Hadoop高可用架构安装
服务器规划
| Hadoop1 | Hadoop2 | Hadoop3 |
|---|---|---|
| NameNode | NameNode | |
| DataNode | DataNode | DataNode |
| JournalNode | JournalNode | JournalNode |
| DFSZKFailoverController | DFSZKFailoverController | DFSZKFailoverController |
| ResourceManager | ResourceManager | |
| NodeManager | NodeManager | NodeManager |
| JobHistoryServer | JobHistoryServer | |
| ZooKeeper | ZooKeeper | ZooKeeper |
| HBase Master | HBase Master | |
| RegionServer | RegionServer | RegionServer |
ZooKeeper安装
1、修改zookeeper配置文件
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
# 修改该行配置
dataDir=/opt/module/apache-zookeeper-3.7.0/data
# 在该文件最后添加,指定zookeeper集群主机及端口,节点数必须为奇数
server.1=hadoop1:2888:3888
server.2=hadoop2:2888:3888
server.3=hadoop3:2888:3888
2、在/opt/module/apache-zookeeper-3.7.0创建data目录,创建myid
mkdir /opt/module/apache-zookeeper-3.7.0/data
touch myid
vim myid
#文件内容为1
#在myid中设置文件内容即表示当前节点为在zoo.cfg中指定的server.1
3、将zk的目录拷贝到其他几台几台节点服务器
scp -r /opt/module/apache-zookeeper-3.7.0 hadoop2:/opt/module/
#更改zk的data中myi文件内容为2
scp -r /opt/module/apache-zookeeper-3.7.0 hadoop2:/opt/module/
#更改zk的data中myi文件内容为3
4、配置zk的环境变量
vim /etc/profile
#新增
export ZOOKEEPER_HOME=/opt/module/apache-zookeeper-3.7.0
export PATH=ZOOKEEPER_HOME/bin:$PATH
source /etc/profile
5、启动zookeeper
在每个节点上运行
zkServer.sh start
##查看角色
zkServer.sh status
#jps查看进程
Hadoop安装
配置文件
1、core-site.xml
加入zk服务
<configuration>
<!-- hdfs地址,单点模式值为namenode主节点名,本测试为HA模式,需设置为nameservice 的名字-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadddpapp</value>
</property>
<!-- 这里的路径默认是NameNode、DataNode、JournalNode等存放数据的公共目录,也可以单独指定 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/tmp</value>
</property>
<!--加入zk服务,不少于三个节点-->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value>
</property>
<!--设置web访问用户,否则web端浏览hdfs文件目录会提权限不足-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
2、hdfs-site.xml
<configuration>
<!-- hadoop HA 配置开始 -->
<!-- 为namenode集群起一个services name,名字和core-site.xml的fs.defaultFS指定的一致 -->
<property>
<name>dfs.nameservices</name>
<value>hadoopapp</value>
</property>
<!-- nameservice 包含哪些namenode,为各个namenode起名 -->
<property>
<name>dfs.ha.namenodes.hadoopapp</name>
<value>hadoop1,hadoop3</value>
</property>
<!-- 指定hadoop1的namenode的rpc地址和端口号,rpc用来和datanode通讯 -->
<property>
<name>dfs.namenode.rpc-address.hadoopapp.hadoop1</name>
<value>hadoop1:9000</value>
</property>
<!-- 指定hadoop3的namenode的rpc地址和端口号,rpc用来和datanode通讯 -->
<property>
<name>dfs.namenode.rpc-address.hadoopapp.hadoop3</name>
<value>hadoop3:9000</value>
</property>
<!--名为hadoop1的namenode的http地址和端口号,用来和web客户端通讯 -->
<property>
<name>dfs.namenode.http-address.hadoopapp.hadoop1</name>
<value>hadoop1:50070</value>
</property>
<!-- 名为hadoop3的namenode的http地址和端口号,用来和web客户端通讯 -->
<property>
<name>dfs.namenode.http-address.hadoopapp.hadoop3</name>
<value>hadoop3:50070</value>
</property>
<!-- namenode间用于共享编辑日志的journal节点列表/hadoopapp是表示日志存储的在hdfs上根路径,为多个HA可公用服务器进行数据存储,节约服务器成本 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/hadoopapp</value>
</property>
<!-- journalnode 上用于存放edits日志的目录 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/module/hadoop-3.1.3/tmp/dfs/journalnode</value>
