嗨喽,大家好,我是程序猿老王,程序猿老王就是我。
今天给大家讲一讲C语言十大经典排序算法原理与实现。
目录
一、排序算法背景
二、十大经典排序算法的由来
三、十大经典排序算法的复杂度
四、十大经典排序算法讲解
1.冒泡排序(Bubble Sort)
2.选择排序(Selection Sort)
3.插入排序(Insertion Sort)
4.快速排序(Quick Sort)
5.归并排序(Merge Sort)
6.希尔排序(Shell Sort)
7.堆排序(Heap Sort)
8.计数排序(Counting Sort)
9.桶排序(Bucket Sort)
10.基数排序(Radix Sort)
一、排序算法背景
排序算法是计算机科学领域的一个经典问题,其由来可以追溯到早期的计算机科学发展历程中。
在20世纪50年代初期,计算机科学家John von Neumann提出了一种新的计算模型——随机访问存储器(Random Access Memory, RAM)模型,它将计算机的内存看作是一个有限的线性数组,并提出了一种称为“合并排序”的排序算法,该算法是一种分治算法,可以有效地对一个大规模的无序数据集合进行排序。
在随后的几十年中,计算机技术和计算机科学不断发展,出现了更多的排序算法,例如快速排序、堆排序、归并排序、桶排序等,这些算法的提出和发展,使得排序问题得到了更加深入和全面的研究。
排序算法不仅是计算机科学领域中的一个重要问题,也是实际应用中的一个经典问题,例如在数据库查询中、图像处理中、网络搜索中等领域都有广泛的应用。随着数据量的不断增加和计算能力的提高,如何高效地对大规模数据进行排序也成为了一个重要的挑战。因此,排序算法的研究和发展仍然具有重要的理论和实际意义。
二、十大经典排序算法的由来
- 冒泡排序(Bubble Sort)
冒泡排序最早由美国计算机科学家、《计算机程序设计艺术》的作者之一唐纳德·克努斯(Donald Knuth)在他的著作《The Art of Computer Programming》中提出。
- 选择排序(Selection Sort)
选择排序最早由美国计算机科学家、图灵奖得主之一约翰·霍普克罗夫特(John Hopcroft)和罗伯特·塔瑟斯(Robert Tarjan)在1976年提出。
- 插入排序(Insertion Sort)
插入排序的概念最早由克努斯在1962年提出,但其实它早在1945年由约翰·冯·诺伊曼(John von Neumann)在他的报告《First Draft of a Report on the EDVAC》中就已经出现了。
- 快速排序(Quick Sort)
快速排序最早由英国计算机科学家托尼·霍尔(Tony Hoare)在1960年提出。
- 希尔排序(Shell Sort)
希尔排序最早由美国计算机科学家唐纳德·希尔(Donald Shell)在1959年提出。
- 归并排序(Merge Sort)
归并排序最早由约翰·冯·诺伊曼在1945年提出,但其实它早在1845年由赫尔曼·冯·亥姆霍兹(Hermann von Helmholtz)在他的日记中就已经描述了。
- 堆排序(Heap Sort)
堆排序最早由美国计算机科学家约翰·威廉·詹姆斯·威廉姆斯(J.W.J. Williams)在1964年提出。
