前置知识
搜索引擎的核心功能,就是查找到一组和用户输入的词/一句话 相关联的网页
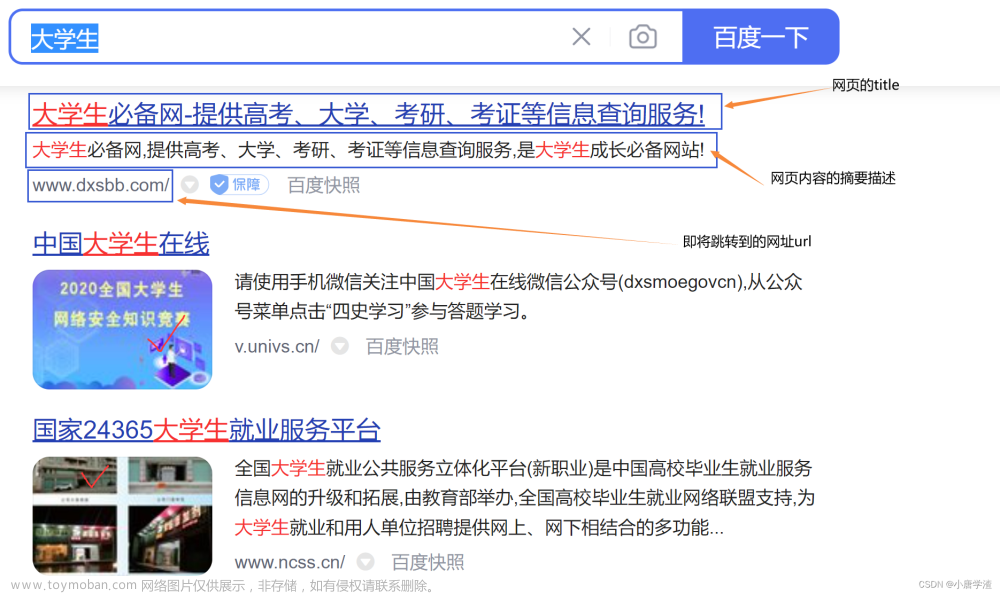
关键字:搜索词;搜索结果的标题,搜索结果的描述,展示URL,跳转过去的目标页面,称为“落地页”;
对于一个搜索引擎来说,首先,需要获取到很多很多的网页;然后再根据用户输入的查询词,在这些网页中进行查找。
1.搜索引擎的网页是怎么获取到的?
此处主要是涉及到“爬虫”这样的程序(Http客户端)
2.用户输入了查询词之后,如何去让查询词和当前的这些网页进行匹配?
假设当前已经爬取到了一亿个网页,用户输入了一个"蛋糕"这样的查询词。这样的暴力搜索,是非常低效的,而搜索引擎需要能够让用户非常高效的获取到结果。
这时候就需要一种特殊的数据结构,倒排索引。
倒排索引
先介绍几个概念
- 文档(document):指的是每个待搜索的网页
- 正排索引:指的是 文档id => 文档内容
- 倒排索引:指的是 词 => 文档id列表
举个例子
正排索引:
文档 id 为1的内容为 : 我要出去实习挣钱
文档 id 为2的内容为:我要发论文顺利毕业
倒排索引:
我要 1,2
出去 1
发论文 2
实习 1
顺利 2
挣钱 1
毕业 2
项目目标:实现一个针对Java文档的搜索引擎
获取Java8官方文档下载地址
在本地基于离线文档来制作索引。实现搜索,当用户在搜索结果页点击具体的搜索结果的时候,就自动跳转到在线文档的页面。
模块划分
-
索引模块
①扫描下载到的文档,分析文档的内容,构建出正排索引+倒排索引。并且把索引内容保存到文件中
②加载制作好的索引,并提供一些API实现查正排和查倒排这样的功能 -
搜索模块
调用索引模块,实现一个搜索的完整过程
输入:用户的查询词
输出:完整的搜索结果(包含了很多条记录,每个记录都有标题,描述,展示URL,并且点击能够跳转) -
web模块
需要实现一个简答的web程序,能够通过网页的形式来和用户进行交互
包含了后端和前端
创建 Maven 项目
针对用户输入的内容 进行分词
分词的原理
-
基于词库
尝试把所有的 “词” 都进行穷举,把这些穷举结果放到词典文件中
然后就可以依次的取句子中的内容。每隔一个字,在词典里查一下;每隔两个字,查一下。 -
基于统计
收集到很多很多的“语料库” => 人工标注=>也就知道了那些字在一起的概率比较大
使用现成的第三方库 ansj 来实现分词。
import org.ansj.domain.Term;
import org.ansj.splitWord.analysis.ToAnalysis;
import java.util.List;
public class TestAnsj {
public static void main(String[] args) {
String str = "我要赶快做好简历,准备实习,先出去实习再说";
// ToAnalysis.parse(str) 返回的是 Result 类型
List<Term> terms = ToAnalysis.parse(str).getTerms();
// Term 就表示一个分词结果
