全球网站都是由各种组件组成,比如用的哪种操作系统、哪种Web容器、什么服务端语言、什么Web应用等等,而ZoomEye是一个面向网络空间的搜索引擎,它允许使用公网设备指纹检索和web指纹检索
web指纹检索语法
web指纹识别包括应用名、版本、前后端框架、服务端语言与操作系统、容器、数据库等等
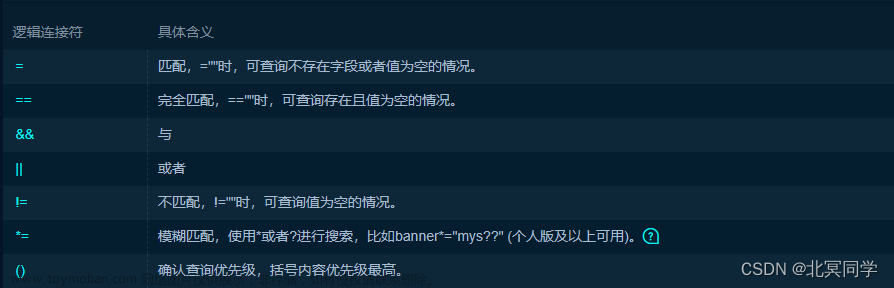
| 语法 | 描述 | 示例 |
|---|---|---|
| app:组件名 | 目标组件名称 | app:"Apache httpd" |
| ver:组件版本 | 目标组件版本号 | ver:'2.2.17' |
| site:网站域名 | 目标网站域名 | site:baidu.com |
| os:操作系统 | 目标操作系统 | os:windows |
| title:页面标题 | 目标网站标题 | title:'hello' |
| keywords:页面关键字 | 目标页面关键字 | keywords:'hello' |
| desc:页面说明 | 页面描述字段 | desc:'hello' |
| headers:请求头部 | HTTP请求中的headers | headers:Server |
| country:国家或者地区代码 | 目标地理位置 | country:US |
| city:城市名称 | 目标城市 | city:"Beijing" |
| ip:IP地址 | IP地址 | ip:1.1.1.1 |
| org:组织机构 | 组织机构 | org:'Vimpelcom' |
| asn:自治系统号 | 自治系统编号 | asn:42893 |
例如:搜索页面标题为hello,页面关键字为hello,地区为US

文章来源地址https://www.toymoban.com/news/detail-407558.html
设备指纹检索语法
设备指纹识别如操作系统、应用名称、版本号、端口、地理位置等等
| 语法 | 描述 | 实例 |
|---|---|---|
| app:组件名 | 目标组件名称 | app:"Apache httpd" |
| ver:组件版本 | 目标组件版本号 | ver:'2.2.17' |
| port:端口号 | 目标系统开发端口 | port:'6379' |
| os:操作系统 | 目标操作系统类型 | os:linux |
| service:服务名 | 目标运行的服务类型 | service:webcam |
| hostname:主机名 | 目标系统的主机名 | hostname:google.com |
| country:国家/地区代码 | 目标系统的地理位置 | country:CN |
| city:城市 | 目标系统的城市 | city:'Shanghai' |
| ip:IP地址 | IP地址 | ip:10.10.10.1 |
| org:组织机构 | 组织机构 | org:'Vimpelcom' |
| asn:自治系统号 | 自治系统编号 | asn:42893 |
| ssl:SSL证书号 | SSL证书 | ssl:'corp.google.com' |
例如:搜索在JP的windows操作系统,运行为Apache的服务器

脚本检索
(1)获取token
方法一、开发者模式获取token(以下脚本使用的是这个)

方法二、通过Python脚本构造post请求,将用户名与密码以json格式发送至后端,获取响应数据包得到token
# 获取token
import json
import requests
# 访问目标开启加密,python请求https关闭证书, 解决https报错问题
requests.packages.urllib3.disable_warnings()
def token():
username = input('username:')
password = input('password:')
URL = 'https://api.zoomeye.org/user/login'
data = {
'username': username,
'password': password
}
access_token = requests.post(URL, data=json.dumps(data), verify=False, allow_redirects=False)
print(access_token.text)
token()方法三、通过curl命令直接获取token

(2)脚本检索
查询开放3306端口的服务对应的ip地址
# 获取token
import json
import re
import requests
# 访问目标开启加密,python请求https关闭证书, 解决https报错问题
requests.packages.urllib3.disable_warnings()
def token():
username = input('username:')
password = input('password:')
URL = 'https://api.zoomeye.org/user/login'
data = {
'username': username,
'password': password
}
access_token = requests.post(URL, data=json.dumps(data), verify=False, allow_redirects=False)
ganyu = access_token.text
tokennum = re.search('ey((\w+.){4})', ganyu).group()
ganyu1 = tokennum.split('"')[0]
def mian():
headers = {
'Accept': '*/*',
'Cache - Control': 'max-age=0',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'If-None-Match':'W/"e46c1403df6dd51ea4bb214fcfc1bad8b12dbd03"',
'Referer': 'https://www.zoomeye.org/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:98.0) Gecko/20100101 Firefox/98.0',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site':'same-origin',
'Cube-Authorization': 'eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VybmFtZSI6IjVmN2FjMWE1YjBmYSIsImVtYWlsIjoiMjMxMTQ5ODM2NkBxcS5jb20iLCJleHAiOjE2NDc1OTYwNTAuMH0.e0yOehVGgWaKFPn1Y7aHyfoDmIqqV9VBIzbFiIOOQKY'
}
url = 'https://www.zoomeye.org/search?q=port%3A3306&page=1&pageSize=20&t=v4+v6+web'
res = requests.get(url=url, headers=headers, verify=False, allow_redirects=False)
init = json.loads(res.text)
for line in init['matches']:
print(line['ip']+':'+str(line['portinfo']['port']))
if __name__ == '__main__':
mian() 文章来源:https://www.toymoban.com/news/detail-407558.html
文章来源:https://www.toymoban.com/news/detail-407558.html
到了这里,关于ZoomEye搜索引擎语法与脚本检索的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![搜索引擎(大数据检索)论述[elasticsearch原理相关]](https://imgs.yssmx.com/Uploads/2024/01/402964-1.png)