CNN代表卷积神经网络(Convolutional Neural Network)
它是一种深度学习算法,特别适用于处理图像和视频数据。CNN由多个卷积层、池化层和全连接层组成,通过学习图像或视频数据的特征来进行分类、识别或检测任务。与传统的全连接神经网络相比,CNN的参数数量较少,能够提取更多的空间特征,因此在图像处理和计算机视觉领域表现出色。CNN已经被广泛应用于图像分类、目标检测、人脸识别、自然语言处理等各种领域。【先局部,再整体】
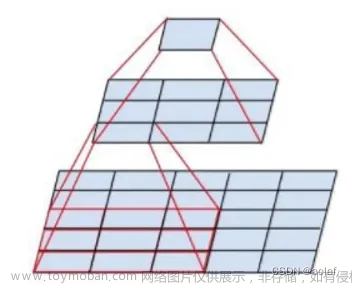
卷积层:二维离散卷积操作。卷积层是神经网络中常用的一种层,主要应用于图像处理和语音识别等领域。卷积层通过将输入数据与卷积核进行卷积运算来提取特征。卷积层可以有效地减少网络中的参数数量,并且具有平移不变性,可以在输入图像发生平移时保持对特征的识别能力。
卷积层的卷积核通常是一个小的矩阵,该矩阵可以在输入数据上滑动,与输入数据的每个局部区域进行卷积运算。卷积运算可以将每个局部区域转换为一个新的特征,这些特征可以被用于下一层的处理。
卷积层通常包括多个卷积核,每个卷积核可以提取不同的特征。卷积层还可以包括池化层,用于对特征图进行降采样,以减少网络的参数数量。
卷积层的应用范围非常广泛,包括图像分类、目标检测、语音识别、自然语言处理等领域。在计算机视觉领域,卷积神经网络(CNN)通常是最先被使用的神经网络类型之一,而卷积层是CNN中最为重要的组成部分之一。
可以有多层卷积5:40该视频思路
卷积后会加入激活函数ReLu()

全连接层:全连接层是神经网络中最基本的一种层。在全连接层中,每个输入神经元都与下一层中的所有神经元相连。这意味着每个输入神经元都会对下一层中的所有神经元产生影响。
在全连接层中,每个输入神经元与下一层中的每个神经元都有一个权重。这些权重控制着输入神经元对下一层神经元的影响。全连接层通常会在网络的最后一层使用,以将网络的输出映射到目标输出。
全连接层可以用于分类、回归、文本处理、图像处理等任务中。但是,全连接层的参数数量随着输入神经元的增加而增加,这会导致网络变得更加复杂和难以训练。因此,在一些应用中,全连接层被其他类型的层所取代,如卷积层、循环神经网络等。

池化层pooling:在深度学习神经网络中,池化层(Pooling Layer)是一种常用的层类型之一,它通常会被用在卷积神经网络(Convolutional Neural Networks,CNN)的后面。
池化层的作用是对输入的特征图进行下采样,从而减少特征图的维度,降低模型的计算复杂度,同时也可以在一定程度上防止过拟合。
常见的池化操作包括最大池化(Max Pooling)、平均池化(Average Pooling)等。最大池化会在输入的特征图上滑动一个固定大小的窗口,然后输出窗口内的最大值作为下采样后的结果。而平均池化则输出窗口内的平均值作为下采样后的结果。
池化层可以在卷积神经网络中使用多次,每次池化都可以将特征图的维度减半,从而逐渐降低模型的计算复杂度。
在机器学习中,过拟合(Overfitting)指的是一个模型在训练集上表现良好,但在测试集上表现较差的情况。简单来说,过拟合是指模型过于复杂,过分关注训练集中的细节和噪声,导致其在测试集上的泛化能力不足。
过拟合的主要原因是模型的复杂度过高,模型可以轻松地记住训练集中的每一个样本和其对应的标签,但是对于新的数据却无法进行准确的预测。过拟合还可能发生在训练数据量过小的情况下,因为训练数据集太小,模型无法充分学习数据的规律,而是过分关注训练集中的个别样本。
解决过拟合的方法有多种,其中一些常用的方法包括:
- 增加训练数据集的大小,让模型可以更好地学习数据的规律,减少过度关注噪声和个别样本的情况。
- 降低模型的复杂度,比如减少神经网络的层数、神经元的数量,或者使用正则化方法对模型参数进行约束。
- 使用 Dropout 技术,随机地丢弃一部分神经元,从而避免过度依赖某些特征。
- 提前停止训练,即在模型在测试集上的表现不再提高时停止训练,避免过度拟合。



经典的卷积神经网络包括:
LeNet-5: 是最早被广泛使用的卷积神经网络之一,由Yann LeCun在1998年提出。该网络主要用于手写数字识别任务。
AlexNet: 是2012年ImageNet比赛的冠军,由Alex Krizhevsky等人提出。该网络的特点是引入了ReLU激活函数和Dropout正则化方法,使得网络更加稳定和快速收敛。
