1、项目的的相关背景
搜索引擎是指根据一定的策略、运用特定的计算机程序从互联网上采集信息,在对信息进行组织和处理后,为用户提供检索服务,将检索的相关信息展示给用户的系统。
国内有许多做搜索的公司:百度、搜狗、360搜索等等。
这些大型公司做的搜索引擎是全网搜索,背后也是有巨大的团队支撑,单单靠几个人是完全不可能的完成的。
所以,我这次做的是一个小型的搜索引擎。
1.1 什么样的搜索引擎
学C++朋友都应该知道Boost库吧,需要用到现成的东西就需要去官网查找,但Boost官网中并没有站内搜索,所以这次的项目就是基于Boost官网的站内搜索引擎。
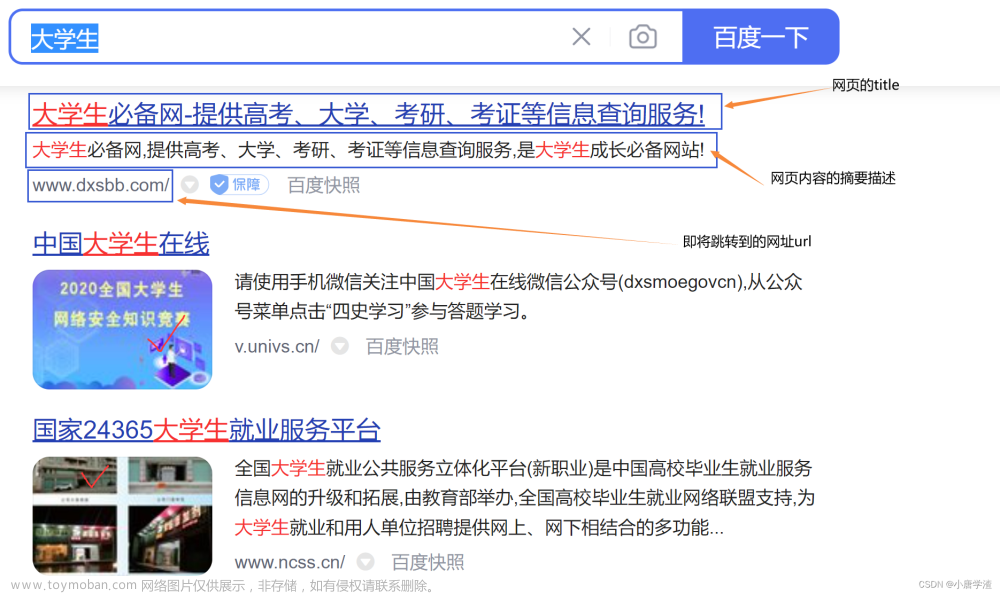
在实现项目之前,需要了解搜索成功后,需要将哪些内容呈现给用户,可以对标一下其它的搜索引擎。
百度:
搜狗:
360搜索:
根据上面的搜索结果可以发现,都包含了标题,正文,url链接。所以我们的搜索结果也以这样的方式呈现。
项目效果
后台数据:

前端页面:

2、搜索引擎的相关宏观原理图

3、搜索引擎技术栈和项目环境
- 技术栈: C/C++,C++11,STL,准标准库Boost(用于对文件的处理),Jsoncpp(进行序列化和反序列化),cppjieba(对html中的内容进行分词处理),cpp-httplib(c++封装的http开源库),html5,css,js,jQuery,Ajax(进行前后端交互)
- 项目环境: Centos 7云服务器,vim/gcc(g++)/Makefile,vscode
4、 正排索引 vs 倒排索引——搜索引擎具体原理
正排索引: 根据文档ID映射文档内容,只要文档ID正确,就一定能找到对应的文档
| 文档ID | 文档内容 |
|---|---|
| 1 | 重庆今年特别热,不愧为中国的火炉呀 |
| 2 | 重庆是中国的四大火炉之首 |
对目标文档进行分词,目的是为了方便建立倒排索引和查找
- 重庆今年特别热:重庆/今年/特别/热/特别热/不愧/中国/火炉
- 重庆是中国的四大火炉之首:重庆/中国/四大火炉/火炉/之首
像"的",“呀"之类的词,几乎在所有的文章都有大量出现,不应该作为搜索的关键词,这类词称之为**“暂停词”**,类似的还有"了”、"吗"等等,对此,不给予考虑。
倒排索引: 根据文档内容,分词,整理不重复的各个关键字,对应联系到文档ID的方案
| 关键词(具有唯一性) | 对应的文档ID |
|---|---|
| 重庆 | 文档1、文档2 |
| 今年 | 文档1 |
| 特别 | 文档1 |
| 热 | 文档1 |
| 中国 | 文档1、文档2 |
| 特别热 | 文档1 |
| 火炉 | 文档1、文档2 |
| 四大火炉 | 文档2 |
| 不愧 | 文档1 |
| 四大火炉 | 文档2 |
| 之首 | 文档2 |
模拟一次查找的过程: 输入关键词火炉,通过倒排索引提取对应的文档ID,在正排索引中,通过文档ID获取文档内容,对文档内容中的title、conent(desc)、url文档结果进行摘要,最后构成响应结果
此时有两个细节:
细节一:需要用到权值(weight)对搜索到的文档结果进行排序,而权值根据关键词在标题中是否出现以及在内容中出现的次数决定
细节二:搜索的内容可能不是一个关键词,而是一条语句,语句经过分词处理,被处理成多个关键词,多个关键词可能对应着同一个文档,此时需要进行去重处理
5、 编写数据去标签与数据清洗的模块Parser
5.1 获取原始数据

到Boost官网下载boost_1_79_0.tar.gz,也可以下载其它版本
链接:https://www.boost.org/users/history/version_1_79_0.html
下载好后,通过rz -E命令将下载好的压缩文件上传到服务器上
通过命名tar xzf 进行解压,例如:tar xzf boost_1_78_0.tar.gz
然后进入boost_1_79_0这个文件夹,就可以看到文件的内容
因为Boost的大部分网页内容都在doc/html下,这也是搜索的数据源,将其拷贝到data/input
mkdir -p data/input 创建目录
cp -rf boost_1_78_0/doc/html/* data/input/ 拷贝doc/html下的所有html文件
5.2 为什么要进行数据清洗
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>Chapter?41.?Boost.Typeof</title>
<link rel="stylesheet" href="../../doc/src/boostbook.css" type="text/css">
<meta name="generator" content="DocBook XSL Stylesheets V1.79.1">
<link rel="home" href="index.html" title="The Boost C++ Libraries BoostBook Documentation Subset">
