引言
本节及后续小节将从指数族分布 → \to → 熵、最大熵原理 → sigmoid,softmax \to \text{sigmoid,softmax} →sigmoid,softmax函数的思路进行介绍。
指数族分布介绍
指数族分布(
Exponential Families of Distributions
\text{Exponential Families of Distributions}
Exponential Families of Distributions),它不是某一个分布,而是满足某种条件的分布集合。从名字可以看出,指数族分布描述的概率分布与指数相关。指数族分布的统一格式表示如下:
P
(
x
∣
η
)
=
h
(
x
)
exp
{
η
T
ϕ
(
x
)
−
A
(
η
)
}
\mathcal P(x \mid \eta) = h(x) \exp \left\{\eta^{T} \phi(x) - A(\eta) \right\}
P(x∣η)=h(x)exp{ηTϕ(x)−A(η)}
如果只看公式等号左边 → P ( x ∣ η ) \to P(x \mid \eta) →P(x∣η),在介绍极大似然估计与最大后验概率估计中介绍过,它可以表示为 基于参数向量 η \eta η,生成随机样本 x x x的概率模型。
我们称:
-
ϕ
(
x
)
\phi(x)
ϕ(x)为充分统计量,它可以理解成样本的函数—— 如果已知充分统计量,就可以通过该统计量得到完整的概率分布表达形式。
在后续的公式推导中进行证明。 - η \eta η表示生成概率模型 P ( x ∣ η ) P(x \mid \eta) P(x∣η)的参数向量;
- h ( x ) h(x) h(x)仅表示关于 x x x的一个函数,在一些具体分布中(如高斯分布、伯努利分布)通常以常数形式出现;
-
A
(
η
)
A(\eta)
A(η)通常表示为
log
\log
log配分函数(对数配分函数)(
log Partition Function
\text{log Partition Function}
log Partition Function),在指数族分布主要起归一化作用,其本质是关于模型参数
η
\eta
η的函数;
因此,指数族分布还有另一种常见表达形式(将 A ( η ) A(\eta) A(η)提出来):
P ( x ∣ η ) = h ( x ) exp { η T ⋅ ϕ ( x ) } ⋅ exp { − A ( η ) } = 1 exp { A ( η ) } ⋅ h ( x ) exp { η T ⋅ ϕ ( x ) } \begin{aligned} \mathcal P(x \mid \eta) & = h(x) \exp \left\{\eta^{T} \cdot \phi(x) \right\} \cdot \exp \{-A(\eta)\} \\ & = \frac{1}{\exp \{A(\eta)\}} \cdot h(x) \exp \left\{\eta^{T} \cdot \phi(x) \right\} \end{aligned} P(x∣η)=h(x)exp{ηT⋅ϕ(x)}⋅exp{−A(η)}=exp{A(η)}1⋅h(x)exp{ηT⋅ϕ(x)}
令 exp { A ( η ) } = Z \exp \{A(\eta) \} = \mathcal Z exp{A(η)}=Z( Z \mathcal Z Z表示 配分函数);原始表示为:
1 Z h ( x ) ⋅ exp { η T ⋅ ϕ ( x ) } \frac{1}{\mathcal Z} h(x) \cdot \exp \{\eta^{T} \cdot \phi(x) \} Z1h(x)⋅exp{ηT⋅ϕ(x)}
因此, A ( η ) = log Z A(\eta) = \log \mathcal Z A(η)=logZ。 这也是 A ( η ) A(\eta) A(η)对数配分函数的由来。配分函数相关:传送门
指数族分布应用广泛,如广义线性模型(
Generalized Linear Model,GLM
\text{Generalized Linear Model,GLM}
Generalized Linear Model,GLM),概率图中的无向图模型如受限玻尔兹曼机(
Restricted Boltzmann Machine,RBM
\text{Restricted Boltzmann Machine,RBM}
Restricted Boltzmann Machine,RBM)均存在指数族分布的理论支撑;
甚至在深度强化学习中,使用策略梯度方法求解强化学习任务时,需要使用
Softmax
\text{Softmax}
Softmax函数将离散型的动作映射成具有连续性质的指数族分布。
常见指数族分布
我们在概率论与数理统计中学习到的大部分分布都是指数族分布,下面列举一些常见分布:
- 高斯分布( Normal Distribution \text{Normal Distribution} Normal Distribution);
- 伯努利分布( Bernoulli Distribution \text{Bernoulli Distribution} Bernoulli Distribution);
