原文:Hands-On Data Analysis with NumPy and pandas
协议:CC BY-NC-SA 4.0
译者:飞龙
一、配置 Python 数据分析环境
在本章中,我们将介绍以下主题:
- 安装 Anaconda
- 探索 Jupyter 笔记本
- 探索 Jupyter 的替代品
- 管理 Anaconda 包
- 配置数据库
在本章中,我们将讨论如何安装和管理 Anaconda。 Anaconda 是一个包,我们将在本书的以下各章中使用。
什么是 Anaconda?
在本节中,我们将讨论什么是 Anaconda 以及为什么使用它。 我们将提供一个链接,以显示从其赞助商 Continuum Analytics 的网站下载 Anaconda 的位置,并讨论如何安装 Anaconda。 Anaconda 是 Python 和 R 编程语言的开源发行版。
在本书中,我们将专注于 Anaconda 专门用于 Python 的部分。 Anaconda 帮助我们将这些语言用于数据分析应用,包括大规模数据处理,预测分析以及科学和统计计算。 Continuum Analytics 为 Anaconda 提供企业支持,包括可帮助团队协作并提高其系统性能的版本,并提供一种部署使用 Anaconda 开发的模型的方法。 因此,Anaconda 出现在企业环境中,有抱负的分析师应该熟悉它的用法。 Anaconda 附带了本书中使用的许多包,包括 Jupyter,NumPy,pandas 以及其他许多数据分析中常用的包。 仅此一项就可以解释其受欢迎程度。
Anaconda 的安装包括现成的数据分析所需的大部分内容。 Conda 包管理器还可用于下载和安装新包。
为什么要使用 Anaconda? Anaconda 专门为数据分析打包了 Python。 Anaconda 安装中包含了您项目中最重要的包。 除了 Anaconda 提供的一些性能提升,和 Continuum Analytics 对该包的企业支持之外,对于它的流行也不应感到惊讶。
安装 Anaconda
您可以从 Continuum Analytics 网站免费下载 Anaconda。 下载主页面在这里; 否则,很容易找到。 确保选择适合您系统的安装程序。 显然,选择适合您的操作系统的安装程序,但也要注意 Anaconda 具有 32 位和 64 位版本。 64 位版本为 64 位系统提供最佳性能。
Python 社区正处于从 Python 2.7 到 Python 3.6 的缓慢过渡中,这不是完全向后兼容的。 如果您需要使用 Python 2.7,可能是由于遗留代码或尚未更新为与 Python 3.6 兼容的包,请选择 Anaconda 的 Python 2.7 版本。 否则,我们将使用 Python 3.6。
以下屏幕截图来自 Anaconda 网站,分析人员可从该网站下载 Anaconda:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-caS2nj30-1681367023138)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/afb01afe-769c-4084-8aa3-98d8a13b528f.png)]
Anaconda website
如您所见,我们可以选择适用于操作系统(包括 Windows,macOS 和 Linux),处理器和 Python 版本的 Anaconda 安装。 导航到正确的操作系统和处理器,然后在 Python 2.7 和 Python 3.6 之间进行选择。
在这里,我们将使用 Python 3.6。 在 Windows 和 macOS 上进行安装最终等同于使用安装向导,该安装向导通常会为您的系统选择最佳选项,尽管它确实允许某些选项根据您的首选项而有所不同。
Linux 安装必须通过命令行完成,但是对于那些熟悉 Linux 安装的人来说,它应该不会太复杂。 最终,这相当于运行 Bash 脚本。 在本书中,我们将使用 Windows。
探索 Jupyter 笔记本
在本节中,我们将探索 Jupyter 笔记本,这是我们将使用 Python 进行数据分析的主要工具。 我们将看到什么是 Jupyter 笔记本,还将讨论 Markdown,这是我们在 Jupyter 笔记本中用于创建格式化文本的工具。 在 Jupyter 笔记本中,有两种类型的块。 有一些可执行的 Python 代码块,然后是带格式的,人类可读的文本块。
用户执行 Python 代码块,然后将结果直接插入文档中。 除非以同样的方式运行,否则代码块可以以任何顺序重新运行,而不必影响以后的块。 由于 Jupyter 笔记本基于 IPython,因此有一些附加功能,例如魔术命令。
Anaconda 随附 Jupyter 笔记本。 Jupyter 笔记本允许纯文本与代码混合。 可以使用称为 Markdown 的语言格式化纯文本。 它以纯文本格式完成。 我们也可以插入段落。 以下示例是您在 Markdown 中看到的一些常见语法:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-W10DzIIk-1681367023139)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/91c48200-98ac-44dd-9708-3497a787c687.png)]
以下屏幕截图显示了 Jupyter 笔记本:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-atwwqUD5-1681367023139)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/569e8dbc-0948-41f4-a911-f06b533ed491.png)]
如您所见,它用尽了网络浏览器,例如 Chrome 或 Firefox,在这种情况下为 Chrome。 当我们开始 Jupyter 笔记本时,我们在文件浏览器中。 我们在一个新创建的目录Untitled Folder中。 在 Jupyter 笔记本中,有用于创建新笔记本,文本文件和文件夹的选项。 如前面的屏幕截图所示,当前没有保存笔记本。 我们将需要一个 Python 笔记本,可以通过在以下屏幕快照中显示的“新建”下拉菜单中选择 Python 选项来创建它。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-p33vW2Cw-1681367023140)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/c622867b-9917-4cf6-8873-652cb09681be.png)]
笔记本启动后,我们从一个代码块开始。 我们可以将此代码块更改为 Markdown 块,现在可以开始输入文本了。
例如,我们可以输入标题。 我们还可以输入纯文本以及粗体和斜体,如下面的屏幕快照所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TDBcd82q-1681367023140)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/a0e37ac9-6c29-41a6-800a-d54997940fa6.png)]
如您所见,在渲染结束时会有一些提示,但是实际上我们可以通过单击运行单元按钮来查看渲染。 如果要更改此设置,可以双击同一单元格。 现在我们回到纯文本编辑。 在这里我们添加单型,然后再次单击运行单元,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-m9yzKGK2-1681367023141)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/4e012685-36bb-4577-a304-52fc784de693.png)]
在按下Enter时,随后将立即创建一个新单元格。 该单元格是一个 Python 单元格,我们可以在其中输入 Python 代码。 例如,我们可以创建一个变量。 我们多次打印Hello, world!,如以下屏幕截图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MJ7BVP1X-1681367023141)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/949ce51b-9437-41be-9dba-83546b92383d.png)]
要查看执行单元时会发生什么,我们只需单击运行单元; 同样,当我们按Enter时,将创建一个新的单元块。 让我们将此单元格块标记为 Markdown 块。 如果要插入其他单元格,可以按下面的插入单元格。 在第一个单元格中,我们将输入一些代码,在第二个单元格中,我们可以输入依赖于第一个单元格中的代码的代码。 注意当我们尝试在第一个单元格中执行代码之前在第二个单元格中执行代码时会发生什么。 将产生一个错误,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jqbAfKxG-1681367023141)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/6aafed53-74eb-4362-b24f-4ad744e05df5.png)]
投诉变量trigger尚未定义。 为了使第二个单元正常工作,我们需要运行第一个单元。 然后,当我们运行第二个单元格时,我们将获得预期的输出。 现在假设我们要更改此单元格中的代码。 比方说,我们有trigger = True而不是trigger = False。 第二个单元将不知道该更改。 如果再次运行此单元格,则会得到相同的输出。 因此,我们将需要首先运行此单元格,从而影响更改。 然后我们可以运行第二个单元并获得预期的输出。
后台发生了什么? 发生的事情是有一个内核,它基本上是一个正在运行的 Python 会话,它跟踪我们所有的变量以及到目前为止发生的所有事情。 如果单击内核,则可以看到重新启动内核的选项。 这将基本上重新启动我们的 Python 会话。 我们最初警告说,通过重新启动内核,所有变量都将丢失。
重新启动内核后,似乎没有任何更改,但是如果我们运行第二个单元,则将产生错误,因为变量trigger不存在。 我们将需要首先运行上一个单元,以便该单元正常工作。 相反,如果我们不仅要重启内核,还要重启内核并重新运行所有单元,则需要单击“重启并运行全部”。 重新启动内核后,将重新运行所有单元块。 它可能看起来好像没有发生任何事情,但是我们已经从第一个开始,运行它,运行第二个单元格,然后运行第三个单元格,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OQHxPkEU-1681367023142)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/2565c2e6-345d-4b1e-a1c2-7d3f5c795ea6.png)]
我们也可以导入库。 例如,我们可以从 Matplotlib 导入模块。 在这种情况下,为了使 Matplotlib 在 Jupyter 笔记本中交互工作,我们将需要使用魔术命令,该魔术命令以%开头,魔术命令的名称以及需要传递给的任何类型的参数。 它。 稍后,我们将在详细信息中介绍这些内容,但首先让我们运行该单元格。plt现在已经加载,现在我们可以使用它了。 例如,在最后一个单元格中,我们将输入以下代码:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-n9T3vIrc-1681367023142)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/cd197191-9798-46d6-9448-bed5424046a6.png)]
请注意,此单元格的输出直接插入到文档中。 我们可以立即看到创建的图。 回到魔术命令,这不是我们唯一可用的命令。 让我们看看其他命令:
- 魔术命令
magic将打印有关魔术系统的信息,如以下屏幕截图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PSkfVGvF-1681367023142)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/0f3e2361-f268-4a4c-906f-a07c8abfb37e.png)]
魔术命令的输出
- 另一个有用的命令是
timeit,我们可以使用它来分析代码。 我们首先输入timeit,然后输入我们希望分析的代码,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DElcfvpL-1681367023143)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/7568717e-d006-4017-9604-acd103872739.png)]
- 魔术命令
pwd可用于查看工作目录是什么,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-f3nzHiDc-1681367023143)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/40e2e58c-e439-408c-9599-ecddba61f8b8.png)]
- 魔术命令
cd可用于更改工作目录,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-x6da9WtG-1681367023143)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/17797748-fa2f-487f-b02c-d0059a261bf1.png)]
- 如果我们希望以交互模式启动 Matplotlib 和 NumPy,魔术命令
pylab很有用,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SOm8hWxn-1681367023144)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/4c06dc29-3b70-487d-9d98-7e13353944c9.png)]
如果希望查看可用魔术命令的列表,可以键入lsmagic,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-klhe2fv9-1681367023144)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/e34823c6-6be8-4696-bc06-5e54f9cff9d1.png)]
如果需要快速参考表,可以使用魔术命令quickref,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KfHw4HMC-1681367023145)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/29c90042-1537-4075-88dd-edec313c9025.png)]
现在,我们已经完成了此笔记本的工作,让我们为其命名。 我们简单地称它为My Notebook。 通过单击编辑器窗格顶部的笔记本名称来完成此操作。 最后,您可以保存,并且保存后可以关闭和停止笔记本电脑。 因此,这将关闭笔记本并停止笔记本的内核。 那是离开笔记本电脑的干净方法。 现在注意,在我们的树中,我们可以看到保存笔记本的目录,并且可以看到该目录中存在笔记本。 它是ipynb文件。
探索 Jupyter 的替代品
现在,我们将考虑替代 Jupyter 笔记本。 我们将看:
- Jupyter QT 控制台
- Spider
- Rodeo
- Python 解释器
- ptpython
我们将考虑的第一个替代方案是 Jupyter QT 控制台。 这是一个具有附加功能的 Python 解释器,专门用于数据分析。
以下屏幕截图显示了 Jupyter QT 控制台:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J1WZmLY2-1681367023145)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/43fea253-2b02-483a-8fac-781c98e575b9.png)]
它与 Jupyter 笔记本非常相似。 实际上,它实际上是 Jupyter 笔记本的控制台版本。 注意这里我们有一些有趣的语法。 我们有In [1],然后假设您要键入一个命令,例如:
print ("Hello, world!")
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-T1WKXLmD-1681367023145)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/3c7060ef-3bf8-4512-9e27-204df317932e.png)]
我们看到一些输出,然后看到In [2]。
现在让我们尝试其他方法:
1 + 1
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gT9XIgRV-1681367023145)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/f8fbe4b3-179f-4688-a522-102e7ab26012.png)]
在In [2]之后,我们看到Out[2]。 这是什么意思? 这是一种在会话中跟踪历史命令及其输出的方法。 要访问In [42]的命令,我们输入_i42。 因此,在这种情况下,如果要查看命令 2 的输入,请键入i2。 注意,它给我们一个字符串1 + 1。实际上,我们可以运行此字符串。
如果我们输入eval,然后输入_i2,请注意,它给我们提供的输出与原始命令In [2]相同。 现在Out[2]怎么样? 我们如何获取实际输出? 在这种情况下,我们要做的只是_,然后是输出的数量,例如 2。这应该给我们 2。因此,这为您提供了一种更方便的方法来访问历史命令及其输出。
Jupyter 笔记本电脑的另一个优点是您可以看到图像。 例如,让我们运行 Matplotlib。 首先,我们将使用以下命令导入 Matplotlib:
import matplotlib.pyplot as plt
导入 Matplotlib 之后,回想一下我们需要运行某种魔术,即 Matplotlib 魔术:
%matplotlib inline
我们需要给它内联参数,现在我们可以创建一个 Matplotlib 图形。 请注意,该图像显示在命令的正下方。 当我们输入_8时,它表明创建了 Matplotlib 对象,但实际上并未显示图本身。 如您所见,与典型的 Python 控制台相比,我们可以以更高级的方式使用 Jupyter 控制台。 例如,让我们使用名为Iris的数据集; 使用以下行将其导入:
from sklearn.datasets import load_iris
这是用于数据分析的非常常见的数据集。 它通常用作求值训练模型的一种方法。 我们还将在此上使用 k 均值聚类:
from sklearn.cluster import KMeans
load_Iris函数实际上不是Iris数据集; 它是我们可以用来获取Iris数据集的函数。 以下命令实际上将使我们能够访问该数据集:
iris = load_iris()
现在,我们将在此数据集上训练 K 均值聚类方案:
iris_clusters = KMeans(n_clusters = 3, init = "random").fit(iris.data)
键入函数时,我们可以立即查看文档。 例如,我知道n_clusters参数的含义。 它实际上是函数中的原始文档字符串。 在这里,我希望聚类的数量为3,因为我知道此数据集中实际上有三个真实聚类。 既然已经训练了聚类方案,我们可以使用以下代码对其进行绘制:
plt.scatter(iris.data[:, 0], iris.data[:, 1], c = iris_clusters.labels_)
Spyder
Spyder 是与 Jupyter 笔记本或 Jupyter QT 控制台不同的 IDE。 它集成了 NumPy,SciPy,Matplotlib 和 IPython。 它可以通过插件扩展,并且包含在 Anaconda 中。
以下屏幕截图显示了 Spyder,这是一个用于数据分析和科学计算的实际 IDE:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-L1PjO4MJ-1681367023146)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/ca0a9906-aced-4951-a769-6679c7a0dc9c.png)]
Spyder Python 3.6
在右侧,您可以转到文件资源管理器以搜索要加载的新文件。 在这里,我们要打开iris_kmeans.py。 这是一个文件,其中包含我们之前在 Jupyter QT 控制台中使用的所有命令。 请注意,在右侧,编辑器有一个控制台。 实际上就是 IPython 控制台,您将其视为 Jupyter QT 控制台。 我们可以通过单击 Run 选项卡来运行整个文件。 它将在控制台中运行,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bl8iBZ2B-1681367023146)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/fae7f8db-2540-43cf-a10f-76474350c5ff.png)]
以下屏幕截图将作为输出:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kO1PfgP9-1681367023146)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/2dfc4468-a03e-433a-90c6-d698e12b1019.png)]
注意,最后我们看到了之前看到的聚类结果。 我们也可以在命令中以交互方式键入; 例如,我们可以使计算机说Hello, world!。
在编辑器中,我们输入一个新变量,例如n = 5。 现在,让我们在编辑器中运行此文件。 请注意,n是编辑器可以识别的变量。 现在让我们进行更改,例如n = 6。 除非我们再次实际运行此文件,否则控制台将不会意识到所做的更改。 因此,如果我再次在控制台中键入n,则没有任何变化,仍然是5。 您需要运行此行才能实际看到更改。
我们还有一个变量浏览器,可以在其中查看变量的值并进行更改。 例如,我可以将n的值从6更改为10,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tsCv9WIg-1681367023147)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/284f9dfb-6801-4b6a-ae1c-2ed5fd1f09bd.png)]
以下屏幕截图显示了输出:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Mih8Xydy-1681367023147)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/5dd3a7ac-d098-454b-bbf3-45fec9d1dd4a.png)]
然后,当我进入控制台并询问n是什么时,它会说10:
n
10
到此结束我们对 Spyder 的讨论。
Rodeo
Rodeo 是 Yhat 开发的 Python IDE,专门用于数据分析应用。 它旨在模拟在 R 用户中很流行的 RStudio IDE,并且可以从 Rodeo 的网站上下载。 基本的 Python 解释器的唯一优点是每个 Python 安装程序都包含它,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ii5v68YD-1681367023147)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/e63f586b-c60a-49fe-9a52-dee69d209d6c.png)]
ptpython
Jonathan Slenders 设计的ptpython可能是鲜为人知的基于控制台的 Python REPL。 它仅存在于控制台中,并且是他的独立项目。 您可以在 GitHub 上找到它。 它具有轻量级功能,但还包括语法突出显示,自动完成,甚至包括 IPython。 可以使用以下命令进行安装:
pip install ptpython
到此,我们结束了有关 Jupyter 笔记本替代品的讨论。
使用 Conda 进行包管理
现在,我们将与 Conda 讨论包管理。 在本节中,我们将研究以下主题:
- 什么是 Conda?
