实验1:Hadoop大数据平台安装实验
1. 实验目的
在大数据时代,存在很多开源的分布式数据采集、计算、存储技术,本实验将在熟练掌握几种常见Linux命令的基础上搭建几种常用的大数据采集、处理分析技术环境。
2. 实验环境
相关安装包下载:
链接:https://pan.baidu.com/s/1Wa2U3qstc54IAUCypcApSQ
提取码:lcd8
Hadoop大数据平台所需工具、软件包、版本及安装目录见下表:
| 软件包名 | 软件名称 | 版本 | 安装 |
|---|---|---|---|
| jdk-7u80-linux-x64.tar.gz | java软件开发工具包 | 1.7.80 | /usr/local/jdk1.7.0_80 |
| mysql-5.6.37-linux-glibc2.12-x86_64.tar.gz | MySQL | 5.6.37 | /usr/local/mysql |
| zookeeper-3.4.6.tar.gz | Zookeeper | 3.4.6 | /usr/local/zookeeper-3.4.6 |
| kafka_2.10-0.8.2.1.tgz | Kafka | 2.10.-0.8.2.1 | /usr/local/kafka_2.10.-0.8.2.1 |
| hadoop-2.6.5.tar.gz | Hadoop | 2.6.5 | /usr/local/hadoop-2.6.5 |
| hbase-1.2.6-bin.tar.gz | HBase | 1.2.6 | /usr/local/hbase-1.2.6 |
| apache-hive-1.1.0-bin.tar.gz | Hive | 1.1.0 | /usr/local/apache-hive-1.1.0-bin |
| mysql-connector-java-5.1.43-bin.jar | MySQL JDBC驱动 | 5.1.43 | /usr/local/mysql |
| scala-2.10.6.tgz | Scala | 2.10.6 | /usr/local/scala-2.10.6 |
| spark-1.6.3-bin-hadoop2.6.tgz | Spark | 1.6.3 | /usr/local/spark-1.6.3-binhadoop2.6 |
| apache-storm-1.1.1.tar.gz | Storm | 1.1.1 | /usr/local/apache-storm-1.1.1 |
所有虚拟机上需要安装的软件与服务如下表:
| 主机名 | 服务器名 |
|---|---|
| cluster1 | zookeeper, Kafka, HDFS(主), YARN(主), HBase(主), Hive, Spark(主), storm(主) |
| cluster2 | zookeeper, Kafka, MySQL, HDFS, YARN, HBase, Hive, Spark, storm |
| cluster3 | zookeeper, Kafka, HDFS, YARN, HBase, Hive, Spark, storm |
3. 实验过程
3.1 虚拟机的搭建
3.1.1 安装虚拟机
-
首先下载VirtualBox,点击新建

-
类型选择linux,版本选择Red Hat (64-bit)

-
内存大小为1024B

-
选择现在创建虚拟硬盘

-
VHD

-
动态分配

-
8.00GB

-
管理——>主机网络管理器

-
取消勾选DHCP;网卡—>手动配置网卡:IPv4
192.168.56.1网络掩码255.255.255.0
-
存储——>选择centos7的iso文件

-
网络——>网卡1——>NAT网络

-
网路——>网卡2——>Host-Only网路

-
开机——>中文

-
日期与时间——>上海——>完成

-
安装目标位置——>完成

-
网路和主机名——>以太网(enp0s3)——>开启——>主机名:cluster1 (cluster2\cluster3)

-
网路和主机名——>以太网(enp0s8)——>开启

-
开始安装

-
创建用户——>全名:cluster1 ; 设置root密码;完成配置

-
重启

按照上述的方法,再构建两台同样的虚拟机,分别为cluster2和cluster3
3.1.2 基本linux命令
首先以root身份登入cluster1
-
创建一个初始文件夹,以自己的姓名(英文)命名
mkdir zyw;进入该文件夹cd zyw,在这个文件夹下创建一个文件,命名为Hadoop.txt,touch Hadoop.txt
-
查看这个文件夹下的文件列表
ls。
-
在Hadoop.txt中写入“Hello Hadoop!”
vi Hadoop.txt,并保存:wq
-
在该文件夹中创建子文件夹”Sub”
mkdir Sub,随后将Hadoop.txt文件移动到子文件夹中mv Hadoop.txt ~/zyw/Sub
-
递归的删除整个初始文件夹
rm -rf ~/zyw/
3.2 准备工作
3.2.1 关闭Selinux
每台都要执行(我们安装的centOS最小版没有防火墙,在其他centOS上操作时必须要关闭防火墙)
// 关闭防火墙
# systemctl stop firewalld.service
// 禁止firewall 开机启动
# systemctl disable firewalld.service
// 开机关闭Selinux,编辑Selinux配置文件
# vi /etc/selinux/config
将SELINUX设置为disabled 如下: SELINUX=disabled
// 重启
# reboot

// 重启机器后root用户查看Selinux状态
# getenforce

显示Permissive 表示关闭成功。
3.2.2 安装软件
以下软件是安装时需要的依赖环境,安装MySQL时需要使用perl和libaio,ntpdate负责集群内服务器时间,screen用于新建后台任务。
每台都要执行
# yum install perl*
# yum install ntpdate
# yum install libaio
# yum install screen

3.3.3 检查网卡是否开机自启
每台都要执行
// 查看网卡名,看里面一个enp0s开头的是多少,由于我们开启了两块网卡,注意这两张都是什么名字
// 我的网卡名分别是enp0s3和enp0s8,还有一个lo,这个可以忽略不计
ip addr
//使用这条命令可以查看所有网卡的信息

