前言
对于Spark,网上涉及到Windows平台搭建的资料不多。大多资料不全,而且很少说明注意事项,存在一定的挖坑行为。对于不是很熟悉spark环境搭建过程,但是又非常想在自己的电脑上搭建一个本地环境的小伙伴来说存在一定的绕路行为。本文借鉴了网上大部分的资料,在整理集成的同时,会以一次完整的环境搭建过程为演示内容。
借鉴文章
- vscode配置spark
- Windows7-8-10安装部署hadoop-2.7.5(最详细的步骤,不需要cygwin
- windows平台下安装配置Hadoop
- windows10上配置pyspark工作环境
- …
环境
- 操作系统: Windows 10 x64
- 集成环境: 管理员模式运行的VSCode
- Python版本: 3.10.4 (env)
-
JAVA SDK: 1.8.0
- 注意本文默认已安装JAVA,如未安装JAVA请提前安装。安装时注意路径不要有空格。
- 安装spark环境之前,需要检查环境变量
JAVA_HOME以及path内java路径一定不要有空格。如果有空格,就需要修改JDK路径。具体方法本文不再赘述,请查阅JAVA改路径相关资料。改完之后还要记得更新path。 - 注意,本文是在本地环境部署Spark。
步骤
Spark环境强调版本依赖,所以搭建最重要的一环就是版本管理。Spark环境由下面四个工程组成:
| Project | Download Url |
|---|---|
| Spark | https://spark.apache.org/downloads.html |
| Hadoop | https://archive.apache.org/dist/hadoop/common/ |
| Scala | https://www.scala-lang.org/download/all.html |
| winutils-master | https://github.com/cdarlint/winutils |
