impala的介绍
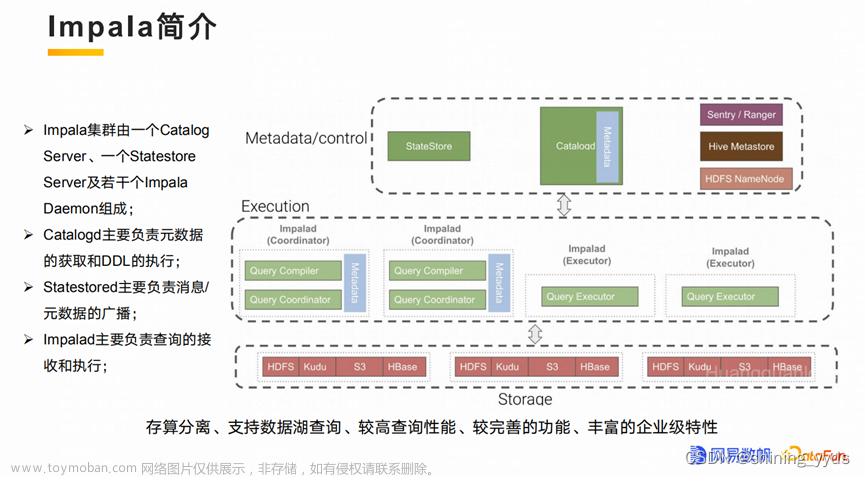
Impala是由Cloudera公司开发的一款开源的大数据交互查询工具,能够对存储在HDFS、HBase上的数据进行快速的交互式SQL查询。Impala可以实现对PB级别的数据的实时分析,其查询速度比基于MapReduce的Hive高出3到90倍。Impala使用了类似于传统的MPP数据库技术,避免了MapReduce引擎的启动开销和中间结果落盘开销,实现了流式数据传输和内存计算。Impala支持Hive查询语言(HiveQL)最常见的SQL-92功能,包括SELECT, JOIN和聚合函数,以及多种数据格式和压缩方式。Impala还提供了常见的数据访问接口,包括JDBC driver、ODBC driver和impala-shell命令行接口。Impala可以与Hive共享元数据和数据文件,实现简单的数据交换和协同分析。
Impala的优点
- 使用了数据科学家和分析师熟悉的SQL接口,降低了学习成本和使用难度。
- 能够查询大数据集,支持PB级别的数据规模,满足大数据场景下的分析需求。
- 是集群环境中的分布式查询引擎,便于扩展和使用廉价商用硬件,提高了可用性和可靠性。
- 能够在不同的分析引擎之间共享数据,比如可以通过Pig写数据,使用Hive转换数据,再使用Impala查询数据。
- 单一系统用于大数据处理和分析,因此可以避免成本高昂的建模和ETL。
Impala与其他大数据引擎的异同
- 与Hive相比,Impala最大的区别在于计算引擎。Hive是基于批处理的Hadoop MapReduce引擎,适合处理长时间运行的批处理作业,比如涉及到批处理的ETL类型的作业。Impala是基于MPP数据库技术的实时交互查询引擎,适合处理对响应速度要求高的交互式分析作业。Impala避免了MapReduce引擎的启动开销和中间结果落盘开销,实现了流式数据传输和内存计算。因此,Impala在查询速度上比Hive快3到90倍。但是,Impala也有一些缺点,比如不支持容错机制,不支持复杂的UDF和窗口函数等。
- 与Spark SQL相比,Impala也有一些异同。Spark SQL是基于Spark引擎的大数据SQL查询工具,也支持内存计算和流式处理。Spark SQL在性能上比Hive有很大提升,但是还是不如Impala快。Spark SQL适合处理复杂的分析作业,比如机器学习、图计算等。Impala适合处理简单的交互式查询作业,比如聚合、过滤、排序等。Spark SQL支持更多的SQL功能和数据格式,比如窗口函数、JSON、Parquet等。Impala支持的SQL功能和数据格式相对较少,比如不支持窗口函数、JSON等
- 与Presto相比,Impala也有一些异同。Presto能够对存储在HDFS、HBase上的数据进行快速的交互式SQL查询。Presto和Impala都使用了类似于MPP数据库技术的架构,避免了MapReduce引擎的开销,实现了流式数据传输和内存计算。Presto和Impala都支持Hive查询语言,以及多种数据格式和压缩方式。Presto和Impala都可以与Hive共享元数据和数据文件,实现简单的数据交换和协同分析。Presto和Impala在性能上都比Hive快很多倍。Presto的优势在于它可以连接多种数据源,比如MySQL、PostgreSQL、MongoDB等,实现跨源查询。Impala的优势在于它可以更好地集成Cloudera公司提供的其他大数据产品和服务,比如Cloudera Manager、Cloudera Navigator等。
Impala的使用场景
Impala适合以下几种使用场景:
- 实时数据分析,需要快速响应和高吞吐量的查询,比如BI工具、仪表盘、报表等。
- 数据探索,需要对大量的原始数据进行交互式的探索和发现,比如数据科学家、分析师等。
- 数据验证,需要对数据的质量和完整性进行验证和检查,比如数据工程师、测试人员等。
Impala不适合以下几种使用场景:
- 复杂的数据转换,需要对数据进行复杂的转换和处理,比如ETL作业、机器学习模型等。
- 容错性要求高的作业,需要对作业的执行结果有高度的保障和容错能力,比如金融交易、审计日志等。
- 非结构化或半结构化数据的处理,需要对非结构化或半结构化数据进行解析和处理,比如文本、图像、JSON、XML等。
Impala的使用方法
Impala提供了多种使用方法,包括impala-shell命令行接口、Hue界面和ODBC/JDBC驱动程序。以下是一些常用的使用方法的示例:
-
使用impala-shell命令行接口
-
启动impala-shell命令行接口
impala-shell -
连接到指定的impalad守护进程
impala-shell -i hostname:port -
执行SQL语句
SELECT * FROM table_name; -
退出impala-shell命令行接口
quit;
-
-
使用Hue界面文章来源:https://www.toymoban.com/news/detail-413046.html
- 打开浏览器,访问Hue的网址,例如http://localhost:8888
- 登录Hue,选择Impala菜单
- 在编辑器中输入SQL语句,点击执行按钮
- 查看查询结果和日志信息
-
使用ODBC/JDBC驱动程序文章来源地址https://www.toymoban.com/news/detail-413046.html
- 下载并安装Impala提供的ODBC/JDBC驱动程序
- 配置连接参数,例如主机名、端口号、用户名、密码等
- 使用支持ODBC/JDBC的应用程序或工具连接到Impala
- 执行SQL语句,获取查询结果
到了这里,关于Impala:大数据交互查询工具的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!