缘起
疫情,不少孩子封控在家,需要上网课,但是老是抑制不住地去打游戏或看视频。
朋友圈里面,某位技术大牛这么描述疫情封控期间,他与孩子的居家“战争”:
孩子上网课已经一个多月了,孩子因为爱玩游戏爱看B站,与我斗智斗勇好几回,目前战斗情况如下:
上课时间玩手机游戏 ~ 没收手机
在电脑上装手机模拟器 继续玩手机游戏 ~ 卸载模拟器
在电脑上看B站 ~ 设置host文件屏蔽B站域名
在电脑上看芒果TV ~ 继续设置屏蔽域名
继续安装手机模拟器、找到host文件删除屏蔽,看B站玩游戏 ~ 被打,被卸载各种软件,被警告再发现就换Linux操作系统
解封后,先买个企业级路由器管控起来… 或者再装个摄像头再加上AI人体姿态识别?😭
因本文是技术文章,在这里咱暂先不讨论教育之道,先提供一个技术方案,解决家长的燃眉之急,不用企业级路由器,也不用AI人体姿态识别。
我的方案是:packetbeat+kafka+ES套件,以大数据可视化方式监控孩子。
这个方案的特点:
- 一是抓住了矛盾的主要方面,疫情封控期间,孩子因网课有正当理由使用电脑等设备,监控重点是上网行为,尤其在上课时间段内不能打游戏看视频
- 二是最大程度利用了现有设备,不需要额外添置监控设备
架构设计

架构设计上有个难点,我的方案中考虑了异地监控的情况,比如孩子在杭州上课,我在新加坡工作,考虑跨国网络的不稳定性,我在常规的packetbeat和ES集群之间,加了一个准备放在阿里云上的kafka消息队列,这样就不用穿透内网,也不怕网络不稳丢消息了,远在新加坡Shopee云的监控主机可以用异步方式读取kafka。
效果展示
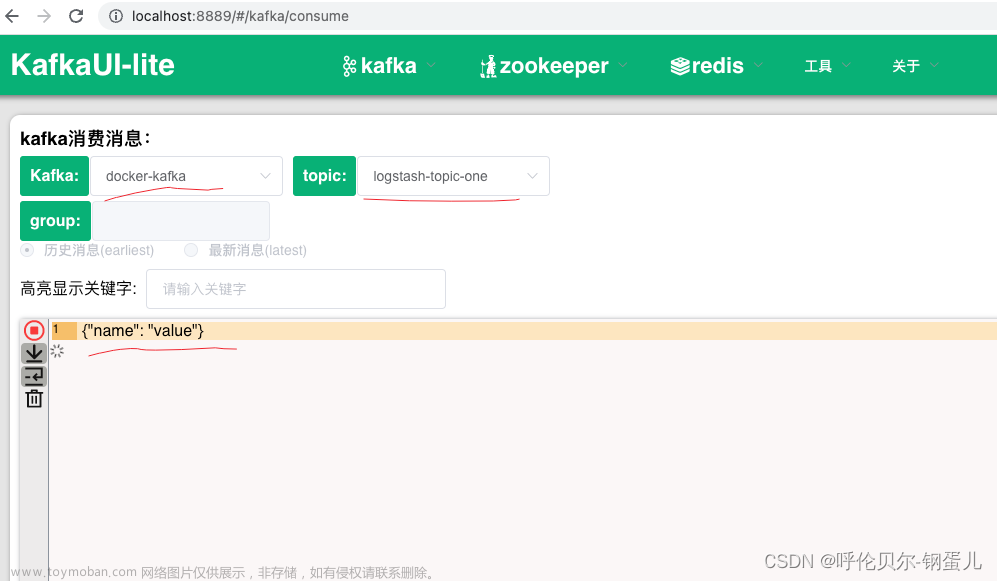
监控实图1:
监控实图2:
孩子访问了啥网站,啥时候访问,网络地址、流量情况一应俱全:) 虽然和教育的目的相背,但是国内就好这一口不是😄 IT前辈大牛目前还在用物理手段,我已经升级到 云+大数据了,我要把这个项目开源,造福中国的父母,嘿嘿
安装运行
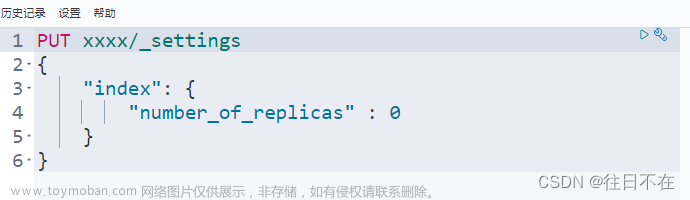
注意版本问题!如下未特别说明的,都采用7.8.1版本,版本不匹配会有坑。
packetbeat
总体过程是:官网下载,unzip解压到本地目录,配置yml文件,后启动运行
10360* sudo ./packetbeat -e -c packetbeat.yml
10362 cd packetbeat-7.8.1-darwin-x86_64
10363* sudo ./packetbeat setup --dashboards
10364* sudo ./packetbeat -e -c packetbeat.yml
配置packetbeat.yml 输出到Kafka
# ---------------------------- Kafka -------------------------------------------
output.kafka:
hosts: ["localhost:9092"]
topic: packetbeat
required_acks: 1
Kafka
采用docker-compose方式安装
version: '3'
services:
zookeeper:
image: wurstmeister/zookeeper
container_name: zookeeper
ports:
- 2181:2181
environment:
ZOO_MY_ID: 1
kafka:
image: wurstmeister/kafka
container_name: kafka
ports:
- 9092:9092
environment:
KAFKA_ADVERTISED_HOST_NAME: 192.168.18.37
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
volumes:
- /var/run/docker.sock:/var/run/docker.sock
kafka_manager:
image: sheepkiller/kafka-manager
container_name: kafka_manager
ports:
- 9000:9000
environment:
ZK_HOSTS: "zookeeper:2181"
APPLICATION_SECRET: "random-secret"
command: -Dpidfile.path=/dev/null
消费端代码如下供参考,也可以用logstash直接拉取
package main
import (
"fmt"
"github.com/Shopify/sarama"
)
const TOPIC = "packetbeat"
func main() {
consumer, err := sarama.NewConsumer([]string{"127.0.0.1:9092"}, nil)
if err != nil {
fmt.Printf("fail to start consumer, err:%v\n", err)
return
}
partitionList, err := consumer.Partitions(TOPIC) // 根据topic取到所有的分区
if err != nil {
fmt.Printf("fail to get list of partition:err%v\n", err)
return
}
fmt.Println(partitionList)