<link rel="up" href="libraries.html" title="Part?I.?The Boost C++ Libraries (BoostBook Subset)">
<link rel="prev" href="boost_typeindex/acknowledgements.html" title="Acknowledgements">
<link rel="next" href="typeof/tuto.html" title="Tutorial">
</head>
<body bgcolor="white" text="black" link="#0000FF" vlink="#840084" alink="#0000FF">
<table cellpadding="2" width="100%"><tr>
<td valign="top"><img alt="Boost C++ Libraries" width="277" height="86" src="../../boost.png"></td>
<td align="center"><a href="../../index.html">Home</a></td>
<td align="center"><a href="../../libs/libraries.htm">Libraries</a></td>
<td align="center"><a href="http://www.boost.org/users/people.html">People</a></td>
<td align="center"><a href="http://www.boost.org/users/faq.html">FAQ</a></td>
<td align="center"><a href="../../more/index.htm">More</a></td>
</tr></table>
<hr>
<div class="spirit-nav"><a accesskey="p" href="boost_typeindex/acknowledgements.html"><img src="../../doc/src/images/prev.png" alt="Prev"></a>
<a accesskey="u" href="libraries.html"><img src="../../doc/src/images/up.png" alt="Up"></a>
<a accesskey="h" href="index.html"><img src="../../doc/src/images/home.png" alt="Home"></a>
<a accesskey="n" href="typeof/tuto.html"><img src="../../doc/src/images/next.png" alt="Next"></a>
上面是一个html页面的部分内容,除了需要的标题,内容之外,还有大量的双标签和单标签,这些是标签之中的内容跟搜索毫无关系,需要去除,然后保留其他有价值的内容
数据清洗后的每个文档之间用’\3’作为分割符,然后将其放到data/raw_html/raw.txt中
为什么要用’\3’作为文档之间的分隔符?
因为它是不可显示的控制字符,不会显示,不会污染我们形成的新的文档。如果原意,也可以采用其他不可显示的字符。
5.3 编写parser.cpp
5.3.1 整体框架
#include <iostream>
#include <string>
#include <vector>
#include <boost/filesystem.hpp>
#include "util.hpp"
//是一个目录,下面放的是所有的html网页
const std::string src_path = "data/input";
//用来存放解析的内容
const std::string output = "data/raw_html/raw.txt";
typedef struct DocInfo
{
std::string title; //文档的标题
std::string content; //文档的内容
std::string url; //文档在官网中的url
} DocInfo_t;
// const&:输入
//*:输出
//&:输入输出
bool EnumFile(const std::string &src_path, std::vector<std::string> *files_list);
bool ParseHtml(const std::vector<std::string> &files_list, std::vector<DocInfo_t> *results);
bool SaveHtml(const std::vector<DocInfo_t> &results, const std::string &output);
int main()
{
std::vector<std::string> files_list;
//第一步,递归式的把每个html文件名+路径,保存到file_list中,方便后期进行文件读取
//例如:data/input/.......
