作为一名机器学习|深度学习的博主,想和大家分享几本深度学习的书籍,让大家更快的入手深度学习,成为AI达人!今天给大家介绍的是:《Python深度学习 基于Pytorch》
一、背景
在人工智能时代,如何尽快掌握人工智能的核心—深度学习呢?相信这是每个欲进入此领域的人面临的主要问题。目前,深度学习框架很多,如TensorFlow、PyTorch、Keras、FastAI、CNTK等。
面对众多的深度学习框架,初学者应如何选择?哪个框架既易于上手,又在工业界有广泛应用?毫无疑问,PyTorch是不二之选。一方面,PyTorch天然与Python结合,大大降低了深度学习的门槛;另一方面,它的流行度仅次于TensorFlow,而且有赶超之势,但是上手难度却比TensorFlow低很多。如果你是一位初学者,建议你选择PyTorch,待有了一定的基础之后,可以学习其他框架,如TensorFlow、CNTK等。

这是一本能指导读者快速掌握PyTorch和深度学习的著作,从PyTorch的原理到应用,从深度学习到强化学习,本书提供了全栈解决方案。本书还涉及AIGC技术的核心内容,本书第8章、第14重点介绍了注意力机制及Transformer架构及其应用,第10章、第16章介绍了生成式网络核心架构(如AE、VAE、GAN等),这些架构包括降噪、重参数化等技术,此外,本书还包括目标检测、强化学习等内容。除理论、原理介绍外,还包括大量可动手实践的实例。
第1版上市后销量和口碑俱佳,是深度学习领域的畅销书,被誉为PyTorch领域的标准著作。第2版在第1版的基础上,去芜存菁,与时俱进,根据PyTorch新版本全面升级,技术性、实战性、丰富性、针对性、易读性均得到了进一步提升,必能帮助读者更轻松、更高效地进入深度学习的世界。帮助读者低门槛进入深度学习领域,轻松掌握深度学习的理论知识和实践方法,快速实现从入门到进阶的转变”是这本书的核心目标。
二、内容简介
本书分为三部分,共19章,第一部分为PyTorch基础,第二部分为深度学习基本原理,第三部分是实战内容。
- 第一部分(第1~4章)为Python和PyTorch基础部分,也是本书的基础部分,为后续学习打下一个坚实基础。第1章介绍了PyTorch的基石NumPy;第2章介绍PyTorch基础;第3、4章分别介绍PyTorch构建神经网络工具箱和数据处理工具箱等内容。
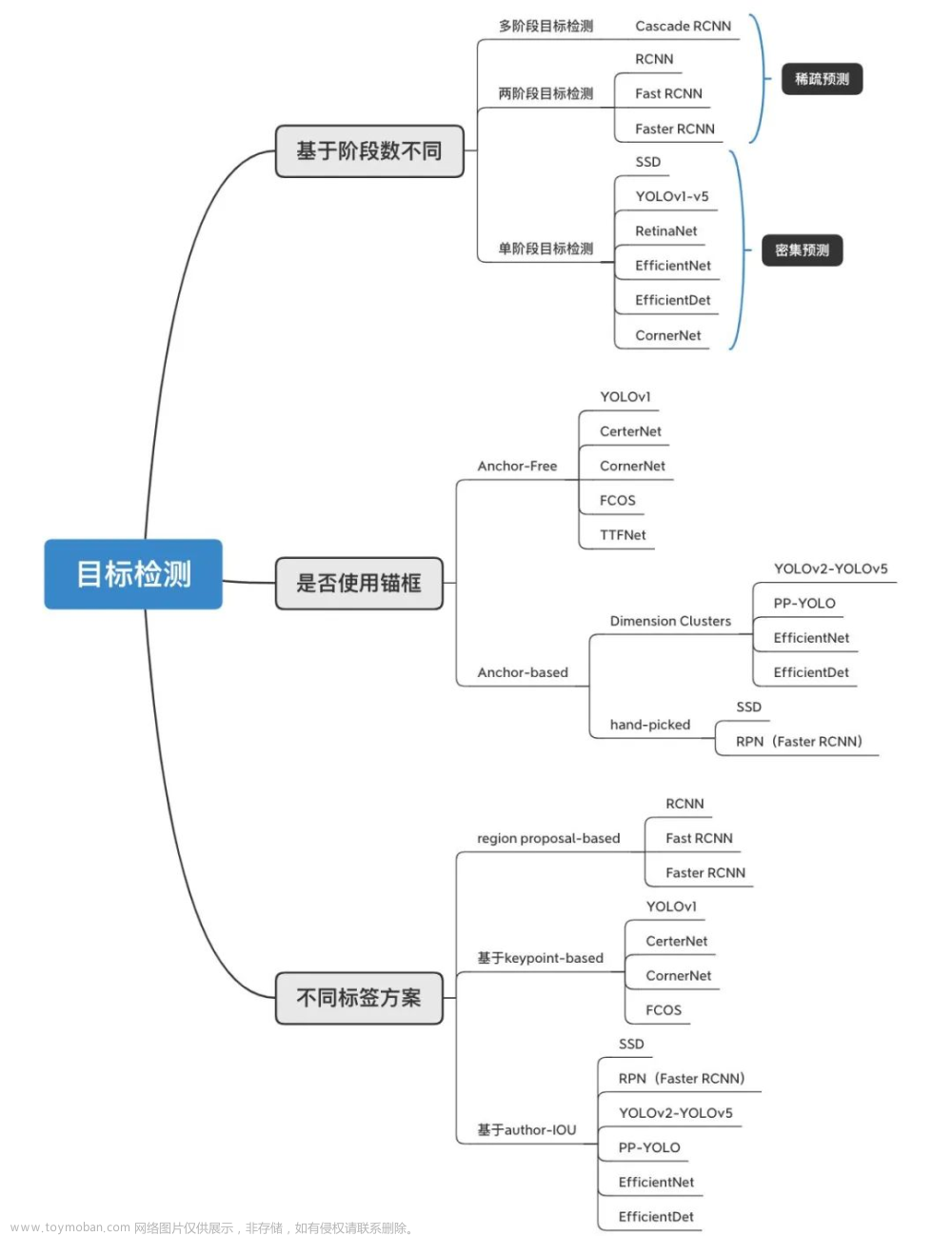
- 第二部分(第5~10章)为机器学习、深度学习部分,这是本书核心部分。第5章为机器学习基础;第6章为视觉处理基础;第7章介绍自然语言处理基础;第8章介绍注意力机制,详解介绍Transformer架构;第9章介绍目标检测与语义分割;第10章介绍生成式深度学习相关内容,包括AE,VAE,GAN、CGAN等模型。
- 第三部分(第11~19章)为深度学习实战,也即前面两部分的具体应用部分。这部分在介绍相关原理、架构的基础上,用PyTorch具体实现的典型实例,最后介绍了强化学习、深度强化学习等内容。具体各章节内容为,第11章用PyTorch实现人脸检测和识别;第12章用PyTorch实现迁移学习、迁移学习结合数据增强等实例;第13章用PyTorch实现中英文互译;第14章介绍了基于Transformer架构的ViT进行图像分类;第15章为语义分割实例;第16章多个生成式网络实例;第17章介绍对抗攻击原理及PyTorch实现对抗攻击实例;第18、19章介绍了强化学习、深度强化学习等基础及多个强化学习实例。
更为重要的是,为了让本书通俗易懂,在内容安排和写作方式上也颇花了一番心思。内容选择上,广泛涉猎、重点突出、注重实战;内容安排上,实例切入、由浅入深、循序渐进;表达形式上,深度抽象、化繁为简、用图说话。
三、新版特色
自本书第1版第1次于2019年10月印刷至今,已累计印刷了9次。在这3年的时间里,深度学习的发展可谓日新月异,其应用范围得到进一步拓展,同时出现了很多新的框架、新的方向。