- 计数排序(Counting Sort)
计数排序最早由美国计算机科学家哈罗德·霍普金斯(Harold H. Seward)在1954年提出。
- 桶排序(Bucket Sort)
桶排序的概念最早由约翰·冯·诺伊曼在1945年提出,但其实它早在1938年由埃米尔·高德堡(Emil Gumbel)在他的论文《Statistical Theory of Extreme Values and Some Practical Applications》中就已经出现了。
- 基数排序(Radix Sort)
基数排序最早由美国计算机科学家赫尔曼·霍普(Herman Heaps)在1961年提出。
三、十大经典排序算法的复杂度
时间复杂度和空间复杂度如下:
| 排序算法 | 平均时间复杂度 | 最坏时间复杂度 | 最好时间复杂度 | 空间复杂度 |
|---|---|---|---|---|
| 冒泡排序 | O(n^2) | O(n^2) | O(n) | O(1) |
| 选择排序 | O(n^2) | O(n^2) | O(n^2) | O(1) |
| 插入排序 | O(n^2) | O(n^2) | O(n) | O(1) |
| 希尔排序 | O(nlogn) 或 O(n^2) | O(n^2) | O(nlogn) | O(1) |
| 归并排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(n) |
| 快速排序 | O(nlogn) | O(n^2) | O(nlogn) | O(logn) |
| 堆排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(1) |
| 计数排序 | O(n + k) | O(n + k) | O(n + k) | O(k) |
| 桶排序 | O(n + k) | O(n^2) | O(n) | O(n + k) |
| 基数排序 | O(n * k) | O(n * k) | O(n * k) | O(n + k) |
其中,n 表示待排序元素的个数,k 表示数据的范围。
需要注意的是,虽然快速排序的平均时间复杂度最优,但是在最坏情况下的时间复杂度为 O(n^2),需要进行优化。而计数排序、桶排序和基数排序虽然具有线性时间复杂度,但是需要满足一定的条件才能使用,如元素值必须是非负整数等。在实际应用中,根据不同的需求和数据特点选择不同的排序算法。
四、十大经典排序算法讲解
1.冒泡排序(Bubble Sort)
冒泡排序是一种简单的排序算法,其基本思想是通过相邻元素的比较和交换,使较大的元素逐渐往后移动,从而实现排序。该算法的名称源于这样的过程:在排序过程中,较小的元素像气泡一样逐渐浮到数组的顶部。
冒泡排序的具体实现过程如下:
- 从数组的第一个元素开始,依次比较相邻的两个元素,如果前面的元素大于后面的元素,则交换它们的位置,使得较大的元素逐渐往后移动。
- 对数组中的所有元素都进行如上操作,除了最后一个元素,因为最后一个元素已经是最大的元素了。
- 重复步骤1和步骤2,直到所有元素都被排序好。
下面是冒泡排序的C语言实现示例:
void bubbleSort(int arr[], int n) {
int i, j;
