一、计算机视觉界的里程碑式研究成果 - SAM与SA-1B综述
Segment Anything受chatGPT式的prompt-based思路启发,训练数据集涵盖10亿masks,根据提供的图片注释实时产生不同的mask分割结果,试用效果惊人。
Segment Anything之于Computer Vision,相当于chatGPT之于NLP。
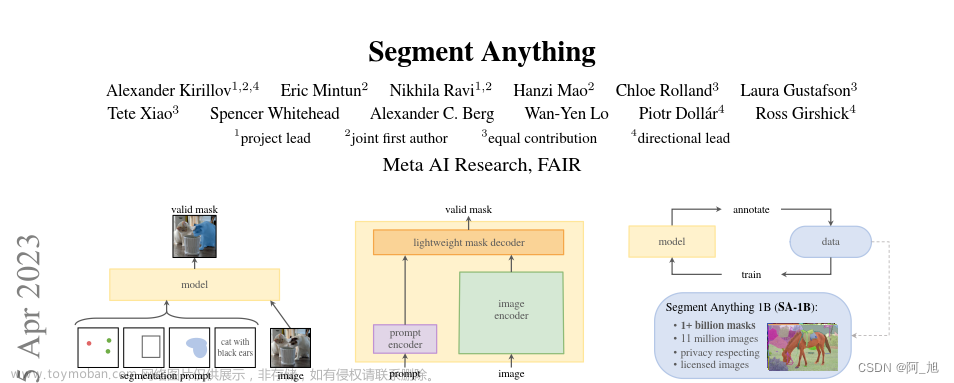
4月5日,Meta AI发布了博客:Introducing Segment Anything: Working toward the first foundation model for image segmentation,译为图像分割领域的第一个基础性模型。
这篇官方博客介绍了Segment Anything Model (SAM) 模型和Segment Anything 1-Billion mask dataset (SA-1B)数据集,从SAM的工作原理、如何构建SA-1B数据集等方面简明扼要地介绍了其工作内容与研究成果,下面我们会对这篇博文及其论文进行探索:
二、Segment Anything项目开发成果综述
1. 项目开发的期望与目标
官方原文:
Reducing the need for task-specific modeling expertise, training compute, and custom data annotation for image segmentation is at the core of the Segment Anything project.
可以大致提取为:
- 降低对特定任务建模专业知识需求
- 减少训练的计算需求
- 减少自定义数据标注的需求
实现目标:建立一个图像分割的基础模型——a promptable model,它在不同种类的数据上进行训练,以适应特定的任务,类似于在自然语言处理模型中使用提示的方式。