- 二项分布( Binomial Distribution \text{Binomial Distribution} Binomial Distribution);
- 泊松分布( Poisson Distribution \text{Poisson Distribution} Poisson Distribution);
- 贝塔分布( Beta Distribution \text{Beta Distribution} Beta Distribution);
- 狄利克雷分布( Dirichlet Distribution \text{Dirichlet Distribution} Dirichlet Distribution);
- 伽马分布( Gamma Distribution \text{Gamma Distribution} Gamma Distribution)等等。
下面对伯努利分布、高斯分布、二项分布进行推导,观察经过变化后的分布和指数族分布统一格式之间的关联关系。
推导过程
-
伯努利分布:
P ( x ) = p x ⋅ ( 1 − p ) 1 − x = { p if x = 1 q if x = 0 \mathcal P(x) = p^x \cdot (1 - p)^{1-x} = \begin{cases} p \quad \text{if} \quad x = 1 \\ q \quad \text{if} \quad x = 0 \end{cases} P(x)=px⋅(1−p)1−x={pifx=1qifx=0将上述公式进行变化:
- 插入
exp
\exp
exp并完全展开:
P ( x ) = p x ⋅ ( 1 − p ) 1 − x = exp { log [ p x ( 1 − p ) 1 − x ] } = exp { x ⋅ log [ p 1 − p ] + log ( 1 − p ) } \begin{aligned} \mathcal P(x) & = p^x \cdot (1 - p)^{1-x} \\ & = \exp \{\log \left[p^x(1 - p)^{1-x} \right] \} \\ & = \exp \left\{x \cdot \log \left[\frac{p}{1- p}\right] + \log (1- p) \right\} \end{aligned} P(x)=px⋅(1−p)1−x=exp{log[px(1−p)1−x]}=exp{x⋅log[1−pp]+log(1−p)} - 令
η
=
log
p
1
−
p
\begin{aligned} \eta = \log\frac{p}{1 - p} \end{aligned}
η=log1−pp,那么
p
p
p用
η
\eta
η表示为:
p = exp { η } 1 + exp { η } p = \frac{\exp \{\eta\}}{1 + \exp \{\eta \}} p=1+exp{η}exp{η} - 将
p
=
e
η
1
+
e
η
\begin{aligned} p = \frac{e^{\eta}}{1 + e^{\eta}} \end{aligned}
p=1+eηeη带回上述展开式:
I = exp { x ⋅ η + log ( 1 − e η e η + 1 ) } = exp { x ⋅ η + log ( 1 1 + e η ) } = exp { η T x − log ( 1 + e η ) } \begin{aligned} \mathcal I & = \exp \left\{x \cdot \eta + \log \left(1 - \frac{e^\eta}{e^\eta + 1} \right) \right\} \\ & = \exp \left\{x \cdot \eta +\log \left(\frac{1}{1 + e^\eta}\right) \right\} \\ & = \exp \left\{\eta^Tx - \log(1 + e^\eta) \right\} \end{aligned} I=exp{x⋅η+log(1−eη+1eη)}=exp{x⋅η+log(1+eη1)}=exp{ηTx−log(1+eη)}
观察变化后的公式,对照指数族分布的定义式,可以发现:
- ϕ ( x ) = x \phi(x) = x ϕ(x)=x
- h ( x ) = 1 h(x) = 1 h(x)=1
- A ( η ) = log ( 1 + e η ) A(\eta) = \log(1 + e^\eta) A(η)=log(1+eη)
伯努利分布完全可以写成指数族分布的形式。
- 插入
exp
\exp
exp并完全展开:
-
二项分布:
二项分布可以看成 n n n次独立重复的伯努利实验。它的概率分布表示如下:
P ( x = k ) = C n k p k ( 1 − p ) n − k \mathcal P(x = k) = \mathcal C_{n}^{k}p^k(1-p)^{n-k} P(x=k)=Cnkpk(1−p)n−k
其中, C n k \mathcal C_{n}^{k} Cnk表示二项式系数:
C n k = n ! k ! ( n − k ) ! C_{n}^{k} = \frac{n!}{k!(n-k)!} Cnk=k!(n−k)!n!
