目录
1. Sentiment Analysis
2. Lexical Database
2.1 What is Lexical Database
2.2 Definitions
2.3 Meaning Through Dictionary
2.4 WordNet
2.5 Synsets
2.6 Hypernymy Chain
3. Word Similarity
3.1 Word Similarity with Paths
3.2 超越路径长度
3.3 Abstract Nodes
3.4 Concept Probability Of A Node
3.5 Similarity with Information Content
4. Word Sense Disambiguation
4.1 Word Sense Disambiguation
4.2 Supervised WSD 有监督词义消歧
4.3 Unsupervised: Lesk 无监督:Lesk
4.4 Final Words
1. Sentiment Analysis
Bag of words, kNN classifier. Training data 词袋模型,kNN分类器。训练数据:
- “This is a good movie.” → ☺
- “This is a great movie.” → ☺
- “This is a terrible film.” → ☹
- “This is a wonderful film.” → ?
Two problems:
- The model does not know that "movie" and "film' are synonyms. Since "film" appears only in negative examples the model learns that it is a negative word. 模型不知道“电影”和“影片”是同义词。因为“影片”只出现在负面例子中,所以模型认为它是一个负面词。
- "wonderful" is not in the vocabulary (OOV ---- Out-Of-Vocabulary). “wonderful”不在词汇表里
Comparing words directly will not work. How to make sure we compare word meanings instead?
Solution: add this information explicitly through a lexical database. 通过 lexical database 显式添加此信息。
2. Lexical Database
2.1 What is Lexical Database
Their dictionary definition
- But dlictionary definitions are necessarily circular
- Only useful if meaning is already understood

Their relationships with other words
- Also circular, but better for text analysis
2.2 Definitions
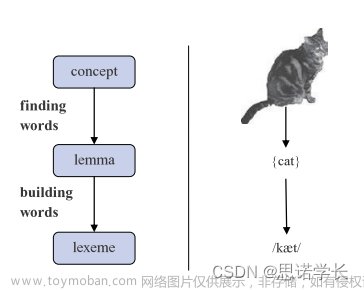
A word sense describes one aspect of the meaning of a word 词义描述了一个词的意义的一个方面
If a word has multiple senses, it is polysemous 如果一个词有多个义项,它就是多义词

2.3 Meaning Through Dictionary
Gloss: textual definition of a sense, given by a dictionary
Bank
- financial institution that accepts deposits and channels the money into lending activities
- sloping land (especially the slope beside a body of water)
Another way to define meaning: by looking at how it relates to other words
Synonymy: near identical meaning
- vomit vs. throw up
- big vs. large
Antonymy: opposite meaning
- long vs. short
- big vs. little
Hypernymy: is-a relation
- cat is an animal
- mango is a fruit
Meronymy: part-whole relation
- leg is part of a chair
- wheel is part of a car

2.4 WordNet
- A database of lexical relations 词汇关系数据库
- English WordNet includes ~120,000 nouns, ~12,000 verbs, ~21,000 adjectives, ~4,000 adverbs 包括大约120,000个名词,12,000个动词,21,000个形容词,4,000个副词
- On average: noun has 1.23 senses; verbs 2.16 平均名词有1.23个义项;动词有2.16个义项
- WordNets available in most major languages
- English version freely available (accessible via NLTK)

2.5 Synsets
Nodes of wordNet are not words or lemmas, but senses
There are represented by sets of synonyms, or synsets
Bass synsets:

Another synset:


2.6 Hypernymy Chain

3. Word Similarity
- Synonymy: film vs. movie
- What about show vs. film? opera vs. film?
- Unlike synonymy (which is a binary relation), word similarity is a spectrum
- We can use lexical database (e.g. WordNet) or thesaurus to estimate word similarity
3.1 Word Similarity with Paths
- 利用WordNet,找到基于路径长度的相似度
- 两个词汇间的相似度计算方法:
- simpath(c1, c2) = 1 / pathlen(c1, c2)
- wordsim(w1,w2) = max{c1∈senses(w1),c2∈senses(w2)} simpath(c1, c2)

