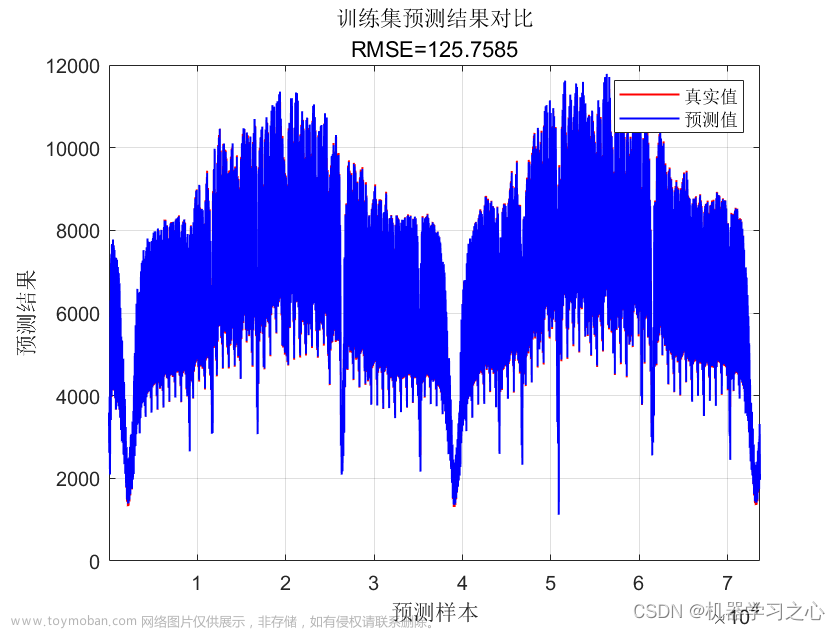
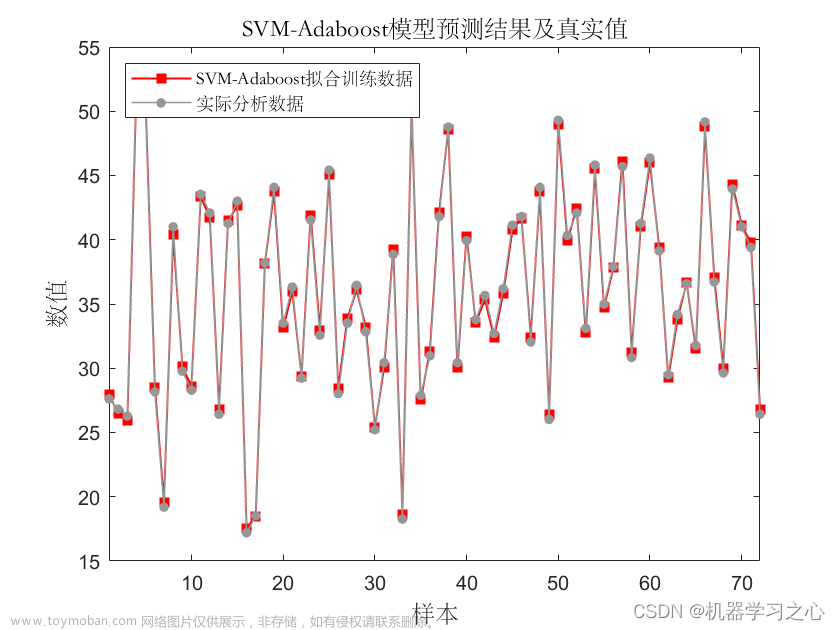
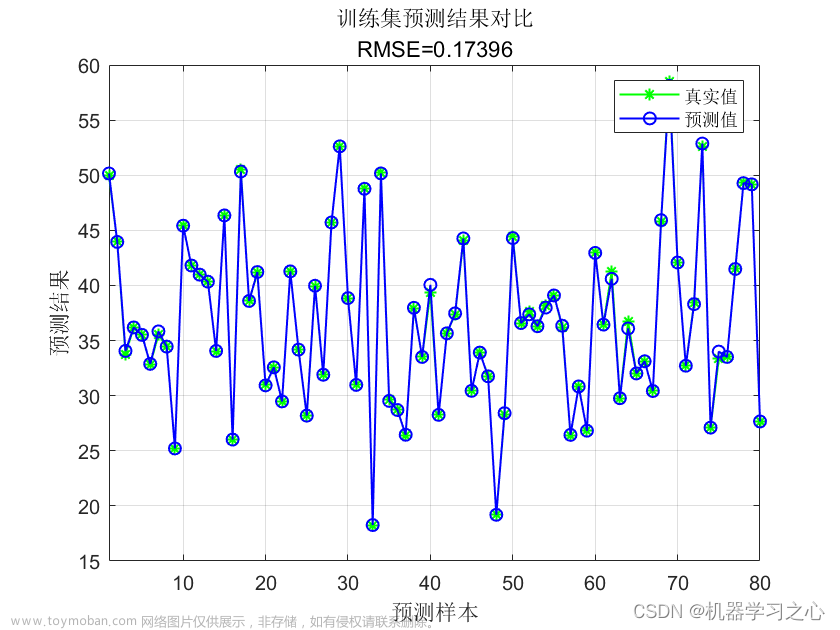
研究背景
支持向量机回归(Support Vector Regression, SVR)算法是一种经典的回归算法,其研究历史可以追溯到20世纪90年代。以下是一些关于SVR算法的经典论文:
Vapnik, V. N. (1995). The nature of statistical learning theory (Vol. 1). Springer.
这本书介绍了支持向量机的理论和算法,为SVR算法的发展提供了重要的基础。
Smola, A. J., & Schölkopf, B. (2004). A tutorial on support vector regression. Statistics and computing, 14(3), 199-222.
这篇论文详细介绍了SVR算法的理论和实现方法,为学习和掌握SVR算法提供了重要的参考。
Drucker, H., Wu, D., & Vapnik, V. N. (1997). Support vector regression machines. In Advances in neural information processing systems (pp. 155-161).
这篇论文是SVR算法的奠基之作,提出了SVR算法的理论和算法,为后来的SVR算法提供了理论基础。
Zhang, Q., & Benveniste, A. (2005). Wavelet-based support vector regression for nonlinear system identification. IEEE Transactions on neural networks, 16(1), 235-243.
这篇论文介绍了基于小波变换的SVR算法在非线性系统识别中的应用,为SVR算法在实际应用中的发展提供了重要的参考。
Liu, Y., & Shen, Z. (2019). An improved support vector regression based on PSO and gradient descent. Soft Computing, 23(15), 6029-6045.
这篇论文提出了基于粒子群优化和梯度下降的改进型SVR算法,为SVR算法的发展和改进提供了重要的思路。
这些论文为SVR算法的研究和应用提供了重要的参考和指导,对于学习和掌握SVR算法具有重要意义。
原理说明
支持向量机回归(Support Vector Machine Regression, SVMR)是一种基于支持向量机的回归算法,它与支持向量机分类(Support Vector Machine Classification, SVMC)相似,但在目标函数和损失函数的定义上有所不同。
目标函数
与SVMC不同,SVMR的目标是最小化模型预测值与真实值之间的差异,即最小化预测值与真实值之间的误差平方和(Sum of Squared Errors, SSE),同时还要最大化间隔,以确保模型的泛化能力。