这里面,Spark会决定Scala和Hadoop的版本;而Hadoop又会受到winutils-master版本的影响。他们的关系可以用下图表示:
一、确定版本
1.1 确定winutils-master版本
通过访问winutils-master的download url,可获取目前为止所有的winutils-master版本。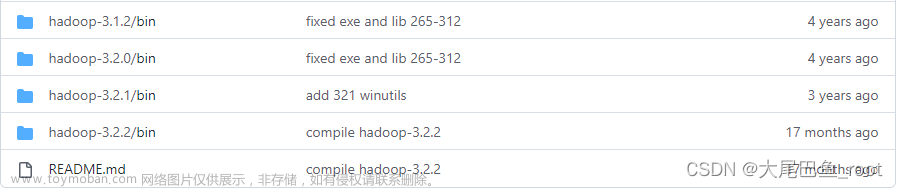
假定我们选择最新的版本:
- Hadoop 3.2.2/bin
它的名称就是所兼容的Hadoop版本,是不是很贴心。
1.2 确定Hadoop版本
上一步给出了兼容的Hadoop版本为version<=3.2.2。
- Hadoop 3.2.2
接下来由它确定兼容的Spark版本。注意,暂时不要下载任何文件,因为我们不确定这个版本是不是最终需要的版本。
1.3 确定Spark版本
Spark主页用多个关联控件的形式帮助我们确定版本。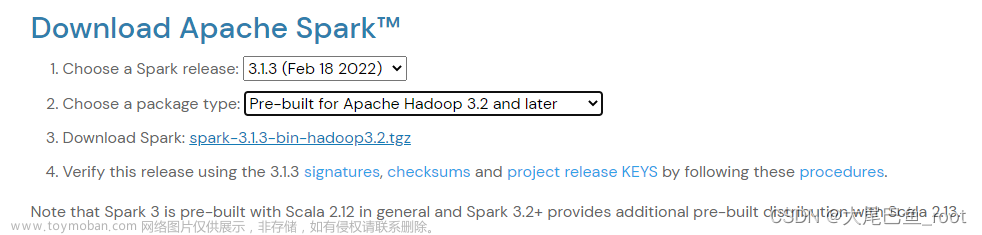
- Spark release = 3.1.3
上面是我选择的版本,主页显示它兼容Hadoop3.2 and later。注意,暂时不要下载任何文件,因为我们不确定这个版本是不是最终需要的版本。
1.4 确定Scala版本
先不要关闭上一步的页面,留意页面中的这句话:
Note that Spark 3 is pre-built with Scala 2.12 in general and Spark 3.2+ provides additional pre-built distribution with Scala 2.13
他提示我们兼容的的Scala version = 2.12。这就方便了我们寻找最后一个工程的版本号码。注意,暂时不要下载任何文件,因为我们不确定这个版本是不是最终需要的版本。
- Scala release = 2.12
二、下载各个版本