for (i = 0; i < n-1; i++) {
// 内层循环从0开始,每次循环的最大索引值为n-i-1
for (j = 0; j < n-i-1; j++) {
// 如果相邻元素的大小关系不满足排序要求,则交换它们的位置
if (arr[j] > arr[j+1]) {
int temp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = temp;
}
}
}
}
2.选择排序(Selection Sort)
选择排序是一种简单的排序算法,其基本思想是每次从待排序的元素中选出最小(或最大)的一个元素,放到已排序的序列的末尾,直到所有元素都排序完毕。
选择排序的具体实现过程如下:
- 从待排序序列中选择最小的元素,将其放到已排序序列的末尾。
- 从待排序序列中选择次小的元素,将其放到已排序序列的末尾。
- 重复上述过程,直到所有元素都已排序完毕。
下面是选择排序的C语言实现示例:
void selectionSort(int arr[], int n) {
int i, j, min_idx, tmp;
// 外层循环表示已排序部分的末尾索引,从0开始
for (i = 0; i < n-1; i++) {
// 内层循环从未排序部分中找到最小的元素
min_idx = i;
for (j = i+1; j < n; j++) {
if (arr[j] < arr[min_idx]) {
min_idx = j;
}
}
// 交换最小元素和已排序部分的末尾元素
temp = arr[i];
arr[i] = arr[min_idx];
arr[min_idx] = temp;
}
}
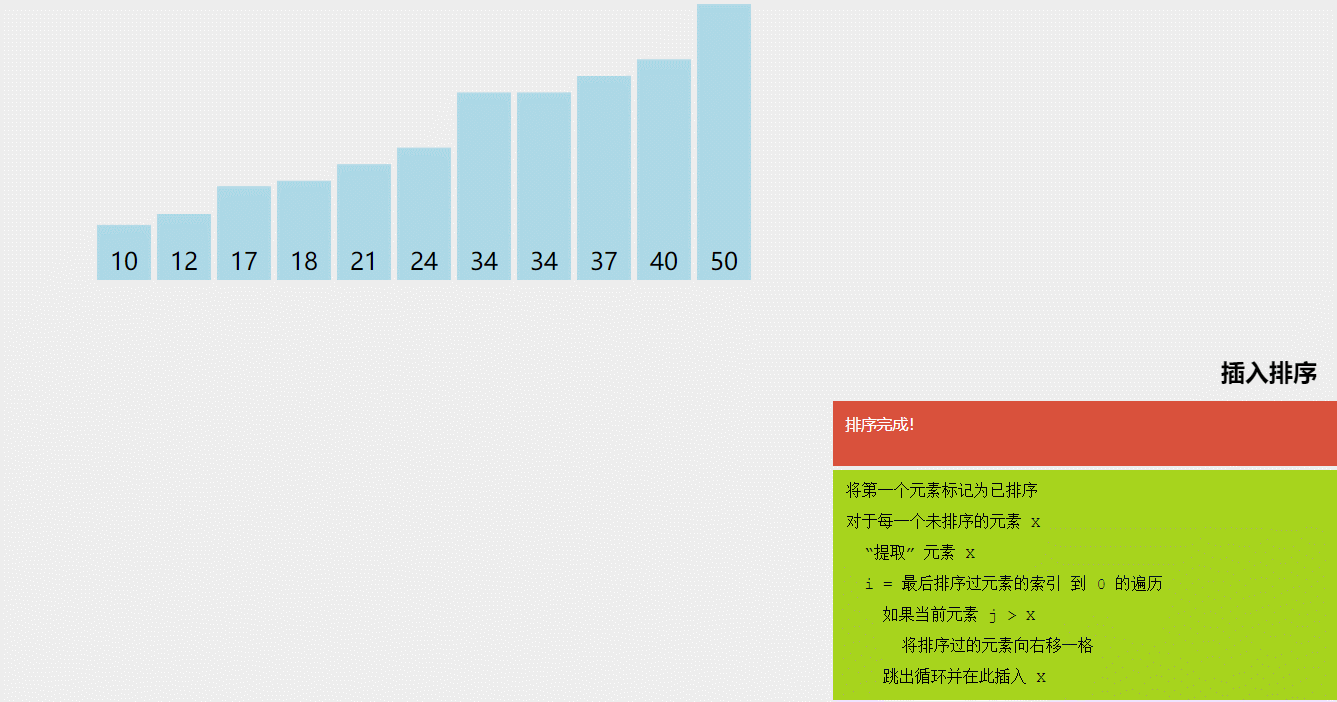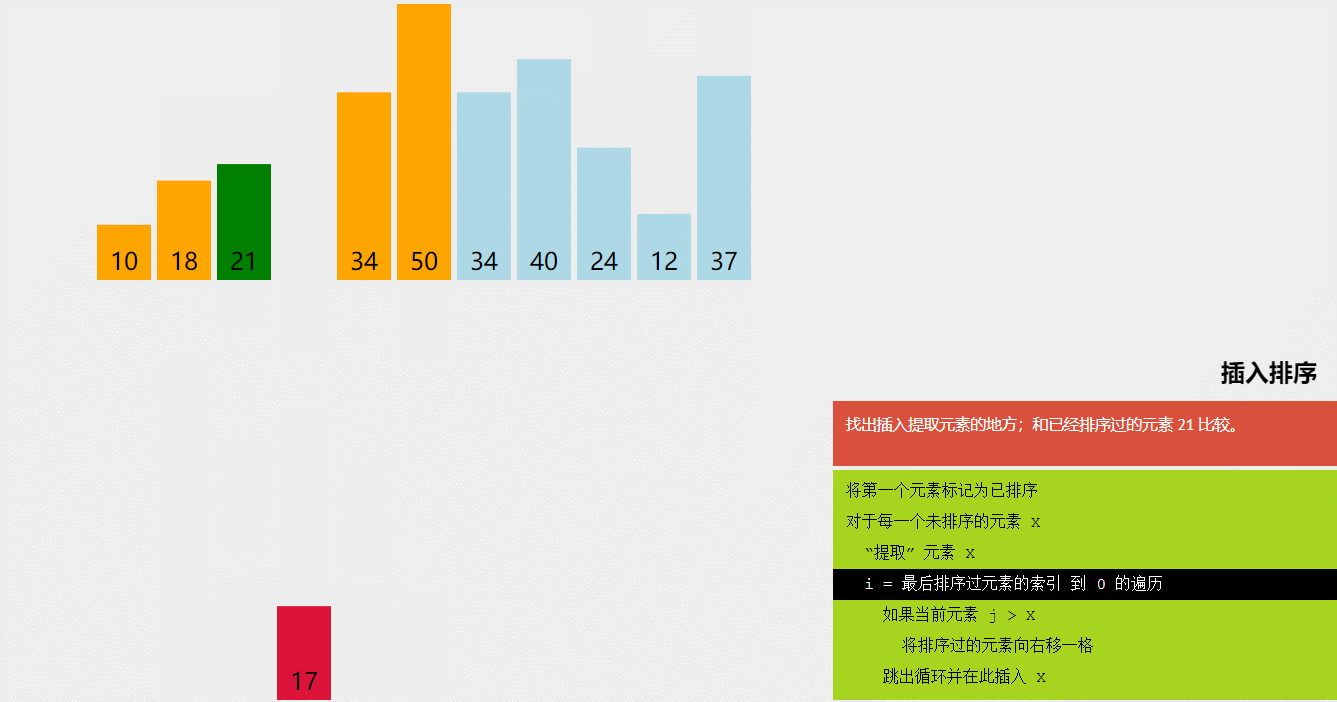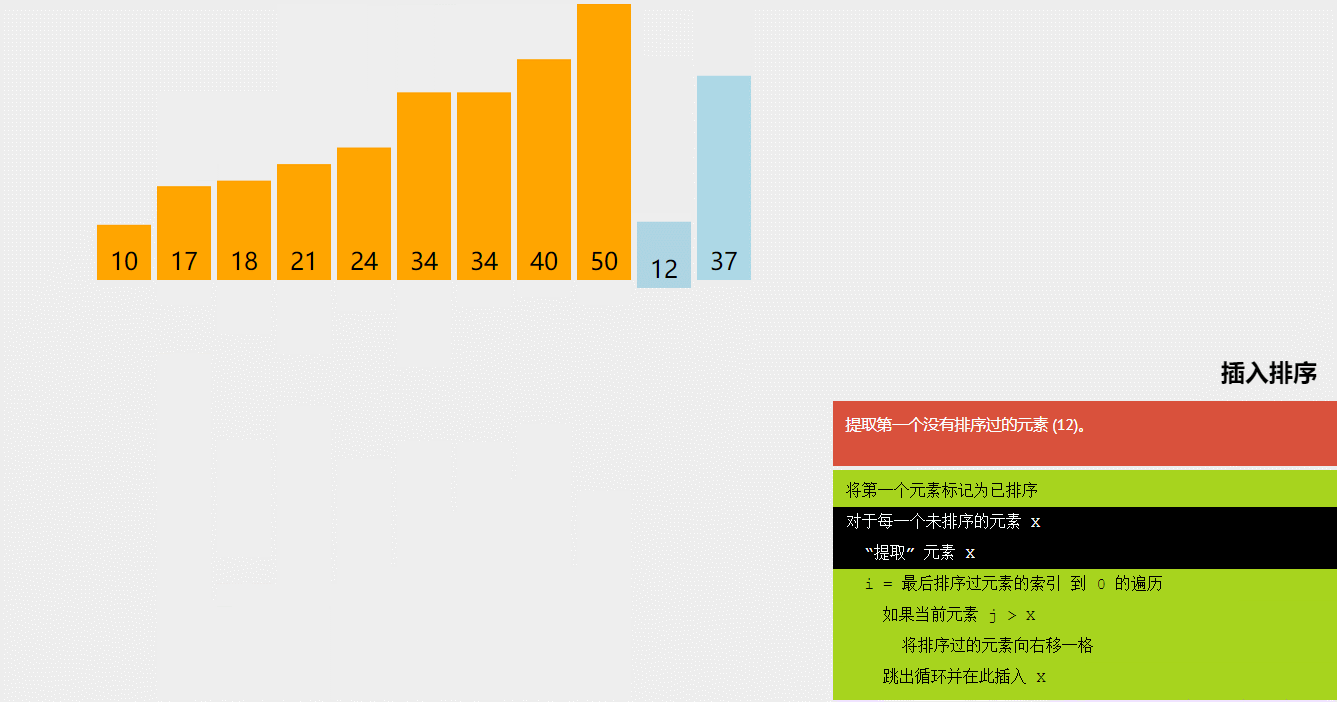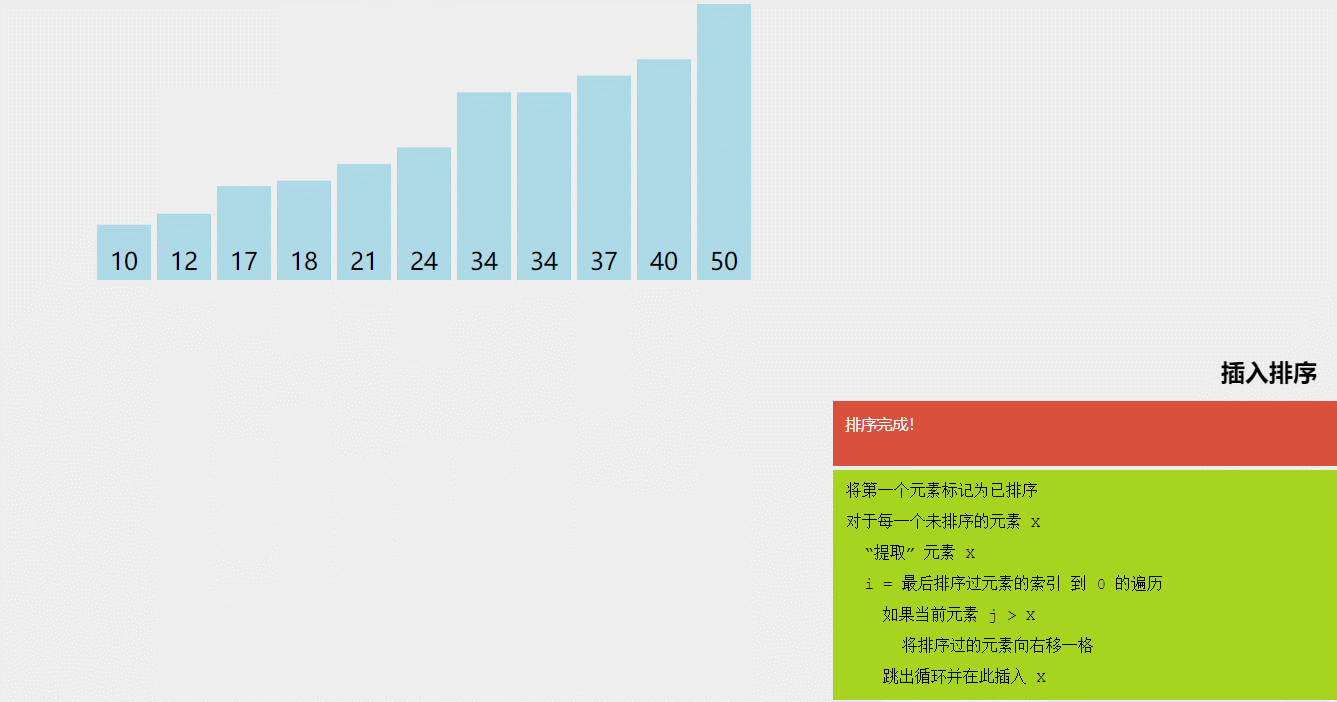
3.插入排序(Insertion Sort)
插入排序是一种简单的排序算法,其基本思想是将待排序的元素插入到已排序的序列中,从而得到一个新的、更长的有序序列。具体实现时,我们将待排序的元素按照从小到大的顺序依次插入到已排序的序列中,直到所有元素都排序完毕。
插入排序的具体实现过程如下:
- 将序列的第一个元素看作是已排序的序列,将其余的元素看作是待排序的序列。
- 依次取出待排序序列中的元素,并将它插入到已排序序列中的正确位置。
- 重复上述过程,直到所有元素都已排序完毕。
下面是插入排序的C语言实现示例:
void insertionSort(int arr[], int n) {
int i, j, tmp;
// 外层循环表示待排序部分的起始索引,从1开始
for (i = 1; i < n; i++) {
tmp = arr[i];
j = i - 1;
// 内层循环从已排序部分中找到待插入元素的正确位置
while (j >= 0 && arr[j] > tmp) {
arr[j+1] = arr[j];
j--;
}
// 插入待排序元素
arr[j+1] = tmp;
}
}
4.快速排序(Quick Sort)
