前言
这学期学计算机网络,但是我感觉我们学校的某位任课老师讲的不太行,听完introduction部分以后,我决定脱离学校课程,直接按照408去学习,备战考研。
我购买了408推荐参考教材《计算机网络》,是谢希仁版本的第八版,网上对应的视频不是很多,我找到了方诗虹老师的课程,他用的书就是408的。虽然方老师的任职学校并不是很好,但是就我的经历来说,408本来就没什么特别深的东西,关键在于能不能讲好,经过我的调查,方老师评价还不错,所以我就直接来听她的课,搭配书籍食用。
本文是系列笔记中的第二篇,内容为概述、物理层、链路层
计算机网络笔记——概述、物理层、链路层(方老师408课程)
计算机网络笔记——网络层、传输层、应用层(方老师408课程)
[考研整理——还没写]
互联网概述
以前有三大网络,有电信网络,有线电视网络,计算机网络,现在三网合一了,计算机网络是现在这个年代里最有价值的技术,是将整个世界统合起来的关键技术,是信息的基础设施。
互联网的核心特点是连通性,资源共享,这也是他的核心价值。实现连通的基础无非就是两类设备:
- 节点:包括终端和传递设备。比如手机,电脑,路由器。
- 链路:节点之间的链接,包括有线和无线。
互联网发展的三个阶段
- 小型的区域互联,分组交换网,即ARPANET。
- 在这个时期的1983年,TCP/IP协议诞生,成为计算机网络的标准协议,延续到现在。
- 人们把TCP/IP协议标准指定的时间作为互联网的诞生时间。
- 三级结构互联网。
- 这个阶段还没有商业化,之所以叫校园网,是因为局域网主要还是校园里用,实际上就是局域网。
- 而局域网之间也并不是这种树状链接,实际上链接是错综复杂的。

- ISP(Internet Service Provider)商业运行时期。
- ISP提供接入互联网的服务,并收取一定费用。ISP一般是公家的,比如移动联通。
- ISP结构比较复杂,但是整体上仍然是层次结构。
- 单纯的层次结构可能会带来交换成本较大的缺陷,IXP(Internet eXchange Point)可以让地区ISP之间的交换不经过主干ISP,起到快捷通道的作用。
- 90年代,www万维网的出现,彻底标志着世界互联的开始。

互联网标准化机构
当互联网遍布全世界,就应该进行标准化了。领导机构是ISOC,其次是IAB,具体执行由两个部门去执行,一是IRTF(互联网研究部),一个是IETF(互联网工程部).
一个标准的指定也是非常麻烦的,需要公开发布草案(RFC,Request For Comments),收集反馈,验证,流程很复杂,所以最后能变成具体标准的草案很少。

互联网的组成
- 核心部分。互联网中负责链接通信的部分,主要由大量路由设备构成,是网络的网络。本质上,核心部分的功能就是“分组交换”
- 边缘部分。一般都是终端,就是我们使用的设备,这些设备接入互联网,只从核心部分收发数据,不会负责转发数据。
边缘部分的通信方式
两个计算机终端之间的通信,究其本质是一台主机的某个进程和另一台主机的某个进程通信。通信的方式由两种:
- CS(Client/Server):
- 众多的客户机与一个服务器对应,服务器被动等待客户机的请求,一旦有客户机主动发送一个请求,服务器就进行解析处理,做出响应,返回信息。
- 因为是一对多,所以服务器需要很强的软硬件设施。
- P2P(Peer to Peer):
- 本质上仍然是CS,但是没有固定的服务器,宏观上就是平等的。
- P2P程序是平等的地位,任何主机都可以发出请求,任何主机也可以提供服务。
核心部分的交换方式
最开始是电路交换,利用的是电话线。打电话的过程就是:
- 建立连接
- 独占链接,传输信息
- 断开连接
很明显,这种模式适合打电话,但是不适合传输网络信息。因为网络信息是不稳定的,可能两个人发微信,一天发不了几次,你要独占一天,是不是就很浪费?所以互联网就不能是独占的。
分组交换的分组指的是将bit分组,每一组前面打上标签用于区分,每一组就是一个包(packet)。

具体过程采用储存转发技术,路由器储存转发具体过程如下:
- 暂存收到的分组
- 检查分组头部
- 查找转发表(由路由器动态维护)
- 按照头部的目的地址,找到合适的接口转发出去
由此可见,每个包传输的路径都是不固定的,用户不关心你走哪个路由,反正最后能送到目的地就行。也正因此,两个包走同一条路是很正常的,这就和电路交换完全是两回事了。具体如何复用,大致有三种技术,后面会讲:
- 频分复用。不同包调频
- 时分复用。时间片轮转
- 统计复用
分组交换一定就好吗?整体是更好的,但是仍然有缺点。
- 排队延迟。储存转发,先储存再转发,如果排队太长,超过储存空间,新来的就会丢包。
- 不保证带宽。因为是共享的动态分配,所以谁用的多,谁用得少就难以确定(后面还有虚电路交换技术解决这个问题)
- 增加开销:比如一个包切得越细,头部信息占的比重就越大,这就是浪费。
报文交换介于电路交换和分组交换之间。可以理解为选定一条路径就发送n组,然后再选一条路径发送n组。
从电路交换,到报文交换,到分组交换,其实可以从流水线角度去理解。电路交换就是完全顺序,报文交换就是部分流水线化,分组交换就是彻底的流水线。
流水线虽然可以提高资源利用率,但是也会产生额外的损失,要根据情况来确定:
- 连续长时间大量信息,用电路交换
- 间断突发信息,用报文和分组交换
我国计算机网络的发展
中国计算机网络起步较晚,好在下一代网络的发展没有落后,在有一些领域还是领头的(比如5G网络)。
中国有5大ISP:
- 电信CHINA-NET。曾经是中国公用互联网,后来给了电信。虽然我们平时用电信的手机卡不多,但是在计算机网络大领域上,其出口带宽是最大的,是其他4个加起来的10倍。
- 联通UNI-NET。
- 移动CM-NET。
- 中国教育和科研计算机网CER-NET。顾名思义,China Education and Research,连接了中国各大学校,研究所。有一些内部资源只能通过这个网络接入获取。如果你是通过其他网络接入,资源获取就会受限。
- 中国科学技术网CST-NET。
计算机网络的类别

计算机网络按照作用范围,有如下类别:
- 个人区域网(PAN,Personal Area Network)。范围很小,大概10米,其实就是热点。
- 局域网(LAN,Local)。一公里左右,通常采用高速通信线路,比如一栋楼里面,一个学校里面。
- 城域网(MAN,Metropolitan)。一个城市
- 广域网(WAN,Wide)。很远,是互联网核心部分。若干广域网组成互联网
按照使用者分类:
- 公用网:按规定缴费的都可以使用
- 专用网:特定用途,比如校园网,公司网
用来把用于接入到网络的网络(AN,Access Network):
听起来有点奇怪,实际上居民是不太方便直接接入本地ISP的,需要一个路由器来中转。也就是说,AN是终端和互联网的桥梁。

