目录
1.channel底层数据结构是什么
2.channel创建的底层实现
3.channel 的发送过程
4.channel的接受过程
5.关闭 channel
1.channel底层数据结构是什么
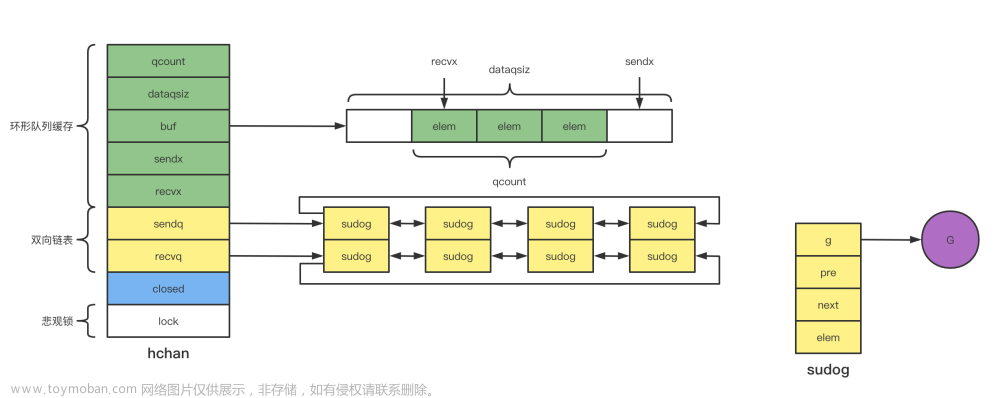
channel底层的数据结构是hchan,包括一个循环链表和2个双向链表
type hchan struct {
qcount uint // total data in the queue
dataqsiz uint // size of the circular queue
buf unsafe.Pointer // points to an array of dataqsiz elements
elemsize uint16
closed uint32
elemtype *_type // element type
sendx uint // send index
recvx uint // receive index
recvq waitq // list of recv waiters
sendq waitq // list of send waiters
// lock protects all fields in hchan, as well as several
// fields in sudogs blocked on this channel.
//
// Do not change another G's status while holding this lock
// (in particular, do not ready a G), as this can deadlock
// with stack shrinking.
lock mutex
}buf:循环链表
sendx:循环链表中已发送的位置
recvx: 循环链表中已接受的位置
qcount:环形队列的实际大小
dataqsiz:环形队列的容量
elemsize:环列队列中元素的大小
elemtype:环形队列中元素的类型
closed:环形队列是否关闭
recvq:等待接收groutinue链表
sendq:等待发送send groutinue链表
lock:悲观锁
结构图如下所示
2.channel创建的底层实现
创建channel底层调用的是makechan,为新创建的channel分配内存空间,分为下面的三种情况:
- 不带缓冲区:只需要给hchan分配内存空间。
- 带缓冲区且不包括指针类型:同时给hchan和环形队列缓存buf分配一段连续的内存空间。
- 带缓冲区且包括指针类型:分别给hchan和环形队列缓存buf分配不同的内存空间。
源码如下:
func makechan64(t *chantype, size int64) *hchan {
if int64(int(size)) != size {
panic(plainError("makechan: size out of range"))
}
return makechan(t, int(size))
}
func makechan(t *chantype, size int) *hchan {
elem := t.elem
// compiler checks this but be safe.
if elem.size >= 1<<16 {
throw("makechan: invalid channel element type")
}
if hchanSize%maxAlign != 0 || elem.align > maxAlign {
throw("makechan: bad alignment")
}
mem, overflow := math.MulUintptr(elem.size, uintptr(size))
if overflow || mem > maxAlloc-hchanSize || size < 0 {
panic(plainError("makechan: size out of range"))
}
// Hchan does not contain pointers interesting for GC when elements stored in buf do not contain pointers.
// buf points into the same allocation, elemtype is persistent.
// SudoG's are referenced from their owning thread so they can't be collected.
