文章目录
- 安装VMware虚拟机
- 下载Ubuntu 18.04镜像,并在VMware中新建虚拟机
- 安装VMware tools
- 搭建Hadoop伪分布式
1、安装VMware虚拟机
1.安装VMware Workstation 14 Pro版本
2、下载Ubuntu 18.04镜像,并在VMware中新建虚拟机
2.1 在VMware上方菜单栏,文件--新建虚拟机

2.2 默认

2.3 选择稍后安装操作系统

2.4 选择Linux(L),版本 Ubuntu

2.5 定义虚拟机的名称,选择虚拟机的位置,本人选择放在了D盘

2.6 处理器配置根据自己情况自己选择,这里选择了处理器数量2,内核数量2

2.7 虚拟机内存设为2048 MB

2.8 默认

2.9 默认

2.10 默认

2.11 选择创建新虚拟磁盘

2.12 磁盘容量设为40G

然后一直下一步 创建完成
2.13 编辑虚拟机设置

2.14 在CD/DVD(SATAT)--连接--使用ISO映像文件,选择Ubuntu18.04的镜像文件的路径,点击确定,启动虚拟机,进行Ubuntu18.04的安装,一直选择默认的就能安装成功。

3、安装VMware Tools
3.1 打开Ubuntu系统,在VMware菜单栏里点击虚拟机选项,找到安装VMware tools选项,点击,本人已安装成功,显示重新安装

3.2 然后进入系统,在右边任务栏中找到DVD图标,打开后找到VMware Tools压缩文件,并将其复制到桌面
3.3 点击左侧文件,主文件夹--桌面,单机右键打开终端,可使用命令解压
tar -zxvf VMwareTools-10.2.5-8068393.tar.gz3.4 进入解压完成的文件夹:cd vmware-tools-distrib