计算机网络的性能
速率、带宽、吞吐量
香农的信息论里,bit是信息的基本单位。
速率=数据率=bit率,单位是bit/s。实际速率换算都用1000来换算:
- 如果是纯粹的K,M,G,比如数据量,数据的大小,那么其换算关系是 2 10 2^{10} 210
- 一旦带上/s这个速率的含义,比如数据率,传输速率,那么换算关系就是 1 0 3 10^3 103
区分一下速率、带宽、吞吐量
- 速率意如其名。通常是指额定速率,并非实际运行速率。
- 带宽是一个信道可以通过的理论数据率,单位也是bit/s。带宽实际上就是一种数据率,只不过可以人为控制。
- 吞吐量。就是实际带宽,其上限值为额定速率,受到很多因素影响,只低不高。
时延
从用户实际体验来看,用户更关心一个操作需要等待的时间延迟。严格来说,时延就是数据从网络的一端到另一端所需的时间。其组成成分很复杂:
- 发送时延:把所有数据发送出去到链路上需要的时间
- =数据帧长度/发送速率
- 传播时延:发送出去的数据在链路上传播需要经过的时间
- =信道长度/信号在信道上的传播速率
- 实际传播速率也就是2/3光速(因为光纤是要不断全反射的,实际路程更远)
- 排队时延:数据在路由器上储存转发过程中,排队等待处理消耗的时间
- 当网络通信量溢出排队队列时,即发生丢包现象,当100%丢包的时候,发出去什么东西都不会有回应,相当于排队的时延为无穷大。
- 处理时延:数据在路由器和终端设备上因为存储转发技术加工处理需要的时间
实际上,这四种时延谁更大,就不好说,有各自的改进点,只有改进瓶颈点的时候,才能带来最大的提升:
- 发送时延可以通过提高发送速度改进
- 传播时延你没办法改,和距离有关(或许改进路由算法可以减少传播距离)
- 排队时延和处理时延都需要提高路由器的性能来改进

这道题的坑点在于单位换算,数据量的换算是2进制,数据率的换算是10进制。
发送时延=
100
×
8
×
2
20
1
×
1
0
6
\dfrac{100\times 8\times 2^{20}}{1\times 10^6}
1×106100×8×220
传播时延=
1000
k
m
2
×
1
0
5
k
m
/
s
\dfrac{1000km}{2\times 10^5km/s}
2×105km/s1000km,传播时延不要用2进制去换算,这和信息没关系,不要考虑二进制。
时延带宽积

有多种理解方式:
- 同一时间内,整条链路可以容纳的bit量
- 按照比特计数的链路长度。
- 从发送端发出但是尚未到达接收端的bit量
这个指标的高低不能反应性能,只是一个比较专业的特殊指标,衡量我们的链路有没有被充分利用。
往返时间RTT(Round-Trip Time)
从发送方发送完数据,到发送方收到接收方回复的时间。
简单来说就是,从发完到收到回复的间隔。
RTT的计算方式很多,本质上就是下面这个图

一个常用的公式:
有效数据率
=
数据长度
实际消耗总时间
=
数据长度
发送时间
+
R
T
T
有效数据率=\dfrac{数据长度}{实际消耗总时间}=\dfrac{数据长度}{发送时间+RTT}
有效数据率=实际消耗总时间数据长度=发送时间+RTT数据长度,有效数据率代表了实际上从开始发送到对方确认收到,这个全过程的数据率。
来道例题, 100 × 8 × 2 20 2 20 × 8 1 0 6 + 2 = 100 × 2 20 × 8 8.39 + 2 = 80.7 × 1 0 6 b i t / s = 80.7 M b i t / s \dfrac{100\times 8\times 2^{20}}{\frac{2^{20}\times 8}{10^6}+2}=\dfrac{100\times2^{20}\times8}{8.39+2}=80.7\times 10^6bit/s=80.7Mbit/s 106220×8+2100×8×220=8.39+2100×220×8=80.7×106bit/s=80.7Mbit/s

利用率
-
信道利用率:信道有多大比例的时间是被使用的。如果总是被利用,就是100%,完全空闲就是0。
- 利用率太低肯定不好。
- 利用率也不是越高越好。根据排队论,当信道的利用率越来越高,时延会急剧增加。

-
网络利用率:全网络的信道利用率的加权平均值。
非性能特征

计算机网络的体系结构
计算机网络体系结构的形成
计算机网络是非常复杂的系统,传输文件需要解决很多很多问题,因此ARPANET设计的时候就提出了分层方法,将复杂的通信问题划分为独立的,易于研究的局部问题。
- 抽象分层。并不是在物理上将网络分层,而是在问题解决的时候分层。
- 统一标准。互联网上的所有主机都要遵守同样的标准。
- 模块独立。分层要分的很清晰,解耦。熟悉程序设计的同学懂的都懂。
协议与划分层次
最开始的标准协议是ISO(国际标准化组织)提出的OSI(Open Systems Interconnection)模型。这个模型在1983年(和TCP/IP协议同时出现)形成了ISO 7498国际标准。ISO 7498模型是一个7层模型,是最开始的理想模型,但是实际上不采用这个模型。
计算机网络的体系结构的定义:
- 定义计算机网络的层次,即分层
- 定义层次内部的协议,即精准定义这个层次要实现的功能
- 协议只是规则,具体实现由厂商来做。
协议
协议是为了数据交换而建立的约定,有三个组成要素
- 语法:数据交换的格式
- 语义:这个格式表达的含义,要完成的功能
- 同步:完成一个任务需要的各种操作的时间顺序。比如A先发给B,然后B告诉A已经收到,A确定B已经确认,这种反复确认需要按照时间顺序来。
协议有两种形式:
- 自然语言:便于人来阅读
- 程序代码:让计算机理解
无论如何,都不能出现二义性,要精确描述。即便如此,也不是十全十美的,很复杂。
分层
关键在于,如何分层?原则很多,下面简单列出一些:
- 层次适度:太少就复杂,太多就浪费资源
- 层次关系:每个层次都应该有自己的分工,互相独立,只对外暴露接口,但是相邻层次之间又要有自下而上的支持。注意,只有相邻层次才会交互信息,不然耦合度就又高了。
- 层次协议:每一个层次都要有一个共同的协议

听起来还挺高大上,其实我们现实中的物流就是一种网络,而且也是分层的:

分层既有优点也有缺点,分层的优点是便于构造大型系统,缺点自然是效率会变低,会产生额外的沟通消耗。
具有五层协议的体系结构
OSI七层很理想,最终因为赶不上商业化速度而被淘汰,实际上其层次太多,效率比较低,实际落地不太好用。
因此最开始用的其实是一个4层约定,即TCP/IP四层模型。这是一个事实上的约定,并不是严格指定的标准。这个模型的根本缺陷在于,是一个凑合用的东西,并不是严格的标准。尤其是最底层的数据链路层和物理层是混在一起的,功能混乱。
现在通用的体系结构是5层结构,相当于TCP/IP的优化版本:

各自的层次大概有如下功能:
- 应用层。
- 任务:通过进程间的交互信息来开发互联网应用程序,为用户服务。注意是在进程间交互
- 协议:进程间通信规则。其数据单元是报文。
- 比如https协议,协议特别多。
- 传输层(运输层)
- 任务:在两台主机的进程之间传输数据。传输数据关键的技术是复用和分用。
- 和上一层的区别:应用层是用这个数据,而传输层是传这个数据。
- TCP协议:面向稳定链接的,可靠数据传输服务
- UDP协议:提供无连接的,最快的传输服务
- 网络层
- 任务:为不同主机提供通信服务
- 路由选择:通过算法为互联网中的路由器生成转发表
- 转发:依据转发表将分组发送到下一个路由器
- 协议:主要是IP协议,其他都是辅助。数据单位为IP数据报。
- 任务:为不同主机提供通信服务
- 数据链路层
- 任务:实现相邻节点之间的可靠通信
- 协议:数据单位为帧,要做到差错检验,保证正确。
- 物理层
- 任务:实现bit的传输
- 协议:确定物理接口的规格,几根引脚,如何链接
我们可以看到,每一层都有一种数据传输单元,即PDU(Protocol Data Unit)协议数据单元,虽然两台主机不一样,但是他们的协议一样,每层的PDU封装解封规则也是一样的。
注意,物理层只是定义了物理接口的规格,实际的传输介质在物理层之下。同理,应用层之上其实还有用户。从微观的角度来说,信息的传递是非常麻烦的:
- 主机1发送:首先主机1要逐层封装,在物理层变成bit流传输到路由器。
- 多次路由:路由器不需要最上面两层,只需要顺着下面三层解析IP就可以。
- 主机2接收:主机2根据对等协议反向逐层解封,最后显示到应用程序中。
然而从宏观角度来说,就是我把一个信息通过路由器中转发送到另一个主机,甚至再宏观点,就是从一个主机发送到了另一个主机。其他过程对于用户来说,都是透明的(在计算机学科里,透明指的是看不见)
实体、协议、服务和服务访问点
- 实体:每一层的那个东西就是实体,没啥含义,就是习惯用法。
- 协议:同一层实体之间沟通的约定。
- 服务:下层实体给上层实体提供功能接口服务。
- 上下层沟通需要用到交换服务原语
- 我们接口想象成上下层之间的接触面,这个接触面就是交换服务点SAP(Service Access Point)。注意,SAP并不是存在于抽象层次中的,他只是一个概念,实际上就是功能接口,
总的来说,协议是水平的,服务是垂直的。从实际运行来讲,效果上每一层的实体都认为自己在和对等层实体通过协议交流,但是实际上实体之间是通过下层实体提供的服务来进行交流的,只是这些服务对于上层是透明的。