在众多创新中,注意力机制是一个典型代表。注意力机制,尤其是以Transformer为基础的一些模型,在自然语言处理(NLP)领域取得了目前最好的效果(如SOTA),近几年研究人员把这种模型(如ViT模型、Swin-T模型等)应用到计算机视觉领域,也取得了巨大成功。
为此,本书第2版增强了注意力机制的相关内容,把注意力机制单独列为一章(即第8章),同时增加了注意力机制的应用实例,详细内容请参考第14章。
人工智能广泛应用于图像、视频、语音等诸多领域,比如人工智能在目标检测、语义分割等任务中的应用日益受到大家的关注,所以在第2版中我们增加了这方面的内容,具体可参考第9章和第15章。
除了这些新增内容外,第2版对很多原有内容进行了补充和完善,如PyTorch基础、优化算法、视觉处理基础、自然语言处理基础等内容。
为便利大家更好理解本书,特提供PPT文档
PPT文档对书中内容进行提炼,并包括很多gif动画,便于更直观理解相关原理和概念,此外,作为不少拓展,包括GPT-3、ChatGPT、Diffusion Model等内容。
四、作者介绍
吴茂贵,资深大数据和人工智能技术专家,在BI、数据挖掘与分析、数据仓库、机器学习等领域工作超过20年。在基于Spark、TensorFlow、PyTorch等的机器学习和深度学习方面有大量的工程实践经验。著有《Python深度学习:基于TensorFlow》《深度实践Spark机器学习》《自己动手做大数据系统》《深入浅出Embedding原理解析与应用实践》等畅销书。
郁明敏,资深商业分析师,从事互联网金融算法研究工作,专注于大数据、机器学习以及数据可视化的相关领域,擅长 Python、Hadoop、Spark 等技术,拥有丰富的实战经验。曾获“江苏省TI杯大学生电子竞技大赛”二等奖和“华为杯全国大学生数学建模大赛”二等奖。
杨本法,高级算法工程师,工业表面缺陷检测设备开发架构师,在机器学习、文本挖掘、可视化等领域有多年实践经验。做过大型电商的推荐系统,知名手机厂商外壳表面检测设备。熟悉Hadoop、Spark生态圈的相关技术,对Python有丰富的实战经验。
李 涛 ,资深AI技术工程师,任职于携程(上海)科技有限公司,负责酒店排序推荐相关项目的数据分析和算法开发,对计算机视觉技术和搜索推荐系统有深刻的理解和丰富的实践经验。文章来源:https://www.toymoban.com/news/detail-407395.html
张粤磊 ,国云大数据学院院长,飞谷云创始人,毕业于中国科技大学,原平安壹钱包大数据架构师。业内知名大数据专家,多部大数据畅销书作者。2016年以来每年都以高级专家和咨询顾问身份深入参与大数据、人工智能技术在行业的落地应用。文章来源地址https://www.toymoban.com/news/detail-407395.html
五、目录
前言
第1版前言
第一部分 PyTorch基础
第1章 NumPy基础知识2
1.1 生成NumPy数组3
1.1.1 数组属性4
1.1.2 利用已有数据生成数组4
1.1.3 利用 random 模块生成数组5
1.1.4 生成特定形状的多维数组7
1.1.5 利用arange、linspace
函数生成数组8
1.2 读取数据9
1.3 NumPy的算术运算11
1.3.1 逐元素操作11
1.3.2 点积运算12
1.4 数组变形13
1.4.1 修改数组的形状13
1.4.2 合并数组16
1.5 批处理19
1.6 节省内存20
1.7 通用函数21
1.8 广播机制23
1.9 小结24
第2章 PyTorch基础知识25
2.1 为何选择PyTorch25
2.2 PyTorch的安装配置26
2.2.1 安装CPU版PyTorch26
2.2.2 安装GPU版PyTorch28
2.3 Jupyter Notebook环境配置30
2.4 NumPy与Tensor31