- 管理 Conda 环境
- 使用 Conda 管理 Python
- 使用 Conda 管理包
什么是 Conda?
那么什么是 Conda? Conda(Conda)是 Anaconda 的包管理器。 Conda 允许我们创建和管理多个环境,从而允许存在多个版本的 Python,R 及其相关包。 如果您需要使用不同版本的 Python 及其包针对不同的系统进行开发,这将非常有用。 Conda 允许您管理 Python 和 R 版本,并且还简化了包的安装和管理。
Conda 环境管理
Conda 环境允许开发人员在其包中使用和管理不同版本的 Python。 这对于在遗留系统上进行测试和开发很有用。 可以保存,克隆和导出环境,以便其他人可以复制结果。
以下是一些常见的环境管理命令。
对于环境创建:
conda create --name env_name prog1 prog2
conda create --name env_name python=3 prog3
对于列表环境:
conda env list
要验证环境:
conda info --envs
克隆环境:
conda create --name new_env --clone old_env
删除环境:
conda remove --name env_name -all
用户可以通过创建 YAML 文件来共享环境,收件人可以使用该文件来构建相同的环境。 您可以手动执行此操作,在其中可以有效地复制 Anaconda 所做的工作,但是让 Anaconda 为您创建 YAML 文件要容易得多。
创建了这样的文件后,或者如果您从其他用户那里收到了此文件,则创建新环境非常容易。
管理 Python
如前所述,Anaconda 允许您管理多个版本的 Python。 可以搜索并查看哪些版本的 Python 可用于安装。 您可以验证环境中使用的是哪个版本的 Python,甚至可以为 Python 2.7 创建环境。 您还可以更新当前环境中的 Python 版本。
包管理
假设我们对安装包selenium感兴趣,该包用于 Web 抓取和 Web 测试。 我们可以列出当前安装的包,并且可以给出安装新包的命令。
首先,我们应该搜索以查看 Conda 系统是否提供该包。 并非pip上可用的所有包都可从 Conda 获得。 也就是说,实际上可以安装pip提供的包,尽管希望,如果我们希望安装包,可以使用以下命令:
conda install selenium
如果selenium是我们感兴趣的包,则可以从互联网自动下载它,除非您具有 Anaconda 可以直接从您的系统直接安装的文件。
要通过pip安装包,请使用以下命令:
pip install package_name
当然,可以如下删除包:
conda remove selenium
配置数据库
现在,我们将开始讨论设置数据库供您使用。 在本节中,我们将研究以下主题:
- 安装 MySQL
- 为 Python 安装 MySQL 连接器
- 创建,使用和删除数据库
为了使 MySQL 和 Python 一起使用,MySQL 连接器是必需的。 存在许多 SQL 数据库实现,尽管 MySQL 可能不是最简单的数据库管理系统,但它功能齐全,具有工业实力,在现实世界中很常见,而且它是免费和开源的,这意味着它是一个很好的学习工具。 您可以从 MySQL 的网站上获取 MySQL 社区版,它是免费和开源的版本。
安装 MySQL
对于 Linux 系统,如果可能,我建议您使用可用的任何包管理系统安装 MySQL。 如果您使用的是基于 Red-Hat 的发行版,则可以使用 YUM;如果您使用的是基于 Debian 的发行版,则可以使用 APT;或者,请使用 SUSE 的存储库系统。 如果您没有包管理系统,则可能需要从源代码安装 MySQL。
Windows 用户可以直接从其网站安装 MySQL。 您还应该注意,MySQL 包含 32 位和 64 位二进制文件,但是下载的任何程序都可能会为您的系统安装正确的版本。
您可以从以下网页下载适用于 Windows 的 MySQL:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AvsLwQRc-1681367023148)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/ee93dcc6-011a-4394-983e-12b44f1d65e8.png)]
我建议您使用 MySQL 安装程序。 向下滚动,然后在寻找要下载的二进制文件时,请注意,第一个二进制文件表示网络社区。 这将是一个安装程序,可在您进行安装时从互联网上下载 MySQL。 请注意,它比另一个二进制文件小得多。 它基本上包括了您能够安装 MySQL 所需的一切。 如果您继续关注的话,我会建议您下载该文件。
通常有可用的发行版。 这些应该是稳定的。 开发版本旁边是“常规版本”选项卡。 我建议您不要下载这些,除非您知道自己在做什么。
MySQL 连接器
MySQL 的功能类似于系统上的驱动程序,其他应用则与 MySQL 交互,就好像它是驱动程序一样。 因此,您将需要下载一个 MySQL 连接器,以便能够将 MySQL 与 Python 结合使用。 这将允许 Python 与 MySQL 通信。 您最终要做的是将其加载到包中,然后开始与 MySQL 的连接。 可以从 MySQL 的网站下载 Python 连接器。
该网页对于任何操作系统都是通用的,因此您需要选择适当的平台,例如 Linux,OS X 或 Windows。 无论您使用的是 32 位还是 64 位版本,都需要选择并下载与系统架构最匹配的安装程序,以及 Python 版本。 然后,您将使用安装向导以将其安装在系统上。
这是用于下载和安装连接器的页面:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zS4QnBI6-1681367023148)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/2242e5c4-4157-423d-a7d7-37975dd2b76b.png)]
注意,我们可以在这里选择哪个平台合适。 我们甚至有独立于平台的版本和源代码版本。 也可以使用包管理系统进行安装,例如,如果使用的是基于 Debian 的系统,则为 APT;如果使用的是基于 Red-Hat 的系统,则为 Ubuntu 或 YUM,等等。 我们有许多不同的安装程序,因此我们需要知道我们正在使用哪个版本的 Python。 建议您使用与项目中实际使用的版本最接近的版本。 您还需要在 32 位和 64 位之间进行选择。 然后,单击下载并按照安装程序的说明进行操作。
因此,数据库管理是一个主要主题。 涉及数据库管理的所有内容将使我们远远超出本书的范围。 我们不会谈论好的数据库是如何设计的。 我建议您转到另一个资源,也许是另一个解释这些主题的 Packt 产品,因为它们很重要。 关于 SQL,我们只会告诉您基本级别使用 SQL 所需的命令。 也没有关于权限的讨论,因此我们将假设您的数据库对使用它的任何用户都具有完全权限,并且一次只有一个用户。
建立数据库
在 MySQL 命令行中安装 MySQL 之后,我们可以使用以下命令创建数据库,其后为数据库的名称:
create database
每个命令必须以分号结尾; 否则,MySQL 将等到命令实际完成。
您可以使用以下命令查看所有可用的数据库:
show databases
我们可以通过以下命令指定要使用的数据库:
use database_name
如果要删除数据库,可以使用以下命令删除数据库:
drop database database_name
这是 MySQL 命令行:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-g8KZHqJy-1681367023148)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/52e30627-c754-4336-a108-f81a6a9d9db6.png)]
让我们练习管理数据库。 我们可以使用以下命令创建数据库:
create database mydb
要查看所有数据库,我们可以使用以下命令:
show databases
这里有多个数据库,其中一些来自其他项目,但是正如您所看到的,我们刚刚创建的数据库mydb显示如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aYEMJxDz-1681367023149)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/4624af19-8534-4869-bcf7-50f7a3c0c526.png)]
如果要使用此数据库,则可以使用命令use mydb。 MySQL 说数据库已更改。 这意味着当我发出诸如创建表,从表中读取或添加新数据之类的命令时,所有这些操作都将由数据库mydb完成。
假设我们要删除数据库mydb; 我们可以使用以下命令进行操作:
drop database mydb
这将删除数据库。
总结
在本章中,向我们介绍了 Anaconda,了解了为什么它是一个有用的起点,然后下载并安装了它。 我们探索了 Jupyter 的一些替代方法,介绍了如何管理 Anaconda 包,还学习了如何设置 MySQL 数据库。 不过,在本书的其余部分中,我们都假定已经安装了 Anaconda。 在下一章中,我们将讨论如何使用 NumPy,它是数据分析中的有用包。 没有这个包,使用 Python 进行数据分析几乎是不可能的。
二、探索 NumPy
到目前为止,您应该已经安装了使用 Python 进行数据分析所需的一切。 现在让我们开始讨论 NumPy,这是用于管理数据和执行计算的重要包。 没有 NumPy,就不会使用 Python 进行任何数据分析,因此了解 NumPy 至关重要。 本章的主要目标是学习使用 NumPy 中提供的工具。
本章将讨论以下主题:
- NumPy 数据类型
- 创建数组
- 切片数组
- 数学
- 方法和函数
我们从讨论数据类型开始,这在处理 NumPy 数组时在概念上很重要。 在本章中,我们将讨论由dtype对象控制的 NumPy 数据类型,这是 NumPy 存储和管理数据的方式。 我们还将简要介绍称为ndarray的 NumPy 数组,并讨论它们的作用。
NumPy 数组
现在让我们讨论称为ndarray的 NumPy 数组。 这些不是您在 C 或 C++ 中可能遇到的数组。 更好的模拟是 MATLAB 或 R 中的矩阵。 也就是说,它们的行为类似于数学对象,类似于数学向量,矩阵或张量。 尽管它们可以存储诸如字符串之类的非数学信息,但它们的存在主要是为了管理和简化对数字数据的操作。ndarray在创建时被分配了特定的数据类型或dtype,并且数组中所有当前和将来的数据必须属于该dtype。 它们还具有多个维度,称为轴。
一维ndarray是一行数据; 这将是一个向量。 二维ndarray将是数据的平方,实际上是一个矩阵。 三维ndarray将是关键数据,就像张量一样。 允许任意数量的尺寸,但大多数ndarray都是一维或二维的。
dtype与基本 Python 语言中的类型相似,但 NumPy dtype与其他语言(例如 C,C++ 或 Fortran)中看到的数据类型也很相似,因为它们的长度是固定的。dtype具有层次结构;dtype通常具有字符串描述符,后跟 2 的幂以决定dtype的大小。
以下是常见的dtype列表:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-62B60lYz-1681367023149)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/c9a05b8f-94b1-4c7e-8888-fed3265c6cd5.png)]
让我们看一下我们刚刚讨论过的一些内容。 我们要做的第一件事是在 NumPy 库中加载。 接下来,我们将创建一个 1 的数组,它们将是整数。
这是数组的样子:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-V2PvEEYk-1681367023149)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/53e332d4-6601-4803-919f-c1e772c4b24f.png)]
如果我们查看dtype,就会看到它是int8,即 8 位整数。 我们还可以创建一个由 16 位浮点数填充的数组。 该数组看起来类似于整数数组。 1 的末尾有一个圆点; 这有点表明包含的数据是浮点而不是整数。
让我们创建一个填充无符号整数的数组:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XbY6IwCj-1681367023149)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/3e9f87fd-7331-4399-9396-881a8c917e2d.png)]
同样,它们为 1,看起来与我们以前的相似,但现在让我们尝试更改一些数据。 例如,我们可以将数组int_ones中的数字更改为 -1,就可以了。 但是,如果我尝试将其以无符号整数更改为 -1,则最终会得到 255。
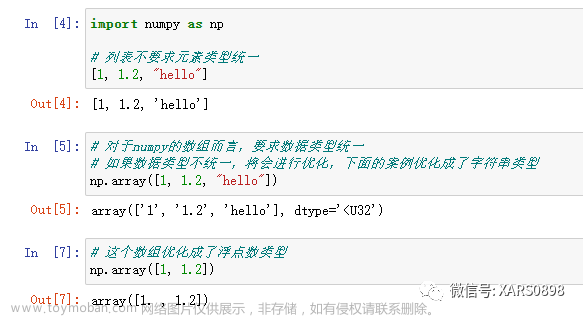
让我们创建一个填充字符串的数组:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Z6l1gKCK-1681367023149)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/137bc79a-59ee-44a6-a90f-c8503ecfa0a3.png)]
我们此处未指定dtype参数,因为通常会猜测dtype。 通常会做出一个很好的猜测,但是并不能保证。 例如,在这里我想为该数组的内容分配一个新值Waldo。 现在,此dtype表示您的字符串长度不能超过四个。 虽然Waldo有五个字符,所以当我们更改数组并更改其内容时,我们以Wald而不是Waldo结尾。 这是因为它不能超过五个字符。 只需要前四个:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9UkXjMhH-1681367023150)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/9d488485-848b-4c1c-bfaa-6cd76eb8fc72.png)]
我可以手动指定dtype并说允许使用 16 个字符; 在这种情况下,Waldo可以正常工作。
特殊数值
除了dtype对象之外,NumPy 还引入了特殊的数值:nan和inf。 这些可以在数学计算中出现。 不是数字(NaN)。 它表明应为数字的值实际上不是数学定义的。 例如,0/0产生nan。 有时nan也用于表示缺少的信息; 例如,Pandas 就用这个。inf表示任意大的数量,因此在实践中,它表示比计算机可以想象的任何数量大的数量。 还定义了-inf,它的意思是任意小。 如果数字运算爆炸,即迅速增长而没有边界,则可能会发生这种情况。
从未等于nan; 没有定义的事物等于其他事物是没有意义的。 您需要使用 NumPy 函数isnan来识别nan。 尽管==符号不适用于nan,但适用于inf。 就是说,最好还是使用函数有限或inf来区分有限值和无限值。 定义了涉及nan和inf的算法,但请注意,它可能无法满足您的需求。 定义了一些特殊函数,以帮助避免出现nan或inf时出现的问题。 例如,nansum 在忽略nan的同时计算可迭代对象的总和。 您可以在 NumPy 文档中找到此类函数的完整列表。 使用它们时,我只会提及它们。
现在让我们来看一个例子:
- 首先,我们将创建一个数组,并将其填充为
1,-1和0。 然后,将其除以0,然后看看得到了什么。 所以,当我们这样做时,它会抱怨,因为显然我们不应该除以0。 我们在小学学习了!