if (!EnumFile(src_path, &files_list))
{
std::cerr << "enum file name error" << std::endl;
return 1;
}
//第二步,读取file_list中的每个文件内容(文件名+路径确定唯一文件),并进行解析
std::vector<DocInfo_t> results;
if (!ParseHtml(files_list, &results))
{
std::cerr << "parse html error" << std::endl;
return 2;
}
//第三步,把解析完毕的各个文件内容,写入到output,以\3作为每个文件的分隔符
if (!SaveHtml(results, output))
{
std::cerr << "save html error" << std::endl;
return 3;
}
return 0;
}
第一步: 递归式的把每个html文件名+路径,保存到file_list中,方便后期进行文件读取
第二步: 读取file_list中的每个文件内容(文件名+路径确定唯一文件),并进行解析
第三步: 把解析完毕的各个文件内容,写入到output,以\3作为每个文件的分隔符
5.3.2 保存html的文件名
因为这里有文件操作,所以需要用到Boost开发库中的一些文件操作函数。
Boost库的安装命令: sudo yum install -y boost-devel
Boost库中的文件操作具体细节可以在官网查看
安装好后,就能进行相关代码的编写,具体如下:
bool EnumFile(const std::string &src_path, std::vector<std::string> *files_list)
{
// boost库下的文件操作函数名全在filesystem的命名空间下
namespace fs = boost::filesystem;
fs::path root_path(src_path);
//判断路径是否存在,不存在就没必要继续了
if (!fs::exists(root_path))
{
std::cerr << src_path << "not exists" << std::endl;
return false;
}
//定义一个空的迭代器,用来进行判断递归是否结束
fs::recursive_directory_iterator end;
for (fs::recursive_directory_iterator iter(root_path); iter != end; ++iter)
{
//判断当前路径下的当前文件是否是普通文件,html都是普通文件
// if (!fs::is_regular_file(*iter))
// {
// continue;
// }
// //判断当前文件l路径名的后缀是否是复合要求,即是否是html文件
// // path()获取当前路径,extension()获取后缀
// if (iter->path().extension() != ".html")
// {
// continue;
// }
//上述两步可以合并为一步
if (!fs::is_regular_file(*iter) || iter->path().extension() != ".html")
{
continue;
}
//当前的路径一定是一个合法的,以html结束的普通网页文件
// path()是一个路径对象,需要对象里面的路径转化为字符串
//将所有带路径的thml保存到files_list中,方便后续进行文本分析
files_list->push_back(iter->path().string());
}
return true;
}
5.3.3 解析html文件
解析html文件一共分为四步
第一步:通过保存下来的文件名(路径),读取文件的内容
第二步:提取文件标题(title)
第三步:提取文件正文(content)
第四步:构建该网页的url链接
bool ParseHtml(const std::vector<std::string> &files_list, std::vector<DocInfo_t> *results)
{
for (const std::string &file : files_list)
{
// 1.读取文件, Read()
std::string result;
if (!ns_util::FileUtil::ReadFile(file, &result))
{
continue;
}
// 2.解析指定文件。提取title
DocInfo doc;
if (!ParseTitle(result, &doc.title))
{
continue;
}
// 3.解析指定文件,提取content
if (!ParseContent(result, &doc.content))
{
continue;
}
// 4.解析指定的文件路径,构建url
if (!ParseUrl(file, &doc.url))
{
continue;
}
// done,一定是完成了解析任务,当前文档的相关结果都保存在了doc里面
results->push_back(std::move(doc)); //移动拷贝,提高效率
}
return true;
}
如何读取html文件内容?
打开对应的文件,一行一行的读取数据,读取完关闭文件。如果中间出错,则返回false。不过这个函数放在了util.hpp下的namespace ns_util中
class FileUtil
{
public:
static bool ReadFile(const std::string &file_path, std::string *out)
{
std::ifstream in(file_path, std::ios::in);
if (!in.is_open())
{
std::cerr << "open file" << file_path << "error" << std::endl;
return false;
}
std::string line;
while (std::getline(in, line)) // getline的返回值是一个&,对其进行判断时,重载了强制将类型转换
{
*out += line;
}
in.close();
return true;
}
};
如何提取标题?
先回顾之前的html文件,在第一次出现< title> 和< /title>之间的内容一定是标题。
首先,需要找到<title>在文件内容中的位置(begin),其次再找到</title>在文件内容中的位置(end),最后begin+<title>的长度就是标题的起始位置,end-起始位置就是标题的长度

static bool ParseTitle(const std::string &file, std::string *title)
{
std::size_t begin = file.find("<title>");
if (begin == std::string::npos)
{
return false;
}
std::size_t end = file.find("</title>");
if (end == std::string::npos)
{
return false;
}
begin += std::string("<title>").size();
if (begin > end)
{
return false;
}
//begin就是标题开始的位置,end-begin就是标题的长度
*title = file.substr(begin, end - begin);
return true;
}
如何提取正文?
html文件中含有大量的标签,不仅有单标签,还有双标签。标签都是使用一堆尖括号<>组成,提取正文的本质也就是将这些标签去除。
使用状态机去标签是一个很好的选择。
状态机的原理:
static bool ParseContent(const std::string &file, std::string *content)
{
//去标签,基于一个简单的状态机
enum status
{
LABLE,
CONTENT
};
enum status s = LABLE;
for (char c : file)
{
switch (s)
{
case LABLE:
if (c == '>')
s = CONTENT;
break;
case CONTENT:
if (c == '<')
s = LABLE;
else
{
//不保留原始文件中的\n,因为需要用\n作为html解析之后文本的分隔符
if (c == '\n')
c = ' ';
content->push_back(c);
}
break;
default:
break;
}
}
return true;
}
如何构建该网页的url链接?