// TODO(dvyukov,rlh): Rethink when collector can move allocated objects.
var c *hchan
switch {
case mem == 0:
// Queue or element size is zero.
c = (*hchan)(mallocgc(hchanSize, nil, true))
// Race detector uses this location for synchronization.
c.buf = c.raceaddr()
case elem.ptrdata == 0:
// Elements do not contain pointers.
// Allocate hchan and buf in one call.
c = (*hchan)(mallocgc(hchanSize+mem, nil, true))
c.buf = add(unsafe.Pointer(c), hchanSize)
default:
// Elements contain pointers.
c = new(hchan)
c.buf = mallocgc(mem, elem, true)
}
c.elemsize = uint16(elem.size)
c.elemtype = elem
c.dataqsiz = uint(size)
lockInit(&c.lock, lockRankHchan)
if debugChan {
print("makechan: chan=", c, "; elemsize=", elem.size, "; dataqsiz=", size, "\n")
}
return c
}3.channel 的发送过程
channel send 发送底层调用的是chansend1函数
channel发送的过程
1.检查 recvq 双向链表 是否为空,如果不为空,说明recvq缓存队列不为空,buffer为空,有大量的recvq在等待,则从 recvq 头部取一个 goroutine,将数据发送过去,并唤醒对应的 goroutine 即可。
2.如果 recvq 为空,代表buffer可能有存储空间,则将数据放入到 buffer 中。
3.如果 buffer 已满,则将要发送的数据和当前 goroutine 打包成 sudog 对象放入到 sendq 中。并将当前 goroutine 置为 waiting 状态。
源码如下
func chansend1(c *hchan, elem unsafe.Pointer) {
chansend(c, elem, true, getcallerpc())
}
/*
* generic single channel send/recv
* If block is not nil,
* then the protocol will not
* sleep but return if it could
* not complete.
*
* sleep can wake up with g.param == nil
* when a channel involved in the sleep has
* been closed. it is easiest to loop and re-run
* the operation; we'll see that it's now closed.
*/
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
if c == nil {
if !block {
return false
}
gopark(nil, nil, waitReasonChanSendNilChan, traceEvGoStop, 2)
throw("unreachable")
}
if debugChan {
print("chansend: chan=", c, "\n")
}
if raceenabled {
racereadpc(c.raceaddr(), callerpc, funcPC(chansend))
}
// Fast path: check for failed non-blocking operation without acquiring the lock.
//
// After observing that the channel is not closed, we observe that the channel is
// not ready for sending. Each of these observations is a single word-sized read
// (first c.closed and second full()).
// Because a closed channel cannot transition from 'ready for sending' to
// 'not ready for sending', even if the channel is closed between the two observations,
// they imply a moment between the two when the channel was both not yet closed
// and not ready for sending. We behave as if we observed the channel at that moment,
// and report that the send cannot proceed.
//
// It is okay if the reads are reordered here: if we observe that the channel is not
// ready for sending and then observe that it is not closed, that implies that the
// channel wasn't closed during the first observation. However, nothing here
// guarantees forward progress. We rely on the side effects of lock release in
// chanrecv() and closechan() to update this thread's view of c.closed and full().
if !block && c.closed == 0 && full(c) {
return false
}
var t0 int64
if blockprofilerate > 0 {
t0 = cputicks()
}
lock(&c.lock)
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("send on closed channel"))
}
//recvq不为空
if sg := c.recvq.dequeue(); sg != nil {
// Found a waiting receiver. We pass the value we want to send
// directly to the receiver, bypassing the channel buffer (if any).