3.5 执行文件夹下的可执行文件,命令:sudo ./vmware-install.pl
第一个[no]输入yes,后面的都按Entre,有Yes输入tes,就安装成功
3.6 安装成功,虚拟机窗口为自动适应
4、Hadoop伪分布式搭建
4.1 单击右键,打开命令终端
4.2 创建新用户,首先切换为root用户,添加新用户hadoop
su root
注:若提示“su: Authentication failure”,原因应该是没有设置root账户的密码
参考:(5条消息) su 报错su: Authentication failure_逐鹿艾缇的博客-CSDN博客
adduser hadoop
4.3 由于部门权限规定或安全限制,负责部署hadoop的管理员没有linux root权限,但按照最佳做法,安装时有一些操作需要以root用户身份执行。以下给予该用户root权限:
sudo adduser hadoop sudo
执行visudo命令,修改该文件,在“root ALL=(ALL:ALL) ALL”这一行下面加入一行:
hadoop ALL=(ALL:ALL) ALL
visudo
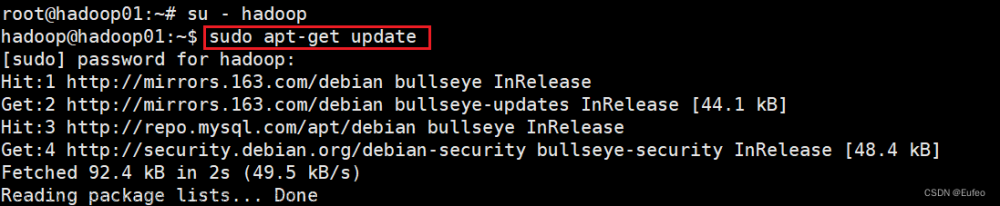
4.4 更新命令
sudo apt-get update
sudo apt-get upgrade
4.5 部分linux系统会自带vim编辑器,但若在终端无法启动该编辑器,则需要安装以待后续编辑配置文件,接下来跳出的提示回复Y即可:
sudo apt-get install vim
4.6 配置SSH
4.6.1 下载SSH,安装SSH server
根据Hadoop分布式系统的特性,在任务计划分发、心跳监测、任务管理、多租户管理等功能上,需要通过SSH(Secure Shell)进行通讯,所以必须安装配置SSH。另因为Hadoop没有提供SSH输入密码登录的形式,因此需要将所有机器配置为NameNode可以无密码登录的状态。
sudo apt-get install openssh-server
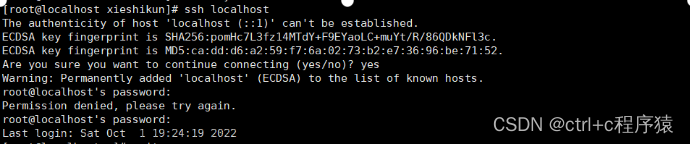
4.6.2 连接本地SSH
ssh localhost
4.7 设置无密码登录
4.7.1 进行无密码登录的设置,首先先退出刚刚ssh localhost的连接:
exit
4.7.2 进入SSH对应目录下,该目录包含了几乎所有当前用户SSH配置认证相关的文件:
cd ~/.ssh/
4.7.3 输入生成SSH私钥与公钥的命令,-t用于声明密钥的加密类型,输入Hadoop密码。这一步会提醒设置SSH密码,输入密码时直接回车就表示无密码,第二次输入密码回车确定,最后一次提交:
ssh-keygen -t rsa4.7.4 将生成的SSH的公钥加入目标机器的SSH目录下,这里采用cat命令与>>,cat file1>>file2的含义为将file1内容append到file2中。
cat ./id_rsa.pub >> ./authorized_keys4.8 在虚拟机中安装JDK
4.8.1 下载对应版本的JDK,解压到指定目录下,将文件名换成对应的即可
sudo tar -zxvf jdk-8u212-linux-x64.tar.gz -C /usr/local/jdk1.84.8.2 配置环境变量
1.通过vim编辑器打开环境变量的设置文件:
sudo vim ~/.bashrc2.首先到达文件尾部,按o字母在当前行的下一行添加以下语句:
export JAVA_HOME=/usr/local/jdk1.8
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
3.按Esc键退出,然后输入:wq保存修改。然后使环境变量生效:
source ~/.bashrc4.9 下载编译好的hadoop
4.9.1 下载hadoop-2.9.2.tar.gz 云盘链接:https://pan.baidu.com/s/1U_Yo4c4xRXh3djIAXkXhJA
提取码:d3nv
4.9.2 在VMware中与电脑进行共享文件
参考链接:(5条消息) 如何在VMWare的Ubuntu虚拟机中设置共享文件夹_Vincent3016的博客-CSDN博客
4.9.3 进入解压包存放的文件夹,右键属性查看压缩包的绝对路径,然后解压至/usr/local目录下:
sudo tar -zxf /home/wangyu/share/hadoop-2.9.2.tar.gz -C /usr/local4.9.4 进入刚刚解压后存放的目录下:
cd /usr/local/
4.9.5 将该文件夹的名字重命名为hadoop,屏蔽掉版本号的信息,使得后续命令行输入更为简便:
sudo mv ./hadoop-2.9.2/ ./hadoop
4.10 配置hadoop的环境
4.10.1 将已重命名的该文件夹的拥有者,指定给用户hadoop,缺少这一步,将导致后续操作特别是运行Hadoop时,反复因权限不足而停止:
sudo chmod 777 -R /usr/local/hadoop
R:对目前目录下的所有档案与子目录进行相同的权限变更(即以递回的方式逐个变更)
777:高权限(读、写、执行)
4.10.2 hadoop实际运行时仍会出现找不到java-jdk的现象,故再对hadoop的环境文件进行修改,进入目录:
cd ./hadoop/etc/hadoop4.10.3 使用vim编辑器,打开环境变量文件:
sudo vim ~/.bashrc
4.10.4 按字母o在当前行的下一行添加该语句:
#HADOOP VARIABLES START
export HADOOP_INSTALL=/usr/local/hadoop
export PATH=$PATH:$HADOOP_INSTALL/bin
export PATH=$PATH:$HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_HOME=$HADOOP_INSTALL
export HADOOP_HDFS_HOME=$HADOOP_INSTALL
export YARN_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib"
#HADOOP VARIABLES END
4.10.5 按Esc键退出,然后输入:wq保存修改。然后使环境变量生效:
source ~/.bashrc
4.10.6 hadoop框架已经搭建好了,可以通过调用版本号进行测试hadoop是否可用,正确搭建应该能看到hadoop的版本号等信息:
cd /usr/local/hadoop
./bin/hadoop version4.11 配置文件
1. 打开hadoop文件夹下的hadoop文件中,配置hadoop-env.sh
sudo vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
添加如下代码
# The java implementation to use.
export JAVA_HOME=/usr/local/jdk1.8
export HADOOP=/usr/local/hadoop
export PATH=$PATH:/usr/local/hadoop/bin
2.先打开 core-site.xml文件,将<configuration>替换为以下内容
sudo vim /usr/local/hadoop/etc/hadoop/core-site.xml<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>3.打开hdfs-site.xml文件:hdfs-site.xml进行同样的替换操作
sudo vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
5. 打开yarn-env.sh,配置yarn-env.sh文件,添加以下代码
sudo vim /usr/local/hadoop/etc/hadoop/yarn-env.sh
# export JAVA_HOME
JAVA_HOME=/usr/local/jdk1.8
6.配置yarn-site.xml,将<configuration>替换为以下内容
sudo vim /usr/local/hadoop/etc/hadoop/yarn-site.xml<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>127.0.0.1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>127.0.0.1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>127.0.0.1:8031</value>
</property>
</configuration>4.12 启动HDFS伪分布式模式
1. 格式化namenode
hdfs namenode -format
显示信息内若包含以下内容successfully formatted,则说明成功格式化:

2.启动hdfs
start-all.sh3.显示进程
jps有6个进程表示正确:

4.打开浏览器,输入http://localhost:50070/,若打不开网址,把localhost换成本机ip地址

输入http://localhost:8088/,显示

文章来源地址https://www.toymoban.com/news/detail-405803.html文章来源:https://www.toymoban.com/news/detail-405803.html
到了这里,关于Hadoop伪分布式安装搭建教程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!