笔者注:如同chatGPT的prompt-based learning一样,Segment Anything Model及其模型的发布,犹如GPT之于nlp界一样的概念。
Meta AI团队着手开发一个通用的promptable segment model,使用它来创建一个规模空前的分割数据集。
以前的cv已成传统。
2. SAM:A general promptable model
2.1 何为Prompt?
Prompt是给input加的一段文字或一组向量,让模型根据input和外加的prompt做masked language modeling (MLM)。
2.2 SAM的开发思路
计算机视觉的基本任务就是区别哪些像素属于哪一个对象,也就是常说的分割,目前主要有两种分割的方法与方向:
- 交互式分割,允许分割任何类别的对象,但需要一个人通过迭代细化掩码来指导该方法
- 自动分割,允许分割提前定义的特定对象类别,但需要大量的手动注释对象来训练,连同计算资源和技术专长一起训练分割模型
这两种方法都没有提供通用的、全自动的分割方法。
SAM 是这两类方法的概括。它是一个单一的模型,可以轻松地执行交互式分割和自动分割。该模型的可提示界面(稍后描述)允许以灵活的方式使用它,只需为模型设计正确的提示(点击、框、文本等),就可以完成范围广泛的分割任务。此外,SAM 在包含超过 10 亿个掩码(作为该项目的一部分收集)的多样化、高质量数据集上进行训练,这使其能够泛化到新类型的对象和图像,超出其在训练期间观察到的内容。这种概括能力意味着,总的来说,从业者将不再需要收集他们自己的细分数据并为他们的用例微调模型。
基于prompting技术对零样本、少样本学习的训练思路,Meta AI团队训练 SAM为any prompt返回有效的分割遮罩,
其中prompt可以是前景/背景点、粗框或掩码、自由格式文本,或者一般来说,指示图像中要分割的内容的任何信息。
有效分割遮罩的要求是:即使提示不明确或者可能指代多个对象,输出也应该是一个合理的掩码这些对象之一。此任务用于预训练模型并通过提示解决一般的下游分割任务。