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true
}
//
if c.qcount < c.dataqsiz {
// Space is available in the channel buffer. Enqueue the element to send.
qp := chanbuf(c, c.sendx)
if raceenabled {
racenotify(c, c.sendx, nil)
}
typedmemmove(c.elemtype, qp, ep)
c.sendx++
if c.sendx == c.dataqsiz {
c.sendx = 0
}
c.qcount++
unlock(&c.lock)
return true
}
if !block {
unlock(&c.lock)
return false
}
// Block on the channel. Some receiver will complete our operation for us.
gp := getg()
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
// No stack splits between assigning elem and enqueuing mysg
// on gp.waiting where copystack can find it.
mysg.elem = ep
mysg.waitlink = nil
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.waiting = mysg
gp.param = nil
c.sendq.enqueue(mysg)
// Signal to anyone trying to shrink our stack that we're about
// to park on a channel. The window between when this G's status
// changes and when we set gp.activeStackChans is not safe for
// stack shrinking.
atomic.Store8(&gp.parkingOnChan, 1)
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanSend, traceEvGoBlockSend, 2)
// Ensure the value being sent is kept alive until the
// receiver copies it out. The sudog has a pointer to the
// stack object, but sudogs aren't considered as roots of the
// stack tracer.
KeepAlive(ep)
// someone woke us up.
if mysg != gp.waiting {
throw("G waiting list is corrupted")
}
gp.waiting = nil
gp.activeStackChans = false
closed := !mysg.success
gp.param = nil
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
mysg.c = nil
releaseSudog(mysg)
if closed {
if c.closed == 0 {
throw("chansend: spurious wakeup")
}
panic(plainError("send on closed channel"))
}
return true
}4.channel的接受过程
channel底层调用的是chanrecv、chanrecv1、chanrecv2,chanrecv1和chanrecv2底层都调用的是chanrecv。chanrecv1和chanrecv2区别有没有接受数据成功的bool类型
chanrecv1(c *hchan, elem unsafe.Pointer)
chanrecv2(c *hchan, elem unsafe.Pointer) (received bool)receiver过程分为4种情况
1.从sendq队列头部取一个元素,如果元素不为空,环形队列缓存区已满,说明buffer已满,大量的send goroutine在发送数据,阻塞了,rece从循环队列读取一个元素,,把goroutinue元素放在循环队列中,从sendq队列中唤醒goroutinue。
2.从sendq队列头部取一个元素,如果元素不为空,环形队列为空,并把goroutine中元素copy到receiver中,从sendq队列中唤醒一个goroutine,
3.sendq队列为空,buffer没有满,从buffer中获取一个元素,recex+1
4.sendq对列为空,buffer为空,rece的goroutinue包装成sudog,放在receq队列中。
channel recv的底层源码如下
// entry points for <- c from compiled code
//go:nosplit
func chanrecv1(c *hchan, elem unsafe.Pointer) {
chanrecv(c, elem, true)
}
//go:nosplit
func chanrecv2(c *hchan, elem unsafe.Pointer) (received bool) {
_, received = chanrecv(c, elem, true)
return
}
// chanrecv receives on channel c and writes the received data to ep.
// ep may be nil, in which case received data is ignored.
// If block == false and no elements are available, returns (false, false).
// Otherwise, if c is closed, zeros *ep and returns (true, false).
// Otherwise, fills in *ep with an element and returns (true, true).
// A non-nil ep must point to the heap or the caller's stack.
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
// raceenabled: don't need to check ep, as it is always on the stack
// or is new memory allocated by reflect.
if debugChan {
print("chanrecv: chan=", c, "\n")
}
if c == nil {
if !block {
return
}
gopark(nil, nil, waitReasonChanReceiveNilChan, traceEvGoStop, 2)
throw("unreachable")
}
// Fast path: check for failed non-blocking operation without acquiring the lock.
if !block && empty(c) {
// After observing that the channel is not ready for receiving, we observe whether the
// channel is closed.
//
// Reordering of these checks could lead to incorrect behavior when racing with a close.
// For example, if the channel was open and not empty, was closed, and then drained,
// reordered reads could incorrectly indicate "open and empty". To prevent reordering,
// we use atomic loads for both checks, and rely on emptying and closing to happen in
// separate critical sections under the same lock. This assumption fails when closing
// an unbuffered channel with a blocked send, but that is an error condition anyway.
if atomic.Load(&c.closed) == 0 {
// Because a channel cannot be reopened, the later observation of the channel
// being not closed implies that it was also not closed at the moment of the
// first observation. We behave as if we observed the channel at that moment
// and report that the receive cannot proceed.
return
}
// The channel is irreversibly closed. Re-check whether the channel has any pending data
// to receive, which could have arrived between the empty and closed checks above.