假设训练集为D={(x1,y1), (x2,y2), …, (xn,yn)},其中xi∈R^d为第i个样本的特征向量,yi∈R为第i个样本的真实值。则SVMR的目标函数可以表示为:
min(w, b) 1/2 ||w||^2 + C ∑(yi - f(xi))^2
其中,w是权重向量,b是偏置项,C是正则化参数,||w||^2是权重向量的L2范数,f(xi) = w^Txi + b是模型预测值。
目标函数的第一项表示最小化权重向量的L2范数,以防止过拟合。第二项是一个平方损失函数,表示最小化预测值与真实值之间的误差平方和。C是正则化参数,它用于平衡最小化误差和最小化权重向量L2范数之间的权衡。C越大,模型越倾向于最小化误差,C越小,模型越倾向于最小化权重向量的L2范数。
约束条件
与SVMC类似,SVMR的优化问题也存在约束条件。训练样本的真实值yi与预测值f(xi)之间的差异需要小于等于ϵ,即|yi - f(xi)| ≤ ϵ,ϵ为一个给定的容忍度。这个约束条件可以表示为:
-ϵ ≤ yi - f(xi) ≤ ϵ
将约束条件代入目标函数,可以得到SVMR的对偶问题:
min α 1/2 α^T Q α - e^T α
subject to: -ϵ ≤ y - Qα ≤ ϵ
其中,α是拉格朗日乘子向量,Q是Gram矩阵,e是全1向量,y是包含训练集真实值的向量。
模型预测
训练完成后,可以使用模型进行预测。给定一个新的样本特征向量x,模型预测值f(x)可以表示为:
f(x) = ∑αiyiK(xi,x) + b
其中,K(xi,x)是核函数,可以是
线性核函数K(xi,x) = xi^Tx,多项式核函数K(xi,x) = (γ(xiTx)+r)d,径向基函数(Radial Basis Function, RBF)核函数K(xi,x) = exp(-γ||xi-x||^2)等。
b是偏置项,可以通过以下公式计算:
b = (1/|S|) ∑(yi - ∑αiyiK(xi,x))
其中,S是支持向量集合,包含那些满足0 < αi < C的样本。|S|表示支持向量的数量。
总结
SVMR是一种基于支持向量机的回归算法,目标是最小化模型预测值与真实值之间的误差平方和,同时最大化间隔。通过引入拉格朗日乘子和核函数,可以将SVMR的优化问题转化为对偶问题,从而使用凸优化方法进行求解。模型预测值可以使用核函数进行计算,并通过支持向量集合中的样本来计算偏置项。SVMR在处理非线性回归问题时具有较好的性能。
公式推导
支持向量机回归(Support Vector Regression,SVR)是一种基于支持向量机的回归算法,通过寻找最大化间隔的超平面来进行回归预测。在SVR中,假设输入数据集为{(xi, yi)|xi∈R^n, yi∈R},其中xi是n维的特征向量,yi是对应的标签。
目标函数
对于回归问题,目标是最小化模型预测值与真实值之间的误差平方和,同时最大化间隔。因此,SVR的目标函数可以表示为:
min_(w,b,ξ,ξ*) 1/2 w^Tw + C ∑(ξ+ξ*)
