本文将从单机定时调度开始,循序渐进地带领大家了解五福定制三层分发任务处理框架。文章来源:https://www.toymoban.com/news/detail-411180.html
一、背景介绍
二、定时任务分类

2.1、单机任务
单机定时任务毫无疑问是在单台机器上运行的定时任务。在业务量级不大,没有进行分库分表时,往往单机定时任务即可满足业务需求。
从复杂度上来说,单机定时任务又可分为简单的定时调度和定时调度+批处理两种。
1、定时调度
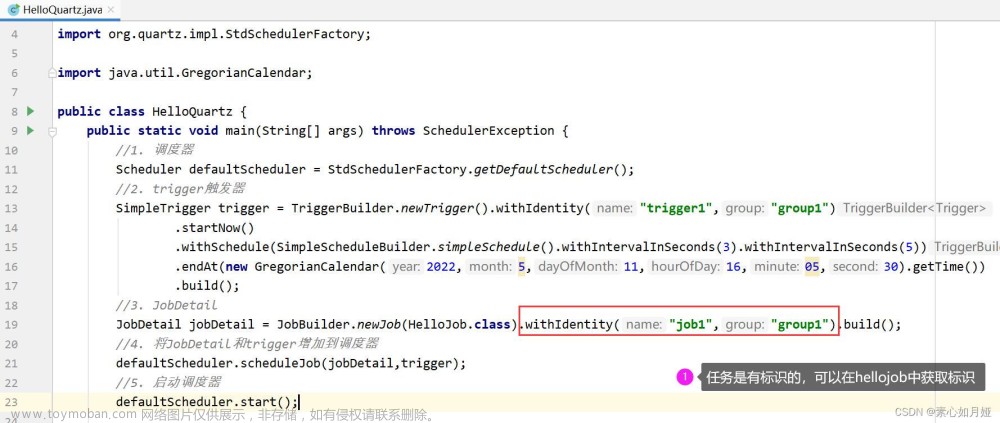
在Spring中可以通过@Scheduled 来启用定时任务。触发的方式有两种,分别是:cron 表达式和 fixedRated类配置参数。常用的案例:
// cron表达式
@Scheduled(cron="0 0/30 9-17 * * ?") //按cron规则执行,朝九晚五工作时间内每半小时
@Scheduled(cron="0 0 12 ? * WED") //按cron规则执行,表示每个星期三中午12点
// fixedRated类配置
@Scheduled(fixedRate=5000) //上一次开始执行时间点后5秒再次执行;
@Scheduled(fixedDelay=3000) //上一次执行完毕时间点后3秒再次执行;
@Scheduled(initialDelay=1000, fixedDelay=2000) //第一次延迟1秒执行,然后在上一次执行完毕时间点后2秒再次执行;定时调度往往用于业务处理流程比较简单的场景,比如定时生成简单报表,发送通知。对于复杂耗时的场景,处理效率不高,业务高峰期会积压大量待处理数据,影响业务。
2、定时调度+批处理
为了解决复杂耗时场景下定时调度效率不高的问题,可以引入批处理框架。定时调度与批处理框架相结合,可以大幅提高数据处理的效率,提升系统稳定性,保障业务稳定运行。
以Spring Batch批处理框架为例,任务处理流程如下:

Spring Batch批处理框架将任务拆分成多个Step,同时每个Step里面又分为itemReader,itemProcessor, itemWriter。通过将任务分层细化,能够让多个阶段并行处理,提高任务处理效率。批处理框架结合定时调度框架,可以在单机情况下,对大量复杂的业务进行高效的批处理。
2.2、集群任务
在分库分表大业务流量情况下,单机定时任务已无法满足业务需求了,这时就产生了集群定时任务。在支付宝技术架构下,用户数据按照eid进行分库分表,同时进行Zone维度的隔离。此时单机定时任务无法对全量数据做处理,于是支付宝便有了自己的分布式任务调度中间件Antscheduler,配合三层分发任务处理框架,就可以对大量数据进行定时批量处理。
1、三层分发