注意:此处有两张网卡,分别是2:enp0s3和3:enp0s8,如果没有,可能是因为在安装系统的过程中,没有打开网络服务,或是网卡没有设定为开机自启。
接下来编辑网卡配置文件 编辑的第一个网卡的配置文件,应该是ip为10.0.2开头的那张网卡,网卡名为enp0s3
// 编辑网卡配置文件
#vi /etc/sysconfig/network-scripts/ifcfg-enp0s3
// 确认ONBOOT为yes,这个设置为yes后,该网卡会开机自启,不会开机连不上网 ONBOOT=yes

接下来编辑第二张网卡的配置文件,是enp0s8
# vi /etc/sysconfig/network-scripts/ifcfg-enp0s8
BOOTPROTO=none
ONBOOT=yes
新增IPADDR=192.168.56.121(cluster2设置为192.168.56.122,cluster3为192.168.56.123)
NETMASK=255.255.255.0
NETWORK=192.168.56.0
保存后关闭文件.
cluster1:
// 重启网络服务
# service network restart
//重启成功后会出现一个绿色的OK,失败则显示红色的failed,若失败,则使用reboot重启服务器即可。
//重启后,使用ip addr 命令查看enp0s8的网址已经成功修改!

cluster2,cluster3也按照上述的方式进行网络配置
然后分别使用Xshell 软件连接三台主机

使用xftp传输文件,分别连接到三台虚拟机。

3.3.4 修改hosts
// 记录当前ip地址,要记录第一张网卡的ip地址
# ip addr

// 修改hosts ,三台都需要
# vi /etc/hosts
// 在最下面添加一下几行内容,ip地址写你用ip addr里面显示的第一张网卡(enp0s3)的ip
10.0.2.4 cluster1
10.0.2.5 cluster2
10.0.2.6 cluster3

3.3.5 检查网络是否正常
// 在cluster1上
# ping cluster2
出现如下界面说明网络正常
3.3.6 新建hadoop用户
每台都要执行
新建hadoop用户,这个用户专门用来维护集群,因为实际中使用root用户的机会很少,而且不安全。
// 新建hadoop组
# groupadd hadoop
// 新建hadoop用户
# useradd -s /bin/bash -g hadoop -d /home/hadoop -m hadoop
// 修改hadoop这个用户的密码
# passwd hadoop

3.3.7生成ssh密钥并分发
只在cluster1上执行
// 生成ssh密钥(cluster1上),切换到hadoop用户
# su hadoop
$ ssh-keygen -t rsa
//然后一路回车

// 接下来分发密钥,请仔细观察显示的内容,会让你输入yes
$ ssh-copy-id cluster1
$ ssh-copy-id cluster2
$ ssh-copy-id cluster3

//测试ssh
$ssh cluster3
$exit
$ssh cluster2

3.3.8 安装NTP服务
三台都要安装
#yum install ntpdate
// cluster1上装ntp
# yum install ntp

// cluster1上执行以下操作
# vi /etc/ntp.conf
//注释如下4行

//并在最后加入:
restrict default ignore
restrict 10.0.2.0 mask 255.255.255.0 nomodify notrap
server 127.127.1.0

// 重启ntp服务
# service ntpd restart
// 设置ntp服务器开机自动启动
# chkconfig ntpd on

以下为客户端的配置(除cluster1外其他所有的机器,即cluster2和cluster3)
//设定每天00:00向服务器同步时间,并写入日志
# crontab -e

输入以下内容后保存并退出:
0 0 * * * /usr/sbin/ntpdate cluster1>> /root/ntpd.log
// 手动同步时间,需要在每台机器上(除ntp server),使用ntpdate cluster1同步时间
# ntpdate cluster1

3.3 安装MySQL
3.3.1 安装
只在cluster2上做以下内容,因为我们的集群中,只有cluster2上需要安装一个MySQL
# yum remove mysql mysql-server mysql-libs compat-mysql51
# rm -rf /var/lib/mysql
# rm -rf /etc/my.cnf
下载mysql-5.6.37-linux-glibc2.12-x86_64 (鼠标拖动即可)
# cp mysql-5.6.37-linux-glibc2.12-x86_64.tar.gz /usr/local/
// 解压到/usr/local/
# tar -zxvf mysql-5.6.37-linux-glibc2.12-x86_64.tar.gz
// 改名为mysql
# mv mysql-5.6.37-linux-glibc2.12-x86_64 mysql

// 修改环境变量
# vi /etc/profile 在最下面添加
export MYSQL_HOME=/usr/local/mysql
export PATH=$MYSQL_HOME/bin:$PATH

// 刷新环境变量
# source /etc/profile
// 新建mysql用户
# groupadd mysql
//在/etc/group中可以看到
# useradd -r -g mysql -s /bin/false mysql
//在/etc/passwd中可以看到
# cd /usr/local/mysql
# chown -R mysql:mysql .
# scripts/mysql_install_db --user=mysql

// 修改当前目录拥有者为root用户
# chown -R root .
// 修改当前data目录拥有者为mysql用户
# chown -R mysql data

// 新建一个虚拟窗口,叫mysql
# screen -S mysql
# bin/mysqld_safe --user=mysql &

// 退出虚拟窗口
# Ctrl+A+D
# cd /usr/local/mysql
// 登陆mysql
# bin/mysql
// 登陆成功后退出即可
# exit;

// 进行root账户密码的修改等操作
# bin/mysql_secure_installation
//首先要求输入root密码,由于我们没有设置过root密码,括号里面说了,如果没有root密码就直接按回车。
//是否设定root密码,选y,设定密码为cluster,
//是否移除匿名用户:y。
//然后有个是否关闭root账户的远程登录,选n,
//删除test这个数据库?y,
//更新权限?y,然后ok

// 查看mysql的进程号
# ps -ef | grep mysql
// 如果有的话就 kill 掉,保证 mysql 已经中断运行了
# kill 进程号

// 启动mysql
# /etc/init.d/mysql.server start -user=mysql

//还需要配置一下访问权限:
# su hadoop
$ mysql -u root -p 密码:cluster
mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'cluster' WITH GRANT OPTION;
mysql> FLUSH PRIVILEGES;