考虑到在Web浏览器实现实时分割和提供prompt并运算反馈,简单的设计在实践中产生良好的结果。图像编码器为图像生成一次性嵌入,而轻量级编码器将任何提示实时转换为嵌入向量。然后将这两个信息源组合在一个预测分割掩码的轻量级解码器中。在计算图像嵌入后,SAM 可以在 50 毫秒内根据网络浏览器中的任何提示生成一个片段。如下图所示:
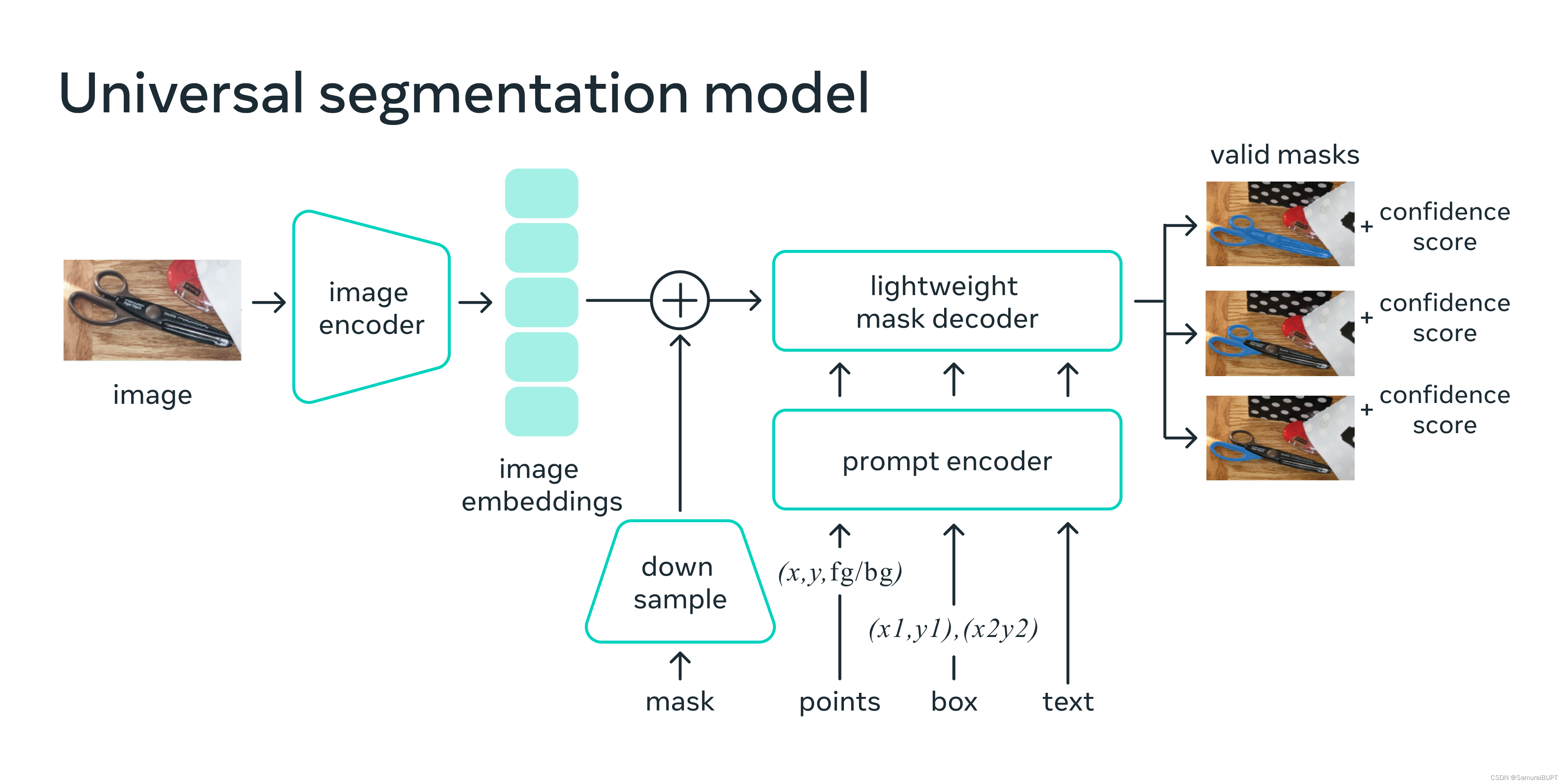
S A M 有效地映射图像特征和一组提示嵌入以生成分割掩码 SAM 有效地映射图像特征和一组提示嵌入以生成分割掩码 SAM有效地映射图像特征和一组提示嵌入以生成分割掩码
图片来源:介绍Segment Anything官方博客
2.3 未来可能的应用场景
S A M 未来可以成为 A R 、 V R 、内容创建、科学领域和更通用 A I 系统的强大组件 SAM未来可以成为 AR、VR、内容创建、科学领域和更通用 AI 系统的强大组件 SAM未来可以成为AR、VR、内容创建、科学领域和更通用AI系统的强大组件
S A M 还有可能在农业领域帮助农民或者协助生物学家进行研究 SAM还有可能在农业领域帮助农民或者协助生物学家进行研究 SAM还有可能在农业领域帮助农民或者协助生物学家进行研究
3. 数据集SA-1B的构建
SAM模型的训练需要大量的数据源,新发布的分割数据集是迄今为止最大的。使用 SAM 收集数据。特别是,标注者使用 SAM 交互式地标注图像,然后使用新标注的数据依次更新 SAM。以此方式多次重复此循环以迭代改进模型和数据集。
使用 SAM,收集新的分割mask比以往任何时候都快。
笔者上传图像进行测试:处理时间的确不到 20 秒 笔者上传图像进行测试:处理时间的确不到20秒 笔者上传图像进行测试:处理时间的确不到20秒
