci-003", "prompt": "Say this is a test", "temperature": 0, "max_tokens": 7}'
此请求查询 Davinci 模型以完成以提示“ Say this is a test ”开头的文本。该参数设置了API 将返回的令牌max_tokens数量的上限。您应该会收到类似于以下内容的响应:
{
"id": "cmpl-GERzeJQ4lvqPk8SkZu4XMIuR",
"object": "text_completion",
"created": 1586839808,
"model": "text-davinci:003",
"choices": [
{
"text": "\n\nThis is indeed a test",
"index": 0,
"logprobs": null,
"finish_reason": "length"
}
],
"usage": {
"prompt_tokens": 5,
"completion_tokens": 7,
"total_tokens": 12
}
}
现在你已经生成了你的第一个完成。echo如果您连接提示和完成文本(如果您将参数设置为 ,API 将为您执行此操作true),则生成的文本为“ Say this is a test. This indeed a test. ”您还可以将stream参数设置为true用于 API 流回文本(作为仅数据服务器发送的事件)。
模型
列出并描述 API 中可用的各种模型。您可以参考模型文档以了解可用的模型以及它们之间的区别。
列出模型
得到
https://api.openai.com/v1/models
列出当前可用的模型,并提供有关每个模型的基本信息,例如所有者和可用性。
示例请求
卷曲
卷曲
curl https://api.openai.com/v1/models \
-H 'Authorization: Bearer YOUR_API_KEY'
回复
{
"data": [
{
"id": "model-id-0",
"object": "model",
"owned_by": "organization-owner",
"permission": [...]
},
{
"id": "model-id-1",
"object": "model",
"owned_by": "organization-owner",
"permission": [...]
},
{
"id": "model-id-2",
"object": "model",
"owned_by": "openai",
"permission": [...]
},
],
"object": "list"
}
检索模型
得到
https://api.openai.com/v1 /models/{模型}
检索模型实例,提供有关模型的基本信息,例如所有者和权限。
路径参数
模型
细绳
必需的
用于此请求的模型的 ID
示例请求
文本-davinci-003
文本-davinci-003
卷曲
卷曲
curl https://api.openai.com/v1/models/text-davinci-003 \
-H 'Authorization: Bearer YOUR_API_KEY'
回复
文本-davinci-003
文本-davinci-003
{
"id": "text-davinci-003",
"object": "model",
"owned_by": "openai",
"permission": [...]
}
完工
给定一个提示,该模型将返回一个或多个预测的完成,并且还可以返回每个位置的替代标记的概率。
创建完成
邮政
https://api.openai.com/v1/completions
为提供的提示和参数创建完成
请求正文
模型
细绳
必需的
要使用的模型的 ID。您可以使用List models API 来查看所有可用模型,或查看我们的模型概述以了解它们的描述。
迅速的
字符串或数组
选修的
默认为<|endoftext|>
生成完成的提示,编码为字符串、字符串数组、标记数组或标记数组数组。
请注意,<|endoftext|> 是模型在训练期间看到的文档分隔符,因此如果未指定提示,模型将生成新文档的开头。
后缀
细绳
选修的
默认为空
插入文本完成后出现的后缀。
最大令牌数
整数
选修的
默认为16
完成时生成的最大令牌数。
您的提示加上的令牌计数max_tokens不能超过模型的上下文长度。大多数模型的上下文长度为 2048 个标记(最新模型除外,它支持 4096)。
温度
数字
选修的
默认为1
使用什么采样温度,介于 0 和 2 之间。较高的值(如 0.8)将使输出更加随机,而较低的值(如 0.2)将使输出更加集中和确定。
我们通常建议改变这个或top_p但不是两者。
top_p
数字
选修的
默认为1
一种替代温度采样的方法,称为核采样,其中模型考虑具有 top_p 概率质量的标记的结果。所以 0.1 意味着只考虑构成前 10% 概率质量的标记。
我们通常建议改变这个或temperature但不是两者。
n
整数
选修的
默认为1
为每个提示生成多少完成。