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QJe4lXqC-1681367023150)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/beb7c2f1-67a7-4273-a78e-b0be573c6963.png)]
也就是说,它确实带有数字:1/0是inf,-1/0是-inf和0/0不是数字。 那么我们如何检测特殊值呢?
- 让我们首先运行一个错误的循环:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1arAbKy3-1681367023150)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/27a62731-2f47-4664-98b7-577852953fa5.png)]
我们将遍历vec2的每个可能值,并打印i == np.inf,i == -np.inf的结果以及i是否等于nan,i == np.nan的结果。 我们得到的是一张清单;inf和-inf的前两个块很好,但是这个nan不好。 我们希望它检测到nan,但它没有这样做。 因此,让我们尝试使用是nan函数:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-27ZNRIE3-1681367023151)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/5a78d47d-efda-4805-89cc-7184f5541f39.png)]
实际上,这确实有效; 我们能够检测到nan。
- 现在,让我们检测有限与无限:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YoBfkD0o-1681367023151)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/4aafb70e-7107-4da8-a8af-083282dd191a.png)]
毫不奇怪,inf不是有限的。-inf都不是。 但是nan既不是有限的也不是无穷大; 它是未定义的。 让我们看看执行inf + 1,inf * -1和nan + 1时会发生什么。 我们总是得到nan。
如果我们将 2 增大到负无穷大的幂,则得到的是 0。但是,如果将其提高到无穷大,我们将得到无穷大。inf - inf等于NaN而不是任何特定数字:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-33VzMJ1n-1681367023151)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/de302823-d282-46b1-81d2-a1655f52a956.png)]
- 现在,让我们创建一个数组并用数字
999填充它。 如果我们求这个数组和自身的幂,换言之,计算999的999次方,那么最终得到的就是inf:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lSqqXbll-1681367023151)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/d207463c-cb60-4a36-aa60-a938a2aa801a.png)]
对于这些程序来说,这个数字太大了。 也就是说,我们知道这个数字实际上不是无限的。 它是有限的,但是对于计算机而言,它是如此之大,以至于它也可能是无限的。
- 现在,让我们创建一个数组,并将该数组的第一个元素指定为
nan。 如果我们对这个数组的元素求和,我们得到的是nan,因为nan +都是nan:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SFx9mnYa-1681367023151)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/45324bdd-4926-41d6-aaed-0e6efdb562c7.png)]
但是,如果我们使用函数nansum,则nan将被忽略,我们将获得合理的值 4。
创建 NumPy 数组
现在,我们已经讨论了 NumPy 数据类型,并简要介绍了 NumPy 数组,下面让我们讨论如何创建 NumPy 数组。 在本节中,我们将使用各种函数创建 NumPy 数组。 有一些函数可以创建所谓的空ndarray; 用于创建ndarray的函数,其中填充了 0、1 或随机数; 以及使用数据创建ndarray的函数。 我们将讨论所有这些,以及从磁盘保存和加载 NumPy 数组。 有几种创建数组的方法。 一种方法是使用数组函数,在此我们提供一个可迭代的对象或一个可迭代的对象列表,从中将生成一个数组。
我们将使用列表列表来执行此操作,但是这些列表可以是元组,元组的元组甚至其他数组的列表。 还有一些方法可以自动创建充满数据的数组。 例如,我们可以使用诸如ones,zeros或randn之类的函数; 后者填充了随机生成的数据。 这些数组需要传递一个元组,该元组确定数组的形状,即数组具有多少维以及每个维的长度。 每个创建的数组都被认为是空的,不包含任何感兴趣的数据。 这通常是垃圾数据,由创建数组的内存位置中的任何位组成。
我们可以根据需要指定dtype参数,但如果不指定,则可以猜测dtype或浮点数。 请注意下表中的最后一行:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7acyMbHk-1681367023152)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/dd0e5908-9020-4161-93b6-ed15a67f7865.png)]
认为可以通过将arr1分配给新变量来复制它是错误的。 相反,您实际上得到的是指向相同数据的新指针。 如果您想要一个具有完全独立于其父代的相同数据的新数组,则将需要使用copy方法,我们将看到。
创建ndarray
在下面的笔记本中,我们创建一个ndarray。 我们要做的第一件事是创建一个 1 的向量。 注意正在传递的元组; 它仅包含一个数字5。 因此,它将是具有五个元素的一维ndarray:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8JqVi5mq-1681367023152)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/12e69768-3944-4664-b6c5-4458046f4bed.png)]
系统自动为其分配了dtype浮点 64:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-khTbz5OE-1681367023152)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/dcec4e5a-58a1-42ca-ac5e-f2a92e02a5f4.png)]
如果我们想将其转换为整数,我们可以首先尝试通过以下方式进行操作,但结果将是垃圾:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1y1Z3s3l-1681367023152)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/4234f49f-fcc5-4a98-8426-b73ec248839b.png)]
转换dtype时需要非常小心。
正确的方法是首先创建一个由五个 1 组成的原始向量,然后使用这些元素作为输入来创建一个全新的数组。 结果如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6Z2S2dd7-1681367023153)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/f75db329-ed43-4dbe-9d89-90b70549854e.png)]
注意vec1实际上具有正确的数据类型。 当然,我们可以通过指定我们最初想要的dtype来规避此问题。 在这种情况下,我们需要 8 位整数。 结果如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gMZlHAHO-1681367023153)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/90db700f-ecc0-4db4-bd7c-9b7429254765.png)]
现在,让我们创建一个 0 的多维数据集。 在这里,我们将创建一个三维数组。 也就是说,我们有行,我们有列,还有楼板。
因此,我们按此顺序有两行,两列和两个平板,我们将把它做成 64 位浮点数。 结果如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IfJDuD7N-1681367023153)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/c07321a7-79bf-4e42-b28d-951f94c0cdae.png)]
结果的顶部将被视为一个平板,而底部将被视为另一平板。
现在,让我们创建一个填充有随机数据的矩阵。 在这种情况下,我们将使用randn函数创建一个具有三行三列的方阵,该函数是 NumPy 随机模块的一部分:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xCvbjTAu-1681367023153)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/68db44e7-74f3-44b8-8712-ee9926259dcd.png)]
我们传递的第一个数字是行数,第二个数字是列数。 您可以传递第三个数字来确定平板的数量,第四个,第五个等等,以指定所需的维数以及每个维的长度。
现在,我们将创建2 x 2个具有所选名称的矩阵,以及2 x 2 x 2个包含数字的数组。 因此,这是一个仅包含名称的矩阵:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Q3TQc2eb-1681367023154)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/bd1788b5-bd18-45d8-bb65-2965bc0332fb.png)]
我们可以看到dtype是U5,即五个字母长的 Unicode 字符串。
我们还可以使用元组来创建数组:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3sF7PJiQ-1681367023154)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/6eea7c99-9d1f-40bd-84a0-0ec0d41772db.png)]
在这种情况下,我们有一个具有多个级别的数组,因此最终将是三维数组。(1, 3, 5)将是此数组的第一个平板的第一行,(2, 4, 6)将是第一个平板的第二行。[(1, 3, 5), (2, 4, 6)]确定第一个平板。[(1, np.nan, 1), (2, 2, 2)]确定第二个平板。 总而言之,我们得到了一个多维数据集:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I5QOwjze-1681367023154)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/360ef440-ccb7-412c-9abe-11852ffb17e5.png)]
如前所述,如果我们希望复制数组的内容,则需要小心。
考虑以下示例:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DbQMsxdr-1681367023154)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/9339726a-53dc-4313-a11a-b8900740f8c7.png)]
例如,我们可能天真地认为这将创建mat2的新副本,并将其存储在mat2_copy中。 但是请注意如果我们要更改此数组的假定副本中的条目,或者更改原始父数组的条目会发生什么。 在mat2中,如果我们将第一行和第一列中的元素(即元素(0, 0))更改为liam,则结果如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FWshjTtA-1681367023154)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/f964c0d8-2438-4651-8682-08e1a95bdd28.png)]
如果查看副本,则会发现更改也影响了副本:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SdQBOT9b-1681367023155)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/dc697d4b-f141-4b98-9ac9-73b6027cd8c8.png)]
因此,如果要独立副本,则需要使用copy方法。 然后,当我们更改mat2的 0,0 元素时,它不会影响copy,方法:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BQ2E8HoX-1681367023155)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/fd6ee3d9-59f3-4eb8-8d9d-98b9e7c61c69.png)]
我们还可以对副本进行更改,并且不会影响父级。
以下是保存ndarray对象的常用方法的列表:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3LX1m1uD-1681367023155)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/d8ce83f0-5dbf-4559-9d09-05239a22de01.png)]
建议您使用save,savez或savetxt函数。 我已经在上表中显示了这些函数的通用语法。 在savetxt的情况下,如果要用逗号分隔的文件,只需将定界符参数设置为逗号字符。 另外,如果文件名以.gz结尾,则savetxt可以保存压缩的文本文件,从而节省了步骤,因为您以后无需自己压缩文本文件。 请注意,除非您编写完整的文件路径,否则指定的文件将保存在工作目录中。
让我们看看我们如何能够保存一些数组。 我们可能应该做的第一件事是检查工作目录是什么:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UXvwSieP-1681367023155)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/8040cc7b-15d7-4df0-89f5-afbf450ee59d.png)]
现在,在这种情况下,我将自动进入所需的工作目录中。 但是,如果我愿意,我可以使用cd命令更改工作目录,然后,实际上我会将那个目录作为我的工作目录:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mltBnFC4-1681367023155)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/1cbb6855-4f29-4568-9bc2-f31d2a31f5d2.png)]
就是说,让我们创建一个npy文件,它是 NumPy 的本机文件格式。 我们可以使用 NumPy 的save函数以此文件格式保存数组:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fzIejvI4-1681367023156)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/02387d90-35ec-4ba0-b00e-979069411de2.png)]
我们将拥有一个名为arr1的npy文件。 实际上,这是我们工作目录中的一个二进制文件。
如果我们希望加载保存在该文件中的数组,可以使用load函数:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PFrHgOoO-1681367023156)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/de072811-9bef-4e59-8ad2-ef193f5fe1c0.png)]
我们还可以创建一个在mat1中包含相同信息的 CSV 文件。 例如,我们可以使用以下函数保存它:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-26k3SyAM-1681367023156)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/432da793-afdb-4fc1-8d9c-c36e0c990774.png)]
我们可以使用以下代码查看mat1.csv的内容:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1uxLVwMI-1681367023156)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/773ca119-da58-47cc-9d5c-e54d348f849e.png)]
列用逗号分隔,行在换行符上。 然后,我们关闭此文件:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EJVksRUU-1681367023156)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/92e6a7fc-a97e-4011-ac75-8e2f08d2fe3e.png)]
现在,很明显,如果我们可以保存ndarray,那么我们也应该能够加载它们。 以下是一些用于加载ndarray的常用函数:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iSTTumPc-1681367023157)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/b74f654c-d2dd-4144-9fa4-d91ae823639a.png)]
这些函数与用于保存ndarray的函数紧密一致。 您将需要在 Python 中保存生成的ndarray。 如果要从文本文件加载,请注意,不必为创建ndarray而由 NumPy 创建数组。 如果您保存到 CSV,则可以使用文本编辑器或 Excel 创建 NumPy ndarray。 然后,您可以将它们加载到 Python 中。 我假设您正在加载的文件中的数据适合ndarray; 也就是说,它具有正方形格式,并且仅由一种类型的数据组成,因此不包含字符串和数字。
可以通过ndarray处理多类型的数据,但是此时您应该使用 pandas 数据帧,我们将在后面的部分中进行讨论。 因此,如果我想加载刚刚创建的文件的内容,可以使用loadtxt函数进行加载,结果如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PD9nFLqv-1681367023157)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/f28be513-9207-4b9c-bb2f-79cf5e1e108a.png)]
总结
在本章中,我们首先介绍 NumPy 数据类型。 然后我们迅速讨论了称为ndarray对象,的 NumPy 数组,它们是 NumPy 感兴趣的主要对象。 我们讨论了如何根据程序员的输入,其他 Python 对象,文件甚至函数创建这些数组。 我们继续讨论了如何从基本算术到成熟的线性代数对ndarray对象进行数学运算。
在下一章中,我们将讨论一些重要主题:使用数组对ndarray对象算术和线性代数进行切片,以及采用数组方法和函数。
三、NumPy 数组上的运算
现在,我们知道如何创建 NumPy 数组,我们可以讨论切片 NumPy 数组的重要主题,以便访问和操作数组数据的子集。 在本章中,我们将介绍每个 NumPy 用户应了解的有关数组切片,算术,带有数组的线性代数以及采用数组方法和函数的知识。
显式选择元素
如果您知道如何选择 Python 列表的子集,那么您将了解有关ndarray切片的大部分知识。 与索引对象的元素相对应的被索引数组元素在新数组中返回。 索引编制的最重要方面是要记住存在多个维度,并且索引编制方法应能够处理这些其他维度。
明确选择元素时,请记住以下几点:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XSCIfnWG-1681367023157)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/dd4c8b0f-33bd-41dc-8c0e-d60623965fda.png)]
用逗号分隔不同维度的索引对象; 第一个逗号之前的对象显示了如何索引第一维。 在第一个逗号之后是第二个维度的索引,在第二个逗号之后是第三个维度的索引,依此类推。
用冒号切片数组
使用冒号索引ndarray对象的工作类似于使用冒号索引列表。 只要记住,现在有多个维度。 请记住,当冒号之前或之后的点留为空白时,Python 会将索引视为扩展到维的开始或结束。 可以指定第二个冒号,以指示 Python 跳过每隔一行或反转行的顺序,具体取决于第二个冒号下的数目。
使用冒号对数组进行切片时,需要记住以下几点:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0tHNs6Y0-1681367023157)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/163f227b-8deb-49ee-be42-93a3d410ecc9.png)]
让我们来看一个例子。 首先,我们加载 NumPy 并创建一个数组:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zW0k2NKA-1681367023158)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/af0927e8-301a-42be-9310-3d7474e8d22b.png)]
注意,我们创建的是三维数组。 现在,这个数组有点复杂,所以让我们使用二维3 x 3数组代替 :
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EZvPFrBf-1681367023158)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/4b7191f0-9604-4d41-ade1-a94f825cc394.png)]
我们在这里使用了复制方法。 返回了一个新对象,但是该对象不是数组的新副本; 它是数组内容的视图。 因此,如果我们希望创建一个独立的副本,则在切片时也需要使用copy方法,如我们之前所见。
如果要更改此新数组中的条目,将第二行和第二列的内容设置为Atilla,则可以更改此新数组:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9YdQRWmg-1681367023158)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/a14afb7d-7531-4172-8cf0-16e2a3686a5f.png)]
但是我们没有更改原始内容:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gQHxBvpa-1681367023158)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/8065a920-5926-4da4-b25f-ffa671e97dcb.png)]
因此,这些是第一个数组中数据的两个独立副本。 现在让我们探索其他切片方案。
在这里,我们看到使用列表建立索引。 我们要做的是创建一个列表,该列表与我们要捕获的对象中每个元素的第一个坐标相对应,然后为第二个坐标提供一个列表。 因此 1 和 0 对应于我们希望选择的一个元素; 如果这是三维对象,我们将需要第三个列表作为第三个坐标:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Qjx0mPgU-1681367023158)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/dbca1a1b-e7bb-4b0d-98a6-1d18cbf8fc98.png)]
我们使用切片器从左上角选择元素:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aB1G3Wi1-1681367023159)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/40172430-b3d5-42c0-8352-764244934c4f.png)]
现在,让我们从中间一栏中选择元素:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-42iZAZTj-1681367023159)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/4cc32014-9940-41e7-9119-8e39ea17c51b.png)]
并且,让我们从中间列中选择元素,但我们不会展平矩阵,而是保持其形状:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kvDCXSoL-1681367023159)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/0496fafd-12d4-4609-9bd7-00ea5b6e184d.png)]
这是一维对象,但是在这里我们需要一个二维对象。 尽管只有一列,但只有一列和一行,而不是只有一行和一列是没有意义的。 现在让我们选择中间列的最后两行:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1wcCwFBc-1681367023159)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/3b069361-e914-4be8-82ca-5de10e97f5e6.png)]
我们反转行顺序:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iWts4NLb-1681367023160)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/7ac075aa-ffdc-4e40-8122-44975eb2aeab.png)]
如果查看原始对象,则会发现这些规则以相反的顺序发生(与最初的排序方式相比),这意味着选择奇数列:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7ZkIxX5l-1681367023160)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/8a40d17d-96b8-4941-9e5a-b021835166e4.png)]
我们可以转到更复杂的三维数组,并查看类似的切片方案。 例如,这是一个2 x 2 x 2的角落立方体:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lCfrjgai-1681367023160)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/71d20c8d-94ee-42a8-bcd0-5873b5436fa9.png)]
这是中间部分:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CcCb29yc-1681367023160)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/c0f97afc-f0ea-4844-a5b2-693f6e425405.png)]
我们可以看到该中间切片是二维数组。 因此,如果我们希望保留维数,那么另一种方法是使用 NumPy 中的新轴对象插入一个额外的维数:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wwcqgYOO-1681367023160)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/11ef9cf1-1380-4b4d-b6bb-c7cbda525b09.png)]
我们看到这个对象实际上是三维的:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yetvPXsH-1681367023161)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/b4c482b3-2c3f-484b-9399-54c8d10a3db4.png)]
尽管事实上其中一个维度的长度为 1。
高级索引
现在让我们讨论更高级的索引技术。 我们可以使用其他ndarray为ndarray对象建立索引。 我们可以使用包含与我们希望选择的ndarray的索引对应的整数的ndarray对象或布尔值的ndarray对象来切片ndarray对象,其中值true表示切片中应包含一个单元格。
选择不是Wayne的arr2元素,这是结果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-R9hcyjwx-1681367023161)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/ac3484b4-148f-429a-8a45-8438a9099552.png)]
Wayne不包括在选择中,这是为执行该索引而生成的数组:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KQWmihXT-1681367023161)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/e8020cee-2b6f-4749-a0fa-0853b8d9ccdf.png)]
除了内容为Wayne的地方,到处都是True。
另一种更高级的技术是使用整数数组进行选择,以标识所需的元素。 因此,在这里,我们将创建两个用于切片的数组:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I3XnN999-1681367023161)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/8fad7f33-bca1-4121-8837-9e70331b95a0.png)]
