Multi-class Token Transformer for Weakly Supervised Semantic Segmentation
摘要
本文提出了一种新的基于Transformer的框架,将特定于类的对象定位映射学习为弱监督语义分割(WSSS)的伪标签。
标准视觉Transformer中一个类Token 的参与区域可以被利用来形成一个类不确定的定位映射
本文研究了Transformer模型是否也可以通过学习Transformer中的多个类Token 来有效地捕获特定于类的注意力,以进行更具鉴别性的对象定位。
本文提出了一个Multi-class Token Transformer ,称为MCTformer,它使用多个类Token 来学习类Token 和patch Token 之间的交互。MCTformer可以成功地从对应的不同类token 的 class-to-patch attentions生成类 区分对象定位图。
作者还建议使用patch级的成对affinity关系,这是从patch到patch Transformer中提取的,以进一步细化局部图。此外,所提出的框架被证明完全补充了类激活映射(CAM)方法,在PASCAL VOC和MS COCO数据集上获得了非常出色的WSSS结果。这些结果强调了类token对于WSSS的重要性。

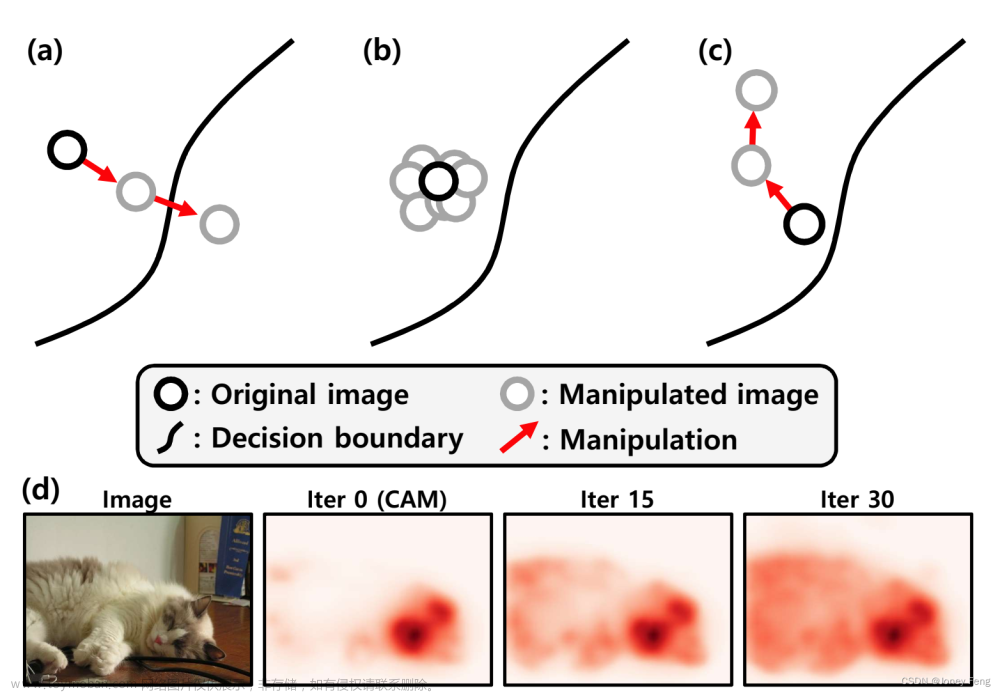
图(a)在之前的vit中,只有一个类token(红色方框)用于从patch token(蓝色方框)中聚合信息。与类token相对应的学习patch attention生成一个类不可知的定位映射。
(b)提议的MCTformer使用多个类token来学习类token和patch token之间的交互。学习到的不同类token的类到patch attention生成特定于类的对象定位映射。
本文方法
MCTformer-V1

首先将输入的RGB图像分割并转换为补丁标记序列。我们建议学习C个额外的类token,其中C是类的数量。C类token与patch token连接,并添加位置嵌入(PE),然后通过连续的L变压器编码层。
最后,输出C类token用于通过平均池生成类分数。将最后K层和多头注意力聚集在一起,生成最终的注意图,从中我们可以分别从类到patch和patch到patch的注意中提取特定于类的对象定位映射和patch级的成对亲和映射。patch级的成对亲和可以用于细化特定类的注意力图,以生成改进的对象定位图
MCTformer-V2

在MCTformer-V1中引入了CAM模块
CAM模块由卷积层和全局平均池(GAP)层组成。
将来自最后一个转换器编码层的经过reshape的输出patch token作为输入,并输出类分数
对于MCTformer-V1,我们也使用输出类token来生成类分数。因此,通过将两种分类损失分别应用于两类预测,优化了整个模型。
在推理时,我们融合了MCT attention和PatchCAM图,通过从patch-to-patch transformer注意中提取patch affinity来进一步细化结果,从而生成最终的目标定位图。
其他细节:
模块融合:
Class-specific object localization map refinement:
patch2patch优化上面融合的模块文章来源:https://www.toymoban.com/news/detail-408115.html
实验结果

 文章来源地址https://www.toymoban.com/news/detail-408115.html
文章来源地址https://www.toymoban.com/news/detail-408115.html
到了这里,关于用于弱监督语义分割的多类token transformer的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!






![[CVPR2022] 用于 3D 医学图像分析的 Swin Transformers 的自监督预训练](https://imgs.yssmx.com/Uploads/2024/02/607339-1.png)