我们获取的网页最终都是在https://www.boost.org/doc/libs/1_79_0/doc/html链接下的,这就是url链接的头部。
而我们已经获取了所有的html文件路径,因为所有的html文件在data/input目录下保存,所有所有的文件路径都是以/data/input为开头,只需要去掉/data/input,将剩下的部分作为尾部,然后将头部和尾部拼接在一起,就能获取完整的url链接。
例如:
https://www.boost.org/doc/libs/1_79_0/doc/html 头部
/accumulators.html 尾部
https://www.boost.org/doc/libs/1_79_0/doc/html/accumulators.html 头部+尾部=完整的url链接
static bool ParseUrl(const std::string &file_path, std::string *url)
{
//链接头部
std::string url_head = "https://www.boost.org/doc/libs/1_79_0/doc/html";
std::string url_tail = file_path.substr(src_path.size());
*url = url_head + url_tail;
return true;
}
至此,我们已经完成了解析html文件的所有功能。不过,需要注意的是,如果以上四步中,哪一步出错,都将舍弃这个html文件,然后再解析下一个html文件
5.3.4 保存已经解析的html文件
通过解析html文件,我们已经提取到了标题、正文、url链接。然后以标题\3正文\3url链接\n的格式进行存储,至于为什么用\3作为分割符,前面已经说过,这里不多赘述。
将所有的html文件都存放在data/raw_html/raw.txt中,各个html网页之间用\n作为分割符,方便后续操作
bool SaveHtml(const std::vector<DocInfo_t> &results, const std::string &output)
{
#define SEP '\3'
//按二进制方式写入
std::ofstream out(output, std::ios::out | std::ios::binary);
if(!out.is_open())
{
std::cerr<<"open "<<output<<"failed!"<<std::endl;
return false;
}
//可以进行文内容的写入了
//写入格式 title\3content\3url\n
for(auto& item:results)
{
std::string out_string;
out_string += item.title;
out_string += SEP;
out_string += item.content;
out_string += SEP;
out_string += item.url;
out_string += '\n';
//写入内容
out.write(out_string.c_str(), out_string.size());
}
out.close();
return true;
}
6、编写建立索引的模块Index
6.1 整体框架
正排索引是根据文档ID映射文档内容,文档内容又包括标题、正文和url链接,所以我们需要构建一个结构体来维护ID到文档内容的映射关系。
struct DocInfo
{
std::string title; //文档标题
std::string content; //文档去标签之后所对应的内容
std::string url; //官网文档url
uint64_t doc_id; //文档ID
};
std::vector<DocInfo> forward_index;
正排索引的数据结构用数组,因为数组的下标是天然的文档ID
倒排索引是由一个关键词映射多个文档。此时的文档并不是采用正排索引的文档(struct DocInfo)。考虑到数据冗余、根据权重排序的问题,需要定义一个包含文档ID、关键词和权重的结构。
关键词映射的多个文档组合在一起,我们称之为倒排拉链(由vector封装而成)。因为关键词具有唯一性,所以采用unordered_map来维护关键词和倒排拉链映射关系。
struct InvertedElem
{
int doc_id; //文档ID
std::string word; //关键词
int weight; //权重,用来排序
};
typedef std::vector<InvertedElem> InvertedList;
std::unordered_map<std::string, InvertedList> inverted_index;
有了正排索引和倒排索引,如何通过关键词获取文档?
通过关键词,经过unordered_map获取映射的倒排拉链,倒排拉链中有多个struct InvertedElem,每个都包含了文档ID。因为文档ID是vector forward_index的下标,所以就能获取文档
整体框架:
namespace ns_index
{
struct DocInfo
{
std::string title; //文档标题
std::string content; //文档去标签之后所对应的内容
std::string url; //官网文档url
uint64_t doc_id; //文档ID
};
struct InvertedElem
{
int doc_id; //文档ID
std::string word; //关键词
int weight; //权重,用来排序
};
//倒排拉链
typedef std::vector<InvertedElem> InvertedList;
class Index
{
private:
//正排索引的数据结构用数组,因为数组的下标是天然的文档ID
std::vector<DocInfo> forward_index;
//倒排索引一定是一个关键词和一组(多个)InvertedElem相对应(关键词和倒排拉链的映射关系)
std::unordered_map<std::string, InvertedList> inverted_index;
public:
Index() {}
~Index() {}
//根据doc_id找到文档内容
DocInfo *GetForwardIndex(uint64_t doc_id)
{
return nullptr;
}
//根据关键词string获取倒排拉链
InvertedList *GetInvertedList(const std::string &word)
{
return nullptr;
}
//根据去标签,格式化之后的文档,构建正排索引和倒排索引
// data/raw_html/raw.txt
bool BuildIndex(const std::string &input)
{
return true;
}
}
6.2 BuildIndex的编写
思路:首先打开经过清洗的html文件,然后一行一行的读取,每读取一行,就表示读取了一个html网页,因为在存在html网页时,是以\n作为分割符的。读取到的html文件包括文档ID和html内容,根据ID可以建立正排索引,根据html内容建立倒排索引
//根据去标签,格式化之后的文档,构建正排索引和倒排索引
// data/raw_html/raw.txt
bool BuildIndex(const std::string &input)
{
std::ifstream in(input, std::ios::in | std::ios::binary);
if (!in.is_open())
{
LOG(FATAL, input + "open error");
// std::cerr << "sorry " << input << "open error" << std::endl;
return false;
}
std::string line;
int count = 0;
while (std::getline(in, line))
{
//建立正排索引
DocInfo *doc = BuildForwardIndex(line);
if (doc == nullptr)
{
std::cerr << "bulid: " << line << " error" << std::endl; // fro debug
continue;
}
//建立倒排索引
BuildInvertedIndex(*doc);
}
return true;
}
6.2.1 建立正排索引
通过前面的步骤,已经成功提取到了html网页内容,而内容中的标题、正文和url链接通过’\3’作为分隔符。因此,我们需要用Boost库中的split函数将其解析出来,从而形成DocInfo,再插入forwardindex中,返回DocInfo的地址。