// 关闭mysql的指令(不需要执行)
# mysqladmin -u root -p shutdown
3.3.2 测试
mysql> create database test_table;
mysql> use test_table; mysql> create table userinfo(id int not null);
mysql> insert into userinfo values(1); mysql> select * from userinfo;
mysql> drop database test_table;
mysql> show databases;

3.4 安装JDK
3.4.1 安装
cluster1上执行
复制到cluster1的root目录下
$ su root
# cp jdk-7u80-linux-x64.tar.gz /usr/local/
# cd usr/local/
# tar -zxvf jdk-7u80-linux-x64.tar.gz
// 复制jdk到其他的服务器上
# scp -r /usr/local/jdk1.7.0_80/ cluster2:/usr/local/
# scp -r /usr/local/jdk1.7.0_80/ cluster3:/usr/local/
然后分别在三台服务器上修改环境变量
# vi /etc/profile
// 添加以下内容
export JAVA_HOME=/usr/local/jdk1.7.0_80/
export JRE_HOME=/usr/local/jdk1.7.0_80/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$JAVA_HOME:$PATH
3.4.2 测试
//配置生效
$source /etc/profile
//查看版本
$java -version
出现java的版本说明安装成功
3.5 安装ZooKeeper
3.5.1 安装
Cluster1上执行
将ZooKeerper的压缩包拖动到/usr/local目录下
// cluster1上 将zookeeper解压到/usr/local目录下
tar -zxvf zookeeper-3.4.6.tar.gz
//配置环境变量
# vi /etc/profile
// 添加以下内容
export ZOOKEEPER_HOME=/usr/local/zookeeper-3.4.6
export PATH=$ZOOKEEPER_HOME/bin:$PATH
//编辑配置文件:zoo.cfg
#cd cd /usr/local/zookeeper-3.4.6/conf
#cp zoo_sample.cfg zoo.cfg
#vi zoo.cfg

添加如下内容
# 数据存储目录
dataDir=/home/hadoop_files/hadoop_data/zookeeper
# 数据日志存储目录
dataLogDir=/home/hadoop_files/hadoop_logs/zookeeper/dataLog
# 集群节点和服务端口配置
server.1=cluster1:2888:3888
server.2=cluster2:2888:3888
server.3=cluster3:2888:3888
// 创建zookeeper的数据存储目录和日志存储目录
# mkdir -p /home/hadoop_files/hadoop_data/zookeeper
# mkdir -p /home/hadoop_files/hadoop_logs/zookeeper/dataLog
# mkdir -p /home/hadoop_files/hadoop_logs/zookeeper/logs
// 修改文件夹的权限
# chown -R hadoop:hadoop /home/hadoop_files
# chown -R hadoop:hadoop /usr/local/zookeeper-3.4.6
// 在cluster1号服务器的data目录中创建一个文件myid,输入内容为1
// myid应与zoo.cfg中的集群节点相匹配
# echo "1" >> /home/hadoop_files/hadoop_data/zookeeper/myid

// 修改zookeeper的日志输出路径(注意CDH版与原生版配置文件不同)
# vi bin/zkEnv.sh
// 将配置文件里面的以下项替换
if [ "x${ZOO_LOG_DIR}" = "x" ]
then
ZOO_LOG_DIR="/home/hadoop_files/hadoop_logs/zookeeper/logs"
fi
if [ "x${ZOO_LOG4J_PROP}" = "x" ]
then
ZOO_LOG4J_PROP="INFO,ROLLINGFILE"
fi

// 修改zookeeper的日志配置文件
# vi conf/log4j.properties
// 修改为以下内容:
zookeeper.root.logger=INFO,ROLLINGFILE log4j.appender.ROLLINGFILE=org.apache.log4j.DailyRollingFileAppender

//将这个zookeeper-3.4.6的目录复制到其他的两个节点上
# scp -r /usr/local/zookeeper-3.4.6 cluster2:/usr/local/
# scp -r /usr/local/zookeeper-3.4.6 cluster3:/usr/local/
//退回hadoop用户
#su hadoop
// 刷新环境变量
$ source /etc/profile
// 启动zookeeper
$ zkServer.sh start

cluster2上执行
// cluster2上面 改环境变量
#vi /etc/profile
//加入以下内容
export ZOOKEEPER_HOME=/usr/local/zookeeper-3.4.6
export PATH=$ZOOKEEPER_HOME/bin:$PATH
// 创建zookeeper的数据存储目录和日志存储目录
# mkdir -p /home/hadoop_files/hadoop_data/zookeeper
# mkdir -p /home/hadoop_files/hadoop_logs/zookeeper/dataLog
# mkdir -p /home/hadoop_files/hadoop_logs/zookeeper/logs
// 修改文件夹的权限
# chown -R hadoop:hadoop /home/hadoop_files
# chown -R hadoop:hadoop /usr/local/zookeeper-3.4.6
// 在cluster2号服务器的data目录中创建一个文件myid,输入内容为2
// myid应与zoo.cfg中的集群节点相匹配
# echo "2" >> /home/hadoop_files/hadoop_data/zookeeper/myid
//退回hadoop用户
#su hadoop
// 刷新环境变量
$ source /etc/profile
// 启动zookeeper
$ zkServer.sh start

cluster3上执行
// cluster3上面 改环境变量
#vi /etc/profile
//加入以下内容
export ZOOKEEPER_HOME=/usr/local/zookeeper-3.4.6
export PATH=$ZOOKEEPER_HOME/bin:$PATH
// 创建zookeeper的数据存储目录和日志存储目录 # mkdir -p /home/hadoop_files/hadoop_data/zookeeper
# mkdir -p /home/hadoop_files/hadoop_logs/zookeeper/dataLog
# mkdir -p /home/hadoop_files/hadoop_logs/zookeeper/logs
// 修改文件夹的权限
# chown -R hadoop:hadoop /home/hadoop_files
# chown -R hadoop:hadoop /usr/local/zookeeper-3.4.6
// 在cluster3号服务器的data目录中创建一个文件myid,输入内容为3
// myid应与zoo.cfg中的集群节点相匹配
# echo "3" >> /home/hadoop_files/hadoop_data/zookeeper/myid
//退回hadoop用户
#su hadoop
// 刷新环境变量
$ source /etc/profile
// 启动zookeeper
$ zkServer.sh start

