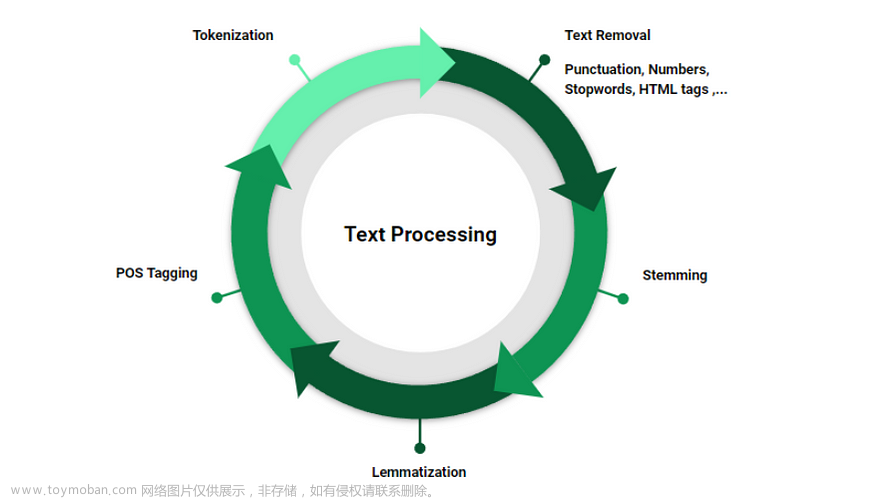
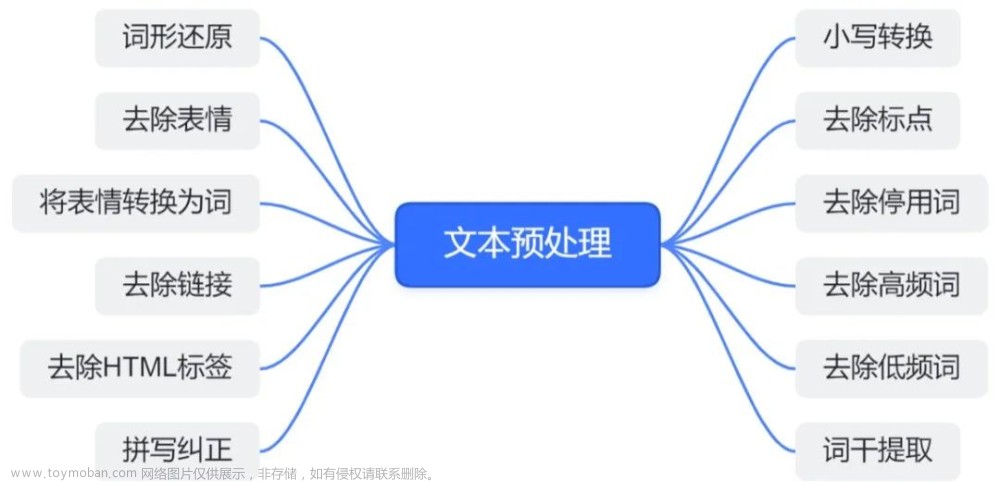
数据清洗是文本预处理的第一步,主要目的是去除文本中的噪声和无关信息,使文本更加干净、规范化。数据清洗通常包括以下几个方面:文章来源:https://www.toymoban.com/news/detail-407763.html
1 去除HTML标签
当我们从网页抓取文本数据时,可能会遇到包含HTML标签的文本。为了使文本更加可读,我们需要去除这些标签。可以使用Python的BeautifulSoup库来实现这一目的:文章来源地址https://www.toymoban.com/news/detail-407763.html
from bs4 import BeautifulSoup
html_text = "<html><head><title>Title</title></head><body><p>Some text here...</p></body></html>"
soup = BeautifulSoup(html_text, "html.parser")
clean_text = soup.get_text到了这里,关于【NLP入门教程】八、数据清洗的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!