ns_util::StringUtil::Split是对Boost库中split的封装
DocInfo *BuildForwardIndex(const std::string &line)
{
// 1.解析line,字符串切分
// line->title content url
std::vector<std::string> results;
const std::string sep = "\3"; //行内分隔符
ns_util::StringUtil::Split(line, &results, sep);
//说明不包含完整的title content url
if (results.size() != 3)
{
return nullptr;
}
// 2.字符串进行填充到DocInfo
DocInfo doc;
doc.title = results[0];
doc.content = results[1];
doc.url = results[2];
doc.doc_id = forward_index.size(); //在没插入之前,forward_index.size()就是doc_id(下标)
// 3.插入到正排索引的vector中
forward_index.push_back(std::move(doc)); // move提高效率
return &forward_index.back();
}
class StringUtil
{
public:
static void Split(const std::string &target, std::vector<std::string> *out, const std::string &sep)
{
// boost split
//第一个参数:存放结果的地方
//第二个参数:需要进行分割的数据源
//第三个参数:分隔符
//第四个参数:是否对进行压缩 例如:fff\3\3\3lll不压缩->fff lll fff\3\3\3lll压缩->ffflll
boost::split(*out, target, boost::is_any_of(sep), boost::token_compress_on /*需要压缩*/);
}
};
以上就是建立正排索引的全部过程
6.2.2 建立倒排索引
因为搜索出的文档最终需要进行排序,那么就需要用到权重值。而关键词在标题和正文出现的不同,所以需要一下结构来记录关键词分别在标题和正文中出现的次数
struct word_cnt
{
int title_cnt; //关键词在标题出现的次数
int content_cnt; //关键词在正文出现的次数
word_cnt() : title_cnt(0), content_cnt(0) {}
};
不仅如此,我们还需要一个结构用来保存关键词和struct word_cnt的映射关系,所以使用unordered_map
std::unordered_map<std::string, word_cnt> word_map;
有了以上结构作为基础,我们就能对关键词进行词频统计
首先需要对标题和正文进行分词,分词的结果放在不同的vector<string>,通过遍历的方式,增加word_map中的struct word_cnt中的title_cnt和 content_cnt。
为了不区分大小写,统一转为小写处理。
这样就获得了完成的 word_map(用来暂存词频的映射表)。我们已经有了文档ID、关键词和词频记录,就能构建一个struct InvertedElem,然后插入到对应的倒排拉链中,至此,整个建立倒排拉链的过程就已经完成。
bool BuildInvertedIndex(const DocInfo &doc)
{
// DocInfo{title, content, url, doc_id}
// word->倒排拉链
struct word_cnt
{
int title_cnt; //关键词在标题出现的次数
int content_cnt; //关键词在正文出现的次数
word_cnt() : title_cnt(0), content_cnt(0) {}
};
std::unordered_map<std::string, word_cnt> word_map; //用来暂存词频的映射表
//对标题进行分词,结果放在title_words中
std::vector<std::string> title_words;
ns_util::JiebaUtil::CutString(doc.title, &title_words);
//对标题进行词频统计
for (std::string s : title_words) //这里不用&s的原因是将s转换为小写时,不需要改变原始数据
{
//进行词频统计时,将单词全都转换为小写,因为搜索不区分大小写
boost::to_lower(s);
word_map[s].title_cnt++; //如果word_map中存在s,就返回value的引用,否则就创建
}
//对文档内容进行分词,结果放在content_words中
std::vector<std::string> content_words;
ns_util::JiebaUtil::CutString(doc.content, &content_words);
//对文档内容进行词频统计
for (std::string s : content_words)
{
boost::to_lower(s);
word_map[s].content_cnt++;
}
#define X 10
#define Y 1
for (auto &word_pair : word_map)
{
InvertedElem item;
item.doc_id = doc.doc_id;
item.word = word_pair.first;
item.weight = X * word_pair.second.title_cnt + Y * word_pair.second.content_cnt; //相关性(权重)
InvertedList &inverted_list = inverted_index[word_pair.first]; //如果不存在就创建,并且返归value的引用。如果存在,直接返回value的引用
inverted_list.push_back(std::move(item)); //将item插入到所对应的倒排拉链中
}
return true;
}
因为这个功能使用到了cppjieba库中的分词功能,所以还需要引入cppjieba库
// 项目源文档:
https://github.com/yanyiwu/cppjieba
// 安装命令
git clone https://github.com/yanyiwu/cppjieba.git
const char *const DICT_PATH = "./dict/jieba.dict.utf8";
const char *const HMM_PATH = "./dict/hmm_model.utf8";
const char *const USER_DICT_PATH = "./dict/user.dict.utf8";
const char *const IDF_PATH = "./dict/idf.utf8";
const char *const STOP_WORD_PATH = "./dict/stop_words.utf8";
class JiebaUtil
{
private:
static cppjieba::Jieba jieba;
std::unordered_set<std::string> stop_words;
JiebaUtil() : jieba(DICT_PATH, HMM_PATH, USER_DICT_PATH, IDF_PATH, STOP_WORD_PATH) {}
JiebaUtil(const JiebaUtil &) = delete;
JiebaUtil operator=(const JiebaUtil &) = delete;
static JiebaUtil *instance;
public:
//获取暂停词
void InitJiebaUtil()
{
std::ifstream in(STOP_WORD_PATH);
std::string line;
while (std::getline(in, line))
{
stop_words.insert(line);
}
in.close();
}
void CutStringHelper(const std::string &src, std::vector<std::string> *out)
{
jieba.CutForSearch(src, *out);
//去掉暂停词会耗费大量的时间
