综述参考:https://zhuanlan.zhihu.com/p/598785102
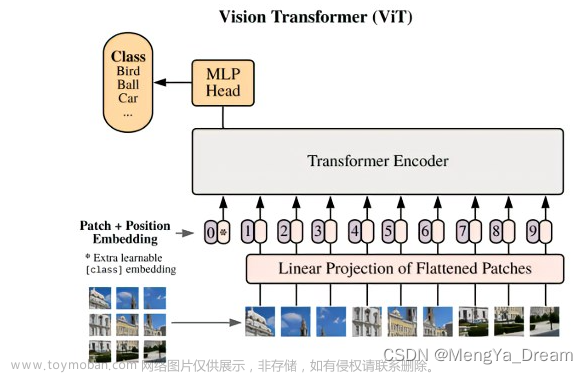
2020 VIT
代码库 https://github.com/lucidrains/vit-pytorch 只有分类任务,有训练的测试。有各种各样的vit模型结构。
原文 https://arxiv.org/abs/2010.11929
2021 Swim Transformer
https://arxiv.org/abs/2103.14030
v2 https://arxiv.org/pdf/2111.09883.pdf
code and pretrain_model https://github.com/microsoft/Swin-Transformer
2021 Video Swin Transformer
zhihu https://zhuanlan.zhihu.com/p/411797103 https://zhuanlan.zhihu.com/p/401341051
paper https://arxiv.org/abs/2106.13230
code & pretrain model https://github.com/SwinTransformer/Video-Swin-Transformer
2021 CLIP
论文 https://arxiv.org/abs/2103.00020
代码 https://github.com/openai/CLIP
Blog https://openai.com/blog/clip/
讨论 https://www.zhihu.com/question/438649654
2021 MAE
IMAGE_MAE
介绍 https://zhuanlan.zhihu.com/p/497637669
论文 https://arxiv.org/abs/2111.06377
代码 https://github.com/facebookresearch/mae/blob/main/models_mae.py
BEiT系列
https://zhuanlan.zhihu.com/p/558427525
2021 BEiT
论文 https://arxiv.org/pdf/2106.08254.pdf
代码及开源模型 https://github.com/microsoft/unilm/tree/master/beit
博客 https://www.zhihu.com/question/478187326
2022 BEiTv2
论文 https://arxiv.org/abs/2208.06366
代码 https://github.com/microsoft/unilm/tree/master/beit2
讨论 https://www.zhihu.com/question/548722860 https://zhuanlan.zhihu.com/p/567855526
参考:https://zhuanlan.zhihu.com/p/581220139
我们来讲Moco v3的代码。
论文的主要内容,参考系列首篇:自监督学习Visual Transformers(ViT)的训练经验(Moco v3) – 论文解析
官方代码链接:
https://github.com/facebookresearch/moco-v3
但现在最佳的模型是微软的EsViT(Swin-B),然后才是Moco v3,下面是来自https://paperswithcode.com/的统计:
这张图最后边的点是EsViT(Swin-B),图中文字没显示出来。
这个模型也公开了源代码:文章来源:https://www.toymoban.com/news/detail-409955.html
https://github.com/microsoft/esvit文章来源地址https://www.toymoban.com/news/detail-409955.html
到了这里,关于Vision Transformer(VIT)调研的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!