// Sequential consistency is also required here, when racing with such a send.
if empty(c) {
// The channel is irreversibly closed and empty.
if raceenabled {
raceacquire(c.raceaddr())
}
if ep != nil {
typedmemclr(c.elemtype, ep)
}
return true, false
}
}
var t0 int64
if blockprofilerate > 0 {
t0 = cputicks()
}
lock(&c.lock)
if c.closed != 0 && c.qcount == 0 {
if raceenabled {
raceacquire(c.raceaddr())
}
unlock(&c.lock)
if ep != nil {
typedmemclr(c.elemtype, ep)
}
return true, false
}
if sg := c.sendq.dequeue(); sg != nil {
// Found a waiting sender. If buffer is size 0, receive value
// directly from sender. Otherwise, receive from head of queue
// and add sender's value to the tail of the queue (both map to
// the same buffer slot because the queue is full).
recv(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true, true
}
if c.qcount > 0 {
// Receive directly from queue
qp := chanbuf(c, c.recvx)
if raceenabled {
racenotify(c, c.recvx, nil)
}
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
typedmemclr(c.elemtype, qp)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.qcount--
unlock(&c.lock)
return true, true
}
if !block {
unlock(&c.lock)
return false, false
}
// no sender available: block on this channel.
gp := getg()
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
// No stack splits between assigning elem and enqueuing mysg
// on gp.waiting where copystack can find it.
mysg.elem = ep
mysg.waitlink = nil
gp.waiting = mysg
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.param = nil
c.recvq.enqueue(mysg)
// Signal to anyone trying to shrink our stack that we're about
// to park on a channel. The window between when this G's status
// changes and when we set gp.activeStackChans is not safe for
// stack shrinking.
atomic.Store8(&gp.parkingOnChan, 1)
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanReceive, traceEvGoBlockRecv, 2)
// someone woke us up
if mysg != gp.waiting {
throw("G waiting list is corrupted")
}
gp.waiting = nil
gp.activeStackChans = false
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
success := mysg.success
gp.param = nil
mysg.c = nil
releaseSudog(mysg)
return true, success
}5.关闭 channel
关闭channel底层源码调用的是closechan
除此之外,关闭channel,出现panic的场景如下:文章来源:https://www.toymoban.com/news/detail-412306.html
- 关闭值为nil的channel
- 关闭已经被关闭的channel
- 向已经关闭的channel写数据
关闭channel的源码如下文章来源地址https://www.toymoban.com/news/detail-412306.html
func closechan(c *hchan) {
if c == nil {
panic(plainError("close of nil channel"))
}
lock(&c.lock)
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("close of closed channel"))
}
if raceenabled {
callerpc := getcallerpc()
racewritepc(c.raceaddr(), callerpc, funcPC(closechan))
racerelease(c.raceaddr())
}
c.closed = 1
var glist gList
// release all readers
for {
sg := c.recvq.dequeue()
if sg == nil {
break
}
if sg.elem != nil {
typedmemclr(c.elemtype, sg.elem)
sg.elem = nil
}
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
gp := sg.g
gp.param = unsafe.Pointer(sg)
sg.success = false
if raceenabled {
raceacquireg(gp, c.raceaddr())
}
glist.push(gp)
}
// release all writers (they will panic)
for {
sg := c.sendq.dequeue()
if sg == nil {
break
}
sg.elem = nil
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
gp := sg.g
gp.param = unsafe.Pointer(sg)
sg.success = false
if raceenabled {
raceacquireg(gp, c.raceaddr())
}
glist.push(gp)
}
unlock(&c.lock)
// Ready all Gs now that we've dropped the channel lock.
for !glist.empty() {
gp := glist.pop()
gp.schedlink = 0
goready(gp, 3)
}
}到了这里,关于channel 源码解析(5问)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!











