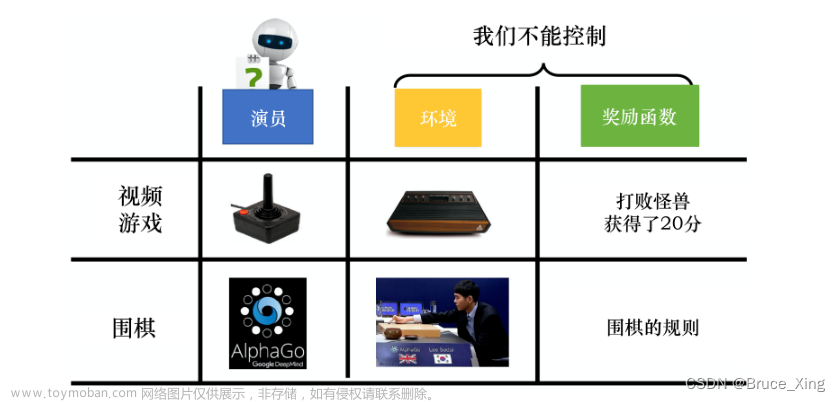
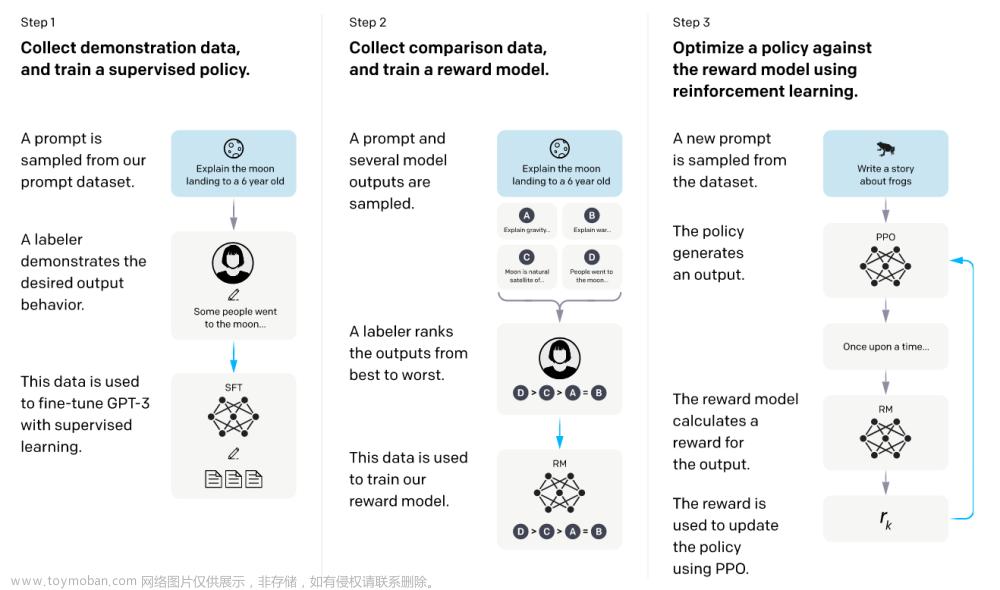
ChatGPT 使用 强化学习:Proximal Policy Optimization算法
强化学习中的PPO(Proximal Policy Optimization)算法是一种高效的策略优化方法,它对于许多任务来说具有很好的性能。PPO的核心思想是限制策略更新的幅度,以实现更稳定的训练过程。接下来,我将分步骤向您介绍PPO算法。
步骤1:了解强化学习基础
首先,您需要了解强化学习的基本概念,如状态(state)、动作(action)、奖励(reward)、策略(policy)和价值函数(value function)。这些概念将帮助您更好地理解PPO算法。
步骤2:了解策略梯度方法
在深入了解PPO之前,您需要了解策略梯度方法,这是一类通过梯度上升来直接优化策略的方法。策略梯度方法的核心思想是,通过计算策略的梯度来更新策略,使得期望累积奖励最大化。
步骤3:了解TRPO算法
PPO算法的前身是TRPO(Trust Region Policy Optimization)算法。TRPO的核心思想是在策略更新过程中使用信任域,限制策略更新的幅度。这可以确保策略更新不会导致性能急剧下降。了解TRPO算法将有助于您更好地理解PPO算法的创新之处。文章来源:https://www.toymoban.com/news/detail-409896.html
步骤4:学习PPO算法的核心思想
PPO算法的主要贡献是提出了一种简化的方法来限制策略更新的幅度。PPO使用了一个名为“PPO-Clip”的策略更新方案,将策略更新限制在一定范围内。这种方法简化了计算文章来源地址https://www.toymoban.com/news/detail-409896.html
到了这里,关于ChatGPT 使用 强化学习:Proximal Policy Optimization算法(详细图解)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!