通过访问上文列表中各个工程的download url,将全部工程下载到本地的某个文件夹里面。
- winutils-master下载办法:点击github右上角的
Code,选择Download ZIP,将整个仓库文件夹下下来,然后取需要的版本。
我假设所有文件都存放于C:\Users\zhhony\Downloads\,这个路径无所谓,记得就行。
三、安装
准备工作
- 首先准备一个文件夹,用于存储Spark的环境文件。注意路径不要有中文,不要有空格:
- Spark环境建议路径:
D:\Spark_env
- Spark环境建议路径:
- 其次给Hadoop工程准备一组文件夹,用于存储Hadoop运行产生的文件。注意路径不要有中文,不要有空格:
- Hadoop仓库建议路径:
D:\tmp - Hadoop仓库建议子路径:
D:\tmp\dfs\data - Hadoop仓库建议子路径:
D:\tmp\dfs\name
- Hadoop仓库建议路径:
3.1 安装Scala
-
按照本文步骤下载的Scala将是一个.msi文件,直接双击安装,把默认安装路径改到环境文件夹
D:\Spark_env的下面。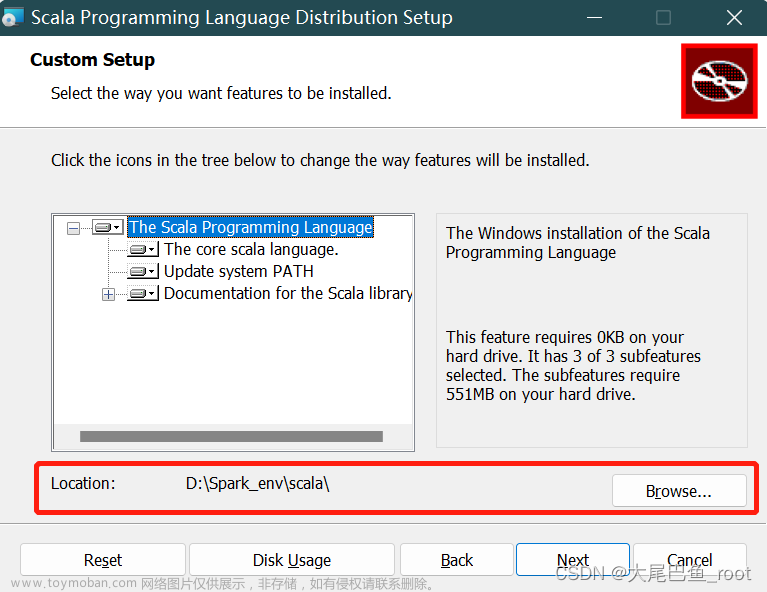
-
在操作系统环境变量中新添加一个变量
SCALA_HOME = D:\Spark_env\scala\bin: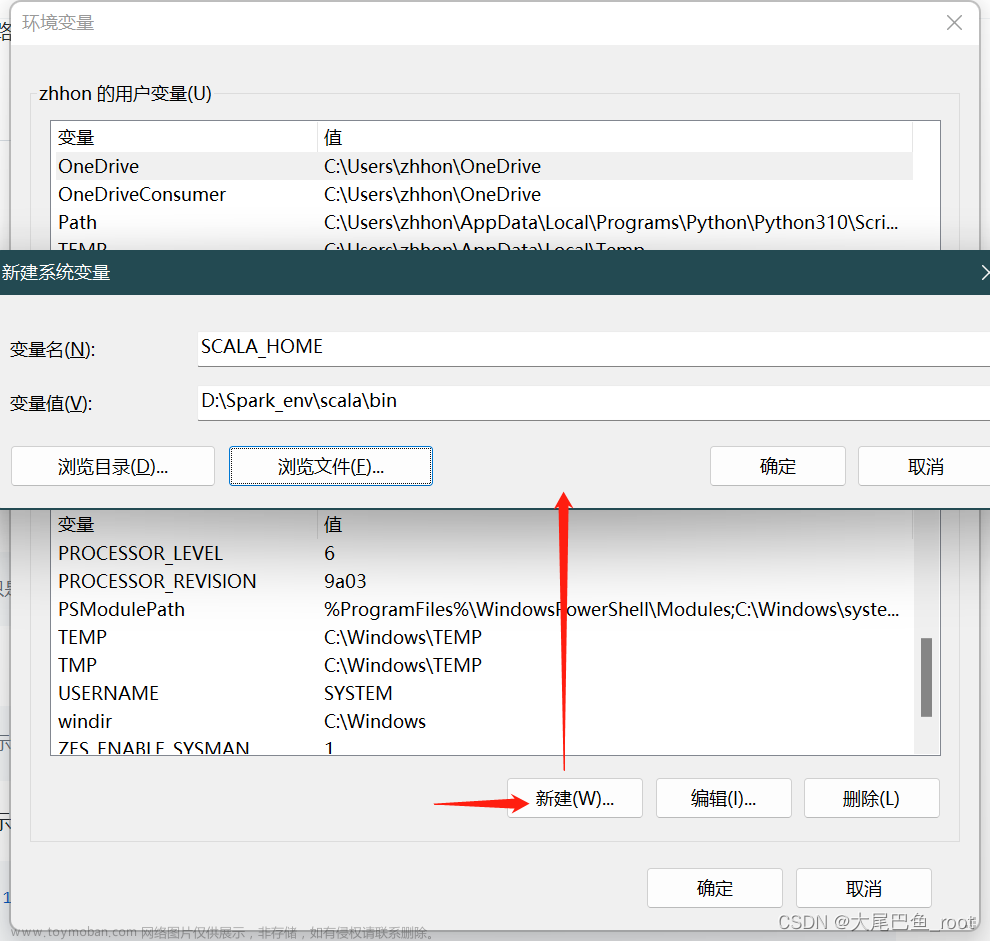
-
同时修改操作系统的
Path变量,新增一个D:\Spark_env\scala\bin。如果系统已经建好了这个值就不用再建了: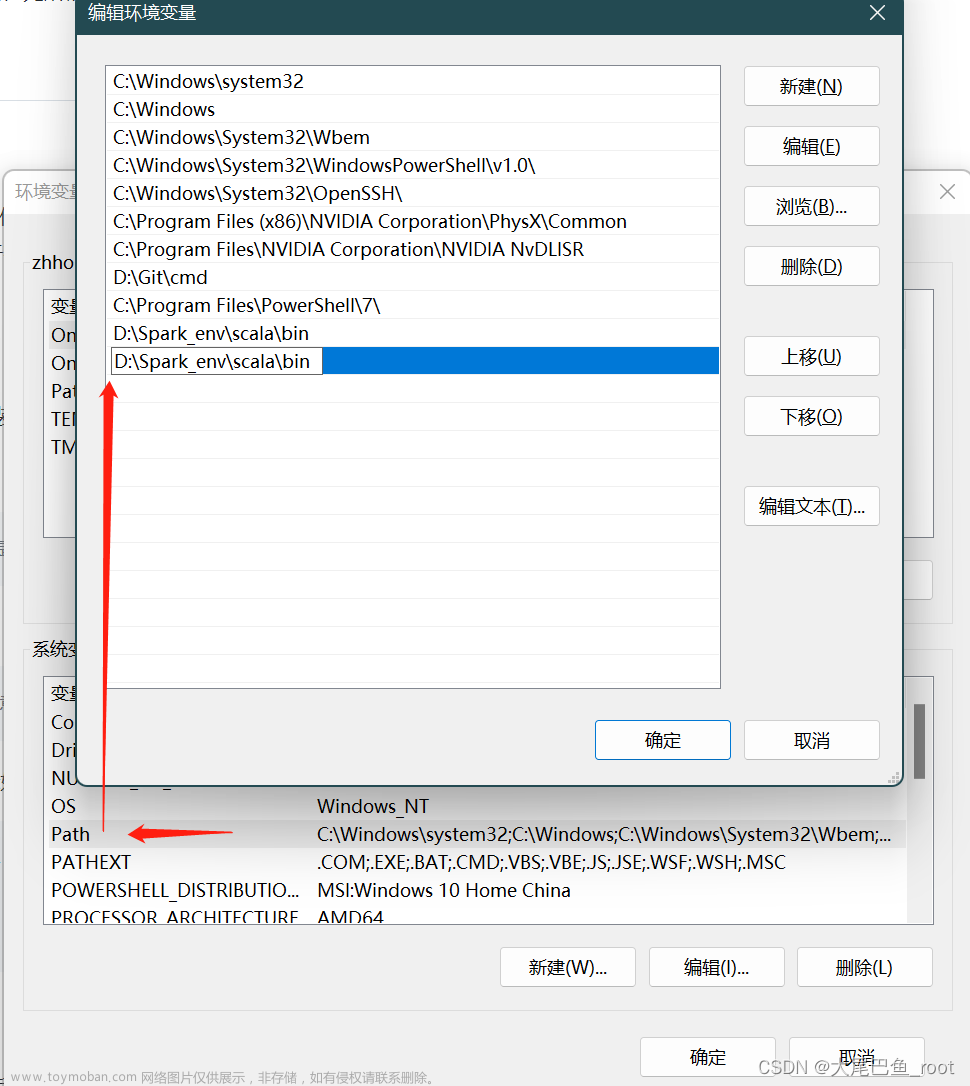
安装完成之后,重新开启一个CMD,输入scala命令,如果显示如下,则表示安装成功:
Welcome to Scala 2.12.0 (OpenJDK 64-Bit Server VM, Java 1.8.0_332).