2.4.1 Tensor概述31
2.4.2 创建Tensor32
2.4.3 修改Tensor形状34
2.4.4 索引操作35
2.4.5 广播机制35
2.4.6 逐元素操作36
2.4.7 归并操作37
2.4.8 比较操作37
2.4.9 矩阵操作38
2.4.10 PyTorch与NumPy比较39
2.5 Tensor与autograd39
2.5.1 自动求导要点40
2.5.2 计算图40
2.5.3 标量反向传播41
2.5.4 非标量反向传播42
2.5.5 切断一些分支的反向传播45
2.6 使用NumPy实现机器学习任务47
2.7 使用Tensor及autograd实现机器
学习任务49
2.8 使用优化器及自动微分实现机器
学习任务51
2.9 把数据集转换为带批量处理功能的
迭代器52
2.10 使用TensorFlow 2实现机器
学习任务54
2.11 小结55
第3章 PyTorch神经网络工具箱56
3.1 神经网络核心组件56
3.2 构建神经网络的主要工具57
3.2.1 nn.Module57
3.2.2 nn.functional58
3.3 构建模型59
3.3.1 继承nn.Module基类构建模型59
3.3.2 使用nn.Sequential按层
顺序构建模型60
3.3.3 继承nn.Module基类并应用
模型容器来构建模型63
3.3.4 自定义网络模块66
3.4 训练模型68
3.5 实现神经网络实例69
3.5.1 背景说明69
3.5.2 准备数据70
3.5.3 可视化源数据71
3.5.4 构建模型72
3.5.5 训练模型72
3.6 小结74
第4章 PyTorch数据处理工具箱75
4.1 数据处理工具箱概述75
4.2 utils.data76
4.3 torchvision78
4.3.1 transforms78
4.3.2 ImageFolder79
4.4 可视化工具81
4.4.1 TensorBoard简介81
4.4.2 用TensorBoard可视化
神经网络82
4.4.3 用TensorBoard可视化损失值83
4.4.4 用TensorBoard可视化特征图84
4.5 小结85
第二部分 深度学习基础
第5 章 机器学习基础88
5.1 机器学习的基本任务88
5.1.1 监督学习89
5.1.2 无监督学习89
5.1.3 半监督学习90
5.1.4 强化学习90
5.2 机器学习的一般流程90
5.2.1 明确目标91
5.2.2 收集数据91
5.2.3 数据探索与预处理91
5.2.4 选择模型及损失函数91
5.2.5 评估及优化模型92
5.3 过拟合与欠拟合93
5.3.1 权重正则化93
5.3.2 dropout正则化94
5.3.3 批量归一化97
5.3.4 层归一化99
5.3.5 权重初始化99
5.4 选择合适的激活函数100
5.5 选择合适的损失函数101
5.6 选择合适的优化器103
5.6.1 传统梯度优化算法104
5.6.2 批量随机梯度下降法105
5.6.3 动量算法106
5.6.4 Nesterov动量算法108
5.6.5 AdaGrad算法109
5.6.6 RMSProp算法111
5.6.7 Adam算法112
5.6.8 Yogi算法113
5.6.9 使用优化算法实例114
5.7 GPU加速116
5.7.1 单GPU加速116
5.7.2 多GPU加速117
5.7.3 使用GPU时的注意事项120
5.8 小结121
第6章 视觉处理基础122
6.1 从全连接层到卷积层122
6.1.1 图像的两个特性123
6.1.2 卷积神经网络概述124
6.2 卷积层125
6.2.1 卷积核127
6.2.2 步幅129
6.2.3 填充130
6.2.4 多通道上的卷积131
6.2.5 激活函数134
6.2.6 卷积函数135
6.2.7 转置卷积136