</property>
<!-- 指定该集群出现故障时,是否自动切换到另一台namenode -->
<property>
<name>dfs.ha.automatic-failover.enabled.hadoopapp</name>
<value>true</value>
</property>
<!-- 客户端连接可用状态的NameNode所用的代理类 -->
<property>
<name>dfs.client.failover.proxy.provider.hadoopapp</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 一旦需要NameNode切换,使用两方式进行操作,优先使用sshfence -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence
shell(/bin/true)</value>
</property>
<!-- 如果使用ssh进行故障切换,使用ssh通信时指定私钥所在位置 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- ssh连接超时超时时间,30s -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<!-- HA配置结束 -->
<!-- 设置 hdfs 副本数量,这里跟节点数量一致 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
3、mapred-site.xml
<!-- 采用yarn作为mapreduce的资源调度框架 -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 打开Jobhistory -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop1:10020</value>
</property>
<!-- 指定hadoop1作为jobhistory服务器 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop1:19888</value>
</property>
<!--存放已完成job的历史日志 -->
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/history/done</value>
</property>
<!--存放正在运行job的历史日志 -->
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/history/done_intermediate</value>
</property>
<!--存放yarn stage的日志 -->
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/history/staging</value>
</property>
# web上默认最多显示20000个历史的作业记录信息,这里设为1000个。
<property>
<name>mapreduce.jobhistory.joblist.cache.size</name>
<value>1000</value>
</property>
<property>
<name>mapreduce.jobhistory.cleaner.enable</name>
<value>true</value>
</property>
<!-- 一天清理一次 -->
<property>
<name>mapreduce.jobhistory.cleaner.interval-ms</name>
<value>86400000</value>
</property>
<!-- 仅保留最近1周的job日志 -->
<property>
<name>mapreduce.jobhistory.max-age-ms</name>
<value>432000000</value>
</property>
</configuration>
//注意,这里加入yarn执行application(job)的日志记录进程,因为hadoop1和hadoop3做了HA,所以hadoop1和hadoop3节点都配上该jobhistory服务,hadoop2节点不需要。
4 、yarn-site.xml
<configuration>
<!-- 启用yarn HA高可用性 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定resourcemanager的名字,自行命名,跟服务器hostname无关 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>hayarn</value>
</property>
<!-- 使用了2个resourcemanager,分别指定Resourcemanager的地址 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 指定nn节点为rm1 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop1</value>
</property>
<!-- 指定dn2节点为rm2 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop3</value>
</property>
<!-- 指定当前机器nn作为主rm1 -->
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
</property>
<!-- 指定zookeeper集群机器 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value>
</property>
<!-- NodeManager上运行的附属服务,默认是mapreduce_shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
<!-- 禁止启动一个线程检查每个任务正使用的物理内存量、虚拟内存量是否可用 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
5、worker配置
三个节点都设为datanode,在生产环境中,DD不要跟DN放在同一台服务器
hadoop1
hadoop2
hadoop3
6、修改启动/停止脚本
start-dfs.sh和stop-dfs.sh头部增加
#三个节点都需要增加下面内容
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
HDFS_ZKFC_USER=root
HDFS_JOURNALNODE_USER=root
start-yarn.sh和stop-dfs.sh头部增加
