前言
大家好,好久不见,终于又有机会来学习深度学习了, 这次我们通过全球人工智能大赛算法挑战赛的赛道一来学习。
2023全球人工智能技术创新大赛 - 算法挑战赛
赛道一的任务是 通过医疗图像的文字描述来生成医生的诊断描述。这是一个典型的文本生成任务, 因此transformer终于可以要打破bert在我心中的地位, 第一次登上历史舞台了。
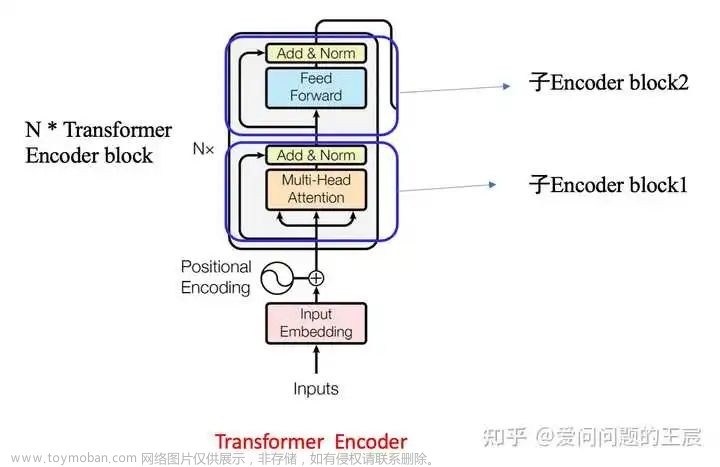
下图很好的展现了transformer,bert和GPT的关系。 transformer包括了一个encoder和一个decoder。 bert因为只需要取特征, 因此用的是encoder这部分, gpt要生成就取了decoder这部分。 事实上, 我认为decoder是更难懂的部分, 超级麻烦。 所以还是得通过推文。 我们这篇文章研究的就是transformer 本身, 即transformer是如何处理一个文字序列的。

transformer的输入:
transformer是做翻译任务起家的, 所以我们的数据需要一段输入,和对应的文字输出。
transformer和bert一样都是把序列作为输入, 最典型的就是一段文字。 这段文字会被分词,之后映射到 input_ids 和 output_ids。 这是我们输入的一段文字和输出的一段文字经过分词和tokenizer后的结果。 (可以先读bert的编码层)。
一文读懂bert结构。_bert模型结构_亮子李的博客-CSDN博客
如果举个例子就是: i love you -> 我爱你
i love you -------- > “i” “love” “you” -------- > "999" , "777", "456"
我爱你 -------- >“我”, “爱”, “你” ------> "100" , "256", "333"
即先分词, 后用一个固定的数字来替换文字。 之后输出需要加上一些特殊的token,也就是特殊的id。
如:
sos_id , eos_id, pad_id。
sos_id: 输出的起始字符, 比如可以用1表示。
eos_id: 输出的结束字符, 比如可以用2表示。
pad_id: 填充id。 如果输入输出长度不够规定的标准长度, 就填充为0 。 (一个数据集一般会规定一个统一的处理长度。)
如假如我们要求处理长度 输入长度为8, 输出长度为6
那么:
i love you -------- > "999" , "777", "456" --- "999" , "777", "456", "0", "0", "0", "0", "0"
我爱你 -------- >“我”, “爱”, “你” ------> "1", "100" , "256", "333" ,"2" ,"0"
这就是transformer的输入。 为什么输出要这样处理, 具体请搜索李宏毅老师的课程。 self-attention。

从这里代码可以看出, transformer就包含两个结构 ,encoder和decoder。
transformer的encoder:
关于self-attention 机制 ,你需要先读下面这篇博客。
一文读懂bert结构。_bert模型结构_亮子李的博客-CSDN博客
transformer的encoder基本和bert差不多。 我们象征性走一下流程。