快速排序是一种常用的基于比较的排序算法,其基本思想是通过一趟排序将待排序序列分割成两部分,其中一部分的所有元素都比另一部分的所有元素小,然后再分别对这两部分递归地进行排序,直到整个序列都有序为止。具体实现时,我们先选定一个基准元素,然后将序列中的所有元素分成两部分,一部分是小于基准元素的元素,另一部分是大于等于基准元素的元素,然后分别对这两部分递归地进行排序。
快速排序的具体实现过程如下:
- 选定一个基准元素,通常选择待排序序列的第一个元素。
- 将序列中的元素分成两部分,一部分是小于基准元素的元素,另一部分是大于等于基准元素的元素,可以使用两个指针i和j来完成。
- 将小于基准元素的部分放在序列的左边,大于等于基准元素的部分放在序列的右边。
- 递归地对左右两部分进行排序。
下面是快速排序的C语言实现示例:
// 快速排序
void quickSort(int arr[], int left, int right) {
int i, j, pivot;
if (left >= right) {
return;
}
// 取第一个元素为基准元素
pivot = arr[left];
i = left;
j = right;
while (i < j) {
// 从右往左扫描,找到第一个小于基准元素的元素
while (i < j && arr[j] >= pivot) {
j--;
}
if (i < j) {
arr[i] = arr[j];
i++;
}
// 从左往右扫描,找到第一个大于基准元素的元素
while (i < j && arr[i] < pivot) {
i++;
}
if (i < j) {
arr[j] = arr[i];
j--;
}
}
// 将基准元素放到正确的位置上
arr[i] = pivot;
// 递归排序基准元素左边的子序列
quickSort(arr, left, i - 1);
// 递归排序基准元素右边的子序列
quickSort(arr, i + 1, right);
}
5.归并排序(Merge Sort)
归并排序是一种基于分治思想的排序算法,其核心思想是将待排序的数组拆分成若干个子问题,将子问题分别排序后再合并成一个有序的数组。具体实现时,将数组不断二分拆分直至子数组只有一个元素,然后将相邻的子数组合并成一个有序的数组,最后再将不断合并后的子数组合并成一个有序的数组。
归并排序的具体实现过程如下:
- 将待排序数组递归拆分成两个子数组,直至子数组中只有一个元素。
- 将相邻的子数组合并成一个有序的数组,合并时依次比较两个子数组的首个元素,将较小的元素放入临时数组中,直至将两个子数组的所有元素都放入临时数组中。
- 将所有子数组合并后得到的有序数组返回。
下面是归并排序的C语言实现示例(使用递归实现):
void merge(int arr[], int left, int mid, int right) {
int i, j, k;
int n1 = mid - left + 1;
int n2 = right - mid;
// 创建临时数组存放左右子数组
int L[n1], R[n2];
// 将左右子数组的元素拷贝到临时数组中
for (i = 0; i < n1; i++)
L[i] = arr[left + i];
