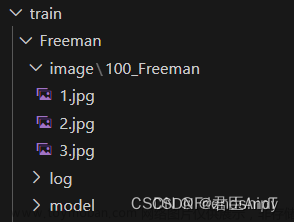
以坤坤为例,上网随便找了几个坤坤的人脸图像,作为训练的数据集

1 训练环境搭建
建议看一遍教程,虽然这个up主好像不是很专业的样子,不过流程差不多是这样的,重点关注一下虚拟环境搭建完之后,在终端选择配置的操作,就是一堆yes no,的选项,跟着视频来就行了。
1.1 git clone 项目
本地找个训练环境存放的文件夹,利用git工具拉取训练webui环境
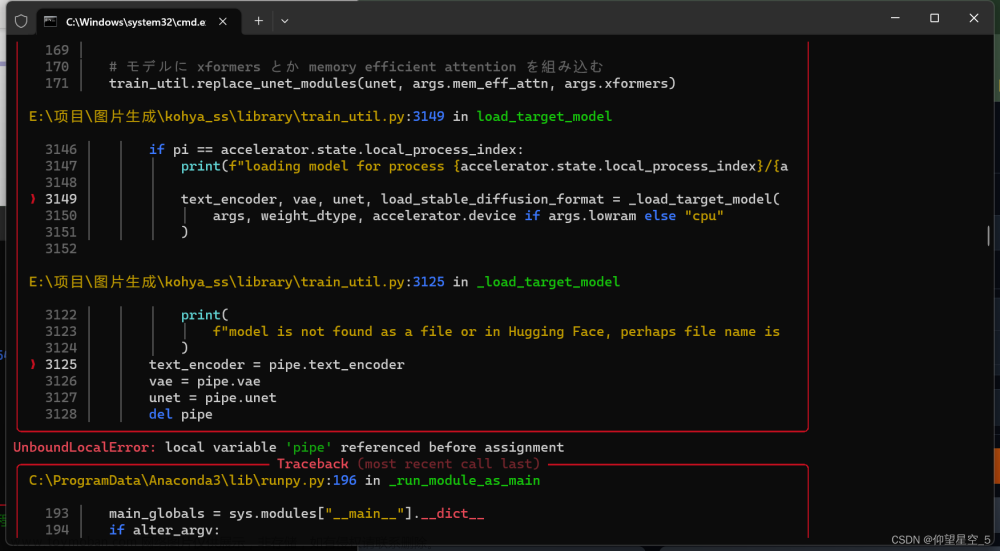
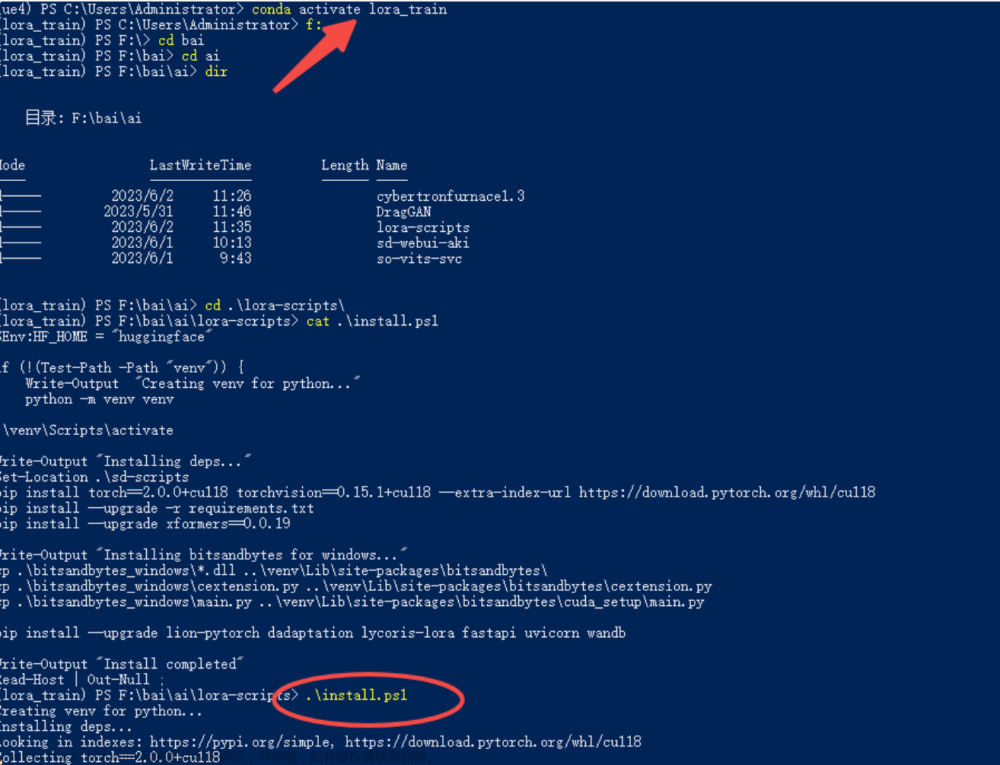
git clone https://github.com/bmaltais/kohya_ss.git拉取后会有这样的目录,执行红框内的setup.bat文件就能安装训练的虚拟环境了(和之前搭建的SD框架虚拟环境类似,但是安装的python库版本会有所出入,如果不想有版本冲突的话,建议直接在这里就不需要操作任何配置了)