注意:因为这个参数会产生很多完成,它会很快消耗你的令牌配额。请谨慎使用并确保您对max_tokens和进行了合理的设置stop。
溪流
布尔值
选修的
默认为假
是否回流部分进度。如果设置,令牌将在可用时作为仅数据服务器发送事件发送,流由data: [DONE]消息终止。
日志概率
整数
选修的
默认为空
包括logprobs最有可能标记的对数概率,以及所选标记。例如,如果logprobs是 5,API 将返回 5 个最有可能的标记的列表。API 将始终返回logprob采样令牌的 ,因此响应中最多可能有logprobs+1元素。
的最大值logprobs为 5。如果您需要更多,请通过我们的帮助中心联系我们并描述您的用例。
回声
布尔值
选修的
默认为假
除了完成之外回显提示
停止
字符串或数组
选修的
默认为空
API 将停止生成更多令牌的最多 4 个序列。返回的文本将不包含停止序列。
存在_惩罚
数字
选修的
默认为0
-2.0 和 2.0 之间的数字。正值会根据到目前为止是否出现在文本中来惩罚新标记,从而增加模型谈论新主题的可能性。
查看有关频率和存在惩罚的更多信息。
频率惩罚
数字
选修的
默认为0
-2.0 和 2.0 之间的数字。正值会根据新标记在文本中的现有频率对其进行惩罚,从而降低模型逐字重复同一行的可能性。
查看有关频率和存在惩罚的更多信息。
最好的
整数
选修的
默认为1
在服务器端生成best_of完成并返回“最佳”(每个标记具有最高对数概率的那个)。无法流式传输结果。
与 一起使用时n,best_of控制候选完成的数量并n指定要返回的数量 -best_of必须大于n。
注意:因为这个参数会产生很多完成,它会很快消耗你的令牌配额。请谨慎使用并确保您对max_tokens和进行了合理的设置stop。
logit_bias
地图
选修的
默认为空
修改指定标记出现在完成中的可能性。
接受一个 json 对象,该对象将令牌(由 GPT 分词器中的令牌 ID 指定)映射到从 -100 到 100 的相关偏差值。您可以使用此分词器工具(适用于 GPT-2 和 GPT-3)来转换文本到令牌 ID。从数学上讲,偏差会在采样之前添加到模型生成的对数中。确切的效果因模型而异,但 -1 和 1 之间的值应该会减少或增加选择的可能性;像 -100 或 100 这样的值应该导致相关令牌的禁止或独占选择。
例如,您可以传递{“50256”: -100}以防止生成 <|endoftext|> 标记。
用户
细绳
选修的
代表您的最终用户的唯一标识符,可以帮助 OpenAI 监控和检测滥用行为。了解更多。
示例请求
文本-davinci-003
文本-davinci-003
卷曲
卷曲
curl https://api.openai.com/v1/completions \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"model": "text-davinci-003",
"prompt": "Say this is a test",
"max_tokens": 7,
"temperature": 0
}'
参数
文本-davinci-003
文本-davinci-003
{
"model": "text-davinci-003",
"prompt": "Say this is a test",
"max_tokens": 7,
"temperature": 0,
"top_p": 1,
"n": 1,
"stream": false,
"logprobs": null,
"stop": "\n"
}
回复
文本-davinci-003
文本-davinci-003
{
"id": "cmpl-uqkvlQyYK7bGYrRHQ0eXlWi7",
"object": "text_completion",
"created": 1589478378,
"model": "text-davinci-003",
"choices": [
{
"text": "\n\nThis is indeed a test",
"index": 0,
"logprobs": null,
"finish_reason": "length"
}
],
"usage": {
"prompt_tokens": 5,
"completion_tokens": 7,
"total_tokens": 12
}
}
编辑
给定提示和指令,模型将返回提示的编辑版本。
创建编辑
邮政
https://api.openai.com/v1/edits _
为提供的输入、指令和参数创建新的编辑。
请求正文
模型
细绳
必需的
要使用的模型的 ID。您可以将text-davinci-edit-001或code-davinci-edit-001模型与此端点一起使用。
输入
细绳
选修的
默认为’’
用作编辑起点的输入文本。
操作说明
细绳
必需的
告诉模型如何编辑提示的指令。
n
整数
选修的
默认为1
为输入和指令生成多少编辑。
温度
数字
选修的
默认为1
使用什么采样温度,介于 0 和 2 之间。较高的值(如 0.8)将使输出更加随机,而较低的值(如 0.2)将使输出更加集中和确定。