# 三个节点都需要增加下面内容
YARN_RESOURCEMANAGER_USER=root
HDFS_DATANODE_SECURE_USER=yarn
YARN_NODEMANAGER_USER=root
7、 启动ZooKeeper进程
zkServer.sh start
8、启动JournalNode进程
hdfs --daemon start journalnode
9、格式化NameNode和ZKFC
在NameNode节点上进行操作
#初始化hdfs
hdfs namenode -format
#初始化zkfc
hdfs zkfc -formatZK
10、启动ZookeeperFailoverController、HDFS、YARN
1、在NameNode主备节点上分别进行操作
hdfs --daemon start zkfc
2、在NameNode主节点上执行
#启动hdfs
start-dfs.sh
#启动yarn
start-yarn.sh
结果:



11、执行FsImage元数据同步命令
hdfs namenode -bootstrapStandby

12、启动jobhistory服务
mapred --daemon start historyserver
13、查看集群组件服务状态
#在namenode主节点上
hdfs haadmin -getServiceState hadoop1
#显示active
hdfs haadmin -getServiceState hadoop3
#显示standby
#查看namenode状态,浏览器打开如下链接
http://hadoop1:50070


#在namenode主节点上,查看RM节点的主备状态
yarn rmadmin -getServiceState rm1
#显示standby
yarn rmadmin -getServiceState rm2
#显示active
#浏览器输入查看rm的状态
http://hadoop1:8088
#由于rm2是主节点,会自动跳转到这个地址
http://hadoop3:8088
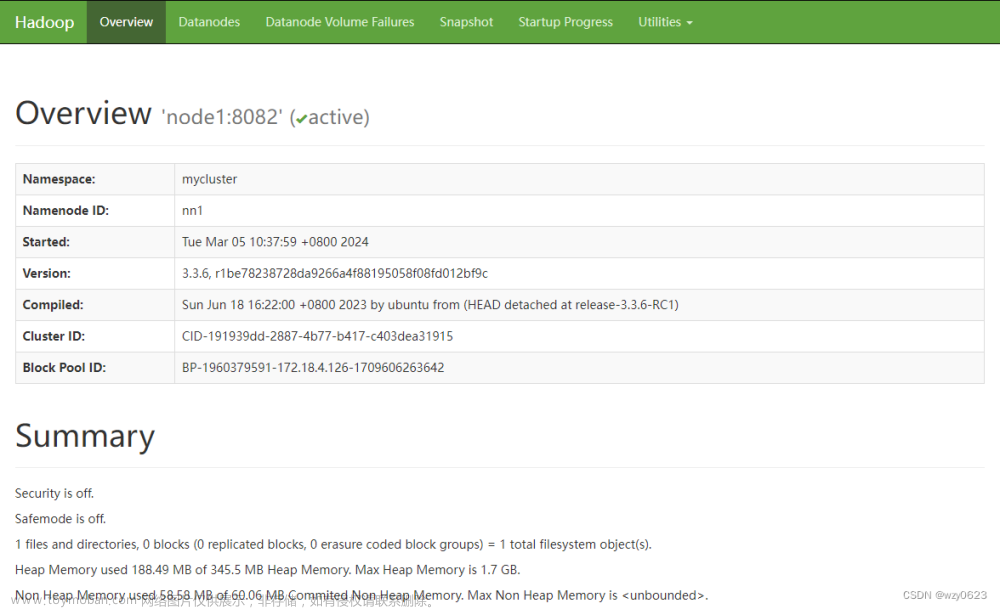
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TJnRcgzo-1648730359731)(C:\Users\Hou\AppData\Roaming\Typora\typora-user-images\image-20220325142028237.png)]
至此负责底层分布式存储的Hadoop HA高可用已经完整实现文章来源:https://www.toymoban.com/news/detail-406621.html
HBase安装
1、配置hbase-env.sh
#增加
export JAVA_HOME=
export HBASE_MANAGES_ZK=false
## 以上配置在三个节点上配置(其实只需在hadoop1和hadoop3 HMaster节点配置),为了避免以后需将hadoop2作为主节点时因之前漏了配置导致启动服务各种报错。
2、配置hbase-site.xml
<configuration>
<!-- 设置HRegionServers共享的HDFS目录,必须设为在hdfs-site中dfs.nameservices的值:hadoopapp,而且不能有端口号,该属性会让hmaster在hdfs集群上建一个/hbase的目录 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoopapp/hbase</value>
</property>
<!-- 启用分布式模式 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 启用分布式模式时,以下的流能力加强需设为false -->
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<!-- 指定Zookeeper集群位置,值可以是hostname或者hostname:port -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop1,hadoop2,hadoop3</value>
</property>
<!-- 指定独立Zookeeper安装路径 -->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/module/zookeeper-3.4.14</value>
</property>
<!-- 指定ZooKeeper集群端口 -->
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
</configuration>
## 以上配置在三个节点配上
3、配置RegionServers
vim regionservers
#填写
hadoop1
hadoop2
hadoop3
## 以上在三个节点配置
4、创建hdfs-site.xml的软链到hbase的conf目录下
## 该操作在三个节点上都要执行,这一环节的配置非常关键,HBase团队也给出相关解释:
## 目的是为了HBase能够同步hdfs配置变化,例如当hdfs副本数改为5时,如果不创建这种配置映射,那么HBase还是按默认的3份去执行。
## 若缺少这个软链接,HBase启动集群服务有问题,部分RegionServer无法启动!
ln -s /opt/module/hadoop-3.1.2/etc/hadoop/hdfs-site.xml /opt/module/hbase-2.4.9/conf/hdfs-site.xml
## 查看结果
ll hdfs-site.xml
e>2181
文章来源地址https://www.toymoban.com/news/detail-406621.html
~~~ shell
## 以上配置在三个节点配上
3、配置RegionServers
vim regionservers
#填写
hadoop1
hadoop2
hadoop3
## 以上在三个节点配置
4、创建hdfs-site.xml的软链到hbase的conf目录下
## 该操作在三个节点上都要执行,这一环节的配置非常关键,HBase团队也给出相关解释:
## 目的是为了HBase能够同步hdfs配置变化,例如当hdfs副本数改为5时,如果不创建这种配置映射,那么HBase还是按默认的3份去执行。
## 若缺少这个软链接,HBase启动集群服务有问题,部分RegionServer无法启动!
ln -s /opt/module/hadoop-3.1.2/etc/hadoop/hdfs-site.xml /opt/module/hbase-2.4.9/conf/hdfs-site.xml
## 查看结果
ll hdfs-site.xml
到了这里,关于Hadoop安装(HA架构)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!