// 三台zookeeper都启动后,使用jps命令查看进程是否启动
# jps
可以看到一个叫QuorumPeerMain的进程,说明zookeeper启动成功
// 查看zookeeper状态
$ zkServer.sh status
可以看到三台中有一个是leader,两个是follower
// 关闭zookeeper的命令 (关机前在每台上都要执行,这里不需要执行)
$ zkServer.sh stop
3.6 安装Kafaka
cluster1上执行
将Kafaka的压缩包拖动到/usr/local目录下
// cluster1上 将zookeeper解压到/usr/local目录下
#cd /usr/local
#tar -zxvf kafka_2.10-0.8.2.1.tgz
//添加环境变量
vi /etc/profile
export KAFKA_HOME=/usr/local/kafka_2.10-0.8.2.1
export PATH=$KAFKA_HOME/bin:$PATH
// 修改配置文件
# vi /usr/local/kafka_2.10-0.8.2.1/config/server.properties
// 修改下面3项
// 第一项:这个值要唯一,不同的机器不能相同,cluster1就写1,cluster2就写2,cluster3就写3
broker.id=1
// 第二项:修改日志路径
log.dirs=/home/hadoop_files/hadoop_logs/kafka
// 第三项:此处要写zookeeper集群的ip+端口号,逗号隔开
zookeeper.connect=cluster1:2181,cluster2:2181,cluster3:2181
// 第四项:此处要写对应机器的ip地址!
advertised.host.name=192.168.56.121

//修改完环境变量,更新配置文件
#source /etc/profile
// 保存退出后创建logs文件夹
# mkdir -p /home/hadoop_files/hadoop_logs/kafka
// 修改权限
# chown -R hadoop:hadoop /home/hadoop_files
# chown -R hadoop:hadoop /usr/local/kafka_2.10-0.8.2.1
// 复制文件夹
# scp -r /usr/local/kafka_2.10-0.8.2.1 cluster2:/usr/local/
# scp -r /usr/local/kafka_2.10-0.8.2.1 cluster3:/usr/local/
cluster2上执行
//修改配置文件
# vi /usr/local/kafka_2.10-0.8.2.1/config/server.properties
// 需要修改如下两项
broker.id=2
advertised.host.name=192.168.56.122
//添加环境变量
# vi /etc/profile
export KAFKA_HOME=/usr/local/kafka_2.10-0.8.2.1
export PATH=$KAFKA_HOME/bin:$PATH
// 保存退出后创建logs文件夹
# mkdir -p /home/hadoop_files/hadoop_logs/kafka
// 修改权限
# chown -R hadoop:hadoop /home/hadoop_files
# chown -R hadoop:hadoop /usr/local/kafka_2.10-0.8.2.1
在cluster3上执行
//修改配置文件
# vi /usr/local/kafka_2.10-0.8.2.1/config/server.properties
// 需要修改如下两项
broker.id=2
advertised.host.name=192.168.56.123
//添加环境变量
# vi /etc/profile
export KAFKA_HOME=/usr/local/kafka_2.10-0.8.2.1
export PATH=$KAFKA_HOME/bin:$PATH
// 保存退出后创建logs文件夹
# mkdir -p /home/hadoop_files/hadoop_logs/kafka
// 修改权限
# chown -R hadoop:hadoop /home/hadoop_files
# chown -R hadoop:hadoop /usr/local/kafka_2.10-0.8.2.1
在每台虚拟机上执行
// 使用hadoop用户启动kafka集群 先启动zookeeper集群,然后在kafka集群中的每个节点使用
# su hadoop
$ source /etc/profile
$ kafka-server-start.sh /usr/local/kafka_2.10-0.8.2.1/config/server.properties &
//启动完成后按回车即可

3.6.2 测试
// 创建topic
$ kafka-topics.sh --create --zookeeper cluster1:2181,cluster2:2181,cluster3:2181 --replication-factor 3 --partitions 1 --topic mykafka
// 查看Topic:
$ kafka-topics.sh --list --zookeeper cluster1:2181,cluster2:2181,cluster3:2181
//此时会显示Topic:mykafka
// 查看详细信息
$ kafka-topics.sh --describe --zookeeper cluster1:2181,cluster2:2181,cluster3:2181