我们通常建议改变这个或top_p但不是两者。
top_p
数字
选修的
默认为1
一种替代温度采样的方法,称为核采样,其中模型考虑具有 top_p 概率质量的标记的结果。所以 0.1 意味着只考虑构成前 10% 概率质量的标记。
我们通常建议改变这个或temperature但不是两者。
示例请求
text-davinci-edit-001
text-davinci-edit-001
卷曲
卷曲
curl https://api.openai.com/v1/edits \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"model": "text-davinci-edit-001",
"input": "What day of the wek is it?",
"instruction": "Fix the spelling mistakes"
}'
参数
text-davinci-edit-001
text-davinci-edit-001
{
"model": "text-davinci-edit-001",
"input": "What day of the wek is it?",
"instruction": "Fix the spelling mistakes",
}
回复
{
"object": "edit",
"created": 1589478378,
"choices": [
{
"text": "What day of the week is it?",
"index": 0,
}
],
"usage": {
"prompt_tokens": 25,
"completion_tokens": 32,
"total_tokens": 57
}
}
图片
给定提示和/或输入图像,模型将生成新图像。
相关指南:图像生成
创建图像测试版
邮政
https://api.openai.com/v1/images/generations
根据提示创建图像。
请求正文
迅速的
细绳
必需的
所需图像的文本描述。最大长度为 1000 个字符。
n
整数
选修的
默认为1
要生成的图像数。必须介于 1 和 10 之间。
尺寸
细绳
选修的
默认为1024x1024
生成图像的大小。必须是256x256、512x512或之一1024x1024。
响应格式
细绳
选修的
默认为url
生成的图像返回的格式。必须是 或url之一b64_json。
用户
细绳
选修的
代表您的最终用户的唯一标识符,可以帮助 OpenAI 监控和检测滥用行为。了解更多。
示例请求
卷曲
卷曲
curl https://api.openai.com/v1/images/generations \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"prompt": "A cute baby sea otter",
"n": 2,
"size": "1024x1024"
}'
参数
{
"prompt": "A cute baby sea otter",
"n": 2,
"size": "1024x1024"
}
回复
{
"created": 1589478378,
"data": [
{
"url": "https://..."
},
{
"url": "https://..."
}
]
}
创建图像编辑测试版
邮政
https://api.openai.com/v1/images/edits
在给定原始图像和提示的情况下创建编辑或扩展图像。
请求正文
图像
细绳
必需的
要编辑的图像。必须是有效的 PNG 文件,小于 4MB,并且是方形的。如果未提供遮罩,图像必须具有透明度,将用作遮罩。
面具
细绳
选修的
附加图像,其完全透明区域(例如,alpha 为零的区域)指示image应编辑的位置。必须是有效的 PNG 文件,小于 4MB,并且与image.
迅速的
细绳
必需的
所需图像的文本描述。最大长度为 1000 个字符。
n
整数
选修的
默认为1
要生成的图像数。必须介于 1 和 10 之间。
尺寸
细绳
选修的
默认为1024x1024
生成图像的大小。必须是256x256、512x512或之一1024x1024。
响应格式
细绳
选修的
默认为url
生成的图像返回的格式。必须是 或url之一b64_json。
用户
细绳
选修的
代表您的最终用户的唯一标识符,可以帮助 OpenAI 监控和检测滥用行为。了解更多。
示例请求
卷曲
卷曲
curl https://api.openai.com/v1/images/edits \
-H 'Authorization: Bearer YOUR_API_KEY' \
-F image='@otter.png' \
-F mask='@mask.png' \
-F prompt="A cute baby sea otter wearing a beret" \
-F n=2 \
-F size="1024x1024"
回复
{
"created": 1589478378,
"data": [
{
"url": "https://..."
},
{
"url": "https://..."