6.2.8 特征图与感受野137
6.2.9 全卷积网络138
6.3 池化层139
6.3.1 局部池化140
6.3.2 全局池化140
6.4 现代经典网络142
6.4.1 LeNet-5模型142
6.4.2 AlexNet模型143
6.4.3 VGG模型143
6.4.4 GoogLeNet模型144
6.4.5 ResNet模型145
6.4.6 DenseNet模型146
6.4.7 CapsNet模型148
6.5 使用卷积神经网络实现CIFAR10
多分类149
6.5.1 数据集说明149
6.5.2 加载数据149
6.5.3 构建网络151
6.5.4 训练模型151
6.5.5 测试模型152
6.5.6 采用全局平均池化153
6.5.7 像Keras一样显示各层参数154
6.6 使用模型集成方法提升性能156
6.6.1 使用模型156
6.6.2 集成方法157
6.6.3 集成效果158
6.7 使用现代经典模型提升性能158
6.8 小结159
第7章 自然语言处理基础160
7.1 从语言模型到循环神经网络160
7.1.1 链式法则161
7.1.2 马可夫假设与N元语法模型161
7.1.3 从N元语法模型到隐含
状态表示161
7.1.4 从神经网络到有隐含状态的
循环神经网络162
7.1.5 使用循环神经网络构建
语言模型164
7.1.6 多层循环神经网络164
7.2 正向传播与随时间反向传播165
7.3 现代循环神经网络167
7.3.1 LSTM168
7.3.2 GRU169
7.3.3 Bi-RNN169
7.4 循环神经网络的PyTorch实现170
7.4.1 使用PyTorch实现RNN170
7.4.2 使用PyTorch实现LSTM172
7.4.3 使用PyTorch实现GRU174
7.5 文本数据处理175
7.6 词嵌入176
7.6.1 Word2Vec原理177
7.6.2 CBOW模型177
7.6.3 Skip-Gram模型178
7.7 使用PyTorch实现词性判别179
7.7.1 词性判别的主要步骤179
7.7.2 数据预处理180
7.7.3 构建网络180
7.7.4 训练网络181
7.7.5 测试模型182
7.8 用LSTM预测股票行情183
7.8.1 导入数据183
7.8.2 数据概览183
7.8.3 预处理数据184
7.8.4 定义模型185
7.8.5 训练模型185
7.8.6 测试模型186
7.9 几种特殊架构187
7.9.1 编码器-解码器架构187
7.9.2 Seq2Seq架构189
7.10 循环神经网络应用场景189
7.11 小结190
第8章 注意力机制191
8.1 注意力机制概述191
8.1.1 两种常见注意力机制192
8.1.2 来自生活的注意力192
8.1.3 注意力机制的本质192
8.2 带注意力机制的编码器-解码器架构194
8.2.1 引入注意力机制194
8.2.2 计算注意力分配概率分布值196
8.3 Transformer198
8.3.1 Transformer的顶层设计198
8.3.2 编码器与解码器的输入200
8.3.3 自注意力200
8.3.4 多头注意力203
8.3.5 自注意力与循环神经网络、
卷积神经网络的异同204
8.3.6 加深Transformer网络层的
几种方法205
8.3.7 如何进行自监督学习205
8.3.8 Vision Transformer207
8.3.9 Swin Transformer208
8.4 使用PyTorch实现Transformer213
8.4.1 Transformer背景介绍214
8.4.2 构建EncoderDecoder214
8.4.3 构建编码器215
8.4.4 构建解码器218
8.4.5 构建多头注意力219
8.4.6 构建前馈神经网络层221