for (j = 0; j < n2; j++)
R[j] = arr[mid + 1 + j];
// 合并左右子数组
i = 0; // 左子数组的起始位置
j = 0; // 右子数组的起始位置
k = left; // 临时数组的起始位置
while (i < n1 && j < n2) {
if (L[i] <= R[j]) {
arr[k] = L[i];
i++;
} else {
arr[k] = R[j];
j++;
}
k++;
}
// 将左子数组中剩余的元素拷贝到临时数组中
while (i < n1) {
arr[k] = L[i];
i++;
k++;
}
// 将右子数组中剩余的元素拷贝到临时数组中
while (j < n2) {
arr[k] = R[j];
j++;
k++;
}
}
void mergeSort(int arr[], int left, int right) {
int mid;
if (left < right) {
// 找到数组的中间位置
mid = left + (right - left) / 2;
// 分别对左右子数组进行排序
mergeSort(arr, left, mid);
mergeSort(arr, mid + 1, right);
// 合并左右子数组
merge(arr, left, mid, right);
}
}
6.希尔排序(Shell Sort)
希尔排序是一种基于插入排序的排序算法,由Donald Shell在1959年提出。希尔排序的基本思想是将待排序元素按照一定的间隔分组,对每组元素使用插入排序,逐渐缩小间隔直至为1,最后对整个序列进行插入排序。
希尔排序的具体实现过程如下:
- 首先,定义一个间隔序列,通常是 n/2, n/4, n/8, …, 1。
- 对于每个间隔,将待排序序列分成若干个子序列,每个子序列内的元素下标之间相差间隔个数。
- 对每个子序列进行插入排序,即将子序列内的元素插入到已排序序列中的正确位置。
- 缩小间隔,重复步骤 2 和步骤 3,直到间隔为 1 时,整个序列已经有序
下面是希尔排序的C语言实现示例,以升序排序为例:
void shellSort(int arr[], int n) {
int i, j, gap, temp;
// 初始化间隔
for (gap = n / 2; gap > 0; gap /= 2) {
// 对每个分组进行插入排序
for (i = gap; i < n; i++) {
temp = arr[i];
// 将元素插入到已排序序列中的正确位置
for (j = i; j >= gap && arr[j - gap] > temp; j -= gap) {
arr[j] = arr[j - gap];
}
arr[j] = temp;
}
}
}
7.堆排序(Heap Sort)
堆排序是一种基于二叉堆数据结构的排序算法。它的主要思想是将待排序序列看成一个完全二叉树,并把它构建成一个堆,然后每次取出堆顶元素并调整堆结构,重复这个过程直到整个序列有序。
堆排序的具体实现过程如下:
- 建立一个初始的二叉堆(可以选择最大堆或最小堆,这里以最大堆为例);
- 取出堆顶元素,将其与堆末尾元素交换;
- 重新调整堆,使其满足最大堆的性质;
- 重复 2-3 步,直到堆中只剩下一个元素为止。