TCP/IP的体系结构
网络层IP协议非常重要,重要性好比计算机的操作系统,起到承上启下的作用。

物理层
基本概念
我们学习的计算机网络体系结构,都是基于TCP/IP发展而来的五层结构,物理层就是最下面的层次。然而需要注意,物理层并不参与具体的信号传输,其功能如下:
- 链路层将bit流传送给物理层
- 物理层将bit流按照传输媒体的需要进行编码,可以是光,可以是电等各种信号。
- 物理层将编码后的信号通过传输媒体传送到目标机器的物理层
关键在于,物理层要尽可能屏蔽掉不同传输媒体和通信手段的差异,为链路层(上层)提供一个统一的bit流传输服务。置于怎么屏蔽,就是物理层的协议,又称作规程。
实际上,物理层的任务在于定义一个从bit到传输媒体的接口,更具体一点说,是定义了DTE(数据终端设备)与数据线与DCE(数据电路终结设备)之间的接口特性:
-
机械特性。接口摸得着的特性,我们平时区分不同接口一般都是用机械特性区分的。
- 物理接口的形状尺寸
- 物理接口的引线数目与排列
- 物理接口的固定和锁定装置
-
电气特性。接口支持的电路特性,比如电压范围,阻抗,速率等等。

-
功能特性。规定某条线的某一个电气特性代表什么含义
- 具体到接口,就是规定了每一个引脚的含义,高电平代表什么,低电平代表什么(这个特性其实就是数字信号和电器信号转换的关键点了)

-
过程特性。对接口上发生的各种事件的宏观定义,规定其发生的时间顺序。

数据通信的基本知识
数据通信系统的模型
三大部分:
- 发送端=信源+发送器
- 传输网络
- 接收端=接收器+信宿

信道与调制

这个图比较宏观清晰:
- 通信。在源和终点之间传输信息。
- 信道。传输的通道,在逻辑上叫信道,分为单工,半双工,全双工
- 传输的内容,按照不同层次有如下含义:
- 信息,就是你实际要表达的意思
- 消息,信息的载体,比如图片,语言,文字
- 数据,消息的实体,图片实际上是一堆RGB的数值构成的,文字是由一堆字符构成的。分为数字数据和模拟数据。
- 信号,消息的载体,分为数字信号和模拟信号。
- 调制。
- 为什么需要调制。信道的通信频率是有范围限制的,最开始产生的信号叫基带信号,频率很低,甚至有直流信号,而且不同信号之间也会干扰,所以在上路前需要进行调制,把基带信号转换为可以在信道上传输的带通信号。
- 调制有两种方法
- 基带调制,仅仅对基带信号进行波形变化,比如用高低电平表示0和1
- 带通调制,使用载波将基带信号的频率提高,并且变成模拟信号。
这里说一下调制和编码的区别,凡是变成模拟信号的,都叫调制,不论你原来是什么信号。对应的,凡是变成数字信号的,都叫编码。其实调制和编码的界限没有这么分明,基带调制其实也算是一种编码。
编码的方式如下:
- 不归零制。正电平是1,负电平是0。看似可以传递消息,但是需要搭配时钟使用,否则无法区分连续的n个0/1.
- 归零制。正脉冲代表1,负脉冲代表0,发出脉冲后回归0电平,因此波形里就蕴含了时钟信息。
- 曼彻斯特编码。位周期中心跳变,高跳低为1,低跳高为0(也可以反过来)。两个位周期之间跳不跳就看情况了,要画图就先画每一个位周期,再画周期之间的跳变。
- 差分曼彻斯特编码。位周期中心始终跳变,位开始时刻是否跳变代表0/1。形象化理解就是,0不会改变波形方向,1会使波形方向翻转。下图中,刚开始有个1,后面000不改变波形方向,之后1,所以翻转一下,之后两个0不影响波形方向。最后的三个1,波形就在不断翻转。

上面4个编码方式中最常用曼彻斯特和差分曼彻斯特,原因如下:
- 频率更高:曼彻斯特和差分曼彻斯特的信号频率比不归零更高。
- 自同步能力:曼彻斯特和差分曼彻斯特可以通过波形提取时钟频率
调制(Modulation)的基本方法就是用正弦波/余弦波来表示0/1,具体如下:
- 调幅(AM,amplitude):频率,初相一致,用幅度区别0/1
- 调频(FM,frequency):幅度,初相一致,用频率区分0/1
- 调相(PM,phase):频率,幅度一致,用初相区分0/1(比如0是cos,1是sin)
- 正交振幅调制(QAM):振幅和相位混合调制,m个振幅和n个相位可以组合成m×n个状态(与后面的码元有关系)

最后说一下码元这个概念:
我们前面编码的时候,每一个位周期可以代表0/1,这个位周期就是码元。那可不可以用一个码元代表多个bit呢?理论上,假设要携带3个bit,那么3个bit的组合有8种状态,因此只要一个位周期可以有8种状态,那么就可以用一个码元表达3个bit。如何实现8种状态呢?正如我们之前用正负来区分两个状态,我们可以通过电平的0-7档来实现区分8个状态。又或者使用QAM技术获得16种状态,那么将会有4个bit。

信道的极限容量
现在已经解决了信息调制的问题了,但是这并不意味着调制后的信号就可以无限制地通过信道进行传输,这涉及到信道的极限容量。极限容量受到很多因素印象,极限容量有两种计算方法,分别是奈氏准则和香农定律。
奈氏准则
一个低通信道中,信号的高频分量无法通过信道,如果低通信道的通频带越宽,那么可以通过的信号频率范围就大,可以传播更多码元却不会引起码间串扰(码元之间出现重叠,无法解析)。奈氏准则给出了理想情况下(没有噪声干扰的信道)
给定通频带带宽W(Hz),则码元传输速率是2W。这只是码元速率,具体到信息速率,还要乘以一个码元可以携带的bit量,所以V进制码元的公式如下:


香农定律
实际情况中,一个信道里还有噪声干扰,所以不见得能达到奈氏准则的理想速率。香农公式给出了带有噪声的信道中,实际可以达到的最高速率。

其中的S/N又被称作信噪比,实际上是信噪功率比。
信噪比有两种写法,一是用S/N,这是便于后续计算的,有时候会给dB单位,你需要转化成S/N值。

设信噪比为r,则 S N = 1 0 r 10 \dfrac{S}{N}=10^{\frac{r}{10}} NS=1010r
两者联系与例题
看起来,奈氏准则和香农公式没有关系,其实,当你提高码元携带的bit量时,S就会提高(信号功率提高),但是S提高的同时,N也会提高,这样反而可能会导致S/N降低。所以说奈氏准则和香农公式时两个有关联的瓶颈,奈氏准则告诉你提高码元携带bit量可以提高速度,但是香农公式又告诉你如果提高bit量会降低S/N,可能会起反效果。
这道题就是简单的奈氏准则。
这道题两个都用了。如果V=2,那么此时奈氏准则上线低于香农公式,此时V就是瓶颈,我们可以提高V到16,则奈氏准则结果为32000,此时香农公式又会成为瓶颈。

物理层下的传输媒介
传输媒介指的是信号实际的通路,这不是物理层的东西,物理层是抽象,而传输媒介是现实的东西,分为两种:
- 导引型:电磁波沿着固态媒体(铜线或者光纤)传播
- 非导引型:电磁波沿着自由空间传播,无线技术都是非导引的
从这一点来看,导引和非导引本质一样,都是传电磁波,只不过导引技术将电磁波收束,集中起来。
下图给出目前所有传输媒体的频谱(根据奈氏准则,频率越高,对应的带宽越大),可以看到,光纤一骑绝尘。
导引型传输媒体
双绞线(Twisted Pair)
原理:把两根互相绝缘的铜线绞合,只要绞合地恰当,两根铜线发射的电磁波就可以互相抵消,极大地降低信号干扰。
理论上绞合程度越高,速度越快,但是实际上绞合程度有上限,因此还诞生了其他方法,比如屏蔽,由此分为两大类:
- UTP:无屏蔽双绞线。便宜不用接地
- STP:屏蔽双绞线。贵需要接地,但是抗干扰。

把各种手段用上,双绞线的带宽也是越来越高。
同轴电缆
以前的数字有线电视就是用的同轴线,抗干扰能力强,所以被广泛用于高速远距离通信。
然而呢,现在双绞线和光纤的速度都已经上来了,比价格,同轴电缆不如双绞线,比距离,同轴电缆不如光纤,所以现在同轴电缆已经基本不用了。

光纤
光纤的原理是,电转光,全反射传输,光转电:
- 发送端要有光源,通过电脉冲转换为光脉冲。
- 传输的过程通过玻璃的全反射来将光的损失减到最低。
- 接收端需要有光检测器,检测到光脉冲后还原为电脉冲
光纤有比较多的种类:
- 单模光纤的强度衰减很慢,支持远距离传输
- 多模光纤折射次数比较多,所以强度衰减快,通常是局域网连接用的多。

光纤有三个常用波段,因为这三个波段衰减率是最小的。因为这三个波段的线缆粗细不同,所以这三个波段不可以混合使用。
总的来说,光纤的性能很好,欠缺点就是布置不太方便,成本较高。

为了解决这些问题,光纤的线缆构造还是比较复杂的:

非导引型传输媒体
非导引型其实就是无线传输。分为长波,中波,短波,微波。

长波和中波对应海事无线电和调幅无线电,基本是直线传输,带有一点绕行能力,所以放到海上,没有遮挡比较省心。
短波比长波和中波的路径要更加直,所以是通过大气电离层的反射来进行远距离传输的。
现在主要是用微波了,微波不能绕行,而且会穿透电离层,所以微波有两种接力方法:
- 卫星通信
- 同步卫星:比如GPS,北斗。时延大,保密性差,但是通信费用与距离无关,理论上3个卫星就能覆盖全球。
- 低轨道卫星:比如星链,鸿雁通信系统。在近地轨道铺设卫星网络,速度比较快,关键是覆盖全球。
- 地面微波接力
信道复用技术
信道复用是为了充分利用信道,防止占着信道不传输信息的情况出现,总之要尽可能让信道忙起来。

频分复用(FDM)、时分复用(TDM)、统计时分复用(STDM)
频分复用FDM中,一个用户自始至终占用一个频带。以前广播申请拍照其实就是给你分一个频带。FDM便于实现,但是缺点就是,容纳的用户总量有限,毕竟频带不能一直分下去。
时分复用TDM中,用户按照时间片轮转来占用信道,每次占用全部频段。TDM同样面临用户容量小的问题,毕竟时间片也不能一直分下去。

为了解决FDM和TDM的容量缺陷,两个方法各自衍生出了一些技巧:
- FDMA(Frequency Division Multiple Access)频分多址技术为了解决FDM用户容量小的问题,让N个用户轮流使用M个频段,防止持续独占。
- TDMA(Time Division Multiple Access)时分多址技术为了解决TDM用户容量不够的问题,让N个用户轮流使用M个时间片,至于M个时间片分给N中的哪M个,就是具体实现的问题了。
实际上,TDM仍然有缺陷,你能保证N个时间片(一个TDM帧)中,每个用户都有要发送的内容吗?你能保证轮到你的时候你有东西发吗,如果没有,那是不是浪费了你的时间片。

因此就有一种思路:
统计时分复用(Statistic TDM):整体上按照时间片轮转,但是如果你没东西发,我就跳过你的时间片。
因此,STDM中,STDM帧长度不固定,根据用户要发的东西来确定,即按需动态分配时间间隙,这个确定的模块就是复用器。

波分复用(WDM,Wawelength Division Multiplexing)
电信号可以进行频率上分割,光信号同样,所以波分复用其实就是光信号的FDM。
下图中不同波长的光各自的频率也不同。
码分多址复用(CDMA,Code Division Multiplexing Access)
CDMA特点
以上两大类方法,其实本质上都是交错发送,没有一个是真正同时同频段的复用。码分复用(CDM)就是如此,多个不同地址用户共享的时候,叫做码分多址(CDMA)。整体思路如下:
- 发送端:为每一个用户分配固定码型,将自己的信号加工一下
- 将每个用户加工后的信号直接叠加发送
- 接收端:通过用户的码型,提取对应的信号
CDMA原理
方老师讲的比较细,第一次不容易理解,结合这篇文章看比较好:
码分复用原理
这篇文章里没有提到,为什么X=1就代表发送了1,X=-1代表发送了0,X=0代表没有发送?
首先明白 S x S_x Sx只可能是两种情况, S S S或者 S ‾ \overline{S} S,因此 S ⋅ ( S x + T x ) S\cdot (S_x+T_x) S⋅(Sx+Tx)的结果就是 S ⋅ S x S\cdot S_x S⋅Sx,这个结果在有信号的情况下,不是1就是-1,对应信号1和0。在没有信号的情况下,点积结果为0,所以0结果对应无信号。
CDMA讨论与应用
CDMA的加密型比较强,很不错,缺点,我感觉就是把一个bit变成了m个bit(但是这个只是我的一个猜测,估计不是我想的这么简单,否则这效率也太低了)
CDMA考研计算可能会考,不过很简单就是了。
数据链路层
链路层概述
首先区分两个概念:
- 链路:两个直接相连接点之间的物理通道
- 数据链路=链路+协议,是两个直接相连接点之间的逻辑通道,不仅有链路,还有控制数据传输的软件协议。
从5层模型上来说:
传输媒体负责无差别传输具体的信号,物理层规定了bit-信号-bit的具体转化细节,实现了相邻节点透明传输bit。链路层的任务是在相邻的两个节点之间,通过数据链路传输帧。
在物理层,数据是连续的bit流,在链路层,数据是分组的,每一组就是一帧,是链路层的PDU,是上层(网络层)数据报的进一步封装。
从宏观协议栈的视角来看,链路层不需要管数据bit是如何传输的,它只负责将bit分成若干帧,在2层之间进行传输。
虽说链路层是在链路之间进行传播,但是也不完全是不能中转,也可以经过交换机的一次中转进行广播通信。