它的指数族分布表示和伯努利分布非常相似:- 插入
exp
\exp
exp并完全展开:
P ( x ) = n ! x ! ( n − x ) ! ⋅ p x ( 1 − p ) n − x = exp { log [ n ! x ! ( n − x ) ! ⋅ p x ( 1 − p ) n − x ] } = exp { log n ! x ! ( n − x ) ! + x log p + n log ( 1 − p ) − x log ( 1 − p ) } = exp { log n ! x ! ( n − x ) ! + x log p 1 − p + n log ( 1 − p ) } \begin{aligned} \mathcal P(x) & = \frac{n!}{x!(n-x)!} \cdot p^x(1-p)^{n-x} \\ & = \exp \left\{\log \left[\frac{n!}{x!(n-x)!} \cdot p^x(1-p)^{n-x} \right] \right\} \\ & = \exp \left\{\log\frac{n!}{x!(n-x)!} + x\log p + n\log(1-p) -x\log(1-p) \right\} \\ & = \exp \left\{\log\frac{n!}{x!(n-x)!} + x\log\frac{p}{1-p} +n \log(1 - p) \right\}\\ \end{aligned} P(x)=x!(n−x)!n!⋅px(1−p)n−x=exp{log[x!(n−x)!n!⋅px(1−p)n−x]}=exp{logx!(n−x)!n!+xlogp+nlog(1−p)−xlog(1−p)}=exp{logx!(n−x)!n!+xlog1−pp+nlog(1−p)} - 由于
n
!
x
!
(
n
−
x
)
!
\begin{aligned}\frac{n!}{x!(n-x)!} \end{aligned}
x!(n−x)!n!中
n
n
n是表示实验次数,是常数,因此
n
!
x
!
(
n
−
x
)
!
\begin{aligned}\frac{n!}{x!(n-x)!} \end{aligned}
x!(n−x)!n!可看做仅关于
x
x
x的函数,将其提出;并令
η
=
log
p
1
−
p
\begin{aligned}\eta = \log\frac{p}{1 - p}\end{aligned}
η=log1−pp,那么
P
(
x
)
\mathcal P(x)
P(x)用
η
\eta
η表示为:
p = e η 1 + e η p = \frac{e^{\eta}}{1 + e^{\eta}} p=1+eηeη - 继续化简如下(将
p
p
p带回原式):
I = n ! x ! ( n − x ) ! exp { x log p 1 − p + n log ( 1 − p ) } = n ! x ! ( n − x ) ! exp { η T x − n log ( 1 + e η ) } \begin{aligned} \mathcal I & = \frac{n!}{x!(n-x)!} \exp \left\{x \log\frac{p}{1-p} + n \log(1 - p) \right\} \\ & = \frac{n!}{x!(n-x)!} \exp \left\{\eta^{T}x - n\log(1 + e^\eta)\right\} \\ \end{aligned} I=x!(n−x)!n!exp{xlog1−pp+nlog(1−p)}=x!(n−x)!n!exp{ηTx−nlog(1+eη)}
对照指数族分布定义式,获取参数如下:
- ϕ ( x ) = x \phi(x) = x ϕ(x)=x
- h ( x ) = n ! x ! ( n − x ) ! \begin{aligned}h(x) = \frac{n!}{x!(n-x)!}\end{aligned} h(x)=x!(n−x)!n!