// 发送消息(cluster1上执行)
$ kafka-console-producer.sh --broker-list localhost:9092 --topic mykafka
// 接收消息(cluster2上执行)
$ kafka-console-consumer.sh -zookeeper cluster1:2181,cluster2:2181,cluster3:2181 --topic mykafka --from-beginning
在cluster1输入”test“ ,可以在cluster2上看到相应的信息 ,按下Ctrl+C退出
// 关闭kafka,在每台上执行
$ kafka-server-stop.sh
//新建虚拟窗口kafka,在每台上执行
$ screen -S kafka
// 启动kafka集群,在每台上执行
$ kafka-server-start.sh /usr/local/kafka_2.10-0.8.2.1/config/server.properties
退出虚拟窗口kafka,在每台上执行 $ Ctrl+A+D ,在每台服务器上面执行jps可以看到Kafka进程在运行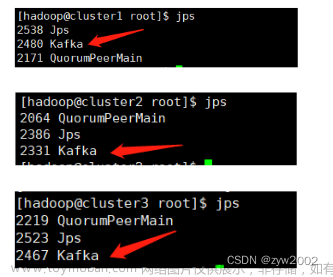
关闭kafka的命令为:在每台服务器上进入虚拟窗口kafka,然后使用kafka-server-stop.sh即可。
3.7 安装Hadoop
3.7.1 安装
Hadoop启动的先决条件是zookeeper已经成功启动
// 在cluster1节点/usr/local/解压hadoop安装包
$ su root # tar -zxvf hadoop-2.6.5.tar.gz
// 删除安装包
# rm hadoop-2.6.5.tar.gz
// 切换到存有hadoop配置文件的目录
# cd /usr/local/hadoop-2.6.5/etc/hadoop
// 修改hadoop-env.sh文件
# vi hadoop-env.sh
//将export JAVA_HOME=${JAVA_HOME}替换为
export JAVA_HOME=/usr/local/jdk1.7.0_80
export HADOOP_PID_DIR=/home/hadoop_files
// 配置mapred-env.sh
# vi mapred-env.sh
export HADOOP_MAPRED_PID_DIR=/home/hadoop_files
// 配置core-site.xml文件
# vi core-site.xml
core-site.xml 添加如下内容
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop_files/hadoop_tmp/hadoop/data/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>cluster1:2181,cluster2:2181,cluster3:2181</value>
</property>
</configuration>
// 配置hdfs-site.xml文件
# vi hdfs-site.xml
hdfs-site.xml 添加如下内容:
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop_files/hadoop_data/hadoop/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop_files/hadoop_data/hadoop/datanode</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>cluster1:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
// 配置mapred-site.xml文件
# vi mapred-site.xml
mapred-site.xml 添加如下内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>cluster1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>cluster1:19888</value>
</property>
</configuration>
// 配置yarn-site.xml文件
# vi yarn-site.xml
yarn-site.xml 添加如下内容:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.web-proxy.address</name>
<value>cluster2:8888</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/home/hadoop_files/hadoop_logs/yarn</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>cluster1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>cluster1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>cluster1:8031</value>
</property>
</configuration>
// 配置slaves文件
# vi slaves
//删除localhost
//添加以下内容:
cluster1
cluster2
cluster3
// 创建配置文件中涉及的目录(在所有结点上)
# mkdir -p /home/hadoop_files/hadoop_data/hadoop/namenode
# mkdir -p /home/hadoop_files/hadoop_data/hadoop/datanode
# mkdir -p /home/hadoop_files/hadoop_tmp/hadoop/data/tmp
# mkdir -p /home/hadoop_files/hadoop_logs/yarn
// 将cluster1的hadoop工作目录同步到集群其它节点
$ scp -r /usr/local/hadoop-2.6.5 cluster2:/usr/local/
$ scp -r /usr/local/hadoop-2.6.5 cluster3:/usr/local/
// 修改文件夹权限(在所有结点上)
# chown -R hadoop:hadoop /home/hadoop_files/
# chown -R hadoop:hadoop /usr/local/hadoop-2.6.5/
// 在集群各节点上修改环境变量
# vi /etc/profile
//添加如下变量
export HADOOP_HOME=/usr/local/hadoop-2.6.5
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
// 使修改的环境变量生效
$ source /etc/profile
// 启动zookeeper集群(分别在cluster1, cluster2和cluster3上执行)
$ zkServer.sh start
接下来开始格式化:
// 启动journalnode(在所有datanode上执行,也就是cluster1, cluster2, cluster3)
$ hadoop-daemon.sh start journalnode
启动后使用jps命令可以看到JournalNode进程
// 格式化HDFS(在cluster1上执行)
$ hdfs namenode -format

// 格式化完毕后可关闭journalnode(在所有datanode上执行)
$ hadoop-daemon.sh stop journalnode
// 启动HDFS(cluster1上)
$ start-dfs.sh

// 启动后cluster1上使用jps可以看到NameNode, DataNode, SecondaryNameNode cluster2和cluster3上可以看到DataNode
$ jps

// 启动YARN(cluster1上)
$ start-yarn.sh
// 启动后cluster1上使用jps可以看到NodeManager, ResourceManager cluster2和cluster3上可以看到NodeManager
$ jps

// 以下两条命令是关闭YARN和HDFS的命令,重启服务器或关机前一定要执行,否则有可能导致数据或服务损坏
// 关闭YARN的命令(cluster1上)
$ stop-yarn.sh
// 关闭HDFS的命令(cluster1上)
$ stop-dfs.sh
3.7.2 测试
启动HDFS后,可以在浏览器中,打开192.168.56.121:50070,可以看到HDFS的web界面
第一页Overview是当前HDFS的概况,里面显示了HDFS的启动时间,版本等信息。 点击上面标签栏的第二项Datanodes,可以看到如下界面
这个页面显示了当前HDFS中的可用节点。
启动YARN后,可以通过浏览器访问192.168.56.121:8088,查看YARN的web界面
该页面展示了所有提交到YARN上的程序,点击左侧的Nodes可以看到YARN的节点
命令行测试:
// cluster1
// 切换至hadoop用户的主目录
$ cd ~/
// 新建一个测试文件
$ vi testfile
//输入
1
2
3
// 保存退出
// 查看HDFS根目录的文件
$ hdfs dfs -ls /
// 在HDFS的根目录创建test目录
$ hdfs dfs -mkdir /test
// 创建完文件夹后再次查看根目录,查看目录是否新建成功
$ hdfs dfs -ls /
// 将测试文件testfile上传至HDFS根目录下的test目录中
$ hdfs dfs -put testfile /test
如果出现了mkdir: Cannot create directory /test. Name node is in safe mode.说明HDFS刚启动不久,还在安全检查中。由于我们的笔记本性能不够强,安全检查的时间会很长,可以使用命令退出安全模式,看到Safe mode is OFF,再执行上面的创建目录的命令 $ hdfs dfsadmin -safemode leave

