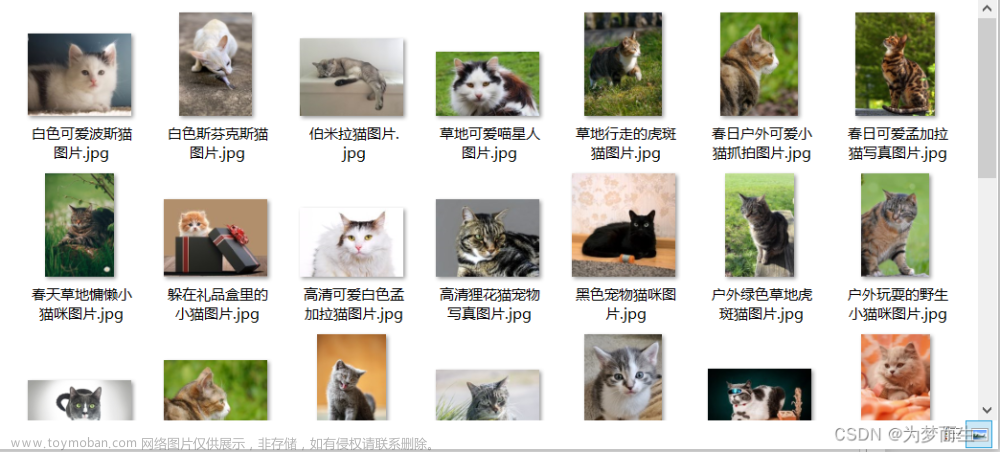
研究Python爬虫,网上很多爬取pexels图片的案例,我下载下来运行没有成功,总量有各种各样的问题。
作为菜鸟初学者,网上的各个案例代码对我还是有不少启发作用,我用搜索引擎+chatGPT逐步对代码进行了完善。
最终运行成功。特此记录。
运行环境:Win10,Python3.10、Google Chrome111.0.5563.148(正式版本)
文章来源:https://www.toymoban.com/news/detail-410904.html
1 import urllib.request 2 from bs4 import BeautifulSoup 3 import os 4 import html 5 import requests 6 import urllib.parse 7 8 path = r"C:\Users\xiaochao\pexels" 9 url_lists = ['https://www.pexels.com/search/book/?page={}'.format(i) for i in range(1, 21)] #页面范围请自行根据实际情况修改。 10 headers = { 11 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36", 12 "Referer": "https://www.pexels.com/", 13 "Accept-Language": "en-US,en;q=0.9", 14 } 15 16 for url in url_lists: 17 print(url) 18 req = urllib.request.Request(url, headers=headers) 19 try: 20 resp = urllib.request.urlopen(req) 21 except urllib.error.HTTPError as e: 22 print("HTTPError occurred: {}".format(e)) 23 continue 24 25 html_content = resp.read().decode() 26 soup = BeautifulSoup(html_content, "html.parser") 27 28 import re 29 pattern = re.compile('"Download" href="(.*?)/?cs=', re.S) 30 matches = re.findall(pattern, html_content) 31 print(matches) 32 33 if not os.path.exists(path): 34 os.makedirs(path) 35 36 for match in matches: 37 match_cleaned = match.split('?')[0] # 去除图片URL地址最后带的“?”号。 38 print(match_cleaned) # 输出去除图片URL“?”号的地址 39 match_cleaned = html.unescape(match_cleaned) #解码 HTML 编码字符,将文件链接还原为正常的 URL 格式 40 match_cleaned = urllib.parse.unquote(match_cleaned) # 对 URL 进行进一步处理,解码URL,确保它的格式正确,包括删除多余的引号和处理特殊字符。 41 match_cleaned = urllib.parse.urljoin(url, match_cleaned) # 将相对 URL 转换为绝对 URL 42 43 44 # 按URL地址后段命名 45 filename = match_cleaned.split("/")[-1] 46 with open(os.path.join(path, filename), "wb") as f: 47 f.write(requests.get(match_cleaned).content)
文章来源地址https://www.toymoban.com/news/detail-410904.html
到了这里,关于Python爬取pexels图片的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!