以下是堆排序的C语言实现示例,以最大堆为例:
// 调整堆,使之满足堆的性质
void adjustHeap(int arr[], int i, int n) {
int temp = arr[i];
int j = 2 * i + 1; // 左孩子节点
while (j < n) {
// 如果右孩子比左孩子大,则将j指向右孩子
if (j + 1 < n && arr[j] < arr[j + 1]) {
j++;
}
// 如果父节点比最大的孩子节点大,则不需要交换
if (temp >= arr[j]) {
break;
}
// 将最大的孩子节点交换到父节点位置
arr[i] = arr[j];
i = j;
j = 2 * i + 1;
}
arr[i] = temp;
}
void heapSort(int arr[], int n) {
int i,tmp;
// 构造堆
for (i = n / 2 - 1; i >= 0; i--) {
adjustHeap(arr, i, n);
}
// 交换堆顶元素与堆底元素,并重新调整堆
for (i = n - 1; i > 0; i--) {
tmp = arr[i];
arr[i] = arr[0];
arr[0] = tmp;
adjustHeap(arr, 0, i);
}
}
8.计数排序(Counting Sort)
计数排序是一种非比较排序算法,适用于数据范围不大且值比较集中的情况。它的基本思想是统计待排序序列中每个元素出现的次数,进而推导出每个元素的正确位置,最后将元素移动到其正确的位置上即可。
计数排序的实现需要额外的数组来存储每个元素出现的次数和每个元素在有序序列中的位置。
计数排序的具体实现过程如下(以升序排序为例):
- 找出待排序序列中的最大值max和最小值min。
- 根据max和min计算出计数数组count的长度,即(countLength = max - min + 1)。
- 初始化计数数组count,数组中每个元素的初始值都为0。
- 遍历待排序序列,统计每个元素出现的次数,并将次数保存在count数组对应元素中。
- 根据count数组中的统计结果,得出每个元素在有序序列中的位置。由于可能有重复元素,因此需要累加计数数组中元素的值,以确定相同元素在有序序列中的相对位置。
- 将待排序序列中的元素移动到有序序列中的正确位置上,这里可以从后往前遍历待排序序列,以保证相同元素的稳定性。
下面是计数排序的C语言实现示例(假设待排序序列中的元素均为非负整数):
void countingSort(int arr[], int len) {
int i, max, min, countLength;
if (len <= 1) {
return;
}
// 找出待排序序列中的最大值和最小值
max = arr[0];
min = arr[0];
for (i = 1; i < len; i++) {
if (arr[i] > max) {
max = arr[i];
}
if (arr[i] < min) {
min = arr[i];
}
}
// 根据最大值和最小值计算出计数数组的长度
countLength = max - min + 1;
// 初始化计数数组
