准备工作
三台虚拟机,关闭防火墙,关闭selinux
查看防火状态 systemctl status firewalld
暂时关闭防火墙 systemctl stop firewalld
永久关闭防火墙 systemctl disable firewalld
查看 selinux状态 getenforce
暂时关闭 selinux setenforce 0
永久关闭 selinux 在/etc/selinux/config文件中将SELINUX改为disabled
修改主机名:hostnamectl set-hostname 主机名称
修改映射文件/etc/hosts 使得三台主机可以互ping

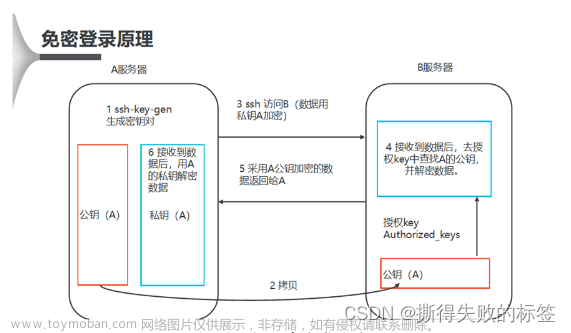
配置ssh免密登录
文章来源地址https://www.toymoban.com/news/detail-411654.html

ssh-copy-id hadoop01 将公钥复制到需要远程连接的机器上
注意:也需要分发给自己,否则启动hadoop进程的时候会要求输入密码

解压jdk与hadoop压缩包 解压到/usr/local/src/目录下


配置jdk与Hadoop环境变量
在/etc/profile文件中修改配置文件

修改Hadoop配置文件
hadoop-env.sh yarn-env.sh mapred-env.sh

配置HDFS相关文件
<configuration> <property> <!-- 指定HDFS中NameNode的地址 --> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <!-- 指定Hadoop运行时产生文件的存储目录 --> <name>hadoop.tmp.dir</name> <value>/usr/local/src/hadoop/data/tmp</value> </property> </configuration>
<configuration> <property> <name>dfs.replication</name> <value>4</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/usr/local/src/hadoop/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/usr/local/src/hadoop/data</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>slave2:50090</value> </property> </configuration>
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn-resourcemanager.hostname</name> <value>slave1</value> </property> </configuration>
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
配置slave文件 写入其他主机名称

全部配置完之后分发给其他集群

scp命令说明
-r是传输文件夹,如果只是传输文件,可以不需要加-r
root是传输给root用户,如果要传输给其他用户也可以修改为其他用户的名称
@后面加主机名 hadoop02是主机名
:后面加传输的目录下
格式化NameNode
[hadoop@hadoop01 hadoop-2.7.2]$ bin/hdfs namenode -format
启动HDFS
[hadoop@hadoop01 hadoop-2.7.2]$ sbin/start-dfs.sh [hadoop@hadoop01 hadoop-2.7.2]$ jps
启动Yarn
在Resourcemanager节点启动
[hadoop@hadoop02 hadoop-2.7.2]$ sbin/start-yarn.sh [hadoop@hadoop02 hadoop-2.7.2]$ jps
| hadoop01 192.168.112.101 | hadoop02 192.168.112.102 | hadoop03 192.168.112.103 | |
|---|---|---|---|
| HDFS |
NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
| YARN | NodeManager |
ResourceManager NodeManager |
启动HDFS:start-dfs.sh
启动Yarn:start-yarn.sh
关闭HDFS:stop-dfs.sh
关闭Yarn:stop-yarn.sh
最终全部启动


 文章来源:https://www.toymoban.com/news/detail-411654.html
文章来源:https://www.toymoban.com/news/detail-411654.html
到了这里,关于hadoop完全分布式的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!