VGGNet: 由Karen Simonyan和Andrew Zisserman在2014年提出,其主要特点是采用多个小尺寸的卷积核来代替大尺寸的卷积核,从而增加网络深度。该网络在ImageNet比赛中获得了较好的成绩。
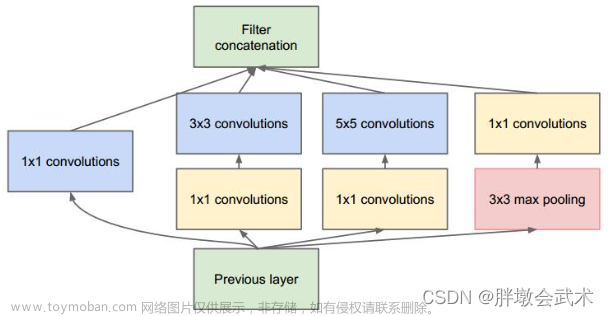
GoogLeNet: 也称为Inception,由Google团队在2014年提出。该网络的主要特点是采用了Inception模块,即将不同尺寸的卷积核和池化核串联起来,并且使用了辅助分类器来缓解梯度消失问题。
ResNet: 由Kaiming He等人在2015年提出,其主要特点是通过残差连接来解决深度神经网络中的梯度消失和过拟合问题。该网络在ImageNet比赛中取得了很好的成绩,并被广泛应用于各种计算机视觉任务。
怎么用pytorch进行基于深度神经网络的图像聚类?
图像聚类是一种无监督学习的任务,可以使用基于深度神经网络的方法进行处理。以下是使用 PyTorch 进行基于深度神经网络的图像聚类的一般步骤:
- 准备数据集。收集适当的图像数据集,可以使用 PyTorch 的数据集类(如
torch.utils.data.Dataset)将数据集加载为 PyTorch 张量格式。 - 加载预训练模型。使用 PyTorch 加载已训练好的深度学习模型,如 VGG、ResNet 或 AlexNet 等。可以使用 PyTorch 提供的
torchvision.models模块中的预训练模型类,或者从其他来源获取预训练模型。 - 提取特征向量。使用预训练模型提取图像的特征向量。可以通过对预训练模型的最后一个卷积层的输出进行平均或池化操作,将每张图像映射为一个固定长度的特征向量。
- 进行聚类。使用聚类算法(如 K-Means 或层次聚类)对特征向量进行聚类,将图像分为多个不同的簇。可以使用 PyTorch 提供的聚类算法类(如
torch.cluster)或其他开源库进行聚类操作。 - 可视化聚类结果。对于聚类结果,可以使用图像处理库(如 PIL 或 OpenCV)将每个簇中的图像可视化,以便进行分析和评估。
需要注意的是,这只是一个基本的流程,具体实现可能涉及到许多细节问题,如模型选择、参数调整、聚类算法的选择和调整等。可以参考 PyTorch 的官方文档和相关教程,以及其他开源项目进行学习和实践。
使用 PyTorch 进行深度学习通常需要遵循以下步骤:
- 安装 PyTorch。可以通过 pip 或者 Anaconda 进行安装,具体方法可以参考 PyTorch 官网提供的安装指南。
- 导入 PyTorch 库。在 Python 代码中,可以使用 import 语句导入 PyTorch 库。
- 构建数据集。使用 PyTorch 的数据集类(如
torch.utils.data.Dataset)构建训练集和测试集。这通常涉及到读取数据、将数据转换为 PyTorch 的张量格式等操作。 - 定义模型。使用 PyTorch 的模型类(如
torch.nn.Module)定义深度学习模型。这通常涉及到定义模型的各个层、参数和激活函数等。 - 定义损失函数。使用 PyTorch 的损失函数类(如
torch.nn.MSELoss)定义模型的损失函数。 - 定义优化器。使用 PyTorch 的优化器类(如
torch.optim.SGD)定义模型的优化器,用于更新模型参数。 - 训练模型。使用 PyTorch 的训练循环,将训练集中的数据输入模型,计算损失函数并进行优化。训练循环通常涉及到迭代、前向传播、反向传播等操作。
- 测试模型。使用测试集中的数据评估模型的性能。可以使用 PyTorch 提供的评估函数(如
torch.nn.functional.softmax)计算模型的输出,并与实际标签进行比较。 - 调整模型。根据测试结果,调整模型的超参数、损失函数或优化器等,重新训练模型。
- 应用模型。将训练好的模型应用到实际数据中,进行预测或分类等任务。
以上是 PyTorch 进行深度学习的一般步骤,具体实现会根据具体问题和数据集的不同而有所差异。可以参考 PyTorch 官方文档和相关教程进行学习和实践。
推荐一个最适合做基于深度神经网络的图像聚类的数据集?