2、五福定制三层分发

/**
* 根据配置中心的dataFlag过滤
* 1、默认ALL不区分
* 2、ODD 表示仅分发奇数表号
* 3、EVEN 标识仅分发偶数表号
*
* @param eidList
*/
public void filteByDataFlag(List<String> eidList) {
String dataFlag = SchedulerConfigDrmUtil.getIndexFilterFlag();
int strategy = -1;
if (StringUtil.equalsIgnoreCase("ODD", dataFlag)) {
strategy = 1;
} else if (StringUtil.equalsIgnoreCase("EVEN", dataFlag)) {
strategy = 0;
}
if (strategy == -1) {
// ALL
return;
}
// filter
Iterator<String> it = eidList.iterator();
while (it.hasNext()) {
String str = it.next();
int index = NumberUtils.toInt(str, -1);
if (index % 2 != strategy) {
it.remove();
}
}
}通过代码可知,推送任务配置时,将A组机器的值推成“ODD”,B组机器的值推成“EVEN”,即可实现A/B组的所有机器同时执行定时任务的效果。
/**
* 计算定时任务的相关配置
*
* 主要计算:
* scheduleSingleLimit 单机限流值
* scheduleLoaderCount loader捞取条数
*
* @param scheduleConfig
*/
public static SchedulerConfig calculateScheduleConfig(SchedulerConfig scheduleConfig) {
final int qpsLimit = scheduleConfig.getScheduleWholeLimit();
final int machineCounts = scheduleConfig.getScheduleMachineCounts();
MtLogger.info(LOGGER,
"【计算定时任务配置】-开始 任务名称:{0},机器数量:{1},任务吞吐量:{2}.", scheduleConfig.getScheduleType(),
machineCounts, qpsLimit);
//定时任务的调度频率是scheduleRate 秒执行一次 所以scheduleRate秒中内集群的整体吞吐量=qps限制*scheduleRate
final int scheduleRate = scheduleConfig.getScheduleRatePerSec();
long totalLoaderCounts = qpsLimit * TimeUnit.SECONDS.toSeconds(scheduleRate);
//定时任务捞取的表数量为1000 所以到每个表的限制=totalLoaderCounts/1000
long loaderCountPerTask = totalLoaderCounts / 1000;
if (loaderCountPerTask < 1) {
loaderCountPerTask = 1;
}
scheduleConfig.setScheduleLoaderCount((int) loaderCountPerTask);
//整体限流通过单机限流实现 整体限流=单机限流*machineCounts
final double singleQps = ((double) qpsLimit / machineCounts);
//创建的限流需要1秒的预热
scheduleConfig.setScheduleSingleLimit(RateLimiter.create(singleQps, 1, TimeUnit.SECONDS));
MtLogger.info(LOGGER,
"【计算定时任务配置】-结束 任务名称:{0},捞取条数:{1},单机限流:{2}.", scheduleConfig.getScheduleType(),
scheduleConfig.getScheduleLoaderCount(),
scheduleConfig.getScheduleSingleLimit().getRate());
return scheduleConfig;
}通过代码可知,推送的任务配置最终会生成两个重要的配置信息:

相比通常情况下指定Loader每次捞取的任务数,五福是通过集群qps和任务调度间隔来确定Loader需要捞取的任务数。因此一个调度间隔内的任务数和集群能够执行的任务数是匹配上的,加上通过单机qps限制达到集群qps限制的效果,从而让整个定时任务做到了平滑调用。简而言之,优化后的调度逻辑,能够让定时调度任务在机器维度和时间维度都能均匀平稳的执行。

三、结语
从单机到集群,再到五福定制集群定时任务,本文逐步做了一个框架设计上的原理介绍。每种定时任务都有自己的优点和缺陷,也都有自己的应用场景。在工作中,要结合当前的业务情况,选择合适的定时任务进行业务处理,避免设计上的失误导致业务受损。以五福定制三层分发任务处理框架为例,虽然日常业务中,因为机器数量不固定,依旧无法做到任务的平滑调用,但我们可以借鉴最大化利用集群机器资源这一点,同时开启A/B组的定时任务,从而实现任务调度真正的负载均衡,提高系统整体的稳定性。
作者|金盛杰(司旭)文章来源地址https://www.toymoban.com/news/detail-411180.html
到了这里,关于支付宝定时任务怎么做?三层分发任务处理框架介绍的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!