第一个数组中的第一个 0 表示第一个坐标为零,第二个数组中的第一个 0 表示第二个坐标为零,这由这两个数组列出的顺序指定。因此,所得数组的第一行和第一列的元素为[0, 0]。 在第一行和第二列中,我们有原始数组中的元素[0, 2]。 然后,在第二行和第一列中,我们具有原始数组的第三行和第一列中的元素。 注意,这是Wayne。
然后,我们有了原始数组的第三行和第三列中的元素,该元素对应于Joey。
让我们来看一下更复杂的数组。 例如,我们可以看到arr1以外的所有条目Curtis:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-E8bVdrYB-1681367023162)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/3d8e7ad6-8e26-4267-8894-56ecc09bc246.png)]
这是索引数组的样子:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NhdD8Psq-1681367023162)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/8d38cc7c-8b76-406d-82e3-8e995d1cab0e.png)]
在这里,我们看到了一个更为复杂的切片方案:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MKPQdkX6-1681367023162)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/7a8488bc-412e-4246-bda9-96d66bb31cc5.png)]
idx0指示如何选择第一个坐标,idx1指示如何选择第二个坐标,idx2指示如何选择第三个坐标。 在这种情况下,我们在原始数组的每个四分之一元素中选择对象。
因此,我实际上已经编写了一些代码,可以实际演示哪些元素将显示在新数组中,即,原始数组中的坐标对新数组中的元素而言是什么。
例如,我们得到的是一个二维矩阵2 x 2 x 2。如果我们想知道切片对象的第二行,第二列和第一个平板中的内容,则可以使用如下代码 :
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Inpxixgv-1681367023162)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/6775c4bd-a18b-4f5d-82a1-054281393b62.png)]
那是原始数组的元素 2、0、2。
扩展数组
连接函数允许使用屏幕上显示的语法沿公共轴将数组绑定在一起。 该方法要求数组沿未用于绑定的轴具有相似的形状。 结果就是全新的ndarray,这是将数组粘合在一起的产物。 为此,还存在其他类似函数,例如堆叠。 我们不会涵盖所有内容。
假设我们想向arr2添加更多行。 使用以下代码执行此操作:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BqaVXSV9-1681367023162)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/e700972d-12c9-4034-b0d3-306ec2834ddc.png)]
我们创建一个全新的数组。 在这种情况下,我们不需要使用copy方法。 结果如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DnjdiMQT-1681367023163)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/ff450802-d16c-42d4-93fa-e7185eaa62b5.png)]
我们在此数组中添加了第四行,将新数组与数据(数组中的名称)绑定在一起。 它仍然是一个二维数组。 例如,请参见以下示例中的数组。 您可以清楚地看到这是二维的,但只有一列,而前一个只有一列,这是我们在此新列中添加后的结果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-O4k3wM69-1681367023163)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/cf51cf02-cb2b-482a-926d-a82c002a1490.png)]
我们将继续对数组进行数学运算。
带数组的算术和线性代数
现在,我们已经了解了如何使用 NumPy 数组创建和访问信息,让我们介绍一下可以对数组执行的一些数值运算。 在本节中,我们将讨论使用 NumPy 数组的算法。 我们还将讨论将 NumPy 数组用于线性代数。
两个形状相等的数组的算术
NumPy 数组的算术总是按组件进行的。 这意味着,如果我们有两个形状相同的矩阵,则通过匹配两个矩阵中的相应分量并将它们相加来完成诸如加法之类的操作。 对于任何算术运算都是如此,无论是加法,减法,乘法,除法,幂,甚至是逻辑运算符。
让我们来看一个例子。 首先,我们创建两个随机数据数组:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4f3ERKvP-1681367023163)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/f96b8cbf-5d45-451d-9f0e-d0c8ddc7ebf9.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CG5MUaWA-1681367023163)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/d298f336-cf3a-4f8c-81d0-5a0652967533.png)]
虽然我用涉及两个数组的算术方式解释了这些想法,但正如我们在此处看到的那样,它可能涉及数组和标量,我们将100添加到arr1中的每个元素中:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KbJP2bcW-1681367023163)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/eea17a05-7c4e-4196-8bb9-374f5efa7ab7.png)]
接下来,我们将arr1中的每个元素除以2:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kKYPkMp8-1681367023164)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/4c43d04b-0e78-4aeb-995a-2619bfbddf09.png)]
接下来,将arr1中的每个元素提升为2的幂:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9zuZQuEt-1681367023164)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/daba0abb-a6db-4245-8828-85a0b153641f.png)]
接下来,我们将arr1和arr2的内容相乘:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OZ5a9FCK-1681367023164)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/209966df-2b39-418f-8748-460afe369d74.png)]
请注意,arr1和arr2的形状相似。 在这里,我们进行了涉及这两个数组的更复杂的计算:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KBqHvncN-1681367023164)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/c0e90f0c-9107-4e67-acac-15aad71e9bd9.png)]
注意,此计算最终产生了inf和nan。
广播
到目前为止,我们已经处理了两个形状相同的数组。 实际上,这不是必需的。 尽管我们不一定要添加两个任意形状的数组,但是在某些情况下,我们可以合理地对不同形状的数组执行算术运算。 从某种意义上说,较小数组中的信息被视为属于相同形状但具有重复值的数组。 让我们看看实际的广播行为。
现在,回想一下数组arr1为3 x 3 x 3; 也就是说,它具有三行,三列和三个平板。 在这里,我们创建一个对象arr3:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FIjqn3y1-1681367023165)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/3933075d-3add-41e7-ab02-a7ddac1faf9e.png)]
该对象的形状为(1, 1, 3)。 因此,此对象的平板数与arr1相同,但只有一行和一列。 这是可以应用广播的情况; 实际上,这是结果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xMHFcfki-1681367023165)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/cc993b4c-c0a0-4b16-bbb7-a5fe7227e792.png)]
我将第 0 列和第 2 列设为 0,将中间列设为 1。因此,结果是我有效地选择了中间列并将其他两列设置为 0。有效地复制了该对象,因此好像我将arr1乘以一个对象一样,其中第一列为 0,第三列为 0,第二列为 1。
现在,让我们看看如果切换此对象的尺寸会发生什么? 因此,现在它具有一列,一个平板和三行:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-N5qc7zZo-1681367023165)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/0d30cbca-e184-4779-bc56-f5b2332b3943.png)]
结果如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4OnglQBs-1681367023165)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/7db3d7e3-45ce-48eb-bf0c-5890de4dee64.png)]
现在,让我们进行另一个换位。 我们将最终将一个具有三个平板的对象相乘,中间的平板由 1 填充。 因此,当我进行乘法运算时,会发生以下情况:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PwVGm1YD-1681367023166)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/e73ffc17-b8e1-4085-af9b-4e47e4d7e2c6.png)]
线性代数
请注意,NumPy 是为支持线性代数而构建的。 一维 NumPy 数组可以对应于线性代数向量; 矩阵的二维数组; 和 3D,4D 或所有ndarray到张量。 因此,在适当的时候,NumPy 支持线性代数运算,例如数组的矩阵乘积,转置,矩阵求逆等。linalg模块支持大多数 NumPy 线性代数函数。 以下是常用的 NumPy 线性代数函数的列表:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-511shsuv-1681367023166)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/947424be-4f60-4dc5-ab46-b64a30b26289.png)]
其中一些是ndarray方法,其他则在您需要导入的linalg模块中。 因此,我们实际上已经在较早的示例中演示了转置。 注意,我们在这里使用转置来在行和列之间交换。
这是arr4中的转置:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FtYvM3mC-1681367023166)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/f7a9f0cd-719f-4d06-bdda-0b7dc921a6e2.png)]
我说arr4是arr3,我们绕着轴切换。 因此,轴 0 仍将是轴 0,但轴 1 将是旧数组的轴 2,而轴 2 将是旧数组的轴 1。
现在,让我们看看其他示例。 让我们看一下重塑的演示。 因此,我们要做的第一件事是创建一个由八个元素组成的数组:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-O1HEEIVc-1681367023166)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/fbe3c803-540a-4bd0-8173-4a9a4cccb241.png)]
我们可以重新排列此数组的内容,使其适合其他形状的数组。 现在,需要的是新数组具有与原始数组相同数量的元素。 因此,创建一个2 x 4数组,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rvAygJWZ-1681367023167)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/9ff57a7c-299e-44f2-9aae-7bfbcba58140.png)]
与原始数组一样,它具有八个元素。 此外,它还创建了一个数组,其中第一行包含原始数组的前四个元素,第二行包含其余元素。 我可以用arr6做类似的操作:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3zlgzn85-1681367023167)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/e54f5721-61e0-4cac-9343-5b3a39c830f6.png)]
您可以通过查看此数组的逻辑方式来猜测。
现在让我们看一些更复杂的线性代数函数。 让我们从 Sklearn 库的数据集模块中加载一个名为load_iris的函数,以便我们可以查看经典的鸢尾花数据集:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sm7cY4pc-1681367023167)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/97bf54b1-56e6-4936-9afa-b1bf10da93a9.png)]
所以以下是iris的转置:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PWizNQCt-1681367023167)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/495b4cb9-950f-4685-ad2e-379f54cb1d08.png)]
复制此数组,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eVBX5Lkd-1681367023167)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/280c0309-eb08-4c7f-a163-d90d2c923790.png)]
我还想创建一个仅包含鸢尾花副本最后一列的新数组,并创建另一个包含其余列和全为 1 的列的数组。
现在,我们将创建一个与矩阵乘积相对应的新数组。 所以我说X平方是X转置并乘以X,这就是结果数组:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FuA4E79z-1681367023168)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/bf272c7e-734d-4e2c-8f2c-1d1e5d90038e.png)]
它是4 x 4。现在让我们得到一个逆矩阵X的平方。
这将是矩阵逆:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eninuexf-1681367023168)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/0f98403f-4fa3-4fba-aec1-c893f18addc5.png)]
然后,我取这个逆,然后将其乘以X的转置乘积与矩阵Y的乘积,矩阵Y是我之前创建的那个单列矩阵。 结果如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QTgvZTwt-1681367023168)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/793b3b23-eb4d-41b2-92a3-241e2ee05250.png)]
这不是任意的计算顺序; 它实际上对应于我们求解线性模型系数的方式。 原始矩阵y = iris_cp[:, 3]对应于我们要使用X的内容预测的变量的值; 但是现在,我只想演示一些线性代数。 当遇到的函数时,您现在就知道自己编写此函数所需的所有代码。
我们在数据分析中经常要做的另一件事是找到矩阵的 SVD 分解,并且在此线性代数函数中提供了 SVD 分解:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iWNYtauG-1681367023168)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/c1c9b11f-b590-4921-96da-160a30dde065.png)]
因此,最后一行对应于奇异值。 奇异值分解(SVD),输出中的值是矩阵的奇异值。 以下是左奇异向量:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zmi26AAJ-1681367023169)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/1a2c9e30-0d14-47a5-9583-c2d5824e7245.png)]
这些是正确的奇异向量:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MCbEWu7r-1681367023169)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/5d2aa92e-60d1-4e7f-89aa-f1a01dd3bb56.png)]
使用数组方法和函数
现在,我们将讨论 NumPy 数组方法和函数的使用。 在本节中,我们将研究常见的ndarray函数和方法。 这些函数使您可以使用简洁,直观的语法执行常规任务,而不仅仅是 Python 代码的概念。
数组方法
NumPy ndarray函数包含一些有助于完成常见任务的方法,例如查找数据集的均值或多个数据集的多个均值。 我们可以对数组的行和列进行排序,找到数学和统计量,等等。 有很多函数可以完成很多事情! 我不会全部列出。 在下面,我们看到了常见管理任务所需的函数,例如将数组解释为列表或对数组内容进行排序:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TmgqymHl-1681367023169)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/fcedd7e4-37bf-4748-811c-80ffbfad1457.png)]
接下来,我们将看到常见的统计和数学方法,例如查找数组内容的均值或总和:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ICBtBPf4-1681367023169)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/8621ecc1-012a-4343-9ec6-033da0ba19f1.png)]
我们还有一些用于布尔值数组的方法:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GzvZD7HG-1681367023169)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/568c19b3-e306-4a48-b0f2-5cc093b6422f.png)]
让我们在笔记本中查看其中一些。 导入 NumPy 并创建一个随机值数组:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-n9SnxBT7-1681367023170)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/af29b35f-17ce-4ac2-980c-159215be2517.png)]
让我们看看我们可以在此数组上执行的一些操作。 我们可以做的一件事是将数组强制为列表:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TpUNd304-1681367023170)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/ba2fae42-8863-4c5c-a04b-580ad14dc931.png)]
我们可以将数组展平,使其从4 x 4数组变为一维数组,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SQ3wIMAa-1681367023170)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/90aef03f-ec71-4f3d-80e8-2f9953006162.png)]
我们还可以使用fill方法填充一个空数组。 在这里,我创建了一个用于字符串的空数组,并用字符串Carlos填充了它:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GytVQzLI-1681367023171)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/8ed9442b-16e1-4ccc-a42a-888d6d544fa7.png)]
我们可以取一个数组的内容并将它们加在一起:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PJFjbl3q-1681367023171)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/02492999-327d-4bdf-8971-8cb6b456c737.png)]
它们也可以沿轴求和。 接下来,我们沿行求和:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-k8IMqaFW-1681367023171)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/0c5848ce-1041-4e75-86cd-ce2ff4feb9b1.png)]
在下面的内容中,我们沿列进行求和:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nEw9gZHP-1681367023171)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/05fda044-ecdf-4c1f-bfd4-a72be99ecdee.png)]
累积总和允许您执行以下操作,而不是对行的全部内容求和:
- 对第一行求和
- 然后将第一行和第二行相加
- 然后第一,第二和第三行
- 然后是第一第二,第三和第四行,依此类推
接下来可以看到:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qr5JMLDh-1681367023172)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/fefb42e0-e214-456a-b32a-74909478cd87.png)]
ufuncs的向量化
ufunc是专门用于数组的 NumPy 函数; 特别地,它们支持向量化。 向量化函数按组件方式应用于数组的元素。 这些通常是高度优化的函数,可以在较快的语言(例如 C)的后台运行。
在下面,我们看到一些常见的ufuncs,其中许多是数学上的:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-42jN8lfm-1681367023172)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/b61a65a6-9cb0-4d42-9085-38c799153d16.png)]
让我们来探讨ufuncs的一些应用。 我们要做的第一件事是找到arr1中每个元素的符号,即它是正,负还是零:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OBag2gCp-1681367023172)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/d2558b96-aa64-4e4a-83b0-7e9496a9dfdb.png)]
然后用这个符号,将该数组乘以arr1。 结果就好像我们取了arr1的绝对值:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NGhFAkBc-1681367023172)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/a9d4550c-b604-48c2-80d9-19b345d12f63.png)]
现在,我们找到产品内容的平方根。 由于每个元素都是非负的,因此平方根是明确定义的:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UNB1uqU4-1681367023172)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/ca953354-cd40-4edc-b718-2a94f81f88b8.png)]
自定义函数
如前所述,我们可以创建自己的ufuncs。 创建ufuncs的一种方法是使用现有的ufuncs,向量化操作,数组方法等(即 Numpy 的所有现有基础结构)来创建一个函数,该函数逐个组件地生成我们想要的结果。 假设由于某些原因我们不想这样做。 如果我们有一个现有的 Python 函数,而只想对该函数进行向量化处理,以便将其应用于ndarray组件,则可以使用 NumPy 的vectorize函数创建该函数的新向量化版本。 vectorize将函数作为输入,并将函数的向量化版本作为输出。
如果您不关心速度,可以使用vectorize,但是vectorize创建的函数不一定很快。 实际上,前一种方法(使用 NumPy 的现有函数和基础结构来创建您的向量化函数)可将ufuncs的生成速度提高许多倍。
我们要做的第一件事是定义一个适用于单个标量值的函数。 它的作用是截断,因此如果一个数字小于零,则该数字将替换为零:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PKWhjoQF-1681367023173)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/3ff39dbc-d824-4de3-8b8b-faf4e2a98576.png)]
此函数未向量化; 让我们尝试将此函数应用于矩阵arr1:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Z81ACqcn-1681367023173)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/04f9f215-dec1-4240-abf7-8eb57454d11e.png)]
然后,我们希望该矩阵中每个错误的数量都改为零。 但是,当我们尝试应用此函数时,它根本不起作用:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zVr484ot-1681367023173)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/6cc5d3ea-e108-4b80-84b6-60cc1a24d15f.png)]
我们需要做的是创建一个ufunc,其函数与原始函数相同。 因此,我们使用 vectorize 并可以创建可以按预期工作的向量化版本,但效率不高:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Y9et8uBh-1681367023173)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/bcddac11-fa34-4ee4-b31b-c01e539951bc.png)]
我们可以通过创建一个使用 NumPy 的现有基础架构的更快版本来看到这一点,例如基于布尔值的索引,并将值分配为零。 这是结果ufunc:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1D8uxX7F-1681367023174)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/380190d1-54f2-4971-8bef-0e5f9196d14b.png)]
让我们比较这两个函数的速度。 以下是使用vectorize创建的向量化版本:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UKmpgEdK-1681367023174)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/a4a3a475-cc94-4a82-88c4-06b7329e39c1.png)]
接下来是手动创建的一个:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Zdu21qb5-1681367023174)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/359ff8e0-9562-4334-a16a-10c1e7f6a1d1.png)]
请注意,第一个函数比手动创建的第二个函数要慢得多。 实际上,它慢了将近 10 倍。
总结
在本章中,我们从显式选择数组中的元素开始。 我们研究了高级索引编制和扩展数组。 我们还用数组介绍了一些算术和线性代数。 我们讨论了使用数组方法和函数以及ufuncs的向量化。 在下一章中,我们将开始学习另一个有影响力的包,称为 Pandas 。
四、Pandas 很有趣! 什么是 Pandas?