for (auto iter = out->begin(); iter != out->end();)
{
//查看暂停词中是否存在当前词,如果存在就从out中删除这个词
auto it = stop_words.find(*iter);
if (it != stop_words.end())
{
iter = out->erase(iter);
}
else
{
++iter;
}
}
}
static void CutString(const std::string &src, std::vector<std::string> *out)
{
jieba.CutStringHelper(src, *out);
}
};
6.3 将Index设置为单例
因为我们对建立索引的html文件不会做任何修改,由于索引是由整个html文件构成,所以十分消耗内存,由此可见,只要需要存在一份即可。
因此,可以把Index设置为单例模式
private:
Index() {} //一定要有函数体,不能delete,用于第一次构造
Index(const Index &) = delete;
Index &operator=(const Index &) = delete;
//单例模式
static Index *instance;
static std::mutex mtx;
public:
~Index() {}
static Index *GetInstance()
{
//双判定加锁,提高效率
if (nullptr == instance)
{
mtx.lock();
if (nullptr == instance)
{
instance = new Index();
}
mtx.unlock();
}
return instance;
}
7、 编写搜索引擎模块Searcher
7.1 整体框架
到此,我们能通过关键词获取倒排拉链。但是获取的倒排拉链中可能存在重复文档,因为搜索的可能是一条语句被切分的多个关键词。
例如:文档内容为今天天气真热,而搜索的语句为今天天气真热,被切分为三个词,今天、天气、真热。所以搜索出的文档会出现三次。
所以,我们需要用到unordered_map对搜索出的文档进行去重,并将其添加到vector中,方便根据权重进行排序
最后再根据查找出来的结果,构建json串,对于正文部分,只需要截取一部分即可
namespace ns_searcher
{
struct InvertedElemPrint
{
int doc_id; //文档ID
int weight; //权重,用来排序
std::vector<std::string> words;
InvertedElemPrint() : doc_id(0), weight(0) {}
};
class Searcher
{
private:
ns_index::Index *index; //供系统进行查找的索引
public:
// query:搜索关键词
// json_string:返回给用户浏览器的搜索结果
void Search(const std::string &query, std::string *json_string)
{
// 1.[分词]:对我们的query进行按照searcher的要求进行分词
std::vector<std::string> words;
ns_util::JiebaUtil::CutString(query, &words);
// 2.[触发]:就是根据分词的各个“词”进行index查找-----建立index是忽略大小写的,所以搜索时,关键词也要忽略大小写(全转为小写)
//关键词可能被分为多个词,多个词对应多个倒排拉链,将这些倒排拉链都存放在inverted_list_all中
// ns_index::InvertedList inverted_list_all; //内部存放的是InvertedElem
std::vector<InvertedElemPrint> inverted_list_all; //内部存放的是InvertedElemPrint
std::unordered_map<int, InvertedElemPrint> tokens_map;
for (std::string word : words)
{
boost::to_lower(word);
// struct InvertedElem
// {
// int doc_id; //文档ID
// std::string word; //关键词
// int weight; //权重,用来排序
// };
// //倒排拉链
// typedef std::vector<InvertedElem> InvertedList;
//通过关键词获取倒排拉链
ns_index::InvertedList *inverted_list = index->GetInvertedList(word);
//倒排拉链可能为空,为空就继续获取下一个关键词的倒排拉链
if (nullptr == inverted_list)
{
continue;
}
//不完美,可能会存在重复文档
// inverted_list_all.insert(inverted_list_all.end(), inverted_list->begin(), inverted_list->end());
//fl/是/一个/程序员-------4个词可能指向了同一个文档,所以需要去重
for (const auto &elem : *inverted_list)
{
auto &item = tokens_map[elem.doc_id]; //返回InvertedElemPrint的引用
item.doc_id = elem.doc_id;
item.weight += elem.weight;
item.words.push_back(elem.word);
}
}
//将已经去重的文档存放在inverted_list_all中
for (const auto &item : tokens_map)
{
inverted_list_all.push_back(std::move(item.second));
}
// 3.[合并排序]:汇总查找结果,按照相关性[weight]进行降序排序
// std::sort(inverted_list_all.begin(), inverted_list_all.end(), [](const ns_index::InvertedElem &e1, const ns_index::InvertedElem &e2)
// { return e1.weight > e2.weight; });
std::sort(inverted_list_all.begin(), inverted_list_all.end(), [](const InvertedElemPrint &e1, const InvertedElemPrint &e2)
{ return e1.weight > e2.weight; });
// 4.[构建]:根据查找出来的结果,构建json串
Json::Value root;
for (auto &item : inverted_list_all)
{
ns_index::DocInfo *doc = index->GetForwardIndex(item.doc_id);
Json::Value elem;
elem["title"] = doc->title;
elem["desc"] = GetDesc(doc->content, item.words[0]); // content是文档的去标签的结果,但不是我们想要的结果,要的是一部分(摘要)
elem["url"] = doc->url;
// for debug
// elem["id"] = (int)doc->doc_id;
// elem["weight"] = item.weight;
//因为item是有序的,doc也是有序的,elem也是有序的,所以root里面的数据也是有序的
root.append(elem);
}
// Json::StyledWriter writer;
Json::FastWriter writer;
*json_string = writer.write(root);
}
//获取内容摘要
std::string GetDesc(const std::string &html_content, const std::string &word)
{
//找到word在html_content中首次出现,然后往前找50字节(如果没有,从begin开始),往后找100字节(如果没有,到end就可以)
//截取出这部分内容
// 1.找到首次出现
const std::size_t prev_step = 50;
const std::size_t next_step = 100;
//为什么不用string.find?