链路层的基本问题
在链路层中新的问题又来了:
- 封装成帧:如何在连续的bit流中找到一组数据的开始和结尾
- 透明传输:线路上有多个设备的时候bit流应该由谁接收,如何去区分不同用户
- 差错控制:bit流传输错误怎么办
封装成帧
之所以要划分成帧,是为了便于检验物理层中的传输错误。如果一次性全部传输,那么出一点错就要前功尽弃,反之,我们只需要重新发送错误的帧就可以。
将bit流切分成不同的帧,关键在于帧定界,在链路层中,帧定界是通过在bit流的首尾加帧首和帧尾实现的。只有链路层首尾都加,其它层只加头部。这是因为链路层的首尾是用来定界的,而其它首部是用来附带信息的。
中间的数据报,最大不能超过MTU,其实也不能太少。
字节计数法
使用一个字节来描述帧的长度。只要传输没有差错,就可以良好运作。然而,一旦出现差错,将出现严重错位,导致所有帧全部混乱,所以字节计数法没有实用价值。
字节定界符
直接用一串特殊序列字节当做帧开始符和帧结束符。

假如帧中数据恰好就是SOH和EOT呢?这必然会导致定界错误,这就要在透明传输部分去解决了。
透明传输
字节填充法
发送方在发送前,首先要增加SOH和EOT,之后检查原始数据。凡是在原始数据中出现EOT,SOH,ESC,都要在其前面插入一个ESC(其实就是转义符),表示这只是原始数据而不是特殊字节。
如此,就可以保证100%排除这个问题。
比特填充法
使用bit序列作为帧定界符。如果在原始数据中碰到和帧定界符一样的序列,那么就插入一些bit序列打断这个帧定界符序列。
物理层编码违例
前面讨论的都是,如果原始数据中出现帧定界符怎么办?
物理层编码违例反其道而行之,直接让原始数据中不出现帧定界符。具体方式就是使用一些很特殊的序列的那个帧定界符,这些序列特殊到几乎不可能或者干脆就不会出现在中间数据中。
比如以太网帧前导码,差分曼彻斯特的不正常跳变信号等。
差错控制
上面的方式只能在理论上保证传输没有问题,但是链路是有噪声的,所以出错是必然的,有一个指标叫误码率BER(bit error rate),信噪比越高,BER越低。
差错控制解决的问题是:如果出错了,如何检测?怎么处理?有两种思路:
- 纠错码:找到错误位置
- 技术难度很高
- 通常用于频繁出错的地方,比如无线链路
- 检错码:确定是否出错
- 错了就丢弃重发,对了就接收
- 用于BER较低的链路,比如光纤,偶尔丢几个帧对效率影响不大。
纠错码太复杂,略过,我们实际上更多使用检错码,检错码在链路层里又叫帧检验序列(FCS,Frame Check Sequence),其中CRC冗余码是很经典的检错码算法,但CRC并不等同于FCS。
CRC冗余码

给出大致流程,注意,他这个除其实不是传统意义上的除,而是模二运算(其实就是特定规则的按位异或运算),总之,其检验流程如下:
- 给定k位原始数据和n+1位除数,通过CRC算法,计算出n位冗余码,将k+n位数据发送过去
- 接收端使用同样的除数,计算CRC结果,为0则大概率无错,非0说明出错。
注意,判错一定是错,但是判对,不一定对,万一就恰好错得整除了。理论上,n越大,误判概率就越小,但是也只能是逼近,而且n太大效率就低了,所以国际上是有一些通用的标准除数的。
这个模二运算很抽象,直接上例子:
- 补n位0
- 反复用除数运算,移位
- 最后剩下n位余数,就是校验码。

链路层无差错但不能可靠传输
首先区分,无差错和无错误。无错误是一点都不错,无差错是以接近于1的概率无误。其次明白可靠传输的含义:发送与接受的内容是无差错的
由上可知,链路层传递的帧内部是无差错的。但是帧外部呢?不能保证。事实上,有两种差错:
- 比特差错:帧内部无差错
- 传输差错:帧丢失,重复,帧失序
真正的可靠传输,还要保证没有传输差错,比如加上帧编号,确认,重传机制,但是这是上层要做的事情了,链路层已经做的够多了。
PPP协议
Point to Point Protocol,是最早的链路层协议,也是最符合数据链路定义的协议。
本质上来说,PPP协议是一种链路层协议,其功能就是向上封装数据包成帧,向下通过同步/异步串行链路进行传输的方法。
PPP协议概述
PPP协议有如下特点:
- 简单。这是任何设计的原则,功能简单,集中。
- 向上,能承载各种网络层协议的分组
- 向下,能兼容各种类型的链路
PPP和广播协议的区别除了点对点以外,还有一个就是地址协商。在发送数据之前,需要进行协商,协商的内容包括资源,地址等。
PPP协议由两个子协议组成:
- 链路控制协议(LCP,Link Control Protocol)。
- 用于协商,主要功能是身份验证。
- 网络控制协议(NCP,Network Control Protocol)
- 是一大类协议,用于向上兼容不同网络层协议
PPP协议的技术点
- 封装成帧。
- 透明传输
- 差错检测
一个PPP协议帧:
- 左右两边有帧定界符F
- 地址字段A
- 控制字段C
- 协议字段,告诉你中间的信息是数据报,还是LCP内容,还是NCP内容
- FCS是校验码,PPP中使用CRC计算。

PPP协议是面向字节的,所以长度一定是整数个字节,但是具体传输不见得就是一个字节一个字节传输:
- 同步传输。
- 面向bit传输,单位是帧,采用的定界符是bit序列。
- 采用零比特填充法保证透明传输,比如定界符是0111 1110,那么一旦发现连续的5个1,就插入一个0。接收端也是,发现连续的5个1,就删掉后面的0。
- 效率更高,光纤常用,因为光纤可以保证时钟统一。
- 异步传输。
- 面向字节传输,单位是字符,采用的定界符是字节。
- 采用字节填充法保证透明传输