- A ( η ) = n log ( 1 + e η ) A(\eta) = n\log(1 + e^\eta) A(η)=nlog(1+eη)
- 插入
exp
\exp
exp并完全展开:
-
一维高斯分布:
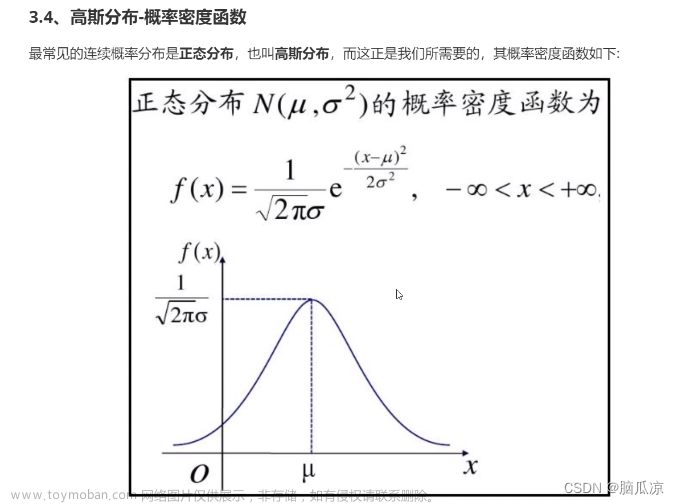
P ( x ∣ θ ) = 1 σ 2 π ⋅ exp { − ( x − μ ) 2 2 σ 2 } \mathcal P(x \mid \theta) = \frac{1}{\sigma\sqrt{2\pi}} \cdot \exp \left\{-\frac{(x - \mu)^2}{2\sigma^2}\right\} P(x∣θ)=σ2π1⋅exp{−2σ2(x−μ)2}
同理,将上述公式完全展开,系数部分插入 exp \exp exp:
I = exp { log ( 2 π σ 2 ) − 1 2 } ⋅ exp { − 1 2 σ 2 ( x 2 − 2 μ x + μ 2 ) } = exp { − 1 2 log ( 2 π σ 2 ) } ⋅ exp { − 1 2 σ 2 ( x 2 − 2 μ x ) − μ 2 2 σ 2 } \begin{aligned} \mathcal I & = \exp \left\{\log \left(2\pi\sigma^2 \right)^{-\frac{1}{2}} \right\} \cdot \exp \left\{-\frac{1}{2\sigma^2} \left(x^2 -2\mu x + \mu^2 \right) \right\} \\ & = \exp \left\{-\frac{1}{2}\log(2\pi\sigma^2) \right\} \cdot \exp \left\{-\frac{1}{2\sigma^2}(x^2 -2\mu x)-\frac{\mu^2}{2\sigma^2} \right\} \end{aligned} I=exp{log(2πσ2)−21}⋅exp{−2σ21(x2−2μx+μ2)}=exp{−21log(2πσ2)}⋅exp{−2σ21(x2−2μx)−2σ2μ2}
此时,两项都有相同的底 exp \exp exp,将两项合并;技巧操作:将 x 2 − 2 μ x x^2 - 2\mu x x2−2μx视为两向量的乘法操作。即:
x 2 − 2 μ x = ( − 2 μ , 1 ) ( x x 2 ) x^2 - 2\mu x = \begin{pmatrix}-2\mu,1\end{pmatrix}\begin{pmatrix}x\\x^2\end{pmatrix} x2−2μx=(−2μ,1)(xx2)
化简得到如下结果:将− 1 2 σ 2 \begin{aligned}-\frac{1}{2\sigma^2}\end{aligned} −2σ21作为系数带到矩阵中:
− 1 2 σ 2 ( − 2 μ , 1 ) = ( μ σ 2 , − 1 2 σ 2 ) -\frac{1}{2\sigma^2} \begin{pmatrix}-2\mu,1\end{pmatrix} = \left(\frac{\mu}{\sigma^2},-\frac{1}{2\sigma^2} \right)\\ −2σ21(−2μ,1)=(σ2μ,−2σ21)
最终化简结果为:
exp { ( μ σ 2 , − 1 2 σ 2 ) ( x x 2 ) − [ μ 2 2 σ 2 + 1 2 log ( 2 π σ 2 ) ] } \exp \left\{ \left(\frac{\mu}{\sigma^2},-\frac{1}{2\sigma^2} \right) \begin{pmatrix}x\\x^2\end{pmatrix} - \left[\frac{\mu^2}{2\sigma^2} + \frac{1}{2}\log(2\pi\sigma^2) \right] \right\} exp{(σ2μ,−2σ21)(xx2)−[2σ2μ2+21log(2πσ2)]}对照指数族分布定义式:
- ϕ = ( x x 2 ) \phi = \begin{pmatrix}x\\x^2\end{pmatrix} ϕ=(xx2);
- h ( x ) = 1 h(x) = 1 h(x)=1;
- η T = ( μ σ 2 , − 1 2 σ 2 ) \begin{aligned} \eta^{T} = \left(\frac{\mu}{\sigma^2},-\frac{1}{2\sigma^2} \right) \end{aligned} ηT=(σ2μ,−2σ21);
- A ( η ) = μ 2 2 σ 2 + 1 2 log ( 2 π σ 2 ) \begin{aligned} A(\eta) = \frac{\mu^2}{2\sigma^2} + \frac{1}{2}\log(2\pi\sigma^2) \end{aligned} A(η)=2σ2μ2+21log(2πσ2)
实际上,我们可以对 η \eta η继续化简:
- 令 η = ( η 1 η 2 ) = ( μ σ 2 − 1 2 σ 2 ) \eta = \begin{pmatrix}\eta_1\\\eta_2\end{pmatrix} = \begin{pmatrix} \begin{aligned}\frac{\mu}{\sigma^2}\end{aligned} \\ \begin{aligned}-\frac{1}{2\sigma^2}\end{aligned} \end{pmatrix} η=(η1η2)= σ2μ−2σ21 :
- 求得
μ
,
σ
\mu,\sigma
μ,σ表示如下:
μ = − η 1 2 ⋅ η 2 ; σ 2 = − 1 2 ⋅ η 2 \mu = -\frac{\eta_1}{2 \cdot \eta_2};\sigma^2 = -\frac{1}{2 \cdot \eta_2} μ=−2⋅η2η1;σ2=−2⋅η21 -
A
(
η
)
A(\eta)
A(η)表示为如下形式:
A ( η ) = − η 1 2 4 η 2 + 1 2 log ( π η 2 ) A(\eta) = -\frac{\eta_1^2}{4\eta_2} + \frac{1}{2} \log \left(\frac{\pi}{\eta_2} \right) A(η)=−4η2η12+21log(η2π)
回头观察充分统计量:
ϕ
=
(
x
x
2
)
\phi = \begin{pmatrix}x\\x^2\end{pmatrix}
ϕ=(xx2)
如果某组数据
X
=
{
x
(
1
)
,
x
(
2
)
,
⋯
,
x
(
N
)
}
\mathcal X = \{x^{(1)},x^{(2)},\cdots,x^{(N)}\}
X={x(1),x(2),⋯,x(N)}服从高斯分布,并且知晓该数据的两种信息:
(
∑
i
=
1
N
x
(
i
)
∑
i
=
1
N
[
x
(
i
)
]
2
)
\begin{pmatrix} \begin{aligned}\sum_{i=1}^N x^{(i)} \end{aligned} \\ \\ \begin{aligned} \sum_{i=1}^N [x^{(i)}]^2 \end{aligned} \end{pmatrix}
i=1∑Nx(i)i=1∑N[x(i)]2
那么该信息就可以构建一个完整的高斯分布模型
P
(
x
∣
η
)
P(x \mid \eta)
P(x∣η), 并可以从该模型中源源不断地生成和
X
\mathcal X
X相同分布的样本:
{
μ
=
1
N
∑
i
=
1
N
x
i
σ
2
=
∑
i
=
1
N
x
i
2
−
μ
2