8.4.7 预处理输入数据222
8.4.8 构建完整网络224
8.4.9 训练模型225
8.4.10 实现一个简单实例228
8.5 小结230
第9章 目标检测与语义分割231
9.1 目标检测及主要挑战231
9.1.1 边界框的表示232
9.1.2 手工标注图像的真实值233
9.1.3 主要挑战236
9.1.4 选择性搜索236
9.1.5 锚框237
9.1.6 RPN239
9.2 优化候选框的几种算法240
9.2.1 交并比240
9.2.2 非极大值抑制240
9.2.3 边框回归241
9.2.4 SPP-Net243
9.3 典型的目标检测算法244
9.3.1 R-CNN244
9.3.2 Fast R-CNN245
9.3.3 Faster R-CNN245
9.3.4 Mask R-CNN246
9.3.5 YOLO247
9.3.6 各种算法的性能比较248
9.4 语义分割249
9.5 小结250
第10章 生成式深度学习251
10.1 用变分自编码器生成图像251
10.1.1 自编码器251
10.1.2 变分自编码器252
10.1.3 用变分自编码器生成图像实例253
10.2 GAN简介256
10.2.1 GAN的架构256
10.2.2 GAN的损失函数257
10.3 用GAN生成图像257
10.3.1 构建判别器258
10.3.2 构建生成器258
10.3.3 训练模型258
10.3.4 可视化结果259
10.4 VAE与GAN的异同260
10.5 CGAN260
10.5.1 CGAN的架构261
10.5.2 CGAN的生成器261
10.5.3 CGAN的判别器262
10.5.4 CGAN的损失函数262
10.5.5 CGAN的可视化262
10.5.6 查看指定标签的数据263
10.5.7 可视化损失值263
10.6 DCGAN264
10.7 提升GAN训练效果的技巧265
10.8 小结266
第三部分 深度学习实战
第11章 人脸检测与识别实例268
11.1 人脸检测与识别的一般流程268
11.2 人脸检测269
11.2.1 目标检测269
11.2.2 人脸定位269
11.2.3 人脸对齐270
11.2.4 MTCNN算法270
11.3 特征提取与人脸识别271
11.4 使用PyTorch实现人脸检测与识别276
11.4.1 验证检测代码277
11.4.2 检测图像277
11.4.3 检测后进行预处理278
11.4.4 查看检测后的图像278
11.4.5 人脸识别279
11.5 小结279
第12章 迁移学习实例280
12.1 迁移学习简介280
12.2 特征提取281
12.2.1 PyTorch提供的预处理模块282
12.2.2 特征提取实例283
12.3 数据增强285
12.3.1 按比例缩放286
12.3.2 裁剪286
12.3.3 翻转287
12.3.4 改变颜色287
12.3.5 组合多种增强方法287
12.4 微调实例288
12.4.1 数据预处理288
12.4.2 加载预训练模型289
12.4.3 修改分类器289
12.4.4 选择损失函数及优化器289
12.4.5 训练及验证模型290
12.5 清除图像中的雾霾290
12.6 小结293
第13章 神经网络机器翻译实例294
13.1 使用PyTorch实现带注意力的
解码器294
13.1.1 构建编码器294
13.1.2 构建解码器295
13.1.3 构建带注意力的解码器295
13.2 使用注意力机制实现中英文互译297
13.2.1 导入需要的模块297
13.2.2 数据预处理298
13.2.3 构建模型300
13.2.4 训练模型302
13.2.5 测试模型303
13.2.6 可视化注意力304
13.3 小结305
第14章 使用ViT进行图像分类306
14.1 项目概述306