在之前的章节中,我们已经讨论过 NumPy。 现在让我们继续学习 pandas,这是一个经过精心设计的包,用于在 Python 中存储,管理和处理数据。 我们将从讨论什么是 Pandas 以及人们为什么使用 Pandas 开始本章。 接下来,我们将讨论 Pandas 提供的两个最重要的对象:序列和数据帧。 然后,我们将介绍如何子集您的数据。 在本章中,我们将简要概述什么是 Pandas 以及其受欢迎的原因。
Pandas 做什么?
pandas 向 Python 引入了两个关键对象,序列和数据帧,后者可能是最有用的,但是 pandas 数据帧可以认为是绑定在一起的序列。 序列是一序列数据,例如基本 Python 中的列表或一维 NumPy 数组。 而且,与 NumPy 数组一样,序列具有单个数据类型,但是用序列进行索引是不同的。 使用 NumPy 时,对行和列索引的控制不多; 但是对于一个序列,该序列中的每个元素都必须具有唯一的索引,名称,键,但是您需要考虑一下。 该索引可以由字符串组成,例如一个国家中的城市,而序列中的相应元素表示一些统计值,例如城市人口; 或日期,例如股票序列的交易日。
可以将数据帧视为具有公共索引的多个序列的公共长度,它们在单个表格对象中绑定在一起。 该对象类似于 NumPy 2D ndarray,但不是同一件事。 并非所有列都必须具有相同的数据类型。 回到城市示例,我们可以有一个包含人口的列,另一个包含该城市所在州或省的信息,还有一个包含布尔值的列,用于标识城市是州还是省的首都,仅使用 NumPy 来完成是一个棘手的壮举。 这些列中的每一个可能都有一个唯一的名称,一个字符串来标识它们包含的信息。 也许可以将其视为变量。 有了这个对象,我们可以轻松,有效地存储,访问和操纵我们的数据。
在下面的笔记本中,我们将预览可以使用序列和数据帧进行的操作:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yGGQOBme-1681367023174)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/1e8c0c05-3a69-4331-8685-aa11ae55feee.png)]
我们将同时加载 NumPy 和 pandas,我们将研究读取 NumPy 和 pandas 的 CSV 文件。 实际上,我们可以在 NumPy 中加载 CSV 文件,并且它们可以具有不同类型的数据,但是为了管理此类文件,您需要创建自定义dtype以类似于此类数据。 因此,这里有一个 CSV 文件iris.csv,其中包含鸢尾花数据集。
现在,如果我们希望加载该数据,则需要考虑以下事实:每一行的数据不一定都是同一类型的。 特别是最后一列是针对物种的,它不是数字,而是字符串。 因此,我们需要创建一个自定义dtype,在此处执行此操作,以调用此新的dtype模式:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FiTJTjZ7-1681367023175)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/d449f161-4900-4564-8b7a-5e2a7bf0edf7.png)]
我们可以使用 NumPy 函数loadtxt加载此数据集,将dtype设置为schema对象,并将定界符设置为逗号以指示它是 CSV 文件。 实际上,我们可以在以下位置读取此数据集:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HSQQO3nT-1681367023175)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/fb5ffbd9-5c83-4152-b50c-09c72d0f5704.png)]
请注意,此数据集必须在您的工作目录中。 如果我们看一下这个数据集,这将是我们注意到的:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RjWiThxo-1681367023175)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/b2367c9c-d37f-4737-8685-8f7c8a433fd4.png)]
此输出屏幕截图为,仅表示,实际输出包含更多行。 此数据集的每一行都是此一维 NumPy 数组中的新条目。 实际上,这是一个 NumPy 数组:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6w3g3K3s-1681367023175)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/7662a321-9cfa-465c-872a-90e359ee2026.png)]
我们使用以下命令选择前五行:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6kBHqOn9-1681367023175)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/5262fbb7-d8e0-4e99-b468-91dba378371a.png)]
我们可以选择前五行,并指定我们只希望使用隔片长度,它们是每行的第一元素:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-b6yhpac5-1681367023176)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/83e4c85b-b624-4086-9051-d2016421d13d.png)]
我们甚至可以选择花瓣的长度和种类:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-11hNJNDG-1681367023176)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/0d275bf1-2f8a-4b4f-841e-5120cf7579c4.png)]
但是有一种更好的方法可以对付 Pandas。 在 Pandas 中,我们将使用read_csv函数,该函数将自动正确解析 CSV 文件:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RsOQoQGJ-1681367023176)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/08a48a18-eac9-4788-b8f1-5aae1022d307.png)]
查看此数据集,请注意,使用 Jupyter 笔记本电脑,它的显示方式更加可读。 实际上,这是一个 pandas 数据帧:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-68ydtUg4-1681367023176)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/87068bb2-f619-4e2e-8b37-3ff5c460c85c.png)]
使用head函数可以看到前五行:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XRwCf3sj-1681367023176)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/47f9f523-1847-4fa6-b05c-b518d001c7df.png)]
通过将其指定为好像是此数据帧的一个属性,我们还可以看到其间隔长度:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ovzKdZoT-1681367023177)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/7da227f0-f566-4636-8681-f891a2bb2b7a.png)]
我们得到的实际上是一个序列。 我们可以选择此数据帧的一个子集,再次返回前五行,然后选择petal_length和species列:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VDvsUE26-1681367023177)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/abf8e8f5-aa1b-4c69-907d-cfe54d25b340.png)]
话虽如此,Pandas 的核心是建立在 NumPy 之上。 实际上,我们可以看到 pandas 用于描述其内容的 NumPy 对象:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bYHsyxFh-1681367023177)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/c65cf239-06de-4aaf-b417-7a5b18ee2682.png)]
实际上,我们之前创建的 NumPy 对象可用于构造 Pandas 数据帧:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WbevVusz-1681367023177)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/e88f7759-0724-4736-bac7-de4ab7fb85ce.png)]
现在是时候仔细看一下 Pandas 序列和数据帧了。
探索序列和数据帧对象
我们将开始研究 Pandas 序列和数据帧对象。 在本节中,我们将通过研究 Pandas 序列和数据帧的创建方式来开始熟悉它们。 我们将从序列开始,因为它们是数据帧的构建块。 序列是包含单一类型数据的一维数组状对象。 仅凭这一事实,您就可以正确地得出结论,它们与一维 NumPy 数组非常相似,但是与 NumPy 数组相比,序列具有不同的方法,这使它们更适合管理数据。 可以使用索引创建索引,该索引是标识序列内容的元数据。 序列可以处理丢失的数据; 他们通过用 NumPy 的 NaN 表示丢失的数据来做到这一点。
创建序列
我们可以从类似数组的对象创建序列; 其中包括列表,元组和 NumPy ndarray对象。 我们还可以根据 Python 字典创建序列。 向序列添加索引的另一种方法是通过将唯一哈希值的索引或类似数组的对象传递给序列的创建方法的index参数来创建索引。
我们也可以单独创建索引。 创建索引与创建序列很像,但是我们要求所有值都必须唯一。 每个序列都有一个索引。 如果我们不分配索引,则将从 0 开始的简单数字序列用作索引。 我们可以通过将字符串传递给该序列的创建方法的name参数来为该序列命名。 我们这样做是为了,如果我们要使用该序列创建一个数据帧,我们可以自动为该序列分配列名或行名,这样我们就可以知道该序列描述的日期。
换句话说,该名称提供了有用的元数据,我建议在合理范围内尽可能设置此参数。 让我们看一个可行的例子。 请注意,我们直接将序列和数据帧对象导入名称空间:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jd9F6YqZ-1681367023177)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/b2516bf8-dccd-41be-bf29-9dbbe26a3c22.png)]
我们经常这样做,因为这些对象已被详尽地使用。 在这里,我们创建两个序列,一个由数字1,2,3,4组成,另一个由字母a,b和c组成:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KpM4SQgH-1681367023178)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/ecf99f93-73a1-4895-ac0f-63bda88dbc28.png)]
请注意,索引已自动分配给这两个序列。
让我们创建一个索引; 该索引包含美国城市的名称:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Uj4BAfk9-1681367023178)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/24b34554-6143-4b05-85f8-3592e934bea6.png)]
我们将创建一个由pops组成的新序列,并将该索引分配给我们创建的序列。 这些城市的人口成千上万。 我从维基百科获得了这些数据。 我们还为该序列分配了名称Population。 结果如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FgAhqEUp-1681367023178)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/7d137c03-9a76-4029-a9f0-b06f8af92009.png)]
注意,我插入了一个缺失值; 这是Phoenix的人口,我们确实知道,但是我想添加一些额外的内容来进行演示。 我们也可以使用字典创建序列。 在这种情况下,字典的键将成为结果序列的索引,而值将是结果序列的值。 因此,在这里,我们添加state名称:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VkbCKLzq-1681367023178)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/0f40bfee-28c6-419a-ac7b-6f5f42b37b51.png)]
我还使用字典创建了一个序列,并在这些城市中填充了相应的区域:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7hoD8uvQ-1681367023179)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/25fd070e-296e-455d-a38c-0325591d2165.png)]
现在,我想提请您注意以下事实:这些序列的长度不相等,而且它们也不都包含相同的键。 它们并非全部或都包含相同的索引。 我们稍后将使用这些序列,因此请记住这一点。
创建数据帧
序列很有趣,主要是因为它们用于构建 pandas 数据帧。 我们可以将 pandas 数据帧视为将序列组合在一起以形成表格对象,其中行和列为序列。 我们可以通过多种方式创建数据帧,我们将在此处进行演示。 我们可以给数据帧一个索引。 我们还可以通过设置columns参数来手动指定列名。 选择列名遵循与选择索引名相同的规则。
让我们看看一些创建数据帧的方法。 我们要做的第一件事是创建数据帧,我们不会太在意它们的索引。 我们可以从 NumPy 数组创建一个数据帧:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4hXkYUF7-1681367023179)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/299f7640-bffc-4ad5-b4f4-4ae28afa3667.png)]
在这里,我们有一个三维 NumPy 数组,其中填充了数字。 我们可以简单地通过将该对象作为第一个参数传递给数据帧创建函数从该对象创建一个数据帧:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YASTO41Q-1681367023179)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/119801fe-cb4e-4579-9d7c-7b6e88c0b1ee.png)]
如果需要,可以向此DataFrame添加索引和列名:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KL9phtnI-1681367023179)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/7d5fa02d-ae75-4803-adf4-c00b47e4e973.png)]
我们从元组列表创建数据帧:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EhvvMMtB-1681367023179)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/18107d9f-204a-405e-b397-287510801717.png)]
我们也可以从dict创建数据帧:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QiwbCS6i-1681367023180)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/aa282d53-2377-44e2-9fa3-e87784e108db.png)]
现在,假设我们要创建一个数据帧并将一个字典传递给它,但是该字典不由长度相同的列表组成。 这将产生一个错误:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ShOyXj3r-1681367023180)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/34b2c99c-803f-4f06-8ec9-9e87c2ae3681.png)]
原因是需要将索引分配给这些值,但是函数不知道如何分配丢失的信息。 它不知道如何对齐这些列表中的数据。
但是,如果我们要传递一个字典(并且字典的值是不等长的序列,但是这些序列具有索引),则不会产生错误:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1FLTl9Zu-1681367023180)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/0bb83419-123b-489f-9b80-dd70ce1e6dd2.png)]
取而代之的是,由于它知道如何排列不同序列中的元素,因此它将这样做,并用 NaN 填充任何缺少信息的位置。
现在,让我们创建一个包含有关序列信息的数据帧,您可能还记得这些序列的长度不同。 此外,它们并非都包含相同的索引值,但是我们仍然能够从它们创建一个数据帧:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-B9wuZhmQ-1681367023180)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/1b83c6ff-184f-45ae-a02a-24d0d4e10930.png)]
但是,在这种情况下,这不是我们想要的数据帧。 这是错误的方向; 行是我们将解释为变量的内容,列是我们将解释为键的内容。 因此,我们可以在实际需要的方法中使用字典创建数据帧:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TMjw4VQn-1681367023180)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/bd1d3af6-ccfe-4d06-9da9-c2bb9d06c40c.png)]
或者我们可以像 NumPy 数组一样使用转置方法T方法来使数据帧处于正确的方向:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4pc481cw-1681367023181)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/96d001d2-c8b3-4668-8aed-7a384d1d5afe.png)]
新增数据
创建序列或数据帧之后,我们可以使用concat函数或append方法向其中添加更多数据。 我们将一个对象传递给包含将添加到现有对象中的数据的方法。 如果我们正在使用数据帧,则可以附加新行或新列。 我们可以使用concat函数添加新列,并使用dict,序列或数据帧进行连接。
让我们看看如何将新信息添加到序列或数据帧中。 例如,让我们在pops序列中添加两个新城市,分别是Seattle和Denver。 结果如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kN4MpF03-1681367023181)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/4d9bb80b-ddac-4e0d-9db1-dc6987b9425b.png)]