我们首先要对输入进行嵌入embedding。 
看forward 即运行的第一句。
posit_index 即位置编码。 要转为位置embedding。 这里是可学习的全连接层: nn.linear(句子长度, 编码长度)。 有的时候是固定函数算的,而不是可学习的。
padding_mask 即 输入的有效位置, 为1的地方表示无效。
token_embedding 即词embedding。
attn_mask 全为0 . 大小为(输入长度, 输入长度) 一个方阵。
处理后变为embedding, 之后把他们全部输入到encoder中去。
值得注意的是与bert的不同之处:
1, 这里要把输入转换维度 不是很懂。 后面感觉确实没啥用意义。在multi attention head那里同意变不就行了?
2, 没有用nn.linear来创建全连接, 而是定义了参数w和b直接用计算来做。
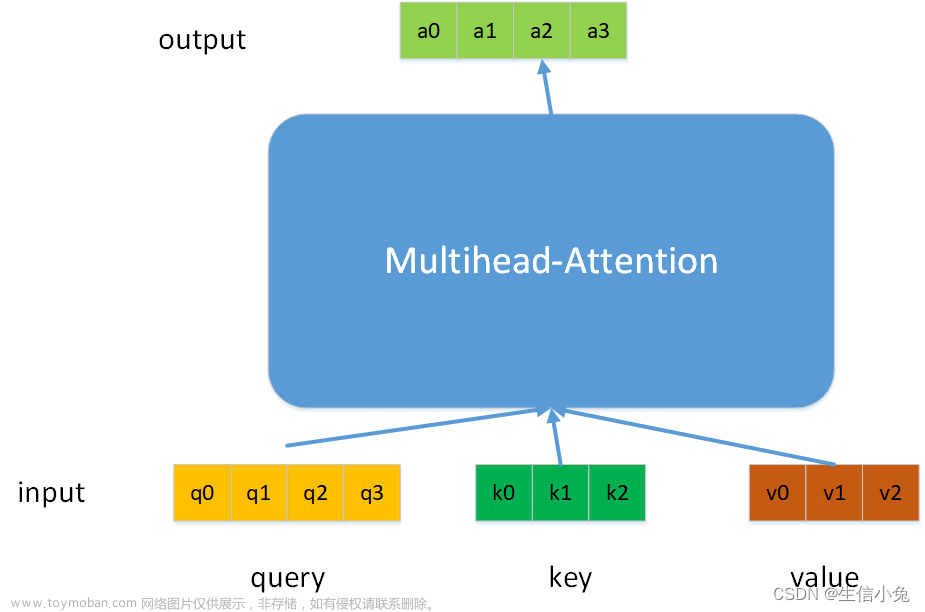
q, k, v = linear(query, in_proj_weight, in_proj_bias).chunk(3, dim=-1)q,k,v用chunk函数创建。 注意 这里的q大小是( length* batch* dim) 即长度,batch大小,编码维度。而w大小为 (3*dim,dim) w和q相乘后会变为 ( length* batch* 3×dim)
.chunk表示分块。 沿着dim 也就是最后一维 3*dim这一维。 分成三块 也就是Q,K,V。 真是麻烦这样子写,
transformer的decoder:

transformer 输入有两个 , 一个是encoder输出的特征,一个是目标target , 也就是输出。
看看decoder定义了哪些东西:
 前几个说过了。
前几个说过了。
d 就是编码维度。
n_token 是输入的值,即词表的大小。
同样有解码器的位置编码 posit_embedding, 和编码器不共享。
还附带输入的位置编码。 source_posit_embedding。 这个等会看看什么作用,
定义了输出的linear
self.output = nn.Linear(d, n_token)
然后看前向。

先来个arange的下标列表, 之后用linear得到位置编码。 再加上token编码。 这里caption就是输出。
attn_mask = self.generate_square_subsequent_mask(caption.shape[1]).to(caption.device)
这一句用来生成一个对角矩阵, 大小为输出的 length*length 一个阵。 A[i][j]位置的数字可以理解为第i个token 对第j个token的注意力, 也就是i有多么关注j。 这里设计了一个下三角矩阵,例:
1,-inf,-inf,-inf
1, 1, -inf,-inf
1, 1, 1, -inf
1, 1, 1, 1
也就是说 第一个token 对后面的token都不关注, 这是为了完成输出时,每个token只看前面的token,不看后面的这个功能。 因为生成任务,只能根据前面生成的来生成后面的。