int *count = (int*)malloc(countLength*sizeof(int));
memset(count, 0, countLength * sizeof(int));
for (int i = 0; i < len; i++) {
count[arr[i] - min]++;
}
// 计算每个元素在有序序列中的位置
for (i = 1; i < countLength; i++) {
count[i] += count[i - 1];
}
// 将元素移动到有序序列中的正确位置上
int *sorted = (int*)malloc(len*sizeof(int));
for (i = len - 1; i >= 0; i--) {
sorted[count[arr[i] - min] - 1] = arr[i];
count[arr[i] - min]--;
}
// 将有序序列复制回原序列
memcpy(arr, sorted, len*sizeof(int));
// 释放内存
free(count);
free(sorted);
}
9.桶排序(Bucket Sort)
桶排序是一种排序算法,它根据待排序元素的大小,将它们分散到一系列的桶中,每个桶再单独进行排序。最后,将每个桶中的元素合并起来,即可得到有序序列。
桶排序的具体实现过程如下:
- 找到待排序序列中的最大值和最小值。
- 根据最大值和最小值计算出桶的个数,并创建桶数组。
- 将待排序序列中的元素分配到各个桶中。
- 对每个桶中的元素进行排序。
- 将所有桶中的元素依次取出,放回到原序列中,得到有序序列。
下面是桶排序的C语言实现示例:
void bucketSort(int arr[], int len) {
int i, max, min, bucketNum, index;
int *buckets = NULL;
if (len <= 1) {
return;
}
// 找出待排序序列中的最大值和最小值
max = arr[0];
min = arr[0];
for (i = 1; i < len; i++) {
if (arr[i] > max) {
max = arr[i];
}
if (arr[i] < min) {
min = arr[i];
}
}
// 计算桶的数量
bucketNum = max - min + 1;
// 动态分配桶的空间
int *buckets = (int*)malloc(bucketNum * sizeof(int));
if (!buckets) {
printf("Memory allocation failed.\n");
return;
}
memset(buckets, 0, bucketNum * sizeof(int));
// 将元素放入桶中
for (i = 0; i < len; i++) {
buckets[arr[i] - min]++;
}
// 将桶中的元素按顺序取出,放回原数组
index = 0;
for (i = 0; i < bucketNum; i++) {
while (buckets[i] > 0) {
arr[index++] = i + min;
buckets[i]--;
}
}
// 释放桶的空间