使用该工具,只需大约 14 秒就可以交互式地注释mask。我们的每个掩码注释过程仅比注释边界框慢 2 倍,使用最快的注释接口大约需要 7 秒。与之前的大规模分割数据收集工作相比,该模型比 COCO 全手动基于多边形的mask注释快 6.5 倍,比之前最大的数据注释工作快 2 倍,后者也是模型辅助的。
然而,依靠交互式注释mask并不能充分扩展来创建团队所使用的的 10 亿mask数据集。因此,团队构建了一个数据引擎来创建其 SA-1B 数据集。该数据引擎具有三个“齿轮”。
- 模型协助注释器,上文已提及。
- 第二是全自动标注与辅助标注相结合,有助于增加收集mask的多样性。
- 最后是全自动创建masks,以此来达成扩展训练所使用的数据集。
最终数据集包括在大约 1100 万张许可和隐私保护图像上收集的超过 11 亿个分割masks。SA-1B 的masks总量比任何现有的分割数据集多 400 倍,并且经人工评估研究证实,这些masks具有高质量和多样性,在某些情况下甚至在质量上可与之前更小、完全手动注释的数据集的mask相媲美。
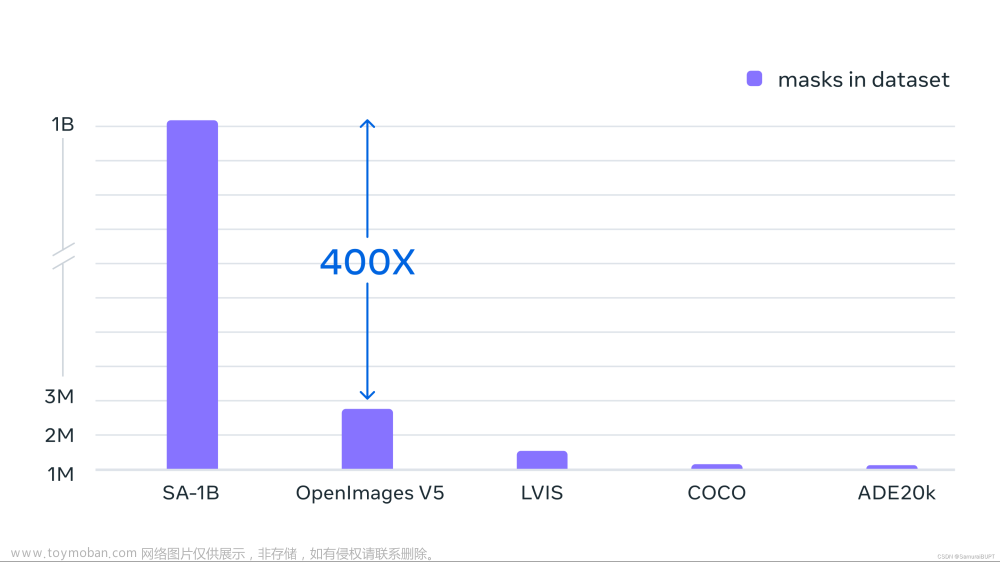
注:Segment Anything对数据引擎收集的数百万张图像和掩码进行训练,结果是一个包含超过 10 亿个分割掩码的数据集——比之前的任何分割数据集大 400 倍。
看到这样的数据集规模,未免让其余开发者望而却步。企业级的AI开发团队正在利用其数据集训练方面的巨大优势,掀起一场又一场变革。
三、Segment Anything网页Demo尝试分割
笔者在Segment Anything官网try demo,传送门在这里,感兴趣的朋友可以一试。
笔者目前正在做医学图像分割方向的开发,以下是我们用自己训练出的网络进行分割的结果:
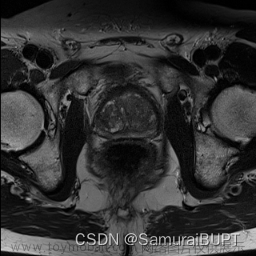
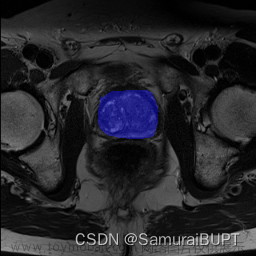
使用 R e s i d u a l U n e t 网络训练的模型进行图像分割 使用Residual Unet网络训练的模型进行图像分割 使用ResidualUnet网络训练的模型进行图像分割
