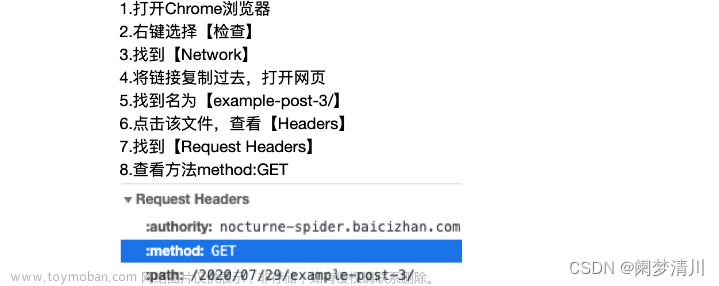
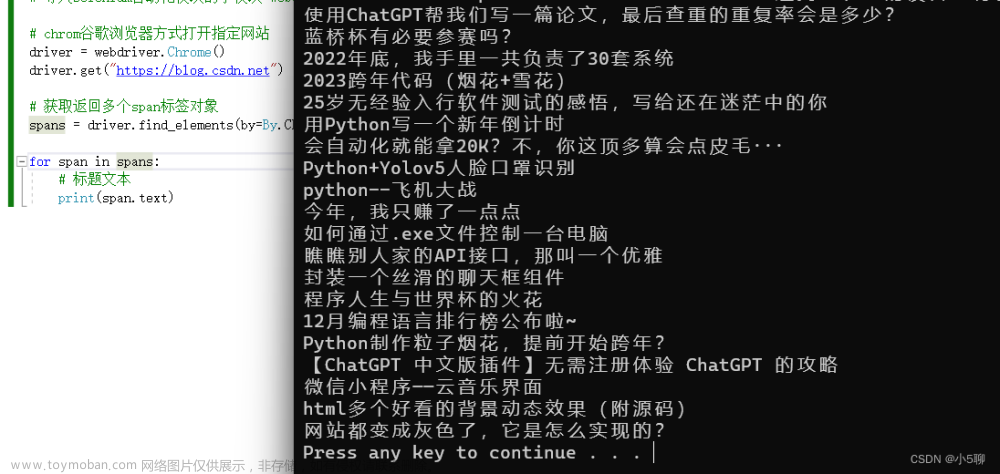
#导入requests模块
import requests
#a,b赋值的是文件名和后缀
a=['xx','xxx','123','xihuan','666']
b=['jpg','jpeg','png','gif','zip','rar','php']
#for循环a+b
for name1 in a:
for name2 in b:
name=(name1+'.'+name2)
q=requests.get('http://ip/'+name)
q.status_code文章来源:https://www.toymoban.com/news/detail-409068.html
print(name)
print(q)文章来源地址https://www.toymoban.com/news/detail-409068.html
到了这里,关于简单的python爬虫的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!