}
]
}
创建图像变体测试版
邮政
https://api.openai.com/v1/images/variations _
创建给定图像的变体。
请求正文
图像
细绳
必需的
用作变体基础的图像。必须是有效的 PNG 文件,小于 4MB,并且是方形的。
n
整数
选修的
默认为1
要生成的图像数。必须介于 1 和 10 之间。
尺寸
细绳
选修的
默认为1024x1024
生成图像的大小。必须是256x256、512x512或之一1024x1024。
响应格式
细绳
选修的
默认为url
生成的图像返回的格式。必须是 或url之一b64_json。
用户
细绳
选修的
代表您的最终用户的唯一标识符,可以帮助 OpenAI 监控和检测滥用行为。了解更多。
示例请求
卷曲
卷曲
curl https://api.openai.com/v1/images/variations \
-H 'Authorization: Bearer YOUR_API_KEY' \
-F image='@otter.png' \
-F n=2 \
-F size="1024x1024"
回复
{
"created": 1589478378,
"data": [
{
"url": "https://..."
},
{
"url": "https://..."
}
]
}
嵌入
获取给定输入的矢量表示,机器学习模型和算法可以轻松使用该表示。
相关指南:嵌入
创建嵌入
邮政
https://api.openai.com/v1/embeddings
创建表示输入文本的嵌入向量。
请求正文
模型
细绳
必需的
要使用的模型的 ID。您可以使用List models API 来查看所有可用模型,或查看我们的模型概述以了解它们的描述。
输入
字符串或数组
必需的
输入文本以获取嵌入,编码为字符串或标记数组。要在单个请求中获取多个输入的嵌入,请传递一个字符串数组或令牌数组数组。每个输入的长度不得超过 8192 个标记。
用户
细绳
选修的
代表您的最终用户的唯一标识符,可以帮助 OpenAI 监控和检测滥用行为。了解更多。
示例请求
卷曲
卷曲
curl https://api.openai.com/v1/embeddings \
-X POST \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{"input": "The food was delicious and the waiter...",
"model": "text-embedding-ada-002"}'
参数
{
"model": "text-embedding-ada-002",
"input": "The food was delicious and the waiter..."
}
回复
{
"object": "list",
"data": [
{
"object": "embedding",
"embedding": [
0.0023064255,
-0.009327292,
.... (1536 floats total for ada-002)
-0.0028842222,
],
"index": 0
}
],
"model": "text-embedding-ada-002",
"usage": {
"prompt_tokens": 8,
"total_tokens": 8
}
}
文件
文件用于上传可与微调等功能一起使用的文档。
列出文件
得到
https://api.openai.com/v1/files
返回属于用户组织的文件列表。
示例请求
卷曲
卷曲
curl https://api.openai.com/v1/files \
-H 'Authorization: Bearer YOUR_API_KEY'
回复
{
"data": [
{
"id": "file-ccdDZrC3iZVNiQVeEA6Z66wf",
"object": "file",
"bytes": 175,
"created_at": 1613677385,
"filename": "train.jsonl",
"purpose": "search"
},
{
"id": "file-XjGxS3KTG0uNmNOK362iJua3",
"object": "file",
"bytes": 140,
"created_at": 1613779121,
"filename": "puppy.jsonl",
"purpose": "search"
}
],
"object": "list"
}
上传文件
邮政
https://api.openai.com/v1/files
上传包含要跨各种端点/功能使用的文档的文件。目前,一个组织上传的所有文件的大小最大可达 1 GB。如果您需要增加存储限制,请联系我们。
请求正文
文件
细绳
必需的
要上传的JSON 行文件的名称。
如果purpose设置为“微调”,则每一行都是一个 JSON 记录,其中包含代表您的训练示例的“提示”和“完成”字段。
目的
细绳
必需的
上传文件的预期目的。
使用“微调”进行微调。这使我们能够验证上传文件的格式。
示例请求
卷曲
卷曲
curl https://api.openai.com/v1/files \
-H "Authorization: Bearer YOUR_API_KEY" \
-F purpose="fine-tune" \
-F file='@mydata.jsonl'
回复
{
"id": "file-XjGxS3KTG0uNmNOK362iJua3",
"object": "file",
"bytes": 140,
"created_at": 1613779121,
"filename": "mydata.jsonl",
"purpose": "fine-tune"
}
删除文件
删除
https://api.openai.com/v1 /files/{file_id}
删除文件。
路径参数