- simpath(nickel,coin) = 0.5
- simpath(nickel,currency) = 0.25
- simpath(nickel,money) = 0.17
- simpath(nickel,Richter scale) = 0.13
3.2 超越路径长度
- 问题:边缘在实际语义距离上的变化很大
- 接近等级制度顶端的跳跃要大得多
- 解决方案1:包含深度信息(Wu & Palmer)
- 使用 path 查找最小公共子包(LCS)
- Something 比较使用深度
simwup(c1, c2) = 2 × depth(LCS(c1, c2)) / (depth(c1) + depth(c2))
3.3 Abstract Nodes
- But node depth is still poor semantic distance metric
- simwup (nickel, money) = 0.44
- simwup (nickel, Richter scale) = 0.22
- Nodes high in the hierarchy is very abstract or general
- How to better capture them?
3.4 Concept Probability Of A Node
Intuition :
Intuition: general node → high concept probability (e.g. object)
narrow node → low concept probability (e.g. vocalist)

Example

3.5 Similarity with Information Content

4. Word Sense Disambiguation
4.1 Word Sense Disambiguation
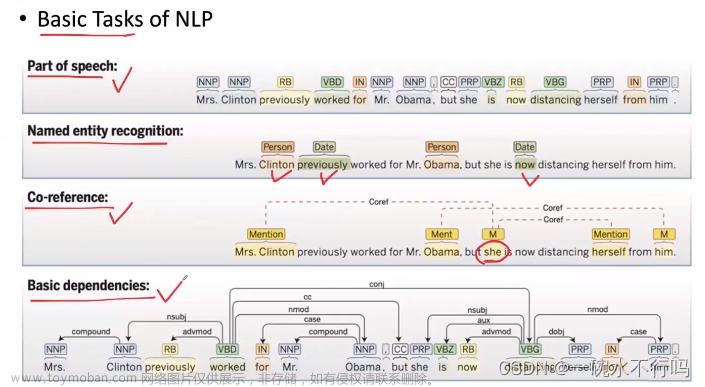
Task: selects the correct sense for words in a sentence 为句子中的词选择正确的词义
Baseline: Assume the most popular sense 假设最常见的词义
Good WSD potentially useful for many tasks 良好的词义消歧对许多任务可能有用
- Knowing which sense of mouse is used in a sentence is important! 知道句子中mouse的哪个词义很重要!
- Less popular nowadays; because sense information is implicitly captured by contextual representations (lecture 11) 如今不太受欢迎;因为词义信息被上下文表示隐含地捕获
4.2 Supervised WSD 有监督词义消歧
Apply standard machine classifiers 应用标准的机器分类器
Feature vectors typically words and syntax around target 特征向量通常是目标词周围的单词和语法
- But context is ambiguous too! 但上下文也是模糊的!
- How big should context window be? (in practice small) 上下文窗口应该有多大?(实际上较小)
Requires sense-tagged corpora 需要有词义标注的语料库
- E.g. SENSEVAL, SEMCOR (available in NLTK) 例如 SENSEVAL,SEMCOR(可在NLTK中找到)
- Very time consuming to create! 创建非常耗时!
4.3 Unsupervised: Lesk 无监督:Lesk
Lesk:选择WordNet释义与上下文重叠最多的词义
 文章来源:https://www.toymoban.com/news/detail-409272.html
文章来源:https://www.toymoban.com/news/detail-409272.html
4.4 Final Words
- Creation of lexical database involves expert curation (linguists) 词汇数据库的创建涉及专家策展(语言学家)
- Modern methods attempt to derive semantic information directly from corpora, without human intervention 现代方法试图直接从语料库中获取语义信息,无需人工干预
- Distributional semantics 分布式语义
文章来源地址https://www.toymoban.com/news/detail-409272.html
到了这里,关于自然语言处理(八):Lexical Semantics的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!