1.2 cuda加速安装
项目网站上有安装的教程,用于加速训练过程的,支持30和40系显卡
1.3 打开训练的webui
和打开SD webui类似,直接点击这个目录下的gui.bat文件,看到url网址出现就能打开网站了。

2 图片的预处理
简单来说训练过程中需要图像和对应的图像描述,类似于其他机器学习中的数据和标签。在stable diffusion的webui里可以找到图像预处理模块。输入到lora训练网络中的数据集应该长这样:
结果展示

2.1 裁剪
因为本文一开头搜集到的图像分辨率不一样,训练过程中最好使用同一的分辨率,这里可以通过剪裁网站批量处理人物图像。这里推荐使用512*512的分辨率。这个网站还能同一重命名图片,有强迫症的人很支持。
2.2 利用stable diffusion webui预处理
 在ui的这个界面输入刚刚批量裁剪完的图像,和输出的目录。就能得到以下21张512*512并且带有描述文本的训练集了。
在ui的这个界面输入刚刚批量裁剪完的图像,和输出的目录。就能得到以下21张512*512并且带有描述文本的训练集了。

……这里坤坤的被预处理自动标记为1girl了,大家可以手动修改一下这个标签,然后检查其他的描述是否存在不合理的情况,酌情删除和增加即可。
3 模型的训练和使用
3.1 文件路径安排
回到lora训练的webui上,在dreambooth LoRA栏目下添加源模型,因为本次训练的是真实人物模型,笔者就选择了这个比较合适的大模型。
子栏目Folders按照这个格式放置刚刚处理的图片,这里的文件命名只需要注意10_cxk,前面的数字,是每次训练过程中网络训练单张图片的次数。其余的路径名大家可以自定义。
子栏目training parameter就是训练过程中需要炼丹的参数,大家根据自己电脑的配置来修改,数据量大的,显存足够的情况下,batchsize可以调高。学习率和epoch次数都是比较常见的修改参数。这里用了8个epoch去训练,每次epoch结束后都会保存当前的Lora模型。结果是这样的:

大家可以根据训练的loss值来选择计算机认为较好的结果,当然loss越小拟合得越好,太小则会过拟合,泛化性能不足。
3.2 lora模型挑选
刚刚一共训练了八个cxk_lora模型,但看loss值不好挑选最佳的模型,这里回到stable diffusion webui里,利用脚本来观察那个lora模型比较好。
3.2.1 插件安装

需要安装红框里的插件,才能利用脚本一次性使用多个lora进行对比,当然,大家可以不用插件,一个一个去生成,但是就是会比较麻烦,有插件就方便一些。

3.2.2 比较模型
把刚刚整完的lora模型放到这个插件的model/lora目录下,就能在界面看到这样的效果。记得大模型要选择你训练的时候的基底模型。附加网络随机选取,这个插件不用选择开启。但是网络类型和模型是需要选取的,为的是让后面的脚本能识别你要进行对比的lora模型。

脚本里这样设置,选择XYZ 绘图脚本
X轴类型选择刚刚插件内的额外网络模型(也就是你的Lora模型)
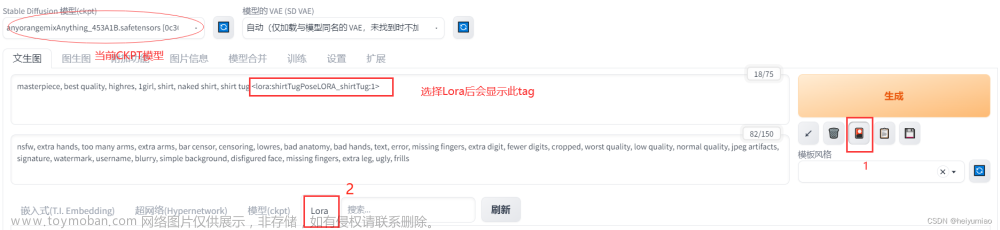
Y轴选择这个模型需要运用的程度,等价于prompt语法中的<lora:cxk_model_xxx:0.5>,因为有些情况下,会出现模型的过拟合,若是应用占比过大,反而效果不好。
出图结果:
可以看到拉,cxk_lora-7这个模型配合上0.9左右的占比,实现的效果比较好。
3.3 lora应用
选择刚刚合适的模型,放入到这个目录下(其实应该可以修改代码,这样就不用复制来复制去了。。还占用空间,不过fine拉,看代码也是个很长的过程)
然后就能在stable diffusion webui里愉快地出图啦~

这里的插件和脚本都不需要开启了。记得关闭。
相关链接
训练工程——kohya_ss文章来源:https://www.toymoban.com/news/detail-411446.html
剪裁工具——photosoft文章来源地址https://www.toymoban.com/news/detail-411446.html
到了这里,关于stable diffusion(Lora的训练)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!