请注意,这尚未完成。 也就是说,返回了一个新序列,而不是更改现有序列。 我将通过使用所需数据创建一个数据帧来向该数据帧添加新行:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YblZXpco-1681367023181)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/696a8c03-b0af-4b8c-8390-98e16a8a1f34.png)]
我还可以通过有效地创建多个数据帧将新列添加到此数据帧。
我有一个列表,在此列表中,我有两个数据帧。 我有df,并且我有新的数据帧包含要添加的列。 这不会更改现有的数据帧,而是创建一个全新的数据帧,然后我们需要将其分配给变量:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BPMu0GBl-1681367023181)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/9d8d6515-f3c5-4035-964f-2da367628601.png)]
保存数据帧
假设我们有一个数据帧; 称它为df。 我们可以轻松保存数据帧的数据。 我们可以使用to_pickle方法对数据帧进行腌制(将其保存为 Python 常用的格式),并将文件名作为第一个参数传递。
我们可以使用to_csv保存 CSV 文件,使用to_json保存 JSON 文件或使用to_html保存 HTML 表。 还有许多其他格式可用; 例如,我们可以将数据保存在 Excel 电子表格,Stata,DAT 文件,HDF5 格式和 SQL 命令中,以将其插入数据库,甚至复制到剪贴板中。
稍后我们可能会讨论其他方法以及如何加载不同格式的数据。
在此示例中,我将数据帧中的数据保存到 CSV 文件中:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4bdTZ0kk-1681367023181)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/5283f0c0-1ce8-487b-a37b-1cf556a6a691.png)]
希望到目前为止,您对什么序列和数据帧更加熟悉。 接下来,我们将讨论在数据帧中设置数据子集,以便您可以快速轻松地获取所需的信息。
选取数据子集
现在我们可以制作 Pandas 序列和数据帧,让我们处理它们包含的数据。 在本节中,我们将看到如何获取和处理我们存储在 Pandas 序列或数据帧中的数据。 自然,这是一个重要的话题。 这些对象否则将毫无用处。
您不应该惊讶于如何对数据帧进行子集化有很多变体。 我们不会在这里涵盖所有特质; 请参考文档进行详尽的讨论。 但是,我们将讨论每个 Pandas 用户应该意识到的最重要的功能。
创建子序列
让我们首先看一下序列。 由于它们与数据帧相似,因此有一些适用的关键过程。 子集序列的最简单方法是用方括号括起来,我们可以这样做,就像我们将列表或 NumPy 数组子集化一样。 冒号运算符确实在这里工作,但我们还有更多工作要做。 我们可以根据序列的索引选择元素,而不是仅根据序列中元素的位置,遵循许多相同的规则,就好像我们使用指示序列中元素位置的整数一样。
冒号运算符也可以正常工作,并且在很大程度上符合预期。 选择两个索引之间的所有元素:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JLZPuwOI-1681367023182)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/89f8aa74-cb85-404d-a300-98786db9f47c.png)]
但是与整数位置不同,冒号运算符确实包含端点。 一个特别有趣的情况是使用布尔值建立索引时。 我将展示这种用法可能看起来像什么。 这样可以方便地获取特定范围内的数据。 如果我们可以得到类似数组的对象(例如列表,NumPy 数组或其他序列)来生成布尔值,则可以将该对象用于索引。 这是一些示例代码,展示了对索引序列的索引:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PGOIx0uJ-1681367023182)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/cacfc4fa-9a1a-44bc-ad71-14ad18d22094.png)]
到目前为止,整数索引以及布尔值索引的行为均符合预期:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UZQXi67i-1681367023182)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/e83b3582-4a47-40ce-a080-00ee3a1a74b4.png)]
唯一真正有趣的示例是当我们将冒号运算符与索引一起使用时; 请注意,所有起点和终点都包括在内,尤其是终点。 这与我们通常与冒号运算符关联的行为不同。 这是一个有趣的示例:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XPENDqQB-1681367023182)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/c6327805-7b1d-444f-a460-dbb14c237112.png)]
我们有一个序列,并且该序列具有index的整数,该整数的顺序不为 0 到 4。 现在,顺序混合了。 考虑我们要求的索引。 会发生什么? 一方面,我们可以说最后一个命令将基于索引进行选择。 因此它将选择元素 2 和 4; 他们之间什么都没有。 但另一方面,它可能会使用整数位置来选择序列的第三和第四元素。 换句话说,当我们从 0 开始计数时,它是位置 2 和位置 3,就像您希望将srs2视为列表一样。 哪种行为会占上风? 还不是很清楚。
索引方法
Pandas 提供的方法可以使我们清楚地说明我们要如何编制索引。 我们还可以区分基于序列索引值的索引和基于对象在序列中的位置的索引,就像处理列表一样。 我们将关注的两种方法是loc和iloc。loc专注于根据序列的索引进行选择,如果我们尝试选择不存在的关键元素,则会出现错误。iloc就像我们在处理 Python 列表一样建立索引; 也就是说,它基于整数位置进行索引。 因此,如果我们尝试在iloc中使用非整数进行索引,或者尝试选择有效整数范围之外的元素,则会产生错误。 有一种hybrid方法ix,其作用类似于loc,但是如果传递的输入无法针对索引进行解释,则它的作用将类似于iloc。 由于ix的行为模棱两可,因此我建议大多数时候坚持使用loc或iloc。
让我们回到我们的例子。 事实证明,在这种情况下,方括号的索引类似于iloc; 也就是说,它们基于整数位置进行索引,就好像srs2是一个列表一样。 如果我们想基于srs2的索引进行索引,则可以使用loc进行索引,以获得其他可能的结果。 再次注意,在这种情况下,两个端点都包括在内。 这与我们通常与冒号运算符关联的行为不同:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Egh7lRYc-1681367023183)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/fbd66516-62ee-411e-a047-fc38a67c14c5.png)]
切片数据帧
在讨论切片序列之后,让我们谈谈切片数据帧。 好消息是,在谈论序列切片时,许多艰苦的工作已经完成。 我们介绍了loc和iloc作为连接方法,但它们也是数据帧方法。 毕竟,您应该考虑将数据帧视为多个列粘合在一起的序列。
现在,我们需要考虑从序列中学到的知识如何转换为二维设置。 如果我们使用括号表示法,它将仅适用于数据帧的列。 我们将需要使用loc和iloc来对数据帧的行进行子集化。 实际上,这些方法可以接受两个位置参数。 根据我们前面描述的规则,第一个位置参数确定要选择的行,第二个位置参数确定要选择的列。 可以发出第二个参数来选择所有列,并将选择规则仅应用于行。 这意味着我们应该将第一个参数作为冒号,以便在我们选择的列中更加挑剔。
loc和iloc将在它们的两个参数上加上基于索引的索引或基于整数位置的索引,而ix可能允许混合使用此行为。 我不建议这样做。 对于后来的读者来说,结果太含糊了。 如果要混合loc和iloc的行为,建议使用方法链接。 也就是说,如果要基于索引选择行,而要基于整数位置选择列,请首先使用loc方法选择行,然后使用iloc方法选择列。 执行此操作时,如何选择数据帧的元素没有任何歧义。
如果您只想选择一列怎么办? 结果如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-n9cxiHqn-1681367023183)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/7a04ad57-6627-41aa-b93d-89bc0d95ef54.png)]
这样做很简捷; 只需将特定的列视为数据帧的属性,作为对象,使用点表示法有效地选择它即可。 这可以很方便:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5dAkBFbd-1681367023183)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/f049093d-84e8-473b-b2d4-765c08aa2744.png)]
请记住,Pandas 是从 NumPy 构建的,在数据帧的后面是 NumPy 数组。
因此,知道了您现在对 NumPy 数组所了解的知识后,以下事实对您来说就不足为奇了。 将数据帧的切片操作的结果分配给变量时,变量承载的不是数据的副本,而是原始数据帧中数据的视图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pyC9YIMI-1681367023183)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/279074fb-d4e4-44a0-8124-01b6a2813a02.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Gddfe7E4-1681367023184)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/1884861d-d8ae-4d16-ac15-c87f0b32b6c4.png)]
如果要制作此数据的独立副本,则需要使用数据帧的copy方法。 序列也是如此。
现在来看一个例子。 我们创建一个数据帧df,它具有有趣的索引和列名:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6sSDOIq8-1681367023184)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/1735a032-d079-4cfb-a7f1-af13d15f6d01.png)]
通过将第一列的名称视为df的属性,我可以轻松地获得一个表示第一列中数据的序列。 接下来,我们看到loc和iloc的行为。loc根据它们的索引选择行和列,但是iloc像选择列表一样选择它们。 也就是说,它使用整数位置:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eyXVTXBe-1681367023184)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/57648920-799d-4aa6-a581-faca79154bff.png)]
在这里,我们看到了方法链接。 对于输入 10,您可能会注意到它的开始类似于上一张幻灯片中的输入 9,但随后我在结果视图上调用了loc,以进一步细分数据。 我将此方法链接的结果保存在df2中。 我还用df2更改了第二列的内容,并用新的自定义数据的序列替换了它们:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XqcrZoYM-1681367023184)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/b2e51dc4-3b34-4a0e-b65a-714e5be57710.png)]
由于df2是df的独立副本,因此请注意,在创建df2时必须使用复制方法; 原始数据不受影响。 这使我们到达了重要的地步。序列和数据帧不是不可变的对象。 您可以更改其内容。 这类似于更改 NumPy 数组中的内容。 但是,在跨列进行更改时要小心; 它们可能不是同一数据类型,从而导致不可预测的结果。有时 :
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BVJ7b0Ot-1681367023185)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/683559b6-4034-4715-86ab-2024b20970c5.png)]
我们在这里看到什么分配:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nBm9P1p2-1681367023185)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/27c5c14f-fdfb-49e4-9bd2-843ad03d966e.png)]
这种行为与您在 NumPy 中看到的行为非常相似,因此我将不做过多讨论。 关于子集,还有很多要说的,特别是当索引实际上是MultiIndex时,但这是以后使用的。
总结
在本章中,我们介绍了 Pandas 并研究了它的作用。 我们探索了 Pandas 序列数据帧并创建了它们。 我们还研究了如何将数据添加到序列和数据帧中。 最后,我们介绍了保存数据帧。 在下一章中,我们将讨论算术,函数应用和函数映射。
五、Pandas 的算术,函数应用以及映射
我们已经看到了使用 pandas 序列和数据帧完成的一些基本任务。 让我们继续进行更有趣的应用。 在本章中,我们将重新讨论先前讨论的一些主题,这些主题涉及将算术函数应用于多元对象并处理 Pandas 中的缺失数据。
算术
让我们来看一个例子。 我们要做的第一件事是启动 pandas 和 NumPy。
在以下屏幕截图中,我们有两个序列,srs1和srs2:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6uRMyliw-1681367023185)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/1aeacb3c-603c-4ed2-9c3c-fa28e1475e16.png)]
srs1的索引从 0 到 4,而srs2的索引从 0 到 3,先跳过 4,然后再到 5。从技术上讲,这两个序列的长度是相同的,但是并不意味着这些元素将按照您的预期进行匹配。 例如,让我们考虑以下代码。 当我们添加srs1和srs2时会发生什么?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SM2chq3I-1681367023185)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/df0aba8d-49b9-405b-9348-dd6e2c3bbc92.png)]
产生了两个 NaN。 这是因为,对于元素 0 到 3,两个序列中都有可以匹配的元素,但是对于 4 和 5,两个序列中每个索引都有不等价的元素。 当我们相乘时也是如此,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xyAn8cMQ-1681367023186)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/448fed81-c330-4aee-8cf2-f2d721d9a7bb.png)]
或者,如果我们要求幂,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0sdzD7Y8-1681367023186)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/867566da-a87d-4d0d-8fde-48ede04cac77.png)]
话虽这么说,布尔运算是不同的。 在这种情况下,就像您通常期望的那样,逐个元素进行比较。 实际上,布尔比较似乎根本不关心索引,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-souYALNf-1681367023186)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/8e3523d4-b5c9-482e-afb8-fe0a5d9c81fb.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iASXS1u1-1681367023186)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/a5935cbe-4cb7-4b1b-b0eb-dc4eb10bd1d7.png)]
取srs2的平方根,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OAe7n6G8-1681367023186)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/145eb41c-4d14-4148-9eaa-af0613bae742.png)]
注意,该序列的索引已保留,但我们采用了该序列元素的平方根。 让我们以srs1的绝对值-再次为预期结果-并注意,我们可以确认这实际上仍然是一个序列,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uPMBkewS-1681367023187)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/f597919b-359d-4d02-a098-442b90b23121.png)]
现在,让我们应用自定义ufunc。 在这里,我们使用装饰器符号。 在下一个屏幕截图中,让我们看看使用此截断函数的向量化版本,数组然后将其应用于srs1时会发生什么,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eFRelQPm-1681367023187)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/f5d73fed-b5c3-49b0-8a7e-4c0f187c8be6.png)]
注意srs1(以前是 Pandas 序列)已不再是序列; 现在是 NumPy ndarray。 因此,该序列的索引丢失了。
计算srs1的平均值:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-G3Vw7idM-1681367023187)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/35d183da-9f09-4827-819a-c0d63c267e43.png)]
或标准偏差,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-itWSOfii-1681367023187)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/b307a410-27be-41db-bad9-9e3aad4331e4.png)]
最大元素,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VxGqPO5I-1681367023188)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/817ba0ef-aabf-4e7e-b644-ea18c778b5a5.png)]
或最大元素所在的位置,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YdQWP3zq-1681367023188)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/7a6b49ea-ccf9-4257-8ce2-7f6fc1d706a9.png)]
或累加和,连续创建序列的元素:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vcroukE1-1681367023188)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/52644228-88c6-44db-b6ce-d6b69b599d7d.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5mY5ajWP-1681367023188)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/3fa02489-e851-43ae-8a6c-3f9d4440aca9.png)]