这是使用Segment Anything进行分割的gif动图:
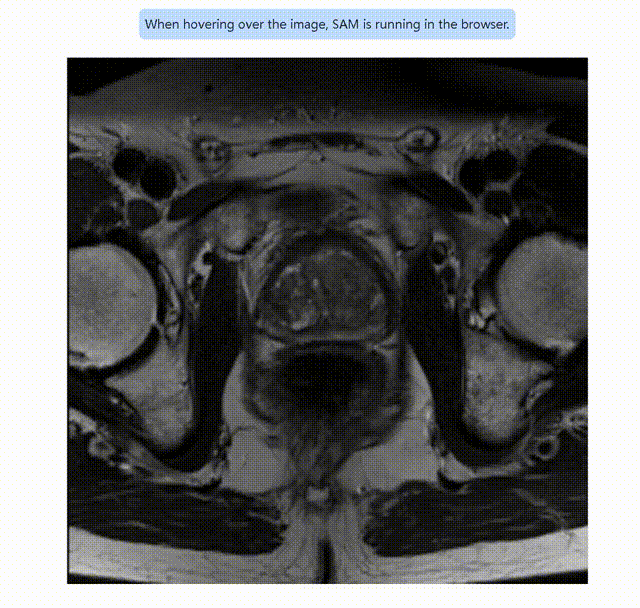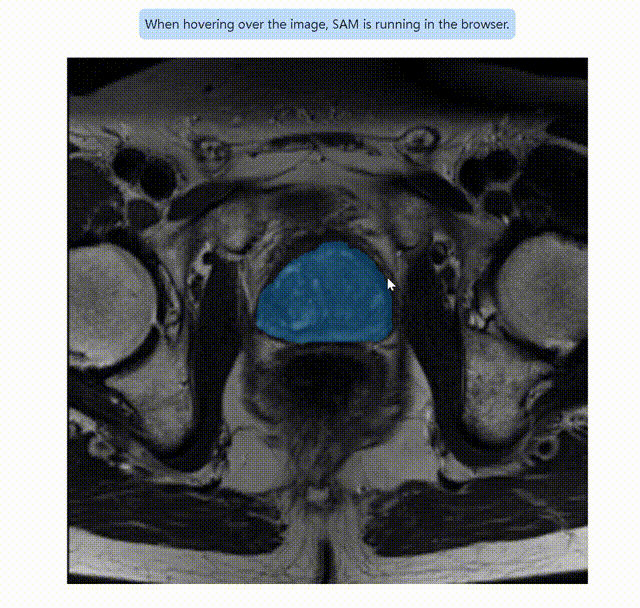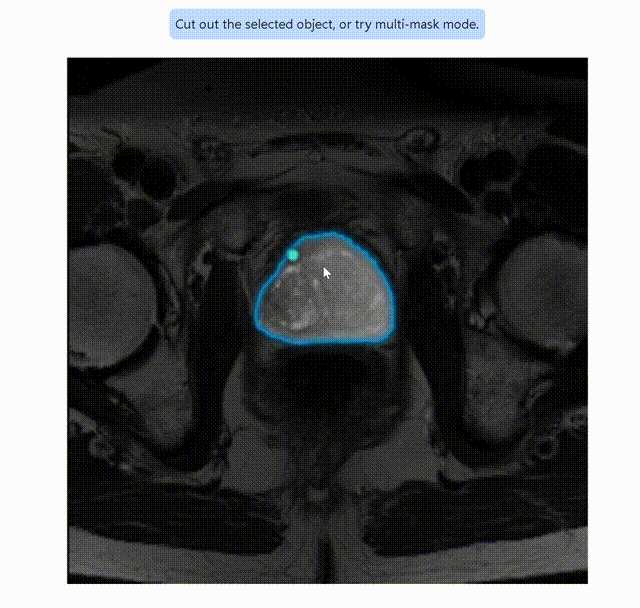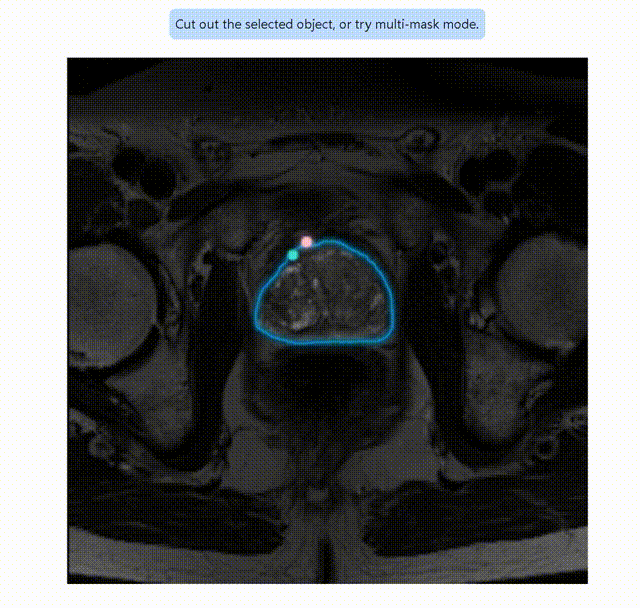
用 S e g m e n t A n y t h i n g 进行图像分割 用Segment Anything进行图像分割 用SegmentAnything进行图像分割
然后可以进行任意的图像分割演示。在前期的演示中,随鼠标移动,会产生不同的mask。鼠标左键是add mask,右键是remove area。在最初没有add mask时,处理结果与我们的训练成果已经相差无几。
笔者仅仅只是提供一个特例,实际上目前Segment Anything在我们数据集的其他图像上的表现,与实际ground truth仍然有较大差异,但是这样的开发思路的优秀以及其给Computer Vision界带来的变革,不可估量。
四、Reference
Introducing Segment Anything: Working toward the first foundation model for image segmentation文章来源:https://www.toymoban.com/news/detail-412624.html
通俗易懂地理解Prompt文章来源地址https://www.toymoban.com/news/detail-412624.html
到了这里,关于Segment Anything CV界的GPT—prompt-based里程碑式研究成果的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!