PPP协议工作状态
流程图如下,失败原因无非两个,一是设备问题导致链路无法建立,二是LCP身份验证无法通过。
一旦成功,就可以链接到网络,进行NCP协商,传输数据。
使用广播信道的链路层
局域网的数据链路层——以太网详解
局域网的概念和问题
PPP点对点是比较麻烦的,尤其是不适应大规模网络,而局域网就不一样了,不仅可以通过广播的方式快速访问全网,还便于扩展系统。
因此现在的网络都是采用局域网了,点对点链接只在很少的场景中使用。
局域网有三种拓扑。最开始是右上角那个总线网,之后出现了环形网,星型网。
其实这些东西都差不了太多,本质上就是总线网,只是集线器在工程上便于部署,所以现在也都是用星型网。局域网发展到了后期,集线器变成网桥,变成交换机,性能又得到了巨大提升,星型网就占据了主导地位。
无论是哪种拓扑,本质上都是所有机器共享一条总线信道,那么必然就会发生冲突(碰撞),解决方案就是通过信道分配:
- 静态分配
- 频分复用,时分复用,波分复用,码分复用。
- 适用于用户少且固定稳定的场景,不适合局域网这种突发情况
- 动态分配
- 随机接入:用户在受控状态下随机地发送信息。
- 受控接入:用户服从更强的控制,比如轮询(polling)
以太网的发展和优势
以太网最开始是一个3Mbps的技术,创始人积极推动技术商业化,并且变成免费开放标准,背靠IEEE,一统有线局域网江山,现在的无线局域网也是基于以太网发展起来的。
一统江山后,以太网的一个重要突破是发明了交换机,取代了网桥和集线器,性能特别好。
后面以太网的主要发展方向就是更快,不断更换线材,提高带宽,从最开始的同轴电缆,到后面的35678类双绞线,再到光纤。当以太网带宽超过千兆的时候,就是我们现在说的gigabit ethernet了,现在已经是万兆级别了。
以太网到现在也是一统江山的地位,这归功于以太网的巨大优点,除了生态好以外,就是快,极致的快,之所以快的具体原因如下:
- 采用较为灵活的无连接工作方式
- 直接发帧,不用提前建立逻辑连接,不用确认身份
- 功能精简,只消除比特差错,忽略传输差错,交给高层决定。在保证一部分可靠性的前提下,尽可能高效。
- 使用曼彻斯特编码
- 不需要考虑同步问题,自带同步信息,便于广播,只管提速就行
可能有人会疑惑,以太网是不是不可以实现PPP,这算不算缺点?
其实以太网可以实现PPP协议,只需要在广播的时候附带目标mac地址,在一众收到广播信息的机器中,只有mac地址匹配的才会做出响应。
至于如何通过动态分配解决总线上的信号冲突(碰撞)问题,这就是后话了。
所以总的来说,以太网优势巨大,缺点很少。
以太网协议与网络适配器(网卡)
802.3是第一个以太网标准,当时有LLC子层和MAC(Medium Access Control)子层。现在LLC子层已经形同虚设,逐渐退出历史舞台,功能被网络层和MAC层吸收,而链路层聚焦于MAC层。
现在的网络适配器(网卡)里面已经没有LLC子层了。
所谓网络适配器,就是网卡。适配器集成了链路层和物理层,比如我们的有线网卡(以太网卡),又比如无线网卡,里面就有链路层和无线收发模块(物理层)。
适配器的功能:
- 进行串并行转换,向上在机器里并行通信,向下在链路中串行通信
- 数据缓存
- 向上,在操作系统中安装驱动,向下,实现以太网协议。
CSMA/CD协议
大致流程
CSMA/CD协议是一种动态分配技术,用于解决以太网冲突。
载波监听多点接入/碰撞检测 :Carrier Sense Multiple Access with Collision Detection
- 多点接入:一条总线,多个点同时接入,共享信道
- 载波监听:发送数据前和发送数据时,每个站点都要不停地检查信道。
- 碰撞检测:靠检测站点直连的信道电压。
总的来说,就是在多点接入的前提下,每个站不断监听,进行碰撞检测,如果发现碰撞,则先停止发送,等待一段时间后重发。
“先听后发,边听边发,冲突停止,延迟重发”
碰撞检测原理
靠检测站点直连的信道电压:
- 在发送前,如果信道电压不变,那么说明没有站在发送信息,信道空闲。
- 在发送时,如果只有一个站发送数据,那么信号电压变化幅度就是一个合理值(比如5)。如果电压变化幅度超过一定限度(比如7),那么就说明至少有两个站发送数据,冲突信号叠加起来超过了5这个幅度。
似乎发送前检测一下就可以了,为什么还要在发送的过程中进行碰撞检测呢?因为监听只能监听当前设备直连的链路电压,如果还有其他设备的信号在路上(传播时延),此时就会误判空闲。
如下图,A在0发送,B在 τ − δ \tau-\delta τ−δ发送,两者各自经过 τ \tau τ的时间到达对方设备,在中间会发生碰撞。B在发送之前,A已经发送了,但是B的判断结果是信道空闲。

只有当B在发送到 τ \tau τ时刻的时候,其检测到信号波动异常,这才知道A已经发过数据了,检测到了碰撞。这类碰撞只有在发送的时候才能检测到。
而当A在发送到 2 τ − δ 2\tau-\delta 2τ−δ时刻的时候,其检测到信号波动异常,A检测到碰撞。
总的来说,之所以这种碰撞会出现,就是因为A的信号没有完全到达B,B误判为空闲后发送信号导致的碰撞。
怎么才能不碰撞呢?或者说怎么才能不误判呢?
那就是在 τ \tau τ时刻,一旦A的信号成功到达B,B检测到信道上有电压波动,说明有人在发送信号,B就会延迟发送信息了。其他设备也是如此,因为以太网是广播的,只要一个设备能够先抢夺到信道,其他的所有设备就都不会再发送信息了。
这里又有一个问题,一个 τ \tau τ只能保证其他设备不误判A,A自己怎么知道自己没有被误判呢?
假设A被误判,那么A将会在 2 τ − δ < 2 τ 2\tau-\delta<2\tau 2τ−δ<2τ的时刻检测到波动异常(其他设备信号干扰)。反之,如果A成功抢夺信道,那么从 τ \tau τ开始,其他设备就不会再发送信息,那么也就意味着,A收到其他设备信息的时刻最早也是在 2 τ 2\tau 2τ以外了。换句话说,只要A在 2 τ 2\tau 2τ内没有检测到碰撞,那么就A就可以确定自己没有被误判。
最后总结一下
- 在一次成功的抢占过程中:
- τ \tau τ时刻,A事实上已经成功抢占信道,屏蔽其他设备,只不过A自己不确定。
- 2 τ 2\tau 2τ时刻还没检测到碰撞,则A可以确定自己成功抢占信道,并继续安全地发送信息。
- 在一次失败的抢占过程中:
- τ \tau τ时刻前,其他任一设备误判,发送信息,与A冲突
- τ \tau τ时刻,其他设备得知自己冲突了,停止发送,等下次。
- τ − 2 τ \tau-2\tau τ−2τ之间某一时刻,A检测到碰撞,则停止发送,等下次。
所以A无非就是两种情况,以
2
τ
2\tau
2τ为分界点,这个点叫做争用期,或者碰撞窗口。
小于这个时间收到消息(检测到异常波动),那么就是冲突了。否则就说明没冲突,而且直到A发完消息的这段时间内也一定不会冲突,因为A已经在 τ \tau τ时刻抢夺信道,将其他设备压制。争用期的意义就在于此,只要过了争用期还没出问题,就可以保证这一次发送一定不会出问题。
有时候,用 τ \tau τ来计算有点抽象,在确定链路长度和发送速率的前提下,可以计算出争用期内发送的数据(比如 2 τ = 51.2 μ 2\tau=51.2\mu 2τ=51.2μ,速率=10Mb/s的情况下,争用期数据=64B),只要A能连续发送64B数据不出问题,那么就代表其已经度过了争用期。
虽然现在的链路和速率已经发生了巨大的变化,甚至我们已经通过交换机从本跟上取代了CSMA/CD算法(交换机模式下,信道已经不是独占了),但是64B这个数字仍然做为一种判断残帧的传统延续了下来,作为最短有效帧长来使用。
重传原理
为了方式反复碰撞,重传的时间间隔一定是要有随机性的。所以采用截断二进制指数退避算法:

解释一下:
- 首先要保证随机性,给一个退避时间倍数集合,随机抽取。最后的退避时间是0(立即重发)或者是争用期整数倍。
- k会逐渐增长。刚开始退避时间整体比较短,可选的项目也很少,随着冲突次数越来越多,整体退避时间的可选范围也要越来越大,项目越来越多,这样就使得冲突概率越来越小。
- k不能无限延长,这代表了退避时间不能无限延长,所以最大就是k=10。同时,退避次数也不能无限积累,最大16次就要丢帧报错了。
强化碰撞通知:人为干扰信号
AB碰撞了,其他设备在这个时候仍然可能误判。为了防止大量不可控的误判,当A/B检测到冲突的时候,一方会广播一个干扰信号,让所有用户都知道发生了碰撞,大家都消停一下。