其中,w是超平面的法向量,b是偏置项,ξ和ξ*是松弛变量,用于处理不可分情况。C是一个正则化参数,用于平衡最大化间隔和最小化误差的权重。这里使用的是L2正则化。
约束条件
为了使SVR的预测更加准确,需要在目标函数中引入约束条件。对于每个样本(xi, yi),需要满足以下约束条件:
yi - w^Txi - b <= ε + ξi
w^Txi + b - yi <= ε + ξi*
其中,ε是一个正值,表示对误差的容忍程度。ξi和ξi是非负松弛变量,用于处理不可分情况。同时,对于所有的i和i,还需要满足以下约束条件:
ξi >= 0, ξi* >= 0
对偶问题
通过引入拉格朗日乘子α和α*,可以将SVR的优化问题转化为对偶问题。对偶问题的目标是最大化拉格朗日函数:
L(w,b,ξ,ξ*,α,α*) = 1/2 w^Tw + C ∑(ξ+ξ*) - ∑(αi(yi-wTxi-b-ξi)-αi*(yi-wTxi-b+ξi*))
其中,α和α*是拉格朗日乘子,用于处理约束条件。最终的对偶问题可以表示为:
max_α,α* ∑(αi - αi*) - 1/2 ∑∑(αiαjK(xi,xj))
s.t. 0 <= αi,αi* <= C
∑(αi - αi*)yi = 0
其中,K(xi,xj)是核函数,用于将样本映射到高维空间进行计算。α和α*的约束条件保证了拉格朗日乘子是非负的,同时不超过正则化参数C的限制。最后一个约束条件保证了预测结果的线性性。
模型预测
在求解对偶问题后,可以通过求解拉格朗日乘子得到超平面和偏置项,从而进行模型预测。对于新的输入特征向量x,预测值可以表示为:
f(x) = ∑(αi - αi*)K(xi,x) + b
其中,K(xi,x)是核函数,表示输入特征向量xi和新的输入特征向量x之间的相似度。超平面的法向量w可以表示为:
w = ∑(αi - αi*)xi
由于大多数αi都等于0,因此只有少数的支持向量的拉格朗日乘子不等于0,它们决定了超平面和偏置项的位置。预测结果只与支持向量有关,因此SVR可以很好地处理高维数据集和非线性问题。
核函数
在SVR中,核函数是非常重要的一个概念,它将输入特征向量映射到高维空间进行计算。常用的核函数包括线性核函数、多项式核函数、径向基函数(Radial Basis Function,RBF)核函数等。不同的核函数对应不同的映射方式,适用于不同的问题。例如,线性核函数适用于线性问题,RBF核函数适用于非线性问题。选择合适的核函数可以提高SVR的预测性能。文章来源:https://www.toymoban.com/news/detail-407211.html
以上就是SVR算法的原理和公式推导过程。文章来源地址https://www.toymoban.com/news/detail-407211.html
代码示意
import numpy as np
import random
class SVR:
def __init__(self, C=1, kernel='linear', epsilon=0.1, max_iter=100):
self.C = C # 惩罚因子
self.kernel = kernel # 核函数类型
self.epsilon = epsilon # 允许的误差
