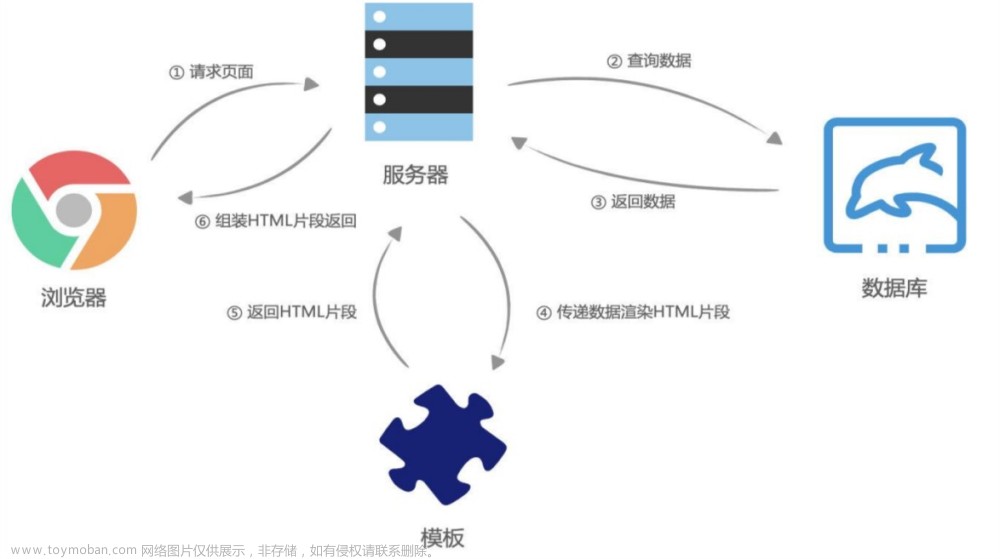
如何解析请求回来的 HTML 代码,DOM 树又是如何构建的。

如何解析请求回来的 HTML 代码
字符流拆成了词(token)需要两个方面(1.2)
1. 词(token)是如何被拆分的

2. 状态机
状态机的初始状态,我们仅仅区分 “< ”和 “非 <”:
- 如果获得的是一个非 < 字符,那么可以认为进入了一个文本节点;
- 如果获得的是一个 < 字符,那么进入一个标签状态。
不过当我们在标签状态时,则会面临着一些可能性。
- 比如下一个字符是“ ! ” ,那么很可能是进入了注释节点或者 CDATA 节点。
- 如果下一个字符是 “/ ”,那么可以确定进入了一个结束标签。
- 如果下一个字符是字母,那么可以确定进入了一个开始标签。
- 如果我们要完整处理各种 HTML 标准中定义的东西,那么还要考虑“ ? ”“% ”等内容。
用状态机做词法分析,其实正是把每个词的“特征字符”逐个拆开成独立状态,然后再把所有词的特征字符链合并起来,形成一个联通图结构。文章来源:https://www.toymoban.com/news/detail-407273.html
DOM 树又是如何构建的
- 用栈来实现构建DOM树
- 栈顶元素就是当前节点;
- 遇到属性,就添加到当前节点;
- 遇到文本节点,如果当前节点是文本节点,则跟文本节点合并,否则入栈成为当前节点的子节点;遇到注释节点,作为当前节点的子节点;
- 遇到 tag start 就入栈一个节点,当前节点就是这个节点的父节点;
- 遇到 tag end 就出栈一个节点(还可以检查是否匹配)。
此文章为4月Day7学习笔记,内容来源于极客时间《重学前端》,推荐该课程。文章来源地址https://www.toymoban.com/news/detail-407273.html
到了这里,关于浏览器是如何工作的(2)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!