// 在cluster2上
// 切换至hadoop用户的主目录
$ cd ~/
// 查看HDFS根目录
$ hdfs dfs -ls /
// 查看HDFS根目录下的test目录,可以看到我们刚才在cluster1上上传的文件testfile
$ hdfs dfs -ls /test
// 查看HDFS上的/test/testfile文件的内容
$ hdfs dfs -cat /test/testfile
// 将HDFS上的/test/testfile下载到本地
$ hdfs dfs -get /test/testfile
// 查看本地当前目录内的内容,可以看到刚才下载的testfile
$ ls

3.8 安装HBase
3.8.1 安装
HBase启动的先决条件是zookeeper和Hadoop已经启动
// 切换至root用户
$ su root
// 在cluster1节点/usr/local/解压hbase安装包
# tar -zxvf hbase-1.2.6-bin.tar.gz
// 进入hbase的conf目录 #cd /usr/local/hbase-1.2.6/conf/
// 修改hbase-env.sh
# vi hbase-env.sh
//将JAVA_HOME, HADOOP_HOME, HBASE_LOG_DIR, HBASE_MANAGES_ZK修改为以下内容:
# 配置JDK安装路径
export JAVA_HOME=/usr/local/jdk1.7.0_80
# 配置Hadoop安装路径
export HADOOP_HOME=/usr/local/hadoop-2.6.5
# 设置HBase的日志目录
export HBASE_LOG_DIR=/home/hadoop_files/hadoop_logs/hbase/logs
# 使用独立的ZooKeeper集群
export HBASE_MANAGES_ZK=false
# 设置pid的路径
export HBASE_PID_DIR=/home/hadoop_files
// 配置hbase-site.xml
# vi hbase-site.xml
修改hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://cluster1:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.master</name>
<value>60000</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/home/hadoop_files/hadoop_tmp/hbase/tmp</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>cluster1,cluster2,cluster3</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hadoop_files/hadoop_data/zookeeper</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>zookeeper.session.timeout</name>
<value>120000</value>
</property>
<property>
<name>hbase.regionserver.restart.on.zk.expire</name>
<value>true</value>
</property>
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
</property>
</configuration>
// 配置regionservers
# vi regionservers
//删除localhost
//添加:
cluster1
cluster2
cluster3
// 删除hbase的slf4j-log4j12-1.7.5.jar,解决hbase和hadoop的LSF4J包冲突
# cd /usr/local/hbase-1.2.6/lib
# mv slf4j-log4j12-1.7.5.jar slf4j-log4j12-1.7.5.jar.bk
// 将hbase工作目录同步到集群其它节点
# scp -r /usr/local/hbase-1.2.6/ cluster2:/usr/local/
# scp -r /usr/local/hbase-1.2.6/ cluster3:/usr/local/
// 创建hbase的缓存文件目录(所有节点)
# mkdir -p /home/hadoop_files/hadoop_tmp/hbase/tmp
// 创建hbase的日志文件目录(所有节点)
$ mkdir -p /home/hadoop_files/hadoop_logs/hbase/logs
// 改权限(所有节点)
# chown -R hadoop:hadoop /usr/local/hbase-1.2.6
# chown -R hadoop:hadoop /home/hadoop_files
// 在集群各节点上修改环境变量
# vi /etc/profile
export HBASE_HOME=/usr/local/hbase-1.2.6
export PATH=$HBASE_HOME/bin:$PATH $ source /etc/profile
先启动zookeeper,Hadoop的HDFS和YARN,然后才能启动HBase
// 启动HDFS(cluster1上)
$ start-dfs.sh
// 启动YARN(cluster1上)
$ start-yarn.sh
// 启动HBase(cluster1上)
$ start-hbase.sh
启动后cluster1上使用jps可以看到HMaster和HRegionServer cluster2和cluster3上可以看到HRegionServer
// 关机前执行关闭HBase的命令(cluster1上)
$ stop-hbase.sh

3.8.2 测试
用浏览器打开192.168.56.121:60010,可以看到HBase的web界面
测试HBase:
// cluster1上
$ hbase shell
hbase> create 'userinfotable',{NAME=>'username'},{NAME=>'fullname'},{NAME=>'homedir'}
hbase> put 'userinfotable','r1','username','vcsa'
hbase> put 'userinfotable','r2','username','sasuser'
hbase> scan 'userinfotable'
可以看到刚才插入的信息,在web界面也可以看到刚才建立的表。

删除刚才建立的表:
hbase> disable 'userinfotable'
hbase> drop 'userinfotable'
hbase> exit

3.9 安装Hive
3.9.1 安装
以下内容除在MySQL中创建hive用户和创建hive数据库只用操作一次,其他操作需要在每个Hadoop结点上都执行一次
注:hive能启动的先决条件是MySQL已经安装并配置完成,而且HDFS也要启动之后才能运行hive
$ su root
# cp apache-hive-1.1.0-bin.tar.gz /usr/local
# cd /usr/local # tar -zxvf ./apache-hive-1.1.0-bin.tar.gz
# vi /etc/profile
// 在下面加上两行:
export HIVE_HOME=/usr/local/apache-hive-1.1.0-bin
export PATH=$HIVE_HOME/bin:$HIVE_HOME/conf:$PATH
// root用户登陆MySQL
# mysql -u root -p
// 创建用户hive,密码hive
mysql> GRANT USAGE ON *.* TO 'hive'@'%' IDENTIFIED BY 'hive' WITH GRANT OPTION;
// 创建数据库hive
mysql> create database hive;
// 允许任意ip以hive登陆数据库
mysql> grant all on hive.* to hive@'%' identified by 'hive';
mysql> grant all on hive.* to hive@'localhost' identified by 'hive';
mysql> grant all on hive.* to hive@'cluster2' identified by 'hive';
// 刷新权限
mysql> flush privileges;
// 退出
mysql> exit;
# mysql -u hive -p
// 查看当前的数据库
mysql> show databases;
//若看到下面有hive这个库,
// 退出mysql
mysql> exit;

