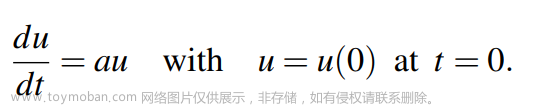前言
SEED数据集是常用的脑电信号情绪识别数据集,在该数据集的Preprocessed_EEG文件夹中是原始的脑电数据,在ExtractedFeatures文件夹中是官方提取特征后的数据(提取了多种特征可直接使用)。
既然官方已经把特征提取好了为什么还要自己做特征提取?
- 官方并没有开源提取特征的代码。
- 为了处理其他数据集或者自己的数据。
- 微分熵(de)作为脑电中非常好的脑电特征目前在网上却很难找到实现的放发,收费的代码大多也是错的或者是不完整的。
带通滤波器
人类的脑电图中脑波频率可以在0.5到几十赫兹,通常按照频率进行分类以表示各种成分:
δ波(0.5-4Hz) ,θ波(4-8Hz),α波(8-13Hz),β波(13-32Hz),γ波(32-50Hz),这个地方很多人写的频率范围都不大一样但也没有很大的差别。我们这里使用带通滤波器来实现频段的提取。
带通滤波器代码实现
from scipy import signal
fStart = [0.5, 4, 8, 13, 32] # 这里是起始频率
fEnd = [4, 8, 13, 32, 50] # 这里是终止频率
results = []
for band_index, band in enumerate(fStart):
b, a = signal.butter(4, [fStart[band_index]/fs, fEnd[band_index]/fs], 'bandpass') # 配置滤波器 4 表示滤波器的阶数
result = signal.filtfilt(b, a, data) # data为要过滤的信号
results.append(result)
最终提取到的五个频段都会存入 results 中。
微分熵
微分熵实际上是香农熵在连续信号上的推广
香农熵:对概率分布中的不确定性总量进行量化,公式如下:
微分熵:对连续性随机变量的概率分布中的不确定性总量进行量化,公式如下: 文章来源:https://www.toymoban.com/news/detail-407079.html
文章来源:https://www.toymoban.com/news/detail-407079.html
微分熵代码实现
def compute_DE(signal):
variance = np.var(signal, ddof=1) # 求得方差
return math.log(2 * math.pi * math.e * variance) / 2 # 微分熵求取公式
这个代码看起来貌似和上面的公式不一样,实际上这个是微分熵的化简式。文章来源地址https://www.toymoban.com/news/detail-407079.html
完整代码(SEED数据集)
from scipy.io import loadmat
from sklearn.preprocessing import MinMaxScaler
from scipy import signal
import numpy as np
import math
import os
def compute_DE(signal):
variance = np.var(signal, ddof=1) # 求得方差
return math.log(2 * math.pi * math.e * variance) / 2 # 微分熵求取公式
def load_data():
data_dir = "../SEED/Preprocessed_EEG/" # 这里设置为数据集相应的路径
fs = 200
fStart = [0.5, 4, 8, 13, 32]
fEnd = [4, 8, 13, 32, 50]
channel = [3, 7, 13, 23] # 这里我选取了四个导联进行训练(AF3,F3,F8,T7)
filename_label = "label"
label = loadmat(data_dir + filename_label)
label = label["label"][0]
datasets_X, datasets_y = [], []
for filename_data in os.listdir(data_dir):
if filename_data in ["label.mat", "readme.txt"]:
continue
data_all = loadmat(data_dir + filename_data)
scenes = list(data_all.keys())[3:]
for index, scene in enumerate(scenes):
dataset_X = []
data = data_all[scene][channel] # 如果想用上全部导联进行训练则将该行改为data = data_all[scene]
scaler = MinMaxScaler()
data = scaler.fit_transform(data) # 归一化
for band_index, band in enumerate(fStart):
b, a = signal.butter(4, [fStart[band_index]/fs, fEnd[band_index]/fs], 'bandpass') # 配置滤波器 4 表示滤波器的阶数
filtedData = signal.filtfilt(b, a, data) # data为要过滤的信号
filtedData_de = []
for lead in range(len(channel)):
filtedData_split = []
# 计算微分熵
for de_index in range(0, filtedData.shape[1] - fs, fs):
filtedData_split.append(compute_DE(filtedData[lead, de_index: de_index + fs]))
# 这里将每个样本大小进行统一,如果想通过滑动窗口截取样本可在这一行下面自行修改
if len(filtedData_split) < 265:
filtedData_split += [0.5] * (265-len(filtedData_split))
filtedData_de.append(filtedData_split)
filtedData_de = np.array(filtedData_de)
dataset_X.append(filtedData_de)
datasets_X.append(dataset_X)
datasets_y.append(label[index])
datasets_X, datasets_y = np.array(datasets_X), np.array(datasets_y)
if __name__ == "__main__":
datasets_X, datasets_y = load_data()
print(datasets_X.shape)
print(datasets_y.shape)
到了这里,关于脑电数据集提取微分熵特征(以SEED数据集为例)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!