上篇文章简单的构造了一个知识图谱,但是其中包含了许多重复的结点,看起来也非常乱,不清晰。科学上网之后,发现了一个 apoc 的工具,关于 apoc 是什么如何安装,这篇文章有很好的介绍 Neo4j:入门基础(三)之APOC插件_Dawn_www的博客-CSDN博客_apoc neo4j,应下载与neo4j相应版本的jar包Releases · neo4j-contrib/neo4j-apoc-procedures · GitHub
于是乎我根据步骤操作完之后,检验是否安装成功,这样就是安装成功了,代码跑起来也没有报错不过重复结点并没有删除。

graph.run('MATCH (n:sex) WITH n.name AS name, COLLECT(n) AS nodelist, COUNT(*) AS count WHERE count > 1 CALL apoc.refactor.mergeNodes(nodelist) YIELD node RETURN node')
在neo4j启动的时候,有这样一个语句,但是上网查找并没有找到合适的解决办法,所以这个 apoc 工具暂且搁置,后面再研究。
APOC couln't set a URLStreamHandlerFactory since some other tool already did this (e.g. tomcat). This means you cannot use s3:// or hdfs:// style URLs in APOC. This is caused by a limitation of the JVM which we cannot fix.继续科学上网之后,最后发现了 merge() 方法,相见恨晚。(以后还是要多去看看源码或者官方文档)。使用的时候程序报错如下命令:
Primary label and primary key are required for MERGE operation这个是因为py2neo版本语法的问题。看源码可以解决。
create 和 merge的主要区别就是,create不会去判断节点中是否有重复数据,只是添加;而merge等于是create+match,如果节点中有重复数据,就不会添加进去。
基于上一篇文章py2neo连接知识图谱(包含代码,导入csv文件)_想不出叫啥名的博客-CSDN博客修改的去重复结点代码
import csv
from py2neo import *
graph = Graph("http://localhost:7474", auth=('neo4j','neo4j'))
graph.delete_all()
with open('data.csv', 'r') as f:
reader = csv.reader(f)
data = list(reader)
print(data[1]) # 测试
for i in range(1,len(data)):
node = Node('person', id = data[i][0], name = data[i][1], age =data[i][2])
relation = Node('address', name = data[i][4])
relation1 = Node('sex', name = data[i][3])
graph.create(node)
graph.merge(relation, 'address', 'name')
graph.merge(relation1, 'sex', 'name')
address = Relationship(node, '居住地', relation)
sex = Relationship(node, '性别', relation1)
graph.create(address)
graph.create(sex)
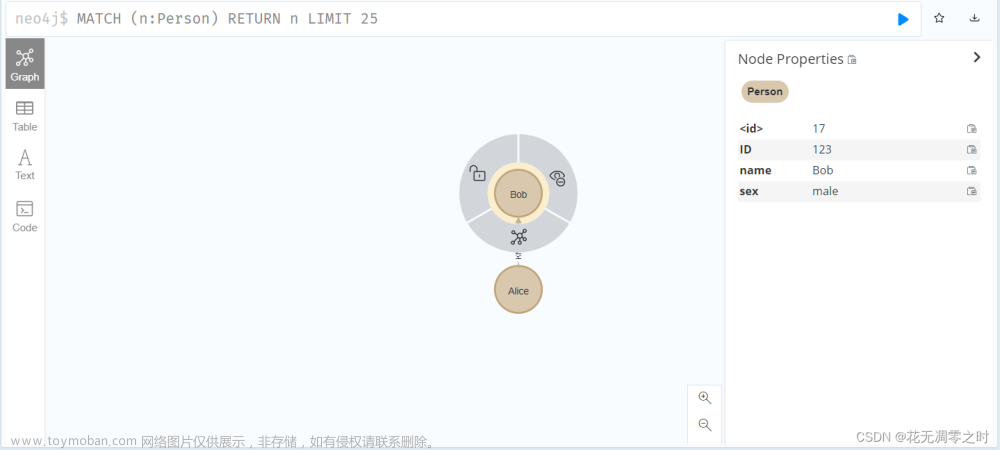
print("创建成功")neo4j可视化效果:

很明显,调理更加清晰了
文章来源地址https://www.toymoban.com/news/detail-411445.html
文章来源:https://www.toymoban.com/news/detail-411445.html
到了这里,关于py2neo创建知识图谱合并结点的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!