// 修改hive-site.xml
# cp apache-hive-1.1.0-bin/conf/hive-default.xml.template apache-hive-1.1.0-bin/conf/hive-site.xml
# vi apache-hive-1.1.0-bin/conf/hive-site.xml
找到以下property项,value值修改成如下,其他的在hive-site.xml中出现,但是下文没出现的就不需要更改了:
<property>
<name>javax.jdo.option.ConnectionURL </name>
<value>jdbc:mysql://cluster2:3306/hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName </name>
<value>com.mysql.jdbc.Driver </value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword </name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>Username to use against metastore database</description>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/home/hadoop_files/hadoop_tmp/hive/iotmp</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/home/hadoop_files/hadoop_tmp/hive/iotmp</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
<property>
<name>hive.querylog.location</name>
<value>/home/hadoop_files/hadoop_logs/hive/querylog</value>
<description>Location of Hive run time structured log file</description>
</property>
// 拷贝mysql-connector-java-5.1.43-bin.jar到hive的lib下面
# cp mysql-connector-java-5.1.43-bin.jar /usr/local/apache-hive-1.1.0-bin/lib/
// 把jline-2.12.jar拷贝到hadoop相应的目录下,替代jline-0.9.94.jar,否则启动会报错
# cp /usr/local/apache-hive-1.1.0-bin/lib/jline-2.12.jar /usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/
// 切换到hadoop目录中share/hadoop/yarn/lib
# cd /usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/
// 将hadoop-2.6.5/share/hadoop/yarn/lib/里面的jline-0.9.94重命名
# mv jline-0.9.94.jar jline-0.9.94.jar.bak
// 创建hive临时文件夹和日志目录
# mkdir -p /home/hadoop_files/hadoop_tmp/hive/iotmp
# mkdir -p /home/hadoop_files/hadoop_logs/hive/querylog
// 改一下权限
# chown -R hadoop:hadoop /home/hadoop_files/
# chown -R hadoop:hadoop /usr/local/apache-hive-1.1.0-bin
3.9.2 测试
// 打开hive客户端
$ hive
hive> create table test_table(id int, name string);
hive> insert into test_table values(1,”test”);

// 换台服务器
hive> show tables;
应该可以看到刚才创建的test_table
hive> select * from test_table;
hive> drop table test_table;
hive> show tables;
hive> exit;

3.10 安装Scala
//在cluster1上
$ su root # mv scala-2.10.6.tgz /usr/local
# tar -zxvf scala-2.10.6.tgz
# vi /etc/profile
//最下面加两行:
export SCALA_HOME=/usr/local/scala-2.10.6
export PATH=$SCALA_HOME/bin:$PATH
// 刷新环境变量
# source /etc/profile
// 查看版本,验证安装是否成功
# scala -version
// 复制到所有的服务器上
# scp -r /usr/local/scala-2.10.6 cluster2:/usr/local/
# scp -r /usr/local/scala-2.10.6 cluster3:/usr/local/
//在每一个节点上修改环境变量
#vi /etc/profile export SCALA_HOME=/usr/local/scala-2.10.6 export PATH=$SCALA_HOME/bin:$PATH
// 刷新环境变量 # source /etc/profile
// 修改文件夹权限(每一个节点都要操作)
# chown -R hadoop:hadoop /usr/local/scala-2.10.6


3.11 安装Spark
3.11.1 安装
(所有节点都要操作)
下载spark-1.6.3-bin-hadoop2.6.tgz
// 解压
# cp spark-1.6.3-bin-hadoop2.6.tgz /usr/local
# cd /usr/local/
# tar -zxvf spark-1.6.3-bin-hadoop2.6.tgz
# cd spark-1.6.3-bin-hadoop2.6
// 环境变量
# vi /etc/profile
添加以下内容:
export SPARK_HOME=/usr/local/spark-1.6.3-bin-hadoop2.6
export PATH=$SPARK_HOME/bin:$PATH
//主节点要再加一行(cluster1):
export PATH=$SPARK_HOME/sbin:$PATH
// 复制conf文件夹里面template一份,改名为spark-env.sh
# cp conf/spark-env.sh.template conf/spark-env.sh
// 在conf/spark-env.sh最下面加入以下7行:
#vi conf/spark-env.sh
export JAVA_HOME=/usr/local/jdk1.7.0_80
export SCALA_HOME=/usr/local/scala-2.10.6
export SPARK_MASTER_IP=cluster1
export HADOOP_CONF_DIR=/usr/local/hadoop-2.6.5/etc/hadoop
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop-2.6.5/bin/hadoop classpath)
export SPARK_CLASSPATH=$HIVE_HOME/lib/mysql-connector-java-5.1.43-bin.jar
export SPARK_PID_DIR=/home/hadoop_files
// 在conf下面新建一个叫slaves的文件
# vi conf/slaves 添加以下几行
cluster1
cluster2
cluster3
// 将hive目录下conf文件夹中的hive-site.xml复制到spark的conf目录下
# cd /usr/local/
# cp apache-hive-1.1.0-bin/conf/hive-site.xml spark-1.6.3-bin-hadoop2.6/conf/
// 将hadoop/etc/hadoop文件中的hdfs-site.xml和core-site.xml文件复制到spark的conf目录下
# cp hadoop-2.6.5/etc/hadoop/hdfs-site.xml hadoop-2.6.5/etc/hadoop/core-site.xml spark-1.6.3-bin-hadoop2.6/conf/
// 将conf目录下的spark-defaults.conf.template复制一份,改名为spark-default.conf
# cd spark-1.6.3-bin-hadoop2.6/conf/
# cp spark-defaults.conf.template spark-defaults.conf
# vi spark-defaults.conf
// 在最下面加上下面这一行
spark.files file:///usr/local/spark-1.6.3-bin-hadoop2.6/conf/hdfs-site.xml,file:///usr/local/spark-1.6.3-bin-hadoop2.6/conf/core-site.xml
//保存后退出即可。
// 复制到所有的服务器上
# scp -r /usr/local/spark-1.6.3-bin-hadoop2.6 cluster2:/usr/local/
# scp -r /usr/local/spark-1.6.3-bin-hadoop2.6 cluster3:/usr/local/
// 修改spark文件夹的权限(每个spark结点)
# chown -R hadoop:hadoop /usr/local/spark-1.6.3-bin-hadoop2.6
// 运行Spark(cluster1上) 运行spark前需启动hadoop的HDFS和YARN
$ start-master.sh
$ start-slaves.sh
// 关闭Spark的命令(cluster1上)
$ stop-slaves.sh
$ stop-master.sh
3.11.2 测试
在cluster1上使用jps命令可以看到Master和Worker,cluster2和3上可以看到Worder 用浏览器访问192.168.56.121:8080可以看到Spark的web界面,可以看到3个worker