free(buckets);
}
10.基数排序(Radix Sort)
基数排序是一种非比较排序算法,它将整数按位数切割成不同的数字,然后按每个位数分别比较。该算法从最低位开始排序,然后对每个位上的数字进行计数排序(或桶排序),这样,每个位上的数字就被排好序了。
基数排序的具体实现过程如下:
- 首先,从个位数开始,按照数字的个位数进行排序,将数字放入0~9这10个桶中,第一次排序后,得到一个以个位数为基准排序后的序列。
- 然后,按照十位数进行排序,将数字放入0~9这10个桶中,第二次排序后,得到一个以十位数为基准排序后的序列。
- 重复以上步骤,直到最高位排序完成,得到一个完全有序的序列。
以下是基数排序的 C 语言实现代码:
// 获取数组中最大的数
int getMax(int arr[], int n) {
int i, max;
max = arr[0];
for (i = 1; i < n; i++) {
if (arr[i] > max) {
max = arr[i];
}
}
return max;
}
// 对每一位进行计数排序
void countSort(int arr[], int n, int exp) {
int i;
int output[n];
int count[10] = {0};
// 统计每个数字出现的次数
for (i = 0; i < n; i++) {
count[(arr[i] / exp) % 10]++;
}
// 计算出现的位置
for (i = 1; i < 10; i++) {
count[i] += count[i - 1];
}
// 输出到数组
for (i = n - 1; i >= 0; i--) {
output[count[(arr[i] / exp) % 10] - 1] = arr[i];
count[(arr[i] / exp) % 10]--;
}
// 将排序后的数组复制到原始数组
for (i = 0; i < n; i++) {
arr[i] = output[i];
}
}
// 基数排序
void radixSort(int arr[], int n) {
int max = getMax(arr, n);
// 从最低位到最高位进行排序
for (int exp = 1; max / exp > 0; exp *= 10) {
countSort(arr, n, exp);
}
}在实际应用中,不同的排序算法适用于不同的场景和数据规模,需要根据具体情况选择合适的算法。本期的内容到这就结束了,如果觉得文章不错,可以点赞、收藏和关注哦,谢谢大家收看,下期再见!文章来源:https://www.toymoban.com/news/detail-407212.html
---END--文章来源地址https://www.toymoban.com/news/detail-407212.html
关于更多嵌入式C语言、FreeRTOS、RT-Thread、Linux应用编程、linux驱动等相关知识,关注公众号【嵌入式Linux知识共享】,后续精彩内容及时收看了解
到了这里,关于C语言之十大经典排序算法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!