\begin{cases} \begin{aligned} \mu & = \frac{1}{N}\sum_{i=1}^N x_i \\ \sigma^2 & = \sum_{i=1}^N x_i^2 - \mu^2 \end{aligned} \end{cases}
⎩
⎨
⎧μσ2=N1i=1∑Nxi=i=1∑Nxi2−μ2
有了均值
μ
\mu
μ,方差
σ
\sigma
σ,自然可以求解高斯分布:
P
(
x
∣
θ
)
=
1
2
π
σ
exp
{
−
(
x
−
μ
)
2
2
σ
2
}
\mathcal P(x \mid \theta) = \frac{1}{\sqrt{2\pi}\sigma} \exp \left\{-\frac{(x - \mu)^2}{2\sigma^2} \right\}
P(x∣θ)=2πσ1exp{−2σ2(x−μ)2}
因此,指数族分布概率模型中的所有信息都存储在充分统计量中。换句话说,如果某一概率模型是指数族分布,那么该模型的统计量本身就是充分统计量。
指数族分布的共轭性质
在极大似然估计与最大后验概率估计介绍了贝叶斯估计及其弊端:
P
(
θ
∣
x
)
=
P
(
x
∣
θ
)
⋅
P
(
θ
)
∫
θ
P
(
x
∣
θ
)
⋅
P
(
θ
)
d
θ
\mathcal P(\theta \mid x) = \frac{\mathcal P(x \mid \theta) \cdot \mathcal P(\theta)}{\int_{\theta} \mathcal P(x \mid \theta) \cdot \mathcal P(\theta)d\theta}
P(θ∣x)=∫θP(x∣θ)⋅P(θ)dθP(x∣θ)⋅P(θ)
其本质是积分难问题,如果 θ \theta θ是多维向量,每一维度都要计算积分,是相当耗费计算资源的事情。
共轭本身意思是指:给定特殊的似然
P
(
x
∣
θ
)
\mathcal P(x \mid \theta)
P(x∣θ)条件下,后验分布
P
(
θ
∣
x
)
\mathcal P(\theta \mid x)
P(θ∣x)与先验分布
P
(
θ
)
\mathcal P(\theta)
P(θ)会形成相同分布形式。
如果概率模型
P
(
x
∣
θ
)
\mathcal P(x \mid \theta)
P(x∣θ)是指数族分布,就可以满足共轭条件,在使用贝叶斯估计求解问题时,可以直接跳过求解分母积分的过程,这种性质为推断、模型选择提供很大便利。
具体表述逻辑如下:
- 如果概率模型(似然函数)
P
(
x
∣
θ
)
\mathcal P(x \mid \theta)
P(x∣θ)分布 存在一个共轭的先验分布
P
(
θ
)
\mathcal P(\theta)
P(θ),那么效果是:后验分布
P
(
θ
∣
x
)
\mathcal P(\theta \mid x)
P(θ∣x)与先验分布
P
(
θ
)
\mathcal P(\theta)
P(θ)会形成相同分布形式。
注意:先验分布和后验分布的分布形式相同,但并不是相等。
下一节将介绍指数族分布与最大熵的关系。文章来源:https://www.toymoban.com/news/detail-409286.html
相关参考:
二项分布
指数族分布
机器学习-白板推导系列(八)-指数族分布(Exponential Family Distribution)文章来源地址https://www.toymoban.com/news/detail-409286.html
到了这里,关于机器学习笔记之指数族分布——指数族分布介绍的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!



![[学习笔记] [机器学习] 10. 支持向量机 SVM(SVM 算法原理、SVM API介绍、SVM 损失函数、SVM 回归、手写数字识别)](https://imgs.yssmx.com/Uploads/2024/02/487779-1.png)