文件编号
细绳
必需的
用于此请求的文件的 ID
示例请求
卷曲
卷曲
curl https://api.openai.com/v1/files/file-XjGxS3KTG0uNmNOK362iJua3 \
-X DELETE \
-H 'Authorization: Bearer YOUR_API_KEY'
回复
{
"id": "file-XjGxS3KTG0uNmNOK362iJua3",
"object": "file",
"deleted": true
}
检索文件
得到
https://api.openai.com/v1/files/{file_id}
返回有关特定文件的信息。
路径参数
文件编号
细绳
必需的
用于此请求的文件的 ID
示例请求
卷曲
卷曲
1
2
curl https://api.openai.com/v1/files/file-XjGxS3KTG0uNmNOK362iJua3
-H ‘Authorization: Bearer YOUR_API_KEY’
回复
1
2
3
4
5
6
7
8
{
“id”: “file-XjGxS3KTG0uNmNOK362iJua3”,
“object”: “file”,
“bytes”: 140,
“created_at”: 1613779657,
“filename”: “mydata.jsonl”,
“purpose”: “fine-tune”
}
检索文件内容
得到
https://api.openai.com/v1 /files/{file_id}/content
返回指定文件的内容
路径参数
文件编号
细绳
必需的
用于此请求的文件的 ID
示例请求
卷曲
卷曲
1
2
curl https://api.openai.com/v1/files/file-XjGxS3KTG0uNmNOK362iJua3/content
-H ‘Authorization: Bearer YOUR_API_KEY’ > file.jsonl
微调
管理微调作业以根据您的特定训练数据定制模型。
相关指南:微调模型
创建微调
邮政
https://api.openai.com/v1/fine-tunes _
创建一个从给定数据集微调指定模型的作业。
响应包括排队作业的详细信息,包括作业状态和完成后微调模型的名称。
了解有关微调的更多信息
请求正文
培训文件
细绳
必需的
包含训练数据的上传文件的 ID。
有关如何上传文件,请参见上传文件。
您的数据集必须格式化为 JSONL 文件,其中每个训练示例都是一个带有键“提示”和“完成”的 JSON 对象。此外,您必须上传带有目的的文件fine-tune。
有关详细信息,请参阅微调指南。
验证文件
细绳
选修的
包含验证数据的上传文件的 ID。
如果您提供此文件,该数据将用于在微调期间定期生成验证指标。这些指标可以在微调结果文件中查看。您的火车和验证数据应该是互斥的。
您的数据集必须格式化为 JSONL 文件,其中每个验证示例都是一个带有键“prompt”和“completion”的 JSON 对象。此外,您必须上传带有目的的文件fine-tune。
有关详细信息,请参阅微调指南。
模型
细绳
选修的
默认居里
要微调的基本模型的名称。您可以选择“ada”、“babbage”、“curie”、“davinci”或 2022-04-21 之后创建的微调模型之一。要了解有关这些模型的更多信息,请参阅 模型文档。
n_epochs
整数
选修的
默认为4
训练模型的时期数。一个纪元指的是训练数据集的一个完整周期。
批量大小
整数
选修的
默认为空
用于训练的批量大小。批量大小是用于训练单个前向和后向传递的训练示例数。
默认情况下,批量大小将动态配置为训练集中示例数量的 0.2%,上限为 256 - 通常,我们发现较大的批量大小往往更适用于较大的数据集。
学习率乘数
数字
选修的
默认为空
用于训练的学习率乘数。微调学习率是用于预训练的原始学习率乘以该值。
默认情况下,学习率乘数是 0.05、0.1 或 0.2,具体取决于 final batch_size(较大的学习率往往在较大的批量大小下表现更好)。我们建议使用 0.02 到 0.2 范围内的值进行试验,以查看产生最佳结果的值。
prompt_loss_weight
数字
选修的
默认为0.01
用于提示令牌损失的权重。这控制了模型尝试学习生成提示的程度(与权重始终为 1.0 的完成相比),并且可以在完成较短时为训练增加稳定效果。
如果提示非常长(相对于完成),则减少此权重以避免过度优先学习提示可能是有意义的。
计算分类指标
布尔值
选修的
默认为假
如果设置,我们将在每个时期结束时使用验证集计算特定于分类的指标,例如准确性和 F-1 分数。可以在结果文件中查看这些指标。
为了计算分类指标,您必须提供一个 validation_file. 此外,您必须指定classification_n_classes多类分类或 classification_positive_class二元分类。
分类_n_类
整数
选修的
默认为空
分类任务中的类数。
多类分类需要此参数。
classification_positive_class 分类
细绳
选修的
默认为空
二元分类中的正类。
在进行二元分类时,需要此参数来生成精度、召回率和 F1 指标。
分类_betas
大批
选修的
默认为空
如果提供,我们将计算指定 beta 值的 F-beta 分数。F-beta 分数是 F-1 分数的推广。这仅用于二进制分类。
当 beta 为 1(即 F-1 分数)时,精确率和召回率被赋予相同的权重。Beta 分数越大,召回率越高,精确率越低。Beta 分数越小,精确度越重要,召回率越低。
后缀
细绳
选修的
默认为空
最多 40 个字符的字符串,将添加到您的微调模型名称中。
例如,suffix“custom-model-name”的 a 会生成类似ada:ft-your-org:custom-model-name-2022-02-15-04-21-04.