现在,让我们谈谈函数应用和映射。 这类似于我们之前定义的截断函数。 我正在使用lambda表达式创建一个临时函数,然后将该临时函数应用于srs1的每个元素,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tON6TJTa-1681367023188)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/4ab5fcba-1a5b-4fc6-92fb-f0c3d827aa87.png)]
我们可以定义一个向量化函数来执行此操作,但是请注意,通过使用apply,我们设法保留了序列结构。 让我们创建一个新序列srs3,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-s2c3Gx1I-1681367023189)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/6448ba68-fdf2-4c13-9aa9-74dd95d66292.png)]
让我们看看当我们有了字典并将srs3映射到字典时会发生什么。 请注意,srs3的元素对应于字典的键。 因此,当我们映射时,我最终得到的是另一个序列,并且对应于由序列映射查找的键的字典对象的值如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WJ1bpCb1-1681367023189)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/8b1383d6-61e6-469b-b2ba-9120749a47b9.png)]
这也适用于函数,例如应用方式。
数据帧的算术
数据帧之间的算术与序列或 NumPy 数组算术具有某些相似之处。 如您所料,两个数据帧或一个数据帧与一个缩放器之间的算术工作; 但是数据帧和序列之间的算术运算需要谨慎。 必须牢记的是,涉及数据帧的算法首先应用于数据帧的列,然后再应用于数据帧的行。 因此,数据帧中的列将与单个标量,具有与该列同名的索引的序列元素或其他涉及的数据帧中的列匹配。 如果有序列或数据帧的元素找不到匹配项,则会生成新列,对应于不匹配的元素或列,并填充 Nan。
数据帧和向量化
向量化可以应用于数据帧。 给定一个数据帧时,许多 NumPy ufuncs(例如平方根或sqrt)将按预期工作; 实际上,当给定数据帧时,它们仍可能返回数据帧。 也就是说,这不能保证,尤其是在使用通过vectorize创建的自定义ufunc时。 在这种情况下,他们可能会返回ndarray。 虽然这些方法适用于具有通用数据类型的数据帧,但是不能保证它们将适用于所有数据帧。
数据帧的函数应用
毫不奇怪,数据帧提供了函数应用的方法。 您应注意两种方法:apply和applymap。apply带有一个函数,默认情况下,将该函数应用于与数据帧的每一列相对应的序列。 产生的内容取决于函数的功能。 我们可以更改apply的axis参数,以便将其应用于行(即跨列),而不是应用于列(即跨行)。applymap具有与应用不同的目的。 鉴于apply将在每一列上求值提供的函数,因此应准备接收序列,而applymap将分别在数据帧的每个元素上求值pass函数。
我们可以使用apply函数来获取所需的数量,但是使用数据帧提供的现有方法通常更有用,并且也许更快。
让我们看一些使用数据帧的演示。 与该序列一起使用的许多技巧也可以与数据帧一起使用,但有些复杂。 因此,让我们首先创建一个数据帧,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PamRg4wC-1681367023189)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/e8841530-cc52-4365-84bb-3556f47f7939.png)]
这里我们从另一个数据帧中减去一个数据帧:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8h0LIYmt-1681367023189)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/db6f0435-908f-48a7-900d-c9f8f6f31668.png)]
还有一些使用数据帧的有用方法。 例如,我们可以取每列的平均值,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3h1aCa4m-1681367023190)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/57047275-afc2-4675-9003-3b060c5e36c1.png)]
或者我们可以找到每列的标准偏差,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-O75ZRF5O-1681367023190)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/b5e9c90a-680c-4125-a367-6c8439b80f64.png)]
另一个有用的技巧是标准化每列中的数字。 现在,df.mean和df.std返回一个序列,所以我们实际上要做的是减去一个序列,然后除以一个序列,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bNGgGNRc-1681367023190)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/441b9928-2a05-4868-bef2-ceda07302961.png)]
现在让我们看一下向量化。 平方根函数是 NumPy 的向量化函数,可在数据帧上按预期工作:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SpLb5CMu-1681367023190)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/abd19d26-34d7-4089-813c-fc8eaf08dae6.png)]
还记得自定义ufunc trunk吗? 它不会给我们一个数据帧,但是它将求值并返回类似于数据帧的内容,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dDrKzOHr-1681367023190)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/c76fa618-cc00-44e4-8fd6-1fb7808165e3.png)]
但是,在混合数据类型的数据帧上运行时,这将产生错误:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JPG8ajA3-1681367023191)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/24b88976-04a0-4203-ad18-8c4840e60822.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YhhilxeM-1681367023191)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/6ecdcc63-b265-4f5a-ac83-1894df73affd.png)]
这就是为什么您需要小心的原因。 现在,在这里,我将向您展示避免混合数据类型问题的技巧。 注意,我使用的是我以前未介绍过的方法select_dtypes。 这将是选择具有特定dtype的列。 在这种情况下,我需要数字dtype的列:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-O7WIPd4p-1681367023191)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/1ce252a9-f718-458c-a3c7-cad5666aca4a.png)]
请注意,排除了由字符串数据组成的第三列。 因此,当我取平方根时,除了负数外,它都可以正常工作:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PjNEbmBe-1681367023191)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/28fbf5d6-c9e9-40e1-b003-9fc26681f2ce.png)]
现在,让我们看一下函数的应用。 在这里,我将定义一个函数,该函数计算所谓的[HTG1]几何平均值。 因此,我要做的第一件事是定义一个几何mean函数:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2tcWDNm1-1681367023191)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/6a665d98-3b5c-479b-a752-3b2f7c87e09c.png)]
我们将此函数应用于数据帧的每一列:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-S7Y2eDMN-1681367023192)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/4d3ab7da-ec1c-4aae-bb9f-6907c8f1759c.png)]
我展示的最后一个技巧是applymap,在该示例中,我演示了此函数如何与用于截断函数的新 lambda 一起工作,这次是在3处截断:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wgITwUSr-1681367023192)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/13e089b1-bc2f-4fa7-8503-c0d1492ae320.png)]
接下来,我们将讨论解决数据帧中丢失数据的方法。
处理 Pandas 数据帧中的丢失数据
在本节中,我们将研究如何处理 Pandas 数据帧中的丢失数据。 我们有几种方法可以检测对序列和数据帧都有效的缺失数据。 我们可以使用 NumPy 的isnan函数; 我们还可以使用序列和数据帧提供的isnull或notnull方法进行检测。 NaN 检测对于处理丢失信息的自定义方法可能很有用。
在本笔记本中,我们将研究管理丢失信息的方法。 首先,我们生成一个包含缺失数据的数据帧,如以下屏幕截图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qwfT6liN-1681367023192)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/71e4866d-1e34-4072-9f30-66daeba42910.png)]
如之前在 Pandas 中提到的,缺失的信息由 NumPy 的 NaN 编码。 显然,这不一定是到处编码丢失的信息的方式。 例如,在某些调查中,丢失的数据由不可能的数值编码。 假设母亲的孩子人数为 999; 这显然是不正确的。 这是使用标记值指示缺少信息的示例。
但是在这里,我们仅使用使用 NaN 表示缺失数据的 Pandas 约定。 我们还可以创建一个缺少数据的序列。 下一个屏幕截图显示了该序列:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xqUtMmyN-1681367023192)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/41acc8cd-2f05-4868-82ef-7f69e42a6562.png)]
让我们看一些检测丢失数据的方法。 这些方法将产生相同的结果或完全矛盾的结果。 例如,我们可以使用 NumPy 的isnan函数返回一个数据帧,如果数据为 NaN 或丢失,则返回true,否则返回false:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5jOySMGq-1681367023192)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/637b576a-8f40-4a7f-86e1-17f3e4bd65a5.png)]
isnull方法做类似的事情; 只是它使用了数据帧方法而不是 NumPy 函数,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vzQ7RPIk-1681367023193)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/6f31c997-41ea-4863-bbea-39fc8e9fb8a3.png)]
notnull函数基本上与isnull函数完全相反; 缺少数据时返回false,不丢失数据时返回true,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Y24JoLCt-1681367023193)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/2696fb61-724d-4539-a2ff-062ff73ea35f.png)]
删除缺失的信息
序列和数据帧的dropna可用于创建对象的副本,其中删除了丢失的信息行。 默认情况下,它将删除缺少任何数据的行,并且与序列一起使用时,它将使用 NaN 消除元素。 如果要适当完成此操作,请将inplace参数设置为true。
如果我们只想删除仅包含缺少信息的行,因此不删除任何使用信息,则可以将how参数设置为全部。 默认情况下,此方法适用于行,但如果要更改其适用于列,则可以将access参数设置为 1。
这是我们刚才讨论的示例。 让我们使用此数据帧df,并删除存在缺失数据的所有行:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4zysMMDZ-1681367023193)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/197cde54-08db-4810-a7fc-409118152df4.png)]
注意,我们大大缩小了数据帧的大小; 只有两行仅包含完整信息。 我们可以对该序列做类似的事情,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IYulqa4T-1681367023193)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/c7c3c7cf-7299-478e-8790-72fb39547812.png)]
有时,在计算某些指标时会忽略掉丢失的信息。 例如,在计算特定指标(例如均值,总和,标准差等)时,简单地排除丢失的信息根本没有问题。 尽管可以更改参数来控制此行为(可能由skipna之类的参数指定),但是默认情况下,这是由许多 pandas 方法完成的。 当我们尝试填充丢失的数据时,此方法可能是一个很好的中间步骤。 例如,我们可以尝试用非缺失数据的平均值填充一列中的缺失数据。
填充缺失的信息
我们可以使用fillna方法来替换序列或数据帧中丢失的信息。 我们给fillna一个对象,该对象指示该方法应如何替换此信息。 默认情况下,该方法创建一个新的数据帧或序列。 我们可以给fillna一个值,一个dict,一个序列或一个数据帧。 如果给定单个值,那么所有指示缺少信息的条目将被该值替换。dict可用于更高级的替换方案。dict的值可以对应于数据帧的列;例如, 可以将其视为告诉如何填充每一列中的缺失信息。 如果使用序列来填充序列中的缺失信息,那么过去的序列将告诉您如何用缺失的数据填充序列中的特定条目。 类似地,当使用数据帧填充数据帧中的丢失信息时,也是如此。
如果使用序列来填充数据帧中的缺失信息,则序列索引应对应于数据帧的列,并且它提供用于填充该数据帧中特定列的值。
让我们看一些填补缺失信息的方法。 例如,我们可以尝试通过计算其余数据集的均值来填充缺失的信息,然后用均值填充该数据集中的缺失数据。 在下一个屏幕截图中,我们可以看到用零填充缺失的信息,这是一种非常粗糙的方法:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-20G80am9-1681367023193)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/26a9b0fd-8645-4b49-beff-880483d95509.png)]
更好的方法是用均值填充丢失的数据,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gwgjdBqA-1681367023194)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/b33b50a1-978b-43c7-8e95-cd4c1adbb7b0.png)]
但是请注意,有些事情可能并不相同。 例如,尽管新数据集的均值与丢失的信息的均值与原始数据集的均值相同,但将原始数据集的标准差与新数据集的标准差进行比较,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jLJ7Nwsd-1681367023194)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/156eb4f0-ac74-4705-8e3b-141e5f21ad48.png)]
标准偏差下降; 这方面没有保留。 因此,我们可能要使用其他方法来填写丢失的信息。 也许,尝试这种方法的方法是通过随机生成均值和标准差与原始数据相同的数据。 在这里,我们看到了一种类似于自举统计技术的技术,在该技术中,您从现有数据集中重新采样以在模拟数据集中模拟其属性。 我们首先生成一个全新的数据集,一个从原始序列中随机选择数字的序列,并作为缺失数据的索引,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Tfc9OdPt-1681367023194)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/91abdaf5-a983-436d-868f-c5daf34c6387.png)]
然后,该序列用于填写原始序列的缺失数据:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EADGNfqA-1681367023194)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/faeafaf8-4b95-4352-8c2d-b332f87c1b7d.png)]
条目 5 和 7 对应于用于填写缺失数据的序列。 现在让我们计算均值,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OclFy599-1681367023195)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/027ca51a-884d-4dbd-a2b6-da8948177773.png)]
均值和标准差都不相同,但是至少与标准差相比,这些均值与原始均值和标准差之间的差异并不像以前那么严重。 现在,很明显有了随机数,只有大样本量才能保证。
让我们看一下在数据帧中填充缺少的信息。 例如,这是以前使用的数据帧,在这里我们用 0 填写丢失的数据:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-G6Tzxj3i-1681367023195)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/b0dea539-9856-45c9-9bc8-ce4e0639d741.png)]
现在,您当然会认为数字 0 有问题,所以让我们看一下也许用列均值填充丢失的数据。 这样做的命令可能类似于以下内容:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Tfv6Qsuw-1681367023195)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/56068f38-ce8f-49a7-8a36-5bf7c17debb7.png)]
但是要注意一些事情; 当我们使用这种方法来填写缺失的数据时,标准偏差都比以前降低了!