CSMA/CD的特点
- 半双工通信。信道独占就决定了,基础以太网只能进行半双工通信。
- 每个站在争用期内,存在碰撞的可能性
- 容量小,当机器变多,频繁碰撞会使得以太网的平均通信量远低于最高数据率。
在以太网的初期,CSMA/CD还不错,但是随着网络发展,局域网设备增加,交换机也就应运而生了。
使用集线器的星型拓扑
前面说的CSMA/CD技术是应用于早期以太网的,那个时候还是总线拓扑,用的也是同轴线,空间限制很大。
后面采用了三类双绞线(10BASE-T,10Mbps基带速度双绞线)后,空间限制变小,拓扑也变成了星型结构。在星形结构中,中间的总线变成了集线器(hub),他是个电子器件设备,还是比总线更具有可靠性。
但是注意,集线器和交换机并不相同,集线器在效果上上和总线没太大区别,还是用的CSMA/CD协议,还是半双工,还是在物理层工作。(而交换机不一样,摒弃CSMA/CD协议,是全双工,工作在链路层)
以太网信道利用率分析
首先定义以太网信道利用率= T 0 T 0 + τ \dfrac{T_0}{T_0+\tau} T0+τT0= 发送时间 占用时间 \dfrac{发送时间}{占用时间} 占用时间发送时间。
可以看到,计算利用率不考虑碰撞退避时间。其中,发送时间 T 0 = L C T_0=\dfrac{L}{C} T0=CL,占用时间还需要多一个 τ \tau τ来避免冲突, τ \tau τ由链路本身的长度决定。

为了便于描述,定义了一个a,a越小,信道利用率越大。
为了降低a,可以降低 τ \tau τ或者提高 T 0 T_0 T0:
- 太长的链路,信息滞留在链路的时间太长,提高碰撞风险
- 太少太频繁的发送帧,也会提高碰撞风险

到目前为止,在没有交换机的情况下,以太网的信道利用率会因为冲突而降低(可能才30%左右)。本质上就是因为共享信道导致的碰撞,进而导致利用率下降,所以CSMA/CD协议虽然可以解决一时的问题,但是还是差很远,这也是交换机出现的意义。
以太网的MAC层
现在LLC子层基本不用了,现在大家主要用MAC子层。
MAC地址
MAC层的MAC地址又叫物理地址,相比之下,IP地址是逻辑的,是随着局域网变化而变化的,而MAC地址是固化在适配器的ROM上的(与网卡绑定),全球都是使用一个48位标准(4×3或者2×6个16进制数字,总计48位),保证适配器MAC地址不重复。
在局域网中,每一个接口对应一个适配器,因此一个接口对应一个MAC地址。一般来说,一台电脑只有一个网卡,所以只有一个MAC地址,而一个交换机有多个接口,背后是多张网卡,因而也具有多个MAC地址。
如何保证MAC地址不重复呢?IEEE组织为每一个生产适配器的厂家分配24位3字节的序号(组织唯一标识符),而厂家内部用剩余的24位3字节的序号来区分适配器(扩展标识符)
所以通过前3个字节可以查出适配器厂家,而后3个字节就是厂家适配器的序列码。
MAC帧格式
mac帧有两种格式:
- 以太网V2格式。
- IEEE的802.3格式。
现在常用以太网V2格式,可以看到和我们前面学的链路层帧结构有很大的不同,不必担心,以这个为准:
- 46-1500字节的MTU
- 除了数据以外,有目的地址和源地址,各6个字节。
- 2字节类型代表了上一层的协议
- 4字节FCS是校验码
是不是只看到了代表信息的首部和尾部校验码,而没找到最重要的帧定界符?那就对啦,一个MAC帧里面压根就没有帧定界符,你要知道MAC层只是链路层的子层,不可以和链路层画等号。
MAC帧封装完毕以后,交给链路层进行链路层本身的封装,你以为会直接加帧首尾?还不是。
- 前面加8字节
- 其中7字节为帧前同步码
- 1字节为帧开始定界符
- 帧结尾定界符一般不加,通过软件来解决定界问题,成本较低。如果为了硬件加速,有的机器会在尾部加定界符。
所以你可以看到,MAC帧只是MAC子层的数据帧罢了,≠链路层帧,既没有前定界符,也没有后定界符,而即使是经过了链路层加装,也只是加装帧首罢了,尾巴加不加还不一定。

这里有补充点:
- MAC帧与MTU的长度区间
- 上界为1500很合理,这是为了限制长度
- MTU的下界为46是一个老传统了,46=64-18,即:46=最小帧长度-MAC层除了MTU以外部分的长度
- MAC帧的长度为64-1518B,MAC帧MTU的长度为46-1500B,注意区分。
MAC地址的分类与收发逻辑
在局域网中,适配器收到一个帧以后会检查帧里面的目标MAC地址是否和自己的mac地址相匹配,如果不匹配,就直接丢弃,接受的帧有三种类型:
- 单播帧(unicast):一对一发送
- 广播帧(braodcast):给局域网里的所有机器发送
- 多播帧(multicast):又叫组播,是给一组机器发送
除了目标地址与当前适配器不匹配的情况下,当前适配器还会因为帧错误而丢弃帧:
- 帧长度出错。帧长度不是整数字节,或者MTU长度在规定字节数量之外
- 帧校验不过。FCS校验失败
- 长度校验不过。在802.3规定中,2字节可能记录了MTU的长度,如果MTU实际长度不等于长度字节的值,就算校验失败,丢弃。

扩展的以太网
所谓扩展,指的是更大的范围,更多的用户。扩展有如下方式:
- 物理层扩展
- 光纤延长
- 集线器扩展
- 链路层扩展
- 网桥
- 交换机
- 虚拟局域网
在物理层扩展以太网
光纤
光纤可以使以太网的物理距离大大延长,光纤可以有2km长,而双绞线只有100m。
集线器与级联
集线器出现后,星型拓扑直接取代掉了总线网络,优点如下:
- 空间不受限。只要设备不超过集线器的覆盖区域,就可以随意摆放。
- 数量不受限。可以任意增删设备,只需要插拔集线器接口即可。
集线器还可以级联,或者说嵌套。这样做,在空间上扩展了集线器的范围,但是并不代表能支持更多的设备,缺点很多:
- 增大碰撞域但不增加吞吐量。无论级联多少级集线器,所有的设备仍然在同一个
冲突域(碰撞域,即可能出现信号重叠碰撞) - 设备类型受限。集线器只是总线的另一种形态,本质上仍然在同一个物理层,无法将使用不同技术的以太网连接起来,比如不同比特率就没办法连接。
- 存在安全隐患。所有设备在同一个冲突域,没有隔离,就可以进行各种形式的攻击。

在链路层扩展以太网
网桥
物理层扩展无法解决共享链路的问题,信号可能发生冲突,是半双工的。要想彻底解决这个问题,就需要在链路层下手,在链路层扼杀物理层冲突的可能,变成全双工。
集线器和网桥虽然都可以是两个集线器的介质,但是网桥将两个集线器隔离开了,两个集线器是两个隔离的冲突域。
集线器是无脑广播的,而网桥会根据转发表选择性进行转发,这种程度的控制就可以杜绝两个信号的碰撞。

网桥转发表记录了机器MAC地址与接口的对应关系,下图中,ABC挂在一个集线器上,接在网桥1接口,DE挂在另一个集线器,接在网桥2接口。
假设A往D发消息,网桥会检查D的mac地址是否在转发表中,如果在,就往对应接口发送消息,发送过去以后再在另一端集线器上广播。