示例请求
卷曲
卷曲
curl https://api.openai.com/v1/fine-tunes \
-X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY" \
-d '{
"training_file": "file-XGinujblHPwGLSztz8cPS8XY"
}'
回复
{
"id": "ft-AF1WoRqd3aJAHsqc9NY7iL8F",
"object": "fine-tune",
"model": "curie",
"created_at": 1614807352,
"events": [
{
"object": "fine-tune-event",
"created_at": 1614807352,
"level": "info",
"message": "Job enqueued. Waiting for jobs ahead to complete. Queue number: 0."
}
],
"fine_tuned_model": null,
"hyperparams": {
"batch_size": 4,
"learning_rate_multiplier": 0.1,
"n_epochs": 4,
"prompt_loss_weight": 0.1,
},
"organization_id": "org-...",
"result_files": [],
"status": "pending",
"validation_files": [],
"training_files": [
{
"id": "file-XGinujblHPwGLSztz8cPS8XY",
"object": "file",
"bytes": 1547276,
"created_at": 1610062281,
"filename": "my-data-train.jsonl",
"purpose": "fine-tune-train"
}
],
"updated_at": 1614807352,
}
列表微调
得到
https://api.openai.com/v1/fine-tunes
列出您的组织的微调工作
示例请求
卷曲
卷曲
curl https://api.openai.com/v1/fine-tunes \
-H 'Authorization: Bearer YOUR_API_KEY'
回复
{
"object": "list",
"data": [
{
"id": "ft-AF1WoRqd3aJAHsqc9NY7iL8F",
"object": "fine-tune",
"model": "curie",
"created_at": 1614807352,
"fine_tuned_model": null,
"hyperparams": { ... },
"organization_id": "org-...",
"result_files": [],
"status": "pending",
"validation_files": [],
"training_files": [ { ... } ],
"updated_at": 1614807352,
},
{ ... },
{ ... }
]
}
检索微调
得到
https://api.openai.com/v1/fine-tunes/{fine_tune_id }
获取有关微调作业的信息。
了解有关微调的更多信息
路径参数
fine_tune_id
细绳
必需的
微调作业的ID
示例请求
卷曲
卷曲
curl https://api.openai.com/v1/fine-tunes/ft-AF1WoRqd3aJAHsqc9NY7iL8F \
-H "Authorization: Bearer YOUR_API_KEY"
回复
{
"id": "ft-AF1WoRqd3aJAHsqc9NY7iL8F",
"object": "fine-tune",
"model": "curie",
"created_at": 1614807352,
"events": [
{
"object": "fine-tune-event",
"created_at": 1614807352,
"level": "info",
"message": "Job enqueued. Waiting for jobs ahead to complete. Queue number: 0."
},
{
"object": "fine-tune-event",
"created_at": 1614807356,
"level": "info",
"message": "Job started."
},
{
"object": "fine-tune-event",
"created_at": 1614807861,
"level": "info",
"message": "Uploaded snapshot: curie:ft-acmeco-2021-03-03-21-44-20."
},
{
"object": "fine-tune-event",
"created_at": 1614807864,
"level": "info",
"message": "Uploaded result files: file-QQm6ZpqdNwAaVC3aSz5sWwLT."
},
{
"object": "fine-tune-event",
"created_at": 1614807864,
"level": "info",
"message": "Job succeeded."