//因为搜索关键词为小写,但原始文档没有改变,可能是大写,此时就存在找不到的情况
auto iter = std::search(html_content.begin(), html_content.end(), word.begin(), word.end(), [](int x, int y)
{ return (std::tolower(x) == std::tolower(y)); });
if (iter == html_content.end())
{
return "None"; //这种情况是不能存在的,因为倒排拉链是对应word,这里只是为了保险起见
}
// distance计算两个迭代器之间的距离
std::size_t pos = std::distance(html_content.begin(), iter);
// 2.获取begin,end
std::size_t start = 0;
std::size_t end = html_content.size() - 1;
if (start + prev_step < pos)
{
start = pos - prev_step;
}
if (pos + next_step < end)
{
end = pos + next_step;
}
// 3.截取子串,然后return
if (start >= end)
{
return "None";
}
std::string desc = html_content.substr(start, end - start);
desc += "...";
return desc;
}
};
7.2 分词
对我们的query进行按照searcher的要求进行分词
std::vector<std::string> words;
ns_util::JiebaUtil::CutString(query, &words);
7.3 触发
建立index是忽略大小写的,所以搜索时,关键词也要忽略大小写(全转为小写)
关键词可能被分为多个词,多个词对应多个倒排拉链,将这些倒排拉链都存放在inverted_list_all中
std::vector<InvertedElemPrint> inverted_list_all; //内部存放的是InvertedElemPrint
std::unordered_map<int, InvertedElemPrint> tokens_map;
for (std::string word : words)
{
//全部转为小写
boost::to_lower(word);
//通过关键词获取倒排拉链
ns_index::InvertedList *inverted_list = index->GetInvertedList(word);
//倒排拉链可能为空,为空就继续获取下一个关键词的倒排拉链
if (nullptr == inverted_list)
{
continue;
}
//不完美,可能会存在重复文档
// inverted_list_all.insert(inverted_list_all.end(), inverted_list->begin(), inverted_list->end());
// fl/是/一个/程序员-------4个词可能指向了同一个文档,所以需要去重
for (const auto &elem : *inverted_list)
{
auto &item = tokens_map[elem.doc_id]; //返回InvertedElemPrint的引用
item.doc_id = elem.doc_id;
item.weight += elem.weight;
item.words.push_back(elem.word);
}
}
//将已经去重的文档存放在inverted_list_all中
for (const auto &item : tokens_map)
{
inverted_list_all.push_back(std::move(item.second));
}
7.4 合并排序
利用sort和lambda表示对文档按照权值进行降序排序
std::sort(inverted_list_all.begin(), inverted_list_all.end(), [](const InvertedElemPrint &e1, const InvertedElemPrint &e2)
{ return e1.weight > e2.weight; });
7.5 利用jsoncpp构建json串
在网路中传输的数据都是已经序列化的字符串,所以我们需要利用jsoncpp对传输的数据进行序列化。
因为jsoncpp是第三方库,也需要自行安装
sudo yum install -y jsoncpp-devel
Json::Value root;
for (auto &item : inverted_list_all)
{
ns_index::DocInfo *doc = index->GetForwardIndex(item.doc_id);
Json::Value elem;
elem["title"] = doc->title;
elem["desc"] = GetDesc(doc->content, item.words[0]); // content是文档的去标签的结果,但不是我们想要的结果,要的是一部分(摘要)
elem["url"] = doc->url;
//因为item是有序的,doc也是有序的,elem也是有序的,所以root里面的数据也是有序的
root.append(elem);
}
// Json::StyledWriter writer;
Json::FastWriter writer;
*json_string = writer.write(root);
7.5.1 获取内容摘要
因为在网页不需要显示的正文全部分,所以需要对正文进行摘要。摘要的原则是找到关键词在正文中首次出现的位置,然后往前找50字节(如果没有,从begin开始),往后找100字节(如果没有,到end就可以)
std::string GetDesc(const std::string &html_content, const std::string &word)
{
//找到word在html_content中首次出现的位置,然后往前找50字节(如果没有,从begin开始),往后找100字节(如果没有,到end就可以)
//截取出这部分内容
// 1.找到首次出现
const std::size_t prev_step = 50;
const std::size_t next_step = 100;
//为什么不用string.find?