for (Term term : terms) {
System.out.println(term.getName());
}
}
}
代码运行的警告是因为没有配置字典。
Parser 类(根据文档路径 读取文件,构建索引 并 保存到指定文件中)
解析出 HTML 对应的 URL 说明
Java API 文档有两份:
- 线上文档
- 线下文档(下载到本地的文档)
线上: https://docs.oracle.com/javase/8/docs/api/java/util/ArrayList.html
线下:D:\Java\javaDocument\docs\api\java\util\ArrayList.html
期望达到的结果是,用户点击搜索结果,能够跳转到对应的线上文档的页面。
以 https://docs.oracle.com/javase/8/docs/api/ 为固定前缀。
将本地文档的后半部分 java\util\ArrayList.html 提出出来与固定前缀进行拼接。
倒排索引
倒排索引,词 => 文档 id 之间的映射关系
首先就需要先知道当前这个文档,里面都有那些词
因此就需要针对当前文档也进行分词
- 针对标题
- 针对正文
因此就可以先针对当前文档进行分词,然后根据每个分词结果;去倒排索引中,找到对应的 value,然后把当前文档 id 给加入到对应的 value列表中即可。
如何来确定权重的值?
这个值描述了 词 和 文档 之间的“相关性”
此处单纯的通过 词 出现的次数,来表示相关性。
权重计算公式:标题中出现的次数+10 + 正文中出现的次数
保存索引结构到磁盘中
索引当前是存储在 内存 中的。构建索引的过程是比较耗时的。
需要把内存中的索引结构,变成一个“字符串”,然后写文件即可。
对应的,把特定结构的字符串,反向解析成一些结构化数据(类/对象/基础数据结构) (反序列化)
通过 json库 来实现序列化和反序列化。ObjectMapper对象
objectMapper.readValue(forwardIndexFile, new TypeReference<ArrayList<DocInfo>>() {});
objectMapper.readValue(invertedIndexFile,new TypeReference<HashMap<String,ArrayList<Weight>>>() {});
创建一个匿名内部类,这个类实现了 TypeReference.同时再创建一个这个匿名内部类的实例。创建这个实例最主要的目的,就是为了把 ArrayList 这个类型信息,告诉 readValue 方法。
关于 Parser 和 Index 之间的关系
Parser 相当于制作索引的入口 => 对应到一个 “可执行” 程序
Index 相当于实现了索引的数据结构,提供了一些 api
Index 类就要给 Parser 进行调用,才能完成整个制作索引的功能
性能优化

通过测试,发现当前主要的性能瓶颈,在循环便利文件上。
每次循环都要针对一个文件进行解析。读文件+分词+解析内容(主要还是卡在CPU运算上)
单个线程的情况,任务都是串行执行的。
多个线程,这些任务就可以并发执行.