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jrANkTZ7-1681367023195)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/46a1feee-8b13-4107-8818-cc7aebe8d755.png)]
我们将尝试之前尝试过的引导技巧。 我们将使用字典或dict填充缺少的信息。 我们将创建一个dict,其中每个列均包含一个序列,而该序列在数据帧中缺少信息,这些序列将类似于我们先前生成的序列:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qy6i7C1W-1681367023195)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/c0f583f9-cdfd-4384-b0bb-8ed5b2321b68.png)]
然后,使用此字典中包含的数据填充缺少的信息:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-62ovXy4V-1681367023196)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/d6fdf0c4-422a-45b1-9930-ab0a0784a7e5.png)]
注意均值和标准偏差之间的关系:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2LMAOuy6-1681367023196)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/c90d4236-1ea9-4d4d-b221-4ad6e8ec27f9.png)]
总结
在本章中,我们介绍了 Pandas 数据帧,向量化和数据帧函数应用的算术运算。 我们还学习了如何通过删除或填写缺失的信息来处理 pandas 数据帧中的缺失数据。 在下一章中,我们将研究数据分析项目中的常见任务,排序和绘图。
六、排序,索引和绘图
现在让我们简要介绍一下使用 pandas 方法对数据进行排序。 在本章中,我们将研究排序和排名。 排序是将数据按各种顺序排列,而排名则是查找数据如果经过排序将位于哪个顺序中。 我们将看看如何在 Pandas 中实现这一目标。 我们还将介绍 Pandas 的分层索引和绘图。
按索引排序
在谈论排序时,我们需要考虑我们到底要排序什么。 有行,列,它们的索引以及它们包含的数据。 让我们首先看一下索引排序。 我们可以使用sort_index方法重新排列数据帧的行,以使行索引按顺序排列。 我们还可以通过将sort_index的访问参数设置为1来对列进行排序。 默认情况下,排序是按升序进行的; 后几行的值比前几行大,但是我们可以通过将sort_index值的升值设置为false来更改此行为。 这按降序排序。 默认情况下,此操作未就位。 为此,您需要将sort_index的就地参数设置为true。
虽然我强调了对数据帧进行排序,但是对序列进行排序实际上是相同的。 让我们来看一个例子。 加载 NumPy 和 pandas 之后,我们创建一个数据帧并带有要排序的值,如以下屏幕快照所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hosEyx7q-1681367023196)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/33d3bbe7-bd54-4ad3-a776-44859ef39984.png)]
让我们对索引进行排序; 请注意,这没有就位:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-slJ3zbkD-1681367023197)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/37c19d95-295f-4662-9b9e-a5aafc6120f5.png)]
这次我们将列排序 ,我们将通过设置ascending=False来反向排列它们; 因此第一列现在是CCC,最后一列是AAA,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dOf3hC7o-1681367023197)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/02543552-9690-4d59-a8f0-62940f0f83c7.png)]
按值排序
如果我们希望对数据帧的行或元素序列进行排序,则需要使用sort_values方法。 对于序列,您可以致电sort_values并每天致电。 但是,对于数据帧,您需要设置by参数; 您可以将by设置为一个字符串,以指示要作为排序依据的列,或者设置为字符串列表,以指示列名称。 根据该列表的第一列,将首先进行的排序; 然后,当出现领带时,将根据下一列进行排序,依此类推。
因此,让我们演示其中一些排序技术。 我们根据AAA列对数据帧的值进行排序,如以下屏幕截图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IViOKZHm-1681367023197)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/4c278caa-05d2-4442-9047-9d4936e5b7e5.png)]
请注意,AAA中的所有条目现在都是按顺序排列的,尽管其他列的内容不多。 但是我们可以使用以下命令根据BBB排序并根据CCC打破平局。 结果如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-j5WzUUYE-1681367023198)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/4457a7af-f3ae-44d5-9d2e-7b4113ea14b1.png)]
排名告诉我们如果元素按顺序排列将如何显示。 我们可以使用rank 方法来查找序列或数据帧中元素的排名。 默认情况下,排名是按升序进行的; 将升序参数设置为false可更改此设置。 除非发生联系,否则排名很简单。 在这种情况下,您将需要一种确定排名的方法。 有四种处理联系的方法:平均值,最小值,最大值和第一种。 平均值给出平均等级,最小值赋予尽可能低的等级,最大值赋予尽可能最高的等级,然后首先使用序列中的顺序打破平局,以使它们永远不会发生。 当在数据帧上调用时,每一列都将单独排名,结果将是一个包含等级的数据帧。 现在,让我们看看这个排名。 我们要求df中条目的排名,这实际上是结果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-crL4YaVp-1681367023198)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/1468e55d-f480-4e84-94d6-f9459e425cf1.png)]
注意,我们看到了此数据帧每个条目的排名。 现在,请注意这里有一些联系,特别是对于列CCC的条目e和条目g。 我们使用平均值来打破平局,这是默认设置,但是如果我们愿意,可以将其设置为max,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-04YeTHcM-1681367023198)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/414d3e3a-a998-403b-8c50-58aabf720bda.png)]
结果,这两个都排在第五位。 接下来,我们讨论分层索引。
分层索引
我们已经走了很长一段路,但是还没有完成。 我们需要谈论分层索引。 在本节中,我们研究层次索引,为何有用,如何创建索引以及如何使用它们。
那么,什么是层次结构索引? 它们为索引带来了额外的结构,并以MultiIndex类对象的形式存在于 Pandas 中,但它们仍然是可以分配给序列或数据帧的索引。 对于分层索引,我们认为数据帧中的行或序列中的元素由两个或多个索引的组合唯一标识。 这些索引具有层次结构,选择一个级别的索引将选择具有该级别索引的所有元素。 我们可以走更理论的道路,并声称当我们有MultiIndex时,表格的尺寸会增加。 它的行为不是作为存在数据的正方形,而是作为多维数据集,或者至少是可能的。
当我们想要索引上的其他结构而不将该结构视为新列时,将使用分层索引。 创建MultiIndex的一种方法是在 Pandas 中使用MultiIndex对象的初始化方法。 我们也可以在创建 Pandas 序列或数据帧时隐式创建MultiIndex,方法是将列表列表传递给index参数,每个列表的长度与该序列的长度相同。 两种方法都是可以接受的,但是在第一种情况下,我们将有一个index对象分配给序列或要创建的数据帧。 第二个是同时创建序列和MultiIndex。
让我们创建一些层次结构索引。 导入 Pandas 和 NumPy 之后,我们直接使用MultiIndex对象创建MultiIndex。 现在,这种表示法可能有点难以理解,因此让我们创建该索引并解释刚刚发生的情况:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WfzcTqG2-1681367023199)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/70dbf80f-d9e4-4b0c-9b4e-f1781334acc2.png)]
在这里,我们指定索引的级别,即MultiIndex可以取的可能值。 因此,对于第一级,我们有a和b; 对于第二级,alpha和beta; 对于第三级,1和2。 然后,我们为MultiIndex的每一行分配采用这些级别中的哪个级别。 因此,此第一列表的每个零指示值a,此列表的每个零指示值b。 然后第二个列表中的alpha为零,beta为。 在第三列表中,为零,2为零。 因此,在将midx分配给序列索引后,最终得到该对象。
创建MultiIndex的另一种方法是直接在创建我们感兴趣的序列时使用。这里,index参数已传递了多个列表,每个列表都是MulitIndex的一部分。
第一行用于MulitIndex的第一级,第二行用于第二级,第三行用于第三级。 这与我们在较早的情况下所做的非常相似,但是没有明确定义级别,然后定义该序列的每个值中的哪个级别,我们只需要输入我们感兴趣的值即可:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ck5i4caV-1681367023199)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/dadcad3c-8f00-45d4-ba0d-91916abb6ea0.png)]
注意,这些产生相同的结果。
切片带有分层索引的序列
在切片时,序列的层次索引类似于 NumPy 多维数组。 例如,如果使用方括号访问器,我们只需用逗号分隔层次结构索引的级别,然后对每个级别进行切片,就可以想象它们是某些高维对象各个维度的单独索引。 这适用于loc方法和序列,但不适用于数据帧; 我们待会儿再看。 使用loc时,切片索引时所有常用的技巧仍然有效,但是切片操作获得多个结果会更容易。
因此,让我们看一下实际操作中的MultiIndex序列。 我们要做的第一件事是切片第一层,仅选择第一层为b的那些元素; 结果是:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-v5aA3kqf-1681367023199)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/a2f577d5-3e7b-4b0c-a69f-a920b7b281d5.png)]
然后我们将其进一步缩小到b和alpha; 结果如下。 这将是该序列的alpha片段(在前面的屏幕截图中):
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RAjCOWk2-1681367023199)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/94bc6803-df54-4698-b805-d69926fa1629.png)]
然后我们进一步选择它,因此如果要选择本序列的一个特定元素,我们必须走三个层次,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qF1LSb7L-1681367023200)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/19405c15-5873-4d9d-ae42-c0b3a4c12b89.png)]
如果我们希望选择序列中的每个元素,例如第一个级别为a,最后一个级别为1,则需要在中间放置一个冒号,以表示我们不在乎是否有alpha或beta,结果如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SC6mUUYP-1681367023200)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/30953bfe-5eeb-44d6-99d3-989faddb675d.png)]
当为数据帧提供层次结构索引时,我们仍然可以使用loc方法进行索引,但是这样做比序列更为棘手。 毕竟,我们不能用逗号分隔索引的级别,因为我们有第二维,即列。 因此,我们使用元组为切片数据帧的维度提供了说明,并提供了指示如何进行切片的对象。 元组的每个元素可以是数字,字符串或所需元素的列表。
使用元组时,我们不能真正使用冒号表示法。 我们将需要依靠切片器。 我们在这里看到如何复制切片器常用的一些切片符号。 我们可以将这些切片器传递给用于切片的元组的元素,以便我们可以执行所需的切片操作。 如果要选择所有列,我们仍然需要在loc中列的位置提供一个冒号。 自然,我们可以用更具体的切片方法(例如列表或单个元素)替换切片器。 现在,我从未谈论过如果列具有层次结构索引会发生什么情况。 这是因为过程本质上是相同的-因为列只是不同轴上的索引。
因此,现在让我们看一下管理附加到数据帧的层次结构索引。 我们要做的第一件事是创建带有分层索引的数据帧。 然后,我们选择该索引的第一级为b的所有行。 我们得到以下结果,这并不太令人震惊:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LUoFwH1h-1681367023200)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/4b156f08-6720-43af-a387-e617b557935d.png)]
然后我们通过缩小b和alpha进行重复,但是请注意,我们现在必须使用元组以确保alpha不会被解释为我们感兴趣的列,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pdM4RKN7-1681367023200)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/f74b545c-a6ea-4a41-9c60-bc62f6398d08.png)]
然后,我们进一步缩小范围,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mVN2otPJ-1681367023200)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/9828715b-96c1-42d7-bf4b-356f1f0ed2e0.png)]
现在,让我们尝试复制以前做过的一些事情,但是请记住,我们在这里不能再使用冒号了。 我们必须使用切片器。 因此,我们将在此处使用的切片调用与srs.loc['b', 'alpha', 1]中使用的切片调用相同。 我说slice(None),这基本上意味着选择第二级中的所有内容:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wWxSuhc7-1681367023201)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/ae2b35bb-a049-49cf-814e-c77641a998fd.png)]
如果要选择所有列,则必须在列的位置放一个冒号。 否则将引发错误。 在这里,我们将执行等效于使用:'b'的操作,因此我们从一开始就选择b。 结果如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nljNOo2l-1681367023201)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/db82b410-e537-4c22-af0d-0715f05bc5d3.png)]
最后,我们选择第一级中的所有内容,然后选择第二级中的所有内容,但是我们仅在第三级中选择,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0fifpmsF-1681367023201)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/150ccf4a-ec53-4af4-91a3-f0958de9c33b.png)]
并注意,我们也一直在将索引调用传递给列,因为这是一个完全独立的调用。 现在,我们继续使用 Pandas 提供的绘图方法。
用 Pandas 绘图
在本节中,我们将讨论 pandas 序列和数据帧提供的绘图方法。 您将看到如何轻松快速地创建许多有用的图。 Pandas 尚未提出完全属于自己的绘图功能。 相反,使用 pandas 方法从 pandas 对象创建的图只是对称为 Matplotlib 的绘图库进行更复杂调用的包装。 这是科学 Python 社区中众所周知的库,它是最早的绘图系统之一,也许是最常用的绘图系统,尽管其他绘图系统正在寻求替代它。
它最初是由 MATLAB 随附的绘图系统启发的,尽管现在它是它自己的野兽,但不一定是最容易使用的。 Matplotlib 具有许多功能,在本课程中,我们将只涉及其绘制的表面。 在本节中,我们将讨论在特定实例之外使用 Python 进行可视化的程度,即使可视化是从初始探索到呈现结果的数据分析的关键部分。 我建议寻找其他资源以了解有关可视化的更多信息。 例如,Packt 有专门针对该主题的视频课程。
无论如何,如果我们希望能够使用 pandas 方法进行绘图,则必须安装 Matplotlib 并可以使用。 如果您正在使用 Jupyter 笔记本或 Jupyter QtConsole 或其他基于 IPython 的环境,则建议运行pylab魔术。
绘图方法
关键的 pandas 对象,序列和数据帧提供了一种绘图方法,简称为plot。 它可以轻松地创建图表,例如折线图,散点图,条形图或所谓的核密度估计图(用于了解数据的形状) , 等等。 可以创建许多图。 我们可以通过将plot中的kind参数设置为字符串来控制所需的绘图,以指示所需的绘图。 通常,这会产生一些带有通常选择的默认参数的图。 通过在plot方法中指定其他参数,我们可以更好地控制最终输出,然后将这些参数传递给 Matplotlib。 因此,我们可以控制诸如标签,绘图样式,x 限制,y 限制,不透明度和其他详细信息之类的问题。
存在用于创建不同图的其他方法。 例如,序列有一个称为hist的方法来创建直方图。
在本笔记本中,我将演示一些图形。 我要做的第一件事是在pandas中加载,并且我将使用pylab魔术(带有参数inline的 Matplotlib 魔术),以便我们可以在创建它们的那一刻看到绘图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-35mdN92M-1681367023202)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/c472ddcb-ba3b-40b5-8bba-a9997d2ab6ed.png)]
现在,我们创建一个包含三个随机游走的数据帧,这是概率论中研究和使用的一个过程。 可以通过创建标准的正常随机变量,然后对其进行累加总和来生成随机游动,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hZzQmrRv-1681367023202)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/d7ae015a-e31b-4ed2-84de-43c2c61c3af8.png)]
我们使用head方法仅查看前五行。 这是了解数据集结构的好方法。 那么,这些地块是什么样的? 好吧,让我们创建一个可视化它们的折线图,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-07ZwGvSA-1681367023202)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/77895404-17e4-46e0-ad77-5aeb36b9051e.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uRiCGqE9-1681367023202)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/c4314631-cb23-4d2c-bf5a-18c81da12168.png)]
这些只是上下随机运动。 请注意,plot方法会自动生成一个键和一个图例,并为不同的线分配颜色,这些线与我们要绘制的数据帧的列相对应。 让我们看一下该序列的图,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NiG9odyA-1681367023203)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/a9f2ddad-23fa-4e90-a86d-bda81a76c508.png)]
它有些先进,但是您可以看到,我们仍然可以使用序列创建这些图。
让我们指定一个参数ylim,以使该序列中绘图的比例与该数据帧的绘图的比例相同,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6OKUFi56-1681367023203)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/557c70de-1db8-4e6f-9a9b-0bf5cd2d3d48.png)]
现在让我们看一些不同的绘图。 在下一个屏幕截图中,让我们看一下该序列中值的直方图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rbfsirUD-1681367023203)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/2e7285e5-5f0b-44f3-801a-f7d89021ab49.png)]
直方图是确定数据集形状的有用方法。 在这里,我们看到一个大致对称的钟形曲线形状。
我们还可以使用plot方法创建直方图,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Jvxu3O3b-1681367023203)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/8d05d1b8-215e-40ef-8050-efe87687da73.png)]
核密度估计器实际上是平滑的直方图。 使用直方图,您可以创建箱并计算数据集中有多少观测值落入这些箱中。 核密度估计器使用另一种方式来创建图,但是最终得到的是一条平滑曲线,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Lz6hmweQ-1681367023204)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/da87e71f-7e74-4658-abde-d8c4dd7110ce.png)]
让我们看看其他绘图。 例如,我们为数据帧创建箱形图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BLyra0MJ-1681367023204)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/1f90164f-7d97-47e4-bea8-fa819a6a01ee.png)]
我们还可以创建散点图,并且在创建散点图时,我们需要指定哪一列对应x值,哪一列对应y值:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MpH06857-1681367023204)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/d4dc7567-67a6-4a3f-a283-fcb60f4dce26.png)]
这里有很多数据点。 另一种方法是使用所谓的十六进制箱图,您可以将其视为 2D 直方图。 它计算落入真实平面上某些六角形面元的观测值,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I8yAgOxM-1681367023205)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/7b623069-150a-4a5f-aefc-41e7e726ee86.png)]
现在,这个十六进制图似乎不是很有用,所以让我们将网格大小设置为25:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-P20Dax7c-1681367023205)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/c4554dd2-424d-4d7e-b872-7135a68479a7.png)]
现在,我们有了一个更有趣的图,并且可以看到数据倾向于聚集的位置。 让我们计算图中各列的标准偏差,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DCbziFNt-1681367023205)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/e01dfd05-11fa-4379-8b97-be946ca88415.png)]
现在,让我们创建一个条形图以可视化这些标准偏差,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LP3XLzQM-1681367023205)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/c00d3910-730c-4007-a5da-edbeae50378c.png)]
现在,让我们看一个称为散点图矩阵的高级工具,该工具可用于可视化数据集中的多个关系,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OlaACjiP-1681367023205)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/1668870c-31d7-4572-96f0-d215f0b89511.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dioMQEth-1681367023206)(https://gitcode.net/apachecn/apachecn-ds-zh/-/raw/master/docs/handson-data-analysis-numpy-pandas/img/7b6b1466-4a6a-4675-b673-6cc68cb69643.png)]
您可以创建更多图。 我诚挚地邀请您探索绘图方法,不仅是 Pandas 的绘图方法(我提供了许多示例的文档链接),而且还探讨了 Matplotlib。
总结
在本章中,我们从索引排序开始,并介绍了如何通过值进行排序。 我们介绍了层次聚类,并用层次索引对序列进行了切片。 最后,我们看到了各种绘图方法并进行了演示。文章来源:https://www.toymoban.com/news/detail-413018.html
我们已经走了很长一段路。 我们已经建立了 Python 数据分析环境,并熟悉了基本工具。 祝一切顺利!文章来源地址https://www.toymoban.com/news/detail-413018.html
到了这里,关于NumPy 和 Pandas 数据分析实用指南:1~6 全的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!