for partition := range partitionList { // 遍历所有的分区
// 针对每个分区创建一个对应的分区消费者
pc, err := consumer.ConsumePartition(TOPIC, int32(partition), sarama.OffsetOldest)
fmt.Printf("---%+v\n", pc)
if err != nil {
fmt.Printf("failed to start consumer for partition %d,err:%v\n", partition, err)
return
}
defer pc.AsyncClose()
// 异步从每个分区消费信息
i := 0
for msg := range pc.Messages() {
fmt.Printf("Partition:%d Offset:%d Key:%v Value:%v\n", msg.Partition, msg.Offset, string(msg.Key), string(msg.Value))
i++
if i > 5 {
return
}
}
}
}
logstash
安装过程参考官网说明,配置文章来源:https://www.toymoban.com/news/detail-409534.html
input {
kafka {
bootstrap_servers => "localhost:59471"
topics => ["packetbeat"]
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "packetbeat-7.8.1-2022.05.01-000001"
document_type => "_doc"
}
stdout { codec => rubydebug }
}
ES集群+kibana
也是docker-compose安装文章来源地址https://www.toymoban.com/news/detail-409534.html
services:
elasticsearch01:
build:
context: elasticsearch/
args:
ELK_VERSION: ${ELK_VERSION:-7.8.1}
volumes:
- type: bind
source: ./elasticsearch/elasticsearch.yml
target: /usr/share/elasticsearch/config/elasticsearch.yml
read_only: true
- ./data_elasticsearch01:/usr/share/elasticsearch/data
ports:
- "9200:9200"
environment:
- node.name=elasticsearch01
- discovery.seed_hosts=elasticsearch02
- cluster.initial_master_nodes=elasticsearch01,elasticsearch02
- bootstrap.memory_lock=true
#- "ES_JAVA_OPTS=-Xms${ES_HEAP_SIZE:-2g} -Xmx${ES_HEAP_SIZE:-2g}"
ulimits:
memlock:
soft: -1
hard: -1
elasticsearch02:
build:
context: elasticsearch/
args:
ELK_VERSION: ${ELK_VERSION:-7.8.1}
volumes:
- type: bind
source: ./elasticsearch/elasticsearch.yml
target: /usr/share/elasticsearch/config/elasticsearch.yml
read_only: true
- ./data_elasticsearch02:/usr/share/elasticsearch/data
environment:
- node.name=elasticsearch02
- discovery.seed_hosts=elasticsearch01
- cluster.initial_master_nodes=elasticsearch01,elasticsearch02
- bootstrap.memory_lock=true
#- "ES_JAVA_OPTS=-Xms${ES_HEAP_SIZE:-2g} -Xmx${ES_HEAP_SIZE:-2g}"
ulimits:
memlock:
soft: -1
hard: -1
kibana:
build:
context: kibana/
args:
ELK_VERSION: ${ELK_VERSION:-7.8.1}
volumes:
- type: bind
source: ./kibana/kibana.yml
target: /usr/share/kibana/config/kibana.yml
read_only: true
ports:
- "5601:5601"
environment:
- elasticsearch.hosts=["http://elasticsearch01:9200"]
到了这里,关于救救家长:疫情封控下packetbeat+kafka+ES套件监控青少年上网行为的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!