1.目标检测中的两类方法
两种进行目标检测任务的深度学习方法:
- 分类:深度学习的目标检测的方法可以分为两类,分别是一阶段方法和二阶段方法。
- 一阶段方法:YOLO系列模型都是一阶段方法,这一类方法可以一步到位地使用卷积神经网络进行特征提取并输出标注框。
- 两阶段方法:两阶段阶段方法包括Faster-RCNN和Mask-RCNN等,在进行目标检测时,这一类方法会在第一个阶段中找出一些可能的边界框作为候选,这一步相当于一个初选,在第二个阶段再从候选的边界框中找出最优的边界框作为目标检测结果。
两类目标检测方法的比较:
- 一阶段网络:单阶段网络的核心优势在于速度会非常快,因此适合做实时检测任务(如视频处理),但是缺点在于效果通常情况下不太好。
- 两阶段网络:两阶段网络的效果一般会比单阶段网络好,但是速度远低于实时任务的要求。
目标检测算法的评价指标:衡量目标检测算法的两个指标分别是MAP和FPS。MAP用于衡量算法的预测能力;FPS用于衡量算法的运行速度。
2.目标检测的评价指标
精确率和召回率:
- 精确率和召回率的定义:精确率是指正确预测为正类的样本占所有预测为正类的样本的比例;召回率是指正确预测为正类的样本占所有实际为正类的样本的比例。
- 目标检测任务中作用的概述:对于目标检测任务,精确率是指对于图像中每一个标注的物体检测效果好不好;召回率是指对图像中每一个标注的物体是否都检测到了。
- 存在的问题:在大部分问题上,精确率高时召回率就低,召回率高时精确率就低。
IOU指标:也就是交集并集比。是指两个边界框的交集面积和并集面积的比值。这个比值越高,说明预测的效果越好。
置信度阈值:
- 每一个目标检测框都会带有一个置信度,表示该边界框中的内容是被检测的物体的概率。
- 如果这个概率值大于一定的置信度阈值,才保留对应的目标检测框。
map指标:结合精确率、召回率、IOU指标和置信度阈值的综合评价指标。map值其实是精确率与召回率曲线与横纵坐标轴所围成的面积大小。对于目标检测任务,MAP值越大表示效果越好。
3.YOLO V1
YOLO的含义:YOU ONLY LOOK ONCE。
YOLO v1的提出时间:2016年。
YOLO v1的核心思想:
- 首先将一张图片分为指定大小(7×7)的多个网格;
- 只关注待检测物体的中心点落在哪个网格中,则由该网格负责对待检测物体进行预测。
- 根据经验先确定两种不同长宽比的检测框,并在模型过程中通过IOU值选择其中一个,如果该检测框的置信度高于一定的阈值,则对其长宽进行调整。
- 调整的过程相当于一个回归预测的过程。调整完成后得到最终的预测检测框。
每个网格的输出值:对于每一个网格,需要预测出两组值,是指该网格对应的检测框的中心坐标(x,y),以及检测框的长宽数据,同时还需要一个置信度。
YOLO v1的输入图像大小:448×448。之所以YOLO v1的输入大小不能改变,是因为网络结构中有全连接层的存在,这一点在后续的版本中有相应的改进。
YOLO使用相对坐标值:在YOLO模型中,候选框的坐标值并非绝对坐标值,而是相对坐标值。
YOLO v1输出结果解释:YOLO V1的输出结果可以表示为7×7×30。其中的7×7表示每个网格中的像素个数;30可以拆分为20和10:20表示属于20个类别对应的概率,10表示两个目标检测框各自的(x,y,w,h,c),其中的c表示置信度。将输出结果更加一般化。假设每个网格的像素为S×S,每个网格分配的目标检测框个数为B,需要进行的多分类类别数为C,那么网络最终的预测结果为(SS)(B*5+C)。
YOLO v1中的损失函数:
- 位置误差损失函数:通过一定的计算衡量预测框与真实框之间的位置和大小差异。
- 置信度误差损失函数:通过一定的计算衡量预测框和真实框之间的置信度误差。需要分为含有待检测物体和不含有待检测物体的两部分函数,之所以需要分开,是因为背景和物体的比例不均衡,因此两个损失函数的权重也不相同。
- 分类误差损失函数:对于分类的正确和错误的情况需要设置一个额外的损失函数。
- 总体损失函数:总体损失函数是其他几种损失函数相加的结果。
非极大值抑制(NMS):非极大值抑制用于处理这样一个问题:如果对于同一个目标,同时存在多个大于IOU阈值的相互之间有部分重叠的候选框,那么我们只选择其中置信度最高的候选框作为最终结果。
YOLO V1的问题:
- 难以检测重合在一起的目标;
- 不方便完成多标签分类任务以及小物体的分类任务。