线程池之保证所有文档处理完毕再保存索引
CountDownLatch 类似于跑步比赛的裁判
只有所有的选手都撞线,就认为这场比赛就结束了
给制作索引代码加锁
如果直接把 synchronized 加到 parseHTML 或者 addDoc 这样的方法上,是不科学的,这样做锁的粒度太粗了,并发程度不高,提高的效率有限。因此要把枷锁的粒度搞细一点。

解决进程不退出的问题
关于守护线程
如果要是一个线程是守护线程(后台线程),此时这个线程的运行状态,不会影响到进程结束。
如果要是一个线程不是守护线程,这个线程的运行状态,就会影响到进程结束。
前面学过的线程创建的手段,默认创建出来的都是非守护线程,需要通过 setDaemon 方法手动设置,才能成为守护线程。
通过线程池创建的线程,并不是守护线程。
当main方法执行完了,这些线程仍然在工作(仍然在等待新任务的到来)
开机之后,首次制作索引特别慢的问题
是由于缓存,parseContent的核心操作,就是读取文件。从磁盘进行访问,操作系统就会对“经常读取的文件”进行缓存。
首次运行的时候,当前的这些Java文档,都没有在内存中缓存。因此读取的时候只能从硬盘上读取。
后面再运行的时候,由于前面已经读取过这些文档了,这些文档在操作系统中其实已经有了一份缓存(在内存中),这次的读取不必直接读硬盘,而是直接读内存的缓存(速度就会快很多)
正则表达式
正则里面主要就是有很多特殊符号
. 表示匹配一个非换行字符(不是 \n 或者不是 \r )
* 表示前面的字符可以出现若干次
.* 匹配非换行字符出现若干次
去除script标签和内容
<script.*?>(.*?)</script>
去除 普通 的标签(不去掉内容)
<.*? > 既能匹配到开始标签,也能匹配到结束标签
? 表示“非贪婪匹配”,匹配到一个符合条件的最短结果
不带?的.* 表示“贪婪匹配” 匹配到一个符合条件的最长结果
约定前后端交互接口
此处只需要实现一个搜索接口即可。
请求:
GET /searcher?query=[查询词] HTTP/1.1
相应:
HTTP/1.1 200 OK
[
{
title:“这是标题1”,
url:“这是url1”,
desc:“这是描述1”,
}
]
实现标红逻辑
- 修改后端的代码。生成搜索结果的时候(生成描述),就需要把其中包含查询词的部分,给加上一个标记。
例如,给这个部分套上一层<i>标签 - 然后在前端这里针对<i>标签设置样式,然后浏览器就可以根据<i>标签的样式来进行显示了。

处理停用词
网上搜到的停用词表,接下来可以让搜索程序加载这个停用词表到内存中。使用一个HashSet把这些词都存起来。
再针对分词结果,在停用词表中进行筛选。
如果某个结果在词表中存在,就直接干掉。
一个文档包含多个查询词,进行权重相加
要想实现这样的效果,就需要把触发结果进行合并。
需要把多个分词结果触发出的文档,按照 docId进行去重,同时进行权重的合并。
去重的核心思路:
数据结构阶段,链表~合并两个有序链表
此处按照类似的思路来合并两个数组
先把分词结果进行一个排序处理(按照 docId 升序排序)
再进行合并,合并的时候就可以根据 docId 值相同的情况,做权重相加。
注意!当前的分词结果,不一定就只是分成两个部分,很可能是多个部分,此时就变成了N个数组合并了。
多路归并
对于两路数组归并,核心就是对比指向两个数组元素的值的大小关系,找到小的,插入到结果中
对于多路数组归并,核心思路仍然是对比多个数组的值的大小关系,找到小的,插入到结果中文章来源:https://www.toymoban.com/news/detail-411806.html
使用 堆(小堆)/优先级队列(√)文章来源地址https://www.toymoban.com/news/detail-411806.html
到了这里,关于Java项目之搜索引擎的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!