Type in expressions for evaluation. Or try :help.
scala>
3.2 安装Spark
-
将下载的
spark-3.1.3-bin-hadoop3.2.tgz直接解压,解压后会有一个spark-3.1.3-bin-hadoop3.2文件夹,将这个文件夹整体搬运到D:\Spark_env下。
-
去到文件夹下面的
python里,将pyspark搬运到python库目录里(pyspark.egg-info存在则也搬过去)。库目录的寻找方法本文不再赘述,可以查阅相关资料。库目录一般路径是:C:\Users\{youraccount}\AppData\Local\Programs\Python\Python38\Lib\site-packages -
在操作系统环境变量中新添加一个变量
SPARK_HOME = D:\Spark_env\spark-3.1.3-bin-hadoop3.2: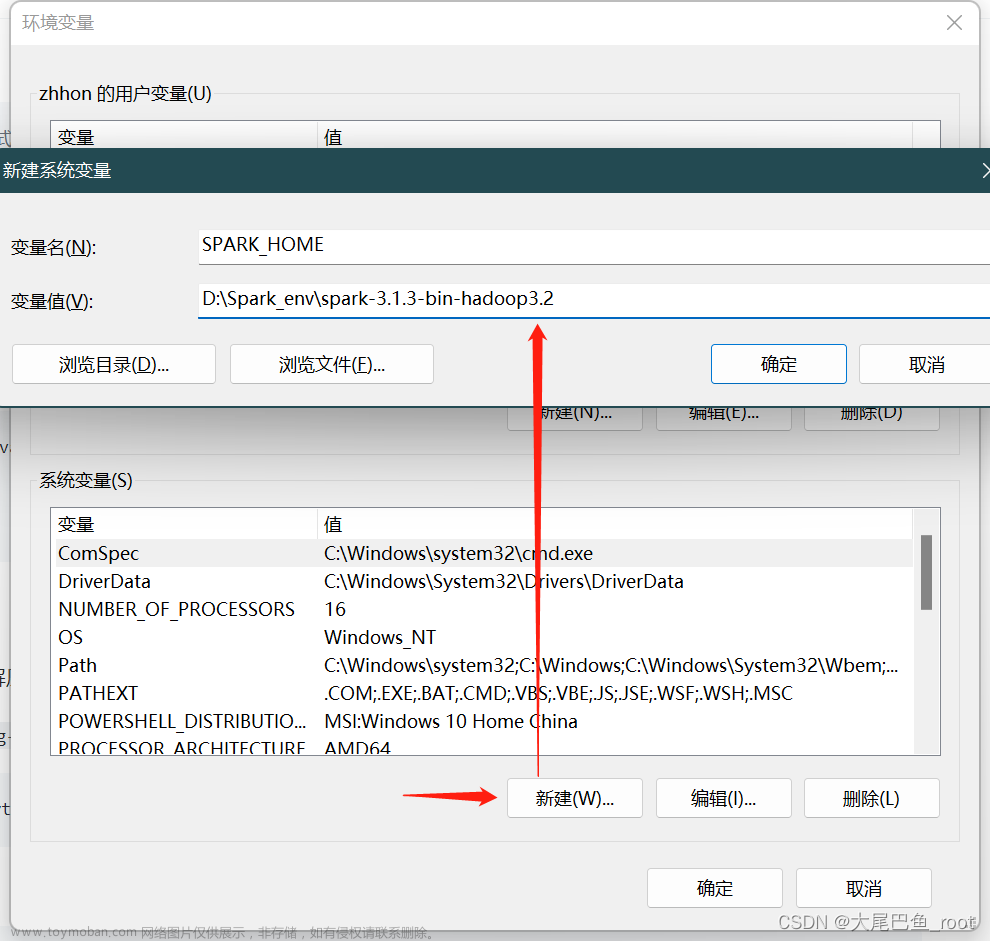
-
同时修改操作系统的
Path变量,新增一个%SPARK_HOME%\bin: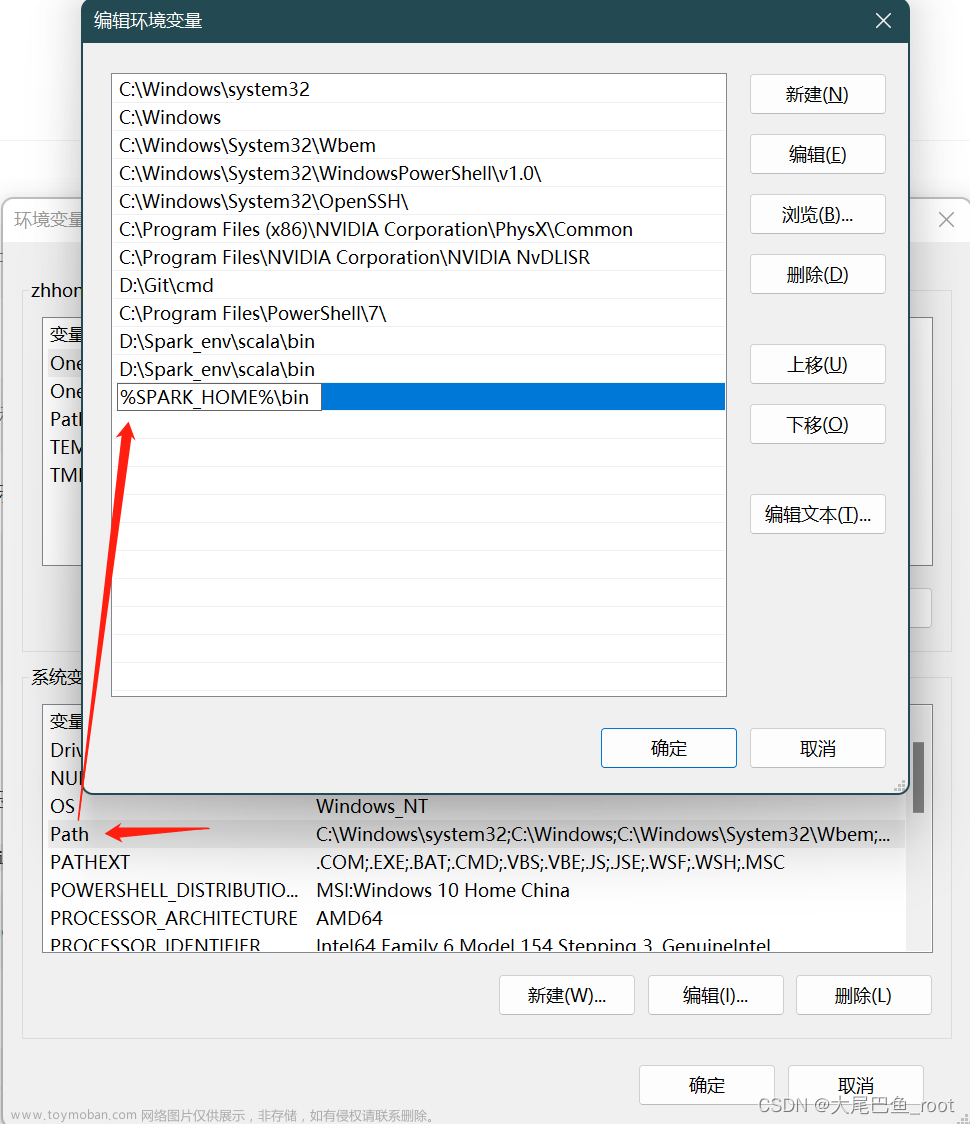
-
这一步,如果电脑用户名含有下划线
_,则需要多加一个环境变量SPARK_LOCAL_HOSTNAME = localhost。加的方法参考上文。同时,去spark的bin文件夹下寻找
spark-shell.cmd,右键编辑,在@echo off下面加一行SPARK_LOCAL_IP=127.0.0.1
3.3 安装Hadoop
-
将下载的
hadoop-3.2.2.tar.gz直接解压,解压后会有一个hadoop-3.2.2文件夹,将这个文件夹整体搬运到D:\Spark_env下。
-
在操作系统环境变量中新添加一个变量
HADOOP_HOME = D:\Spark_env\hadoop-3.2.2,加的方法可以参考Spark环节。 -
同时修改操作系统的
Path变量,新增一个%HADOOP_HOME%\bin,加的方法可以参考Spark环节。
3.4 安装winutils-master
将下载的winutils-master.zip直接解压,解压后寻找hadoop-3.2.2\bin文件夹,将这个文件夹里面的文件,整体搬运到D:\Spark_env\hadoop-3.2.2\bin下,直接覆盖原文件。
winutils-master\hadoop-3.2.2\bin --copy--> D:\Spark_env\hadoop-3.2.2\bin
四、配置修改
-
在操作系统环境变量中新添加一个变量