4.YOLO V2
YOLO V2的改进细节:
- 批量归一化技术:YOLO V2版本丢弃了YOLO V1中的Dropout层,卷积之后全部加入批量归一化。网络的每一层输入都做了归一化,更加容易收敛。
备注:从现在的角度来看,批量归一化处理已经成为了网络的必备处理方式,可以有效提高网络的效果。这是因为归一化可以有效地优化每一层的输出结果防止其跑偏,更加容易收敛。
- 更高的分辨率:在训练过程的最后使用更高分辨率的图像对模型进行微调。这样处理后的模型的MAP值得到的明显提高。
- 舍弃全连接层:YOLO V2中舍弃了全连接层,从而避免了全连接层容易过拟合和训练速度慢的问题。
- Darknet网络结构:YOLO V2中的Darknet网络结构越简单,速度越快;Darknet网络结构越复杂,模型效果越好,但是速度也会变慢。Darknet的输入大小为416×416。
- 更大的网格:相较于YOLO v1中的7×7的网格大小,YOLO v2中采用13×13的网格大小,这样可以获得更多的特征。
- 更小的卷积核:YOLO V2中采用的卷积核都比较小,这样就使得感受野会变得更大。
- 更多长宽比例的先验框:Faster-RCNN中选择的常规的先验比例来制定九种先验框,但是这个方法不一定完全适合数据集。YOLO V2中采用聚类的方式提取先验框。具体的聚类方法是,对图像原始数据集中的边界框进行聚类,按照长宽的大致比例将边界框分为多类。接着,将每一个簇选出一个中心点,并将中心点的数值作为先验框的大小。所以,这样得出的先验框比例更加具有说服力。这里的聚类中的聚类使用1-IOU表示。聚类方式是K均值聚类算法。聚类的个数是通过参数比较得出的,最终得出的K值是5。
备注:候选框种类增加并不会增加MAP值,但是可以增加召回率的值。也就是说,可以尽可能避免图像中的物体不被检测出来的情况。
感受野:
- 感受野的概念:感受野就是指特征图上的一个点能够看到原始图像中的多大区域。特征图中的每个点都相当于原始图像中与卷积核大小相同的一个区域的内容。因此,感受野越大越能识别到一个大区域内的特征或物体内容。
- 感受野的大小的理解:卷积的次数越多,特征更加深层和抽象。这可以视为最终感受野很大的效果。
- 堆叠多个小卷积层:之所以需要堆叠多个小卷积层而不是使用一个大的卷积层。这是因为堆叠小的卷积核需要的参数更少,并且卷积过程越多,特征提取也会更加细致。这也是VGG网络的基本出发点:用小的卷积核来完成特征提取操作。
特征融合的改进方法:如果只关注最后一层卷积层的特征图,那么就会丢失小目标的信息,因此需要融合之前的特征。为了将多个阶段的特征图放在一起处理,因此需要将不同形状的特征图进行形状转换,并拼接在一起进行处理。
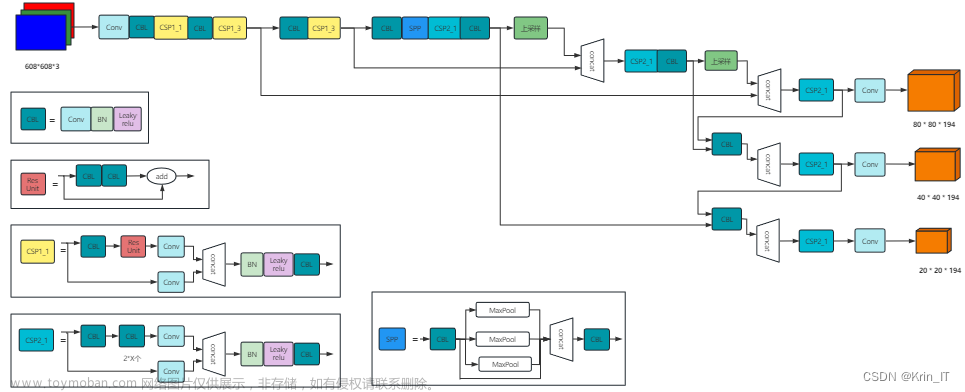
5.YOLO V3
YOLO v3的改进细节:文章来源:https://www.toymoban.com/news/detail-410361.html
- 网络结构改进:最大的改进在于网络结构,使得其可以更加适合于小目标检测。
- 先验框的选择更加丰富:YOLO V3中有了更加类型丰富的先验框,一共3种比例,每种3个规格。
- 改进版本的Softmax函数:YOLO V3中使用了改进版本的Softmax函数,用于预测多标签任务。
- 特征融合的改进方法:图像金字塔(之前比较流行)。这是指将图像先规格化为不同的尺度后融合在一起,但是由于速度较慢现在已经较少使用。另外一种是分别得到不同规格大小的特征图后,将不同规格的特征图叠加融合在一起。融合之后就避免了对不同大小的特征图都要进行一次分析。
- 采用残差连接方法:YOLO V3中也使用了Resnet的思想,通过堆叠更多的层来进行特征提取。
- 去除全连接层和池化层:除了没有全连接层外,同时也去除了会压缩特征图效果的池化层。
备注:Resnet很好地解决了深度神经网络越深效果越差的问题。其核心在于使用了残差连接的方法。残差连接就是对于神经网络中,如果经过某一层网络效果下降,那么就从支路绕过这一层。文章来源地址https://www.toymoban.com/news/detail-410361.html
到了这里,关于深度学习(目标检测):YOLO网络学习笔记(YOLO v1,YOLO v2和 YOLO v3)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!