self.max_iter = max_iter # 最大迭代次数
def fit(self, X, y):
n_samples, n_features = X.shape
# 根据核函数类型选择相应的核函数
if self.kernel == 'linear':
self.kernel_func = self._linear_kernel
elif self.kernel == 'rbf':
self.kernel_func = self._rbf_kernel
else:
raise ValueError('Invalid kernel type')
# 初始化拉格朗日乘子 alpha 和偏置 b
alpha = np.zeros(n_samples)
b = 0
# 迭代训练模型
for _ in range(self.max_iter):
# 随机选择一个样本
i = random.randint(0, n_samples - 1)
# 计算样本的预测值和误差
y_pred = self.predict(X[i, np.newaxis])
error = y_pred - y[i]
# 计算拉格朗日乘子 alpha[i] 的上下界
if y[i] == y_pred:
L = max(0, alpha[i] - self.C)
H = min(self.C, alpha[i])
else:
L = max(0, alpha[i])
H = min(self.C, self.C + alpha[i])
# 如果上下界相等,则跳过本次迭代
if L == H:
continue
# 计算样本 i 的核函数值
K_ii = self.kernel_func(X[i, np.newaxis], X[i, np.newaxis])
# 计算样本 i 与其它样本的核函数值
K_ij = self.kernel_func(X[i, np.newaxis], X)
# 计算拉格朗日乘子 alpha[j] 的新值
eta = 2 * K_ij - K_ii
new_alpha_j = alpha[i] - y[i] * error / eta
# 修剪拉格朗日乘子 alpha[j]
if new_alpha_j > H:
new_alpha_j = H
elif new_alpha_j < L:
new_alpha_j = L
# 如果 alpha[j] 变化太小,则跳过本次迭代
if abs(alpha[i] - new_alpha_j) < 1e-5:
continue
# 更新拉格朗日乘子 alpha[j] 和偏置 b
alpha[i] = new_alpha_j
alpha[j] = alpha[j] + y[j] * y[i] * (alpha[i] - new_alpha_j)
b1 = b - error - y[i] * (alpha[i] - alpha[i]) * K_ii - y[j] * (alpha[j] - alpha[j]) * K_ij
到了这里,关于支持向量机回归的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!