PYSPARK_PYTHON,用于指定python解释器路径,这一步请参考上文环境变量的修改方法来。下面是我的例子:PYSPARK_PYTHON = D:\WorkShop\python\.env\Scripts\python.exe # 我的解释器放在虚拟环境里,和默认路径不一样 -
通过
pip install py4j命令在python中安装py4j库,pip的使用这里不再赘述。
五、Hadoop配置专项修改
-
编辑
hadoop-3.2.2\etc\hadoop文件夹下的core-site.xml文件,将下列文本放入<configuration></configuration>标签内并保存:<property> <name>hadoop.tmp.dir</name> <value>/D:/tmp</value> </property> <property> <name>dfs.name.dir</name> <value>/D:/tmp/name</value> </property> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> -
编辑
hadoop-3.2.2\etc\hadoop文件夹下的mapred-site.xml文件,将下列文本放入<configuration></configuration>标签内并保存:<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapred.job.tracker</name> <value>hdfs://localhost:9001</value> </property> -
编辑
hadoop-3.2.2\etc\hadoop文件夹下的hdfs-site.xml文件,将下列文本放入<configuration></configuration>标签内并保存:<property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.data.dir</name> <value>/D:/tmp/data</value> </property> -
编辑
hadoop-3.2.2\etc\hadoop文件夹下的yarn-site.xml文件,将下列文本放入<configuration></configuration>标签内并保存:<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> -
鼠标右键编辑
hadoop-3.2.2\etc\hadoop文件夹下的hadoop-env.cmd文件,将JAVA_HOME用@rem注释掉,改为系统环境变量中JAVA_HOME变量的路径,然后保存。类似于下面这样:@rem set JAVA_HOME=%JAVA_HOME% set JAVA_HOME=D:\Java\jdk1.8.0_181- 如果java是装在