对于基于深度神经网络的图像聚类,建议使用CIFAR-10数据集进行训练和测试。CIFAR-10是一个非常流行的数据集,包含10个类别的60000张32x32彩色图像。**每个类别有6000张图像,其中50000张用于训练,10000张用于测试。**这个数据集非常适合图像聚类,因为它具有一定的难度,可以测试深度神经网络的性能,并且它也具有足够的图像样本以便学习到不同的特征和类别。另外,CIFAR-10数据集是公开可用的,并且在许多深度学习框架中都有预先加载的实现,因此非常方便使用。
pytorch有哪些模型
PyTorch是一个流行的深度学习框架,它支持许多预训练模型和自定义模型。以下是一些常用的PyTorch模型:
- 卷积神经网络(CNN)模型:PyTorch支持各种经典和现代的CNN模型,例如LeNet、AlexNet、VGG、ResNet、Inception等等。
- 循环神经网络(RNN)模型:PyTorch支持各种类型的RNN,例如简单的循环神经网络(Simple RNN)、长短时记忆网络(LSTM)和门控循环单元(GRU)等。
- 转移学习模型:PyTorch还支持从大规模预训练模型中进行迁移学习的模型,例如BERT、GPT-2和RoBERTa等。
- 生成式对抗网络(GAN)模型:PyTorch支持许多GAN模型,例如DCGAN、CycleGAN、StarGAN和Pix2Pix等。
- 目标检测和图像分割模型:PyTorch支持各种目标检测和图像分割模型,例如Faster R-CNN、Mask R-CNN、U-Net和DeepLab等。
- 强化学习模型:PyTorch还支持各种强化学习模型,例如Deep Q-Networks(DQN)、Actor-Critic、Proximal Policy Optimization(PPO)等。
以上是一些常用的PyTorch模型,但并不是全部,用户可以根据自己的需求,选择适合自己的模型。
卷积神经网络是一种深度学习模型,主要由卷积层、池化层、全连接层和激活函数等组成。以下是卷积神经网络模型的主要组成部分:
- 输入层:输入层接收原始的数据,例如图像数据。
- 卷积层:卷积层是卷积神经网络最核心的部分,它使用多个卷积核对输入的数据进行卷积运算,提取出数据中的特征信息。卷积层通常包括卷积核、步长和填充等参数。
- 激活函数层:激活函数层对卷积层的输出进行非线性变换,增加模型的非线性表达能力。常用的激活函数有ReLU、Sigmoid、Tanh等。
- 池化层:池化层用于对卷积层的输出进行下采样操作,降低模型的计算量,并提高模型的鲁棒性。
- 全连接层:全连接层将池化层的输出转换为模型的最终输出。全连接层的神经元与上一层的所有神经元都相连,因此需要较多的参数。
- Dropout层:Dropout层用于在训练过程中随机丢弃一部分神经元,以防止过拟合。
- Softmax层:Softmax层用于将模型的输出转化为概率分布,可以用于分类问题。
卷积神经网络模型的结构可以根据具体任务的要求进行设计,以上是卷积神经网络模型的基本组成部分。
图像聚类是将相似的图像分组到一起的过程,是图像分析和计算机视觉领域的一个重要问题。下面是快速入门图像聚类的步骤:文章来源:https://www.toymoban.com/news/detail-405904.html
- 数据准备:收集图像数据集并准备好数据,可以使用已有的公共数据集或者自己采集图像数据。确保数据集是干净的,并且有标签或文件名可以用来标识不同的图像。
- 特征提取:将每个图像转换为数字特征向量,以便可以对它们进行聚类。可以使用许多不同的方法来提取图像特征,如基于颜色、纹理、形状、边缘等特征进行提取。
- 特征归一化:对提取的特征向量进行标准化或归一化处理,以确保不同特征之间的尺度和权重的差异不会对聚类结果产生影响。
- 聚类算法选择:选择一个聚类算法来将图像分成不同的组。常见的聚类算法包括k-means、层次聚类、DBSCAN等。
- 聚类结果可视化:使用图形化方法来查看聚类结果,比如使用散点图或者热图将图像组织在不同的聚类中。
- 聚类性能评估:使用外部指标(如Purity、NMI、F1-Score等)或者内部指标(如SSE、DBI等)来评估聚类的性能。
- 聚类结果的分析和解释:分析聚类结果,检查哪些图像被分到了不同的聚类中,并解释每个聚类代表的意义。
以上是一个基本的图像聚类流程。建议在实践过程中尝试不同的特征提取方法和聚类算法,并使用不同的评估指标来选择最佳的方法。同时,也可以参考一些常见的深度学习图像聚类模型,如AutoEncoder、VAE、GAN等。文章来源地址https://www.toymoban.com/news/detail-405904.html
到了这里,关于关于CNN卷积神经网络的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!