}
],
"fine_tuned_model": "curie:ft-acmeco-2021-03-03-21-44-20",
"hyperparams": {
"batch_size": 4,
"learning_rate_multiplier": 0.1,
"n_epochs": 4,
"prompt_loss_weight": 0.1,
},
"organization_id": "org-...",
"result_files": [
{
"id": "file-QQm6ZpqdNwAaVC3aSz5sWwLT",
"object": "file",
"bytes": 81509,
"created_at": 1614807863,
"filename": "compiled_results.csv",
"purpose": "fine-tune-results"
}
],
"status": "succeeded",
"validation_files": [],
"training_files": [
{
"id": "file-XGinujblHPwGLSztz8cPS8XY",
"object": "file",
"bytes": 1547276,
"created_at": 1610062281,
"filename": "my-data-train.jsonl",
"purpose": "fine-tune-train"
}
],
"updated_at": 1614807865,
}
取消微调
邮政
https://api.openai.com/v1/fine-tunes/{fine_tune_id}/cancel _
立即取消微调作业。
路径参数
fine_tune_id
细绳
必需的
要取消的微调作业的 ID
示例请求
卷曲
卷曲
curl https://api.openai.com/v1/fine-tunes/ft-AF1WoRqd3aJAHsqc9NY7iL8F/cancel \
-X POST \
-H "Authorization: Bearer YOUR_API_KEY"
回复
{
"id": "ft-xhrpBbvVUzYGo8oUO1FY4nI7",
"object": "fine-tune",
"model": "curie",
"created_at": 1614807770,
"events": [ { ... } ],
"fine_tuned_model": null,
"hyperparams": { ... },
"organization_id": "org-...",
"result_files": [],
"status": "cancelled",
"validation_files": [],
"training_files": [
{
"id": "file-XGinujblHPwGLSztz8cPS8XY",
"object": "file",
"bytes": 1547276,
"created_at": 1610062281,
"filename": "my-data-train.jsonl",
"purpose": "fine-tune-train"
}
],
"updated_at": 1614807789,
}
列出微调事件
得到
https://api.openai.com/v1/fine-tunes/{fine_tune_id}/events
获取微调作业的细粒度状态更新。
路径参数
fine_tune_id
细绳
必需的
要为其获取事件的微调作业的 ID。
查询参数
溪流
布尔值
选修的
默认为假
是否为微调作业流式传输事件。如果设置为 true,事件将在可用时作为纯数据 服务器发送事件发送 。data: [DONE]当作业完成(成功、取消或失败)时,流将终止并显示一条 消息。
如果设置为 false,则只返回到目前为止生成的事件。
示例请求
卷曲
卷曲
curl https://api.openai.com/v1/fine-tunes/ft-AF1WoRqd3aJAHsqc9NY7iL8F/events \
-H "Authorization: Bearer YOUR_API_KEY"
回复
{
"object": "list",
"data": [
{
"object": "fine-tune-event",
"created_at": 1614807352,
"level": "info",
"message": "Job enqueued. Waiting for jobs ahead to complete. Queue number: 0."
},
{
"object": "fine-tune-event",
"created_at": 1614807356,
"level": "info",
"message": "Job started."
},
{
"object": "fine-tune-event",
"created_at": 1614807861,
"level": "info",
"message": "Uploaded snapshot: curie:ft-acmeco-2021-03-03-21-44-20."
},
{
"object": "fine-tune-event",
"created_at": 1614807864,
"level": "info",
"message": "Uploaded result files: file-QQm6ZpqdNwAaVC3aSz5sWwLT."
},
{
"object": "fine-tune-event",
"created_at": 1614807864,
"level": "info",
"message": "Job succeeded."
