参考的 文章: http://dblab.xmu.edu.cn/blog/931-2/
一、(实现需要先安装好Hadoop3)
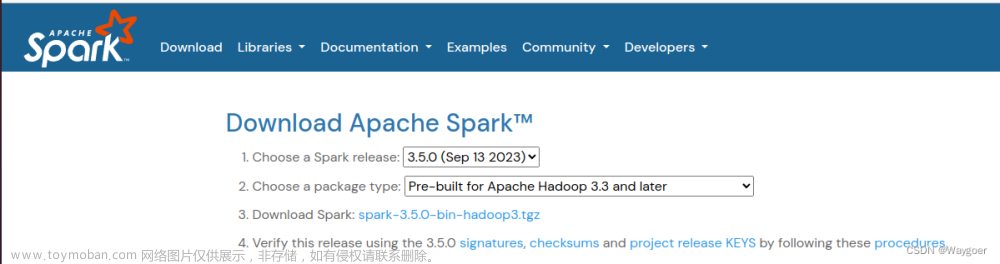
1、官网下载:3版本


2、单机模式 安装配置:
Spark部署模式主要有四种:
- Local模式(单机模式)
- Standalone模式(使用Spark自带的简单集群管理器)、
- YARN模式(使用YARN作为集群管理器)
- Mesos模式(使用Mesos作为集群管理器)。
(1)解压压缩包到之前Hadoop安装的目录:本地计算机-usr-local

(2)cd进入该目录:
(3)解压的压缩包名称太长了,我们改成spark:
(4)赋予该文件相关权限(lpp2是你的hadoop名字,可以在设置的【用户】中查看)
(5)进入spark文件目录:
(6)使用cp复制其中的配置文件,命名为:
(7)编辑spark-env.sh文件(vim ./conf/spark-env.sh),在第一行添加以下配置信息:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)

按i进入插入模式,插入完成,
然后按下退出键ESC,然后是shift+冒号健输入一个英文冒号,他就会在最下面生成一个冒号。
这时候我们输入wq,然会回车,就会【保存并退出】vim编辑器。
如果你不放心,可以进入文件管理中查看:
细心的你会发现,其实就是加了一个hadoop的路径,
其实有了上面的配置信息以后,【Spark】就可以把数据存储到【Hadoop分布式文件系统HDFS】中,也可以从HDFS中读取数据。(如果没有配置上面信息,Spark就只能读写本地数据,无法读写HDFS数据)
(8)直接使用它bin下面的这个命令来运行试试:(运行它自带的实例,检查是否安装成功)
(9)使用管道过滤信息:
bin/run-example SparkPi 2>&1 | grep "Pi is"
如果输出:π,即可
3、在集群上运行Spark应用程序
- 1.standalone模式
与MapReduce1.0框架类似,Spark框架本身也自带了完整的资源调度管理服务,可以独立部署到一个集群中,而不需要依赖其他系统来为其提供资源管理调度服务。在架构的设计上,Spark与MapReduce1.0完全一致,都是由一个Master和若干个Slave构成,并且以槽(slot)作为资源分配单位。不同的是,Spark中的槽不再像MapReduce1.0那样分为Map 槽和Reduce槽,而是只设计了统一的一种槽提供给各种任务来使用。 - 2.Spark on Mesos模式
Mesos是一种资源调度管理框架,可以为运行在它上面的Spark提供服务。Spark on Mesos模式中,Spark程序所需要的各种资源,都由Mesos负责调度。由于Mesos和Spark存在一定的血缘关系,因此,Spark这个框架在进行设计开发的时候,就充分考虑到了对Mesos的充分支持,因此,相对而言,Spark运行在Mesos上,要比运行在YARN上更加灵活、自然。目前,Spark官方推荐采用这种模式,所以,许多公司在实际应用中也采用该模式。
- Spark on YARN模式
Spark可运行于YARN之上,与Hadoop进行统一部署,即“Spark on YARN”,其架构如图9-13所示,资源管理和调度依赖YARN,分布式存储则依赖HDFS。
集群环境搭建:http://dblab.xmu.edu.cn/blog/1187-2/文章来源:https://www.toymoban.com/news/detail-407358.html
这里采用3台机器(节点)作为实例来演示如何搭建Spark集群,文章来源地址https://www.toymoban.com/news/detail-407358.html
- 其中1台机器(节点)作为
Master节点, - 另外两台机器(节点)作为
Slave节点(即作为Worker节点),主机名分别为Slave01和Slave02。
待更新…
到了这里,关于【Ubuntu-大数据】spark安装配置的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!



![林子雨 VirtualBox + Ubuntu[linux] 配置 java、hadoop、Spark[python]、pyspark快速配置流程](https://imgs.yssmx.com/Uploads/2024/04/848890-1.png)