3.12 安装storm
storm需要python2.6以上的版本
// 查看python版本
# python
//可以在最上面一行看到python的版本
// 退出python交互式界面
>>> exit()
如果版本低于2.6,使用yum install python,安装Python2.7
以下都要在所有节点上操作
将下载的storm解压到/usr/local下
// 添加环境变量
# vi /etc/profile
export STORM_HOME=/usr/local/apache-storm-1.1.1
export PATH=$STORM_HOME/bin:$PATH
// 改一下权限
# chown -R hadoop:hadoop apache-storm-1.1.1
// 更改配置文件
# vi apache-storm-1.1.1/conf/storm.yaml
//里面有两个要改的地方
//第一个是
storm.zookeeper.servers : - “cluster1” - “cluster2” - “cluster3”
//第二个是加入一行
storm.local.dir : “/home/hadoop_files/hadoop_tmp/storm/tmp”
//切记:冒号左右要有空格,否则会报错could not found expected ‘ : ’ storm.local.dir的最左边也要有一个空格
// 然后新建tmp文件夹,改权限
# mkdir -p /home/hadoop_files/hadoop_tmp/storm/tmp
# chown -R hadoop:hadoop /home/hadoop_files
# chown -R hadoop:hadoop /usr/local/apache-storm-1.1.1
新建storm-master的虚拟窗口(cluster1)
$ screen -S storm-master
$ storm nimbus
$ Ctrl+A+D

新建storm-supervisor的虚拟窗口(cluster2,cluster3)
$ screen -S storm-supervisor
$ storm supervisor
$ Ctrl+A+D

新建storm-ui的虚拟窗口(cluster1)
$ screen -S storm-ui
$ storm ui
$ Ctrl+A+D

新建storm-logviewer的虚拟窗口(cluster1,cluster2,cluster3)
$ screen -S storm-logviewer
$ storm logviewer
$ Ctrl+A+D

使用jps可以看到以下进程
cluster1:nimbus, core, logviewer
cluster2:Supervisor, logviewer
cluster3:Supervisor, logviewer
关闭的过程就是按逆向的顺序进入虚拟窗口后,使用Ctrl+C退出即可。
4. 踩坑记录
-
所有的linux命令都找不到了
【问题背景】有一次开虚拟机的时候,准备接着往下做实验,突然所有的基本linux命令都找不到了!比如sudo、vi等等,这个时候我推测大概率是\etc\profile\配置文件出错了,但是用vi命令又不能用,没办法打开profile文件,怎末办呢?于是在网上找到两种解决方案
【方案一】直接在linux命令行界面输入如下,然后回车(导入环境变量,以及shell常见的命令的存放地址):export PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin
【方案二】如果系统所有命令都不能使用时,还可以使用绝对命令vi打开profile/bin/vi /etc/profile在系统的配置文件中添加环境变量export PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin
然后我成功的打开了/etc/profile/文件,发现一个path后面不知道啥时候手误,多加了一个/。然后我把/删除了,最后刷新source /etc/profile就可以啦。 -
输入jps的时候出现"process information unavaliable"
【问题的背景】我在root用户下kill掉了hadoop用户下创建的进程,导致系统无法识别
【解决方案】找到/tmp/hsperfdata_hadoop文件夹下和不能识别的进程名同名的文件,删除了即可。
-
启动后,输入jps后一些进程并没有出现
【问题背景】有时候我明明启动了hdfs, 和yarn等,但是在其他的cluster2和cluster3输入jps的时候一些该出现的进程并没有出现。
【解决方案】最好先reboot一下(防止出现process information unavaliable),然后要注意所有的启动和jps命令都要在hadoop用户下输入!这样就可以解决这个问题啦。文章来源:https://www.toymoban.com/news/detail-408308.html
5. 心得体会
在这个实验的过程中,由于老师给了详细的操作文档感觉难度不是很大,主要是工作量很大,而且要非常的细心。比如说要分清楚哪些是root用户下执行的,哪些是hadoop用户下执行的;还比如那些命令是要在cluster1,哪些是需要在cluster2和cluster3上执行的等等,这些一定要分清楚。
在这个过程中最大的收获是学习和熟练了linux的基本命令和一些概念,比如说复制,拷贝,用户组,环境变量,权限等等,在边学习的过程中便阅读了《Linux系统命令和shell编程指南》一书,感觉这种边学边用,效果很不错。
同时,作为组长,觉得大家在小组里交流的氛围特别好。有一次自己因为粗心没有发现网卡配置的问题,拍图发在群里,大家一眼就看出来我的问题,非常热心的解答。除此之外,大家互相帮助,分享自己踩过的坑和解决方案,共同进步。文章来源地址https://www.toymoban.com/news/detail-408308.html
到了这里,关于大数据平台安装实验: ZooKeeper、Kafka、Hadoop、Hbase、Hive、Scala、Spark、Storm的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!