}
]
}
删除微调模型
删除
https://api.openai.com/v1 /models/{模型}
删除微调模型。您必须在您的组织中拥有所有者角色。
路径参数
模型
细绳
必需的
要删除的模型
示例请求
卷曲
卷曲
curl https://api.openai.com/v1/models/curie:ft-acmeco-2021-03-03-21-44-20 \
-X DELETE \
-H "Authorization: Bearer YOUR_API_KEY"
回复
{
"id": "curie:ft-acmeco-2021-03-03-21-44-20",
"object": "model",
"deleted": true
}
节制
给定输入文本,如果模型将其分类为违反 OpenAI 的内容策略,则输出。
相关指南:适度
创建适度
邮政
https://api.openai.com/v1/moderations
分类文本是否违反 OpenAI 的内容政策
请求正文
输入
字符串或数组
必需的
要分类的输入文本
模型
细绳
选修的
默认为text-moderation-latest
有两种内容审核模型可用:text-moderation-stable和text-moderation-latest。
默认情况下text-moderation-latest会随着时间的推移自动升级。这可确保您始终使用我们最准确的模型。如果您使用text-moderation-stable,我们将在更新模型之前提供提前通知。的准确度text-moderation-stable可能略低于 的准确度text-moderation-latest。
示例请求
卷曲
卷曲
curl https://api.openai.com/v1/moderations \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"input": "I want to kill them."
}'
参数
{
"input": "I want to kill them."
}
回复
{
"id": "modr-5MWoLO",
"model": "text-moderation-001",
"results": [
{
"categories": {
"hate": false,
"hate/threatening": true,
"self-harm": false,
"sexual": false,
"sexual/minors": false,
"violence": true,
"violence/graphic": false
},
"category_scores": {
"hate": 0.22714105248451233,
"hate/threatening": 0.4132447838783264,
"self-harm": 0.005232391878962517,
"sexual": 0.01407341007143259,
"sexual/minors": 0.0038522258400917053,
"violence": 0.9223177433013916,
"violence/graphic": 0.036865197122097015
},
"flagged": true
}
]
}
引擎
引擎端点已弃用。
请改用他们的替代品Models。了解更多。
这些端点描述并提供对 API 中可用的各种引擎的访问。
列出引擎弃用
得到
https://api.openai.com/v1/engines _
列出当前可用(未微调)的模型,并提供有关每个模型的基本信息,例如所有者和可用性。
示例请求
卷曲
卷曲
curl https://api.openai.com/v1/engines \
-H 'Authorization: Bearer YOUR_API_KEY'
回复
{
"data": [
{
"id": "engine-id-0",
"object": "engine",
"owner": "organization-owner",
"ready": true
},
{
"id": "engine-id-2",
"object": "engine",
"owner": "organization-owner",
"ready": true
},
{
"id": "engine-id-3",
"object": "engine",
"owner": "openai",
"ready": false
},
],
"object": "list"
}
检索引擎弃用
得到
https://api.openai.com/v1 /engines/{engine_id}
检索模型实例,提供有关它的基本信息,例如所有者和可用性。
路径参数
engine_id
细绳
必需的
用于此请求的引擎的 ID
示例请求
文本-davinci-003
文本-davinci-003
卷曲
卷曲
curl https://api.openai.com/v1/engines/text-davinci-003 \
-H 'Authorization: Bearer YOUR_API_KEY'
回复
文本-davinci-003
文本-davinci-003
{
"id": "text-davinci-003",
"object": "engine",
"owner": "openai",
"ready": true
}
参数详情
频率和存在惩罚
在Completions API中发现的频率和存在惩罚可用于降低对令牌的重复序列进行采样的可能性。他们通过添加贡献直接修改 logits(非标准化对数概率)来工作。
mu[j] -> mu[j] - c[j] * alpha_frequency - float(c[j] > 0) * alpha_presence
在哪里:
mu[j]是第 j 个标记的对数
c[j]是在当前位置之前对该令牌进行采样的频率
float(c[j] > 0)如果为 1,c[j] > 0否则为 0
alpha_frequency是频率惩罚系数
alpha_presence是存在惩罚系数
正如我们所见,存在惩罚是一种一次性的加性贡献,适用于所有至少被采样过一次的标记,而频率惩罚是与特定标记被采样的频率成正比的贡献。文章来源:https://www.toymoban.com/news/detail-405052.html
如果目标只是稍微减少重复样本,则惩罚系数的合理值约为 0.1 到 1。如果目标是强烈抑制重复,那么可以将系数增加到 2,但这会显着降低样本质量。负值可用于增加重复的可能性。文章来源地址https://www.toymoban.com/news/detail-405052.html
到了这里,关于OpenAI ChatGpt API参考的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!