14.2 数据预处理306
14.3 生成输入数据308
14.4 构建编码器模型310
14.5 训练模型313
14.6 小结314
第15章 语义分割实例315
15.1 数据概览315
15.2 数据预处理316
15.3 构建模型319
15.4 训练模型322
15.5 测试模型325
15.6 保存与恢复模型326
15.7 小结326
第16章 生成模型实例327
16.1 Deep Dream模型327
16.1.1 Deep Dream原理327
16.1.2 Deep Dream算法的流程328
16.1.3 使用PyTorch实现
Deep Dream329
16.2 风格迁移331
16.2.1 内容损失332
16.2.2 风格损失333
16.2.3 使用PyTorch实现神经
网络风格迁移335
16.3 使用PyTorch实现图像修复339
16.3.1 网络结构339
16.3.2 损失函数340
16.3.3 图像修复实例340
16.4 使用PyTorch实现DiscoGAN342
16.4.1 DiscoGAN架构343
16.4.2 损失函数344
16.4.3 DiscoGAN实现345
16.4.4 使用PyTorch实现
DiscoGAN实例346
16.5 小结348
第17章 AI新方向:对抗攻击349
17.1 对抗攻击简介349
17.1.1 白盒攻击与黑盒攻击350
17.1.2 无目标攻击与有目标攻击350
17.2 常见对抗样本生成方式350
17.2.1 快速梯度符号算法351
17.2.2 快速梯度算法351
17.3 使用PyTorch实现对抗攻击351
17.3.1 实现无目标攻击351
17.3.2 实现有目标攻击354
17.4 对抗攻击和防御方法355
17.4.1 对抗攻击355
17.4.2 常见防御方法分类355
17.5 小结356
第18章 强化学习357
18.1 强化学习简介357
18.2 Q-Learning算法原理359
18.2.1 Q-Learning算法的主要流程359
18.2.2 Q函数360
18.2.3 贪婪策略360
18.3 使用PyTorch实现Q-Learning算法361
18.3.1 定义Q-Learning主函数361
18.3.2 运行Q-Learning算法362
18.4 SARSA 算法362
18.4.1 SARSA算法的主要步骤362
18.4.2 使用PyTorch实现SARSA
算法363
18.5 小结364
第19章 深度强化学习365
19.1 DQN算法原理365
19.1.1 Q-Learning方法的局限性366
19.1.2 用深度学习处理强化学习
需要解决的问题366
19.1.3 用DQN算法解决问题366
19.1.4 定义损失函数366
19.1.5 DQN的经验回放机制367
19.1.6 目标网络367
19.1.7 网络模型367
19.1.8 DQN算法实现流程367
19.2 使用PyTorch实现 DQN算法368
19.3 小结371
附录A PyTorch 0.4版本变更372
附录B AI在各行业的最新应用377
附录C einops及einsum简介383
到了这里,关于深度学习必备书籍——《Python深度学习 基于Pytorch》的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![[深度学习实战]基于PyTorch的深度学习实战(下)[Mnist手写数字图像识别]](https://imgs.yssmx.com/Uploads/2024/02/603063-1.png)
![[深度学习实战]基于PyTorch的深度学习实战(上)[变量、求导、损失函数、优化器]](https://imgs.yssmx.com/Uploads/2024/02/581963-1.png)