交换机
基本原理
交换机其实就是多接口的网桥,本质上是在链路层进行转发控制,超脱于一层,所以直接解决一层的冲突问题。
交换机转发仍然是像网桥一样基于地址表,不再进行物理层的无脑广播,而是有策略地在链路层发送。而且策略是硬件计算,速度快。本质上是压把力放在了交换机,而不是物理链路上。
下图中,交换机的每一个接口都是一个碰撞域,碰撞域内部可能发生冲突,但是之间不会。现在一般都是一个接口链接一个设备,所以一个碰撞域只有一个设备,自然就不会冲突。
如果从碰撞域的角度理解交换机和网桥,可以说他们将一整个大碰撞域切割为多个小的碰撞域。而集线器不具有这种隔离功能。

最后总结一下交换机的特点:
- 储存转发。不会像广播一样立即转发,而是经过计算安排转发顺序。
- 即插即用。交换表(地址表)可以通过自学习算法学习,不用去配置(当然也可以手动写入静态表项)
- 硬件计算。交换机的转发计算是在硬件上直接跑的,效率很高。
- 隔离冲突域,独占带宽。每个接口的用户都是独占带宽的,所以可以扩展总带宽。
- 支持多种设备。因为交换机是链路层的,所以物理层的各种接口都是可以插在交换机的,即使各不相同。
交换机转发策略
交换机转发要查地址表,地址表可以自学习。自学习是逆向的,当一个设备发送信息给交换机时,交换机会记录这个端口与设备,把这两个信息绑定在一起写入地址表。
根据地址表中有无目标mac地址,有两种转发方式:
- 有目标mac地址。单点转发,直接转到绑定的端口。
- 无目标mac地址。广播,询问是否有机器是目标mac地址,如果有,则对应机器回应(此时又会将目标机器的信息学习进地址表)
一般来说,都是一个机器绑定一个端口,如果端口和集线器相连,集线器上挂了几个机器,那么地址表里就会出现多个mac地址绑定一个端口的情况,转发策略依旧是原来那样,在集线器上略有花样:
- 转发到集线器的信息会在集线器上广播
- 从集线器上某个端口发出的信息,会先在集线器上广播,广播的一个端口是交换机,之后进行转发。

交换机与交换机互联类似于集线器,也会有多个mac地址绑定一个接口的情况,原理大差不差。

广播风暴与STP
如果在以太网中形成环路,那么一条消息在特殊情况下就会绕圈,不停地转发,广播,这就是广播风暴。

掐灭广播风暴的思路也很粗暴,就是消灭环路,把网络变成一个无环图,实际上使用的是STP协议,生成的是一棵树。
STP协议并不改变实际拓扑,只是在链路层的转发上做手脚,逻辑上切断链路,最后把链路网变成树。
可以看到,STP还是挺复杂的,所以从最开始到STP计算生效要经过几分钟,这一段时间叫收敛时间,收敛时间内仍然可能出现广播风暴,所以现在有了一些优化的算法,来减少收敛时间。
虚拟局域网(vlan)
到此为止,交换机使实现了太网的链路层级别扩展,提升显著:
- 从链路层消除了冲突问题,CSMA/CD协议成为历史
- 从半双工变成全双工
- 兼容不同类型的物理层接口
但是以太网仍然存在问题:
- 广播风暴。即使有STP,信息不会兜圈子,也依然可以被有心人利用,输入一个不存在的mac地址,产生大量的广播,浪费资源
- 安全问题。交换机只是在冲突域进行隔离,没有对用户进行身份的隔离
- 管理困难。用户的级别都是一样的,越多越难管理。
本质上这些问题还是因为交换机只能隔离冲突域,不能隔离广播域,一个星型以太网整体是处于一个广播域的。
因为是一个广播域,所以一个信息的目标mac地址不存在时,这条信息可以广播到整个以太网上,如果这种信息很多,就会把以太网资源占用殆尽,这也是广播风暴。

一个以太网中,不同的机器级别不一样,需要区分,而原来的以太网帧不带有区分信息。

这些问题都可以通过vlan实现,即虚拟局域网。
区分不同用户其实就是分组。这就需要更改以太网帧格式,在前面再增加一个vlan字段,缺点是开销大了一点儿,其他的都是优点:
- 降低广播压力,抑制广播风暴
- 提升网络安全性,vlan之间不可以广播,只能点对点单播。
- 便于网络管理,把用户归类,分到一个vlan里
划分vlan的方法很多:
- 基于mac地址。不太容易实现
- 基于端口。常用
- 基于ip子网地址。常用
- 其他。不常用
高速以太网
以太网根据速度区分,有若干档次,对应不同名字:
- 10M以太网。最基础的以太网
- 100BASE-T以太网。又称快速以太网(fast Ethernet),基带速度是100Mb
- Gigabit Ethernet。吉比特以太网
- 10G比特以太网以及更高的。现在不用,战未来。
100BASE-T以太网(Fast Ethernet)
特点:
- 工作方式:全双工,抛弃CSMA/CD协议
- 帧格式:802.3规定的格式,没有vlan
- 物理特性:
- 线缆长度减小到100m(原来是1km)
- 帧间隔调小为原来的十分之一
- 比特率变为10倍
- 简单计算,因为线缆长度缩小十分之一,所以争用期变为十分之一,但是因为比特率是原来10倍,所以争用期数据量不变,最短帧长仍然是64B,以后也就沿用了。
吉比特以太网(Gigabit Ethernet)
特点:
- 工作方式:全双工,兼容半双工
- 帧格式:802.3
- 半双工模式详解
- 半双工下采用CSMA/CD协议,向后兼容。使用载波延伸和分组突发技术来优化效率。
- 载波延伸:将争用时间从64B延长到512B,不够的MAC帧后补充特殊字符。

- 分组突发。如果第一个帧成功地通过载波延伸方式发送,那么代表已经完全占领链路。那么后面的多个短帧之间只需要保证最短时间间隔即可,实现最高效的发送。当然也不能这么一直发,发到1500字节或者稍微多点就停,别影响了别人。

更快的以太网
- 万兆bit
- 帧格式与前面一样,帧长度限制沿用以前的规定
- 介质只使用光纤
- 工作模式只有全双工
使用以太网进行宽带接入(PPPoE)
以太网什么都好,所以很适合接入家庭宽带。但是有一个致命缺点,没有用户身份验证机制,而要实现用户付费就一定要有这个功能。
回顾以太网知识,其实广播的以太网也可以模拟PPP协议,实现身份验证,即PPPoE(PPP over Ethernet)
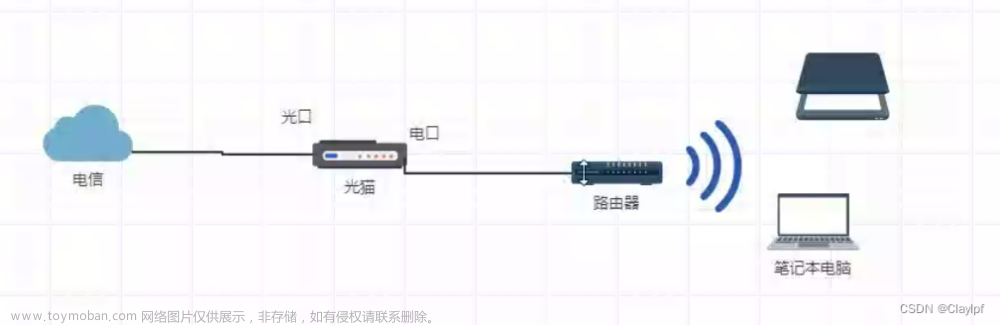
从实际设备来说,其实就是一条光纤入户,首先要通过光猫转化信号。光猫里面记录了用户的身份信息,在光信号转化为电信号的过程里实现身份验证。文章来源:https://www.toymoban.com/news/detail-405964.html
之后的电信号就在家庭内部的以太网上传播了,不需要验证。文章来源地址https://www.toymoban.com/news/detail-405964.html
到了这里,关于计算机网络笔记(方老师408课程)(持续更新)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!