//因为搜索关键词为小写,但原始文档没有改变,可能是大写,此时就存在找不到的情况
auto iter = std::search(html_content.begin(), html_content.end(), word.begin(), word.end(), [](int x, int y)
{ return (std::tolower(x) == std::tolower(y)); });
if (iter == html_content.end())
{
return "None"; //这种情况是不能存在的,因为倒排拉链是对应word,这里只是为了保险起见
}
// distance计算两个迭代器之间的距离
std::size_t pos = std::distance(html_content.begin(), iter);
// 2.获取begin,end
std::size_t start = 0;
std::size_t end = html_content.size() - 1;
if (start + prev_step < pos)
{
start = pos - prev_step;
}
if (pos + next_step < end)
{
end = pos + next_step;
}
// 3.截取子串,然后return
if (start >= end)
{
return "None";
}
std::string desc = html_content.substr(start, end - start);
desc += "...";
return desc;
}
8、编写http_server 模块
const std::string root_path = "./wwwroot";
const std::string input = "data/raw_html/raw.txt";
int main()
{
ns_searcher::Searcher search;
search.InitSearcher(input);
httplib::Server svr;
svr.set_base_dir(root_path.c_str());
svr.Get("/s", [&search](const httplib::Request &req, httplib::Response &rsp)
{
if(!req.has_param("word"))
{
rsp.set_content("必须要有关键字","text/plain:charset=utf-8");
return;
}
std::string word = req.get_param_value("word");
LOG(NORMAL,"用户搜索:" + word);
std::string json_string;
search.Search(word, &json_string);
rsp.set_content(json_string, "application/json"); });
LOG(NORMAL,"服务器启动成功...");
svr.listen("0.0.0.0", 8080);
return 0;
}
9、添加简易日志
系统日志策略可以在故障刚刚发生时就向你发送警告信息,系统日志帮助你在最短的时间内发现问题。为此,我们实现一个简单的日志系统来记录搜索引擎的运行情况。
9.1 编写log.hpp
采用C语言中内置的宏,包装出一个宏函数,用于日志调用,主要信息包含日志等级、日期、日志内容和具体运行位置
//日志等级
#define NORMAL 1
#define WARNING 2
#define DEBUG 3
#define FATAL 4
#define LOG(LEVEL, MESSAGE) log(#LEVEL/*将宏参数转为字符串*/, MESSAGE/*日志内容*/, __FILE__/*文件名*/, __LINE__/*行号*/)
void log(std::string level, std::string message, std::string file, int line)
{
time_t nowtime;
struct tm *t;
time(&nowtime);
t = localtime(&nowtime);
std::cout << "[" << level << "]"
<< "[" << t->tm_year + 1900 << "-" << t->tm_mon + 1 << "-" << t->tm_mday + 1
<< " " << t->tm_hour << ":" << t->tm_min << ":" << t->tm_sec << "]"
<< "[" << message << "]"
<< "[" << file << " : "
<< line << "]" << std::endl;
}
9.2 部署服务到 linux 上
nohup命令 ,英文全称no hang up (不挂起),用于在系统后台不挂断地运行命令,退出终端不会影响程序的运行。nohup命令,在默认情况下(非重定向时),会输出-一个名叫nohup.out的文件到当前目录下,如果当前目录的nohup out文件不可写,输出重定向到$HOME/nohup.out文件中。
使用命令:nohup ./http_server > log/log.txt 2>&1 &将服务部署到linux上2>&1 解释:将标准错误2重定向到标准输出1,标准输出1再重定向输入到 log/log.txt 文件中最后一个&解释:表示后台运行文章来源:https://www.toymoban.com/news/detail-409238.html
部署成功后,如果需要关闭服务,则使用kill -9 命令,根据进程pid结束进程即可。文章来源地址https://www.toymoban.com/news/detail-409238.html
10、整体逻辑框架
- 第一步:对html文件进行数据清洗。
- 第二步:构建正排索引和倒排索引。
- 第三步:对搜索的语句进行分词处理,形成多个关键词。
- 第四步:获取每个关键词所对应的倒排拉链。
- 第五步:对所有倒排拉链中的html文件进行去重。
- 第六步:根据权重对html文件进行排序。
- 第七步:根据文档ID+正排索引,获取文档内容,形成关键词的摘要,构建json串,返回给前端页面
到了这里,关于基于Boost的搜索引擎的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!



![[C++项目] Boost文档 站内搜索引擎(5): cpphttplib实现网络服务、html页面实现、服务器部署...](https://imgs.yssmx.com/Uploads/2024/02/642172-1.png)
![[C++项目] Boost文档 站内搜索引擎(3): 建立文档及其关键字的正排 倒排索引、jieba库的安装与使用...](https://imgs.yssmx.com/Uploads/2024/02/732017-1.png)
![[C++项目] Boost文档 站内搜索引擎(2): 文档文本解析模块parser的实现、如何对文档文件去标签、如何获取文档标题...](https://imgs.yssmx.com/Uploads/2024/02/630882-1.gif)