经过两次维度转换进入decoder。 维度转换的必要性没那么强。
注意和encoder的区别。 encoder只需要输入src 这里加了target,

这里是decoder的核心。 看到一个norm1 是让输出tgt通过自注意力层进行编码。 其他的与普通注意力都一样。
attn_mask = attn_mask.masked_fill(key_padding_mask, float("-inf"))
注意这一句, 表示的是将attn_mask 中那些 key_padding_mask为1的位置下标对应的值都改为“-“inf” 主要是因为 key_padding_mask为1的地方,表示是实际上没有输出 ,全是我们填充的,所以变为负无穷,这样softmax后就为0了。
所以第一句就是用self-attention提取一下target的特征。 而且是遮盖上三角的方式,
来到第二句

这一句同样是自注意力机制处理, 不过不同的是要同时输入 src和tgt的特征。

看sa和mha的区别。 self_attn 和multihead_attn是一模一样的。 主要在于是输入换了。
前三个参数对应的是q,k,v 也就是说, sa是全部用 tgt来产生 q,k,v
而mha是由tgt产生 q ,用输入的特征src来产生k,和v
也就是用tgt来询问输入的特征 问应该给每个输入的token'多少注意力。
加上注意力是下三角形式的。 这样就可以做到, 用第一个词来预测下一个, 用前两个预测第三个。

来到第三句, 就是一个mlp。 之后经过多层att 得到输出。

output即一个全连接层。 从特征长度到词表长度。
至此得到decoder也就是transformer的输出吗, 也就是预测的结果。
预测时。 首先通过encoder得到输入的特征。

在预测时, 是没有目标值的。 也就是target。 这里的caption就是本来output的位置,

可以看到forward直接走的infer函数。 我们也进入infer。

创建两个矩阵, 第一个是batch*1 第二个就是batch。 看看干嘛的。

这句的意思是 从infer在返回forward。 但是不同的是outputs只是一个256*1的矩阵。 也就是只有一个token。 里面的值全部为1, 也就是说代表着sos_id 。 即意思就是用开始字符推断第一个字。
当长度为1的target进入decoder后。

这些的长度全部变为1。 也就是说,假设某轮target的长度为 t, 位置坐标只产生输入长度为t的位置。 编码只编t个token的。

在进入 decoder后与之前一样的三步。
可以看下在交叉注意力时的维度变化。

因为这里的q是tgt提供的, 而k和v是输入提供的, 所以要走下面了。
先把计算qkv的矩阵w拆为两个, 第一个是dim*dim 第二个是2×dim*dim。 dim就是编码维度。

看返回是两个相加。 看第一个。 用q对应的linaer权重q_w去处理q。 因为w是方阵, 所以q保持原来的shape不变。 依然为batch* t* dim 。 (不过这里batch和t在代码里换了位置,我们不管)。 所以前面这个是返回去是q, 后面chunk出来k和v。
现在q大小为 batch* t* dim ,k和v的大小为 batch*l_src*dim。
q和K的转置乘得到 batch* t*l_src 再用这个 去乘以V得到 batch* t* dim 正好可以作为输出。

得到输出后,取最后一个的输出。

这一句就是要来判断是否输出结束了。
首先看这个batch的每一个预测是否和结束id eos相等。 用
torch.ne(outputs[:,-1], eos_id).long() 这个函数。
所以这句代码的意思就是 保持前面每一轮是否结束的标签, 判断新的一轮是否结束了。 取minimum相当于一个和以前的合并。
这里取这个如果not over 全为0 说明全部结束了 就结束这一轮的预测。
这样就完成预测了。 但是没有截断过程么 。 我真的好奇。

文章来源:https://www.toymoban.com/news/detail-406805.html
好了 原来截断在后处理这里。 这里有一个转换函数, 后处理时, 如果遇到pad或者截止符号, 就停止输出, 这样就对了。文章来源地址https://www.toymoban.com/news/detail-406805.html
到了这里,关于transformer模型,文本生成任务。 self-attention结构的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!