C:\Program Files文件夹下面,这时候由于路径含有空格,是无法供Hadoop使用的。这时候可以用progra~1替换Program Files。参考文章: 为什么文件路径 Program Files 可以写成 Progra~1。
- 如果java是装在
六、格式化Hadoop
- 管理员模式运行cmd窗口,执行
hdfs namenode -format。如果提示是否重新格式化,输入y; - 管理员模式运行cmd窗口,切换到hadoop的sbin目录,执行
start-all,启动Hadoop。弹出的四个窗口不出现shutdown说明启动成功。
到这一步实际上环境就已经搭建完毕了。需要hive的小伙伴可以继续尝试搭建hive。
七、尝试在python中启动spark
管理员模式运行cmd窗口,键入命令pyspark,显示如下内容表示启动成功文章来源:https://www.toymoban.com/news/detail-410769.html
Python 3.10.4 (tags/v3.10.4:9d38120, Mar 23 2022, 23:13:41) [MSC v.1929 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.1.3
/_/
Using Python version 3.10.4 (tags/v3.10.4:9d38120, Mar 23 2022 23:13:41)
Spark context Web UI available at http://localhost:4040
Spark context available as 'sc' (master = local[*], app id = local-1661958484812).
SparkSession available as 'spark'.
>>>
也可以按导入包的模式启动spark文章来源地址https://www.toymoban.com/news/detail-410769.html
>>> from pyspark import sql
>>> spark = sql.SparkSession.builder.enableHiveSupport().getOrCreate()
>>> l = [('Alice', 1)]
>>> spark.createDataFrame(l).collect()
[Row(_1='Alice', _2=1)]
到了这里,关于Spark的Windows本地化部署完整方案的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!