Selenium自动化案例
简单说明:最近学习了一下python爬虫,然后这是涉及到的其中一门技术,提功能强大,这只是个简单案例,都实现了自动百度的功能,结合其他的会更加的自动,更利于开发。
Selenium的基本概述
1.什么是selenium?
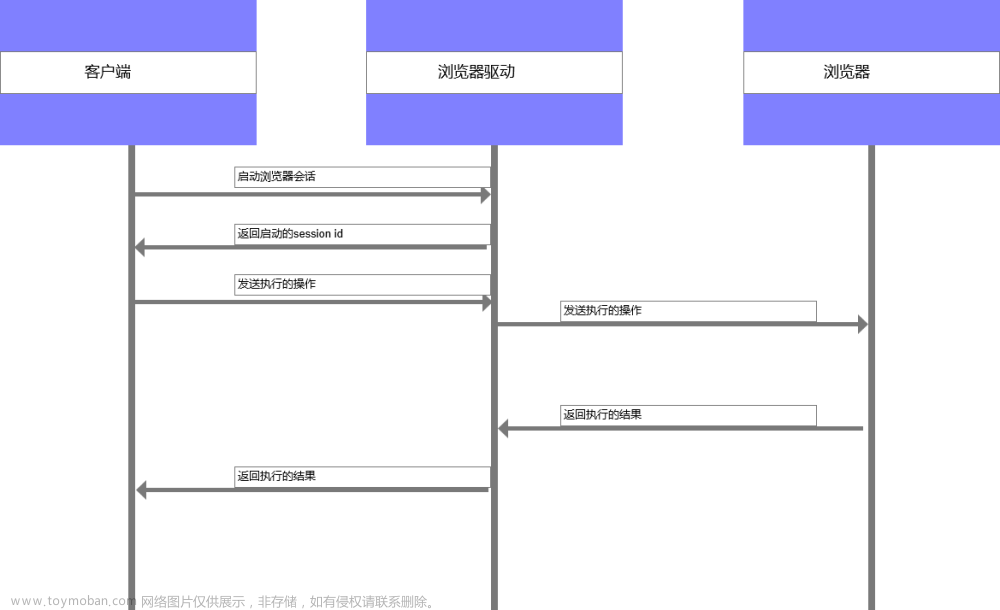
(1)Selenium是一个用于Web应用程序测试的工具。
(2)Selenium 测试直接运行在浏览器中,就像真正的用户在操作一样。
(3)支持通过各种driver(FirfoxDriver,IternetExplorerDriver,OperaDriver,ChromeDriver)驱动
真实浏览器完成测试。
(4)selenium也是支持无界面浏览器操作的。
2.为什么使用selenium?
模拟浏览器功能,自动执行网页中的js代码,实现动态加载
3.如何安装selenium?
(1)操作谷歌浏览器驱动下载地址
http://chromedriver.storage.googleapis.com/index.html
(2)谷歌驱动和谷歌浏览器版本之间的映射表
http://blog.csdn.net/huilan_same/article/details/51896672
(3)查看谷歌浏览器版本
谷歌浏览器右上角‐‐>帮助‐‐>关于
(4)pip install selenium
4.selenium的使用步骤?
(1)导入:from selenium import webdriver
(2)创建谷歌浏览器操作对象:
path = 谷歌浏览器驱动文件路径
browser = webdriver.Chrome(path)
(3)访问网址
url = 要访问的网址
browser.get(url)
案例测试。
需求:用selenium自动打开百度首页,然后自动输入周星驰,然后百度一下,滑到最底部,然后点击下一页,然后返回,然后关闭退出。
1.首先导包,然后创建浏览器对象,打开一个网页。
#1.导包
from selenium import webdriver
#将下载的谷歌浏览器驱动放进来,将其放在一个文件下
path='chromedriver.exe'
#创建浏览器对象,我是使用的chrome,当然它也支持其他常见的浏览器,看个人选择
browser=webdriver.Chrome(path)
#url
url='https://www.baidu.com'
browser.get(url)
打开百度首页效果图:
2.然后就是获取首页里面的文本框输入对象,还有就是百度一下对象。
#通过源码看它们的id,就可以获取到两个对象
input = browser.find_element_by_id('kw')
input = browser.find_element_by_id('su')

3.写入数据,实现点击
# 在文本框中输入周星驰
input.send_keys('周星驰')
#实现点击百度一下
button.click()
4.进入另一页,实现滑到底部
# 滑到底部,固定写法
js_bottom = 'document.documentElement.scrollTop=100000'
browser.execute_script(js_bottom)
5.然后同第二部一样的原理,获取下一页的对象,实现点击功能。
# 获取下一页的按钮
next = browser.find_element_by_xpath('//a[@class="n"]')
# 点击下一页
next.click()
6.回到上一页和返回,并且关闭退出
# 回到上一页
browser.back()
# 回去
browser.forward()
# 退出
browser.quit()
动态图片:

多次测试过后,发现自动下滑的时候出现了验证,所有需要该selenium需要结合其他的使用,比如添加Chrome handless
Chrome-headless 模式, Google 针对 Chrome 浏览器 59版 新增加的一种模式,可以让你不打开UI界面的情况下
使用 Chrome 浏览器,所以运行效果与 Chrome 保持完美一致。 就不需要每次都打开界面,也可以进行该操作,可以选择操作时进行快照的方式,拍摄图片,也更加的省效率,绕过登录的话,还需要结合其他技术一起使用,使其更高效,功能更强大。文章来源:https://www.toymoban.com/news/detail-411420.html
完整代码:文章来源地址https://www.toymoban.com/news/detail-411420.html
#1.导包
from selenium import webdriver
#将下载的谷歌浏览器驱动放进来,将其放在一个文件下
path='chromedriver.exe'
#创建浏览器对象,我是使用的chrome,当然它也支持其他常见的浏览器,看个人选择
browser=webdriver.Chrome(path)
#url
url='https://www.baidu.com'
browser.get(url)
import time
#打开过后休眠一秒,看下反应,方便对比
time.sleep(1)
# 获取文本框的对象
input = browser.find_element_by_id('kw')
# 在文本框中输入周星驰
input.send_keys('周杰伦')
time.sleep(1)
#获取百度一下对象
button = browser.find_element_by_id('su')
#实现点击百度一下
button.click()
# 滑到底部,固定写法
js_bottom = 'document.documentElement.scrollTop=100000'
browser.execute_script(js_bottom)
time.sleep(1)
# 获取下一页的按钮
next = browser.find_element_by_xpath('//a[@class="n"]')
# 点击下一页
next.click()
time.sleep(1)
# 回到上一页
browser.back()
time.sleep(1)
# 回去
browser.forward()
time.sleep(1)
# 退出
browser.quit()
到了这里,关于Selenium自动化案例的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!