作为一个开发人员 总会遇到各种难题 本文列举博主 遇见/想到 的例子 ,也希望同学们可以在评论区举例交流 共同进步,文章博主一直在补充更新,阅读量和收藏量都不少, 非常欢迎各位能在评论区提出一些疑难场景,毕竟博主一个人的能力是有限的。另外,博主原创idea轻量级插件已上架idea的插件marketplace 欢迎搜索下载: Equals Inspection

tips: 本文由csdn博主 孟秋与你 编写,如果您在其它地方看到此文章 那可能是被别的博主爬虫/复制搬运,博主的文章会持续更新 为确保您看到的文章是最新的 强烈建议您前往csdn查看原文
逻辑删除如何建立唯一索引
场景描述:
比如我们有project项目表
字段project_name 是唯一的,
且有逻辑删除字段is_delete 0表示未删除 1表示已删除
很显然 不能直接将project_name设置为唯一索引,
例如A用户建立的project_name为 java工程,又把这个工程(逻辑)删除了, 这时B用户是允许建立 java工程的。
那将is_delete project_name 共同设置为唯一索引是否可行呢? 答案也是否定的,在B用户删除时,就会出现问题了。
解决方案:
is_delete 不用0和1表示,可改为数字递增,或者时间戳(尽量小 例如纳秒级别), 这时将is_delete project_name 共同设置为唯一索引 可以解决该问题。
唯一索引失效问题
场景描述:
人员姓名和电话 组成唯一索引 。

出现问题:
有两个小孩 名字都叫小朋友 且他们都没有手机号 此时数据重复 唯一索引失效。 我们换个场景,在高并发的电商活动中,用户姓名和vip标识码 组成唯一索引,此时有两位用户 都不是vip用户,vip标识码都为空,那可能出现的问题就比较严峻了

解决方案: 唯一索引的字段设置为非空,因为空是允许重复的
( 不管单独将某一个字段设置为唯一索引 还是多个字段组合成唯一索引 都一样的)
加密字段模糊查询问题
场景描述: 用户敏感信息,例如手机号 身份证 户籍所在地 入库时,我们通常会加密, 这时需要模糊查询
解决方案:
-
数据量少时,例如只是一个公司内部系统的人员表,可以全表查询 并解密,在java代码中过滤 (如果遇到要分页,那得好好考虑怎么处理分页问题了)
-
与业务/产品沟通,看搜索的字数是否相对固定的,例如某用户的户籍所在地是广东省广州市 那么我们可以将广东省、广州市拆分加密。
假设广东省加密后字符串为 pwd_gds 广州市加密后字符串为pwd_gzs,
此时我们前端传入广州市,后端加密后再进行模糊查询 sql语句变成 like %pwd_gzs% -
当然 前面两种方式只是取巧,通常在中型规模的项目就已经不适用了,既然提到拆分,那我们可以联想到分词,所以我们可以使用es,将各词都拆分加密 存入es中 (题外话 es也好 其它存储也罢 一定要设置密码 )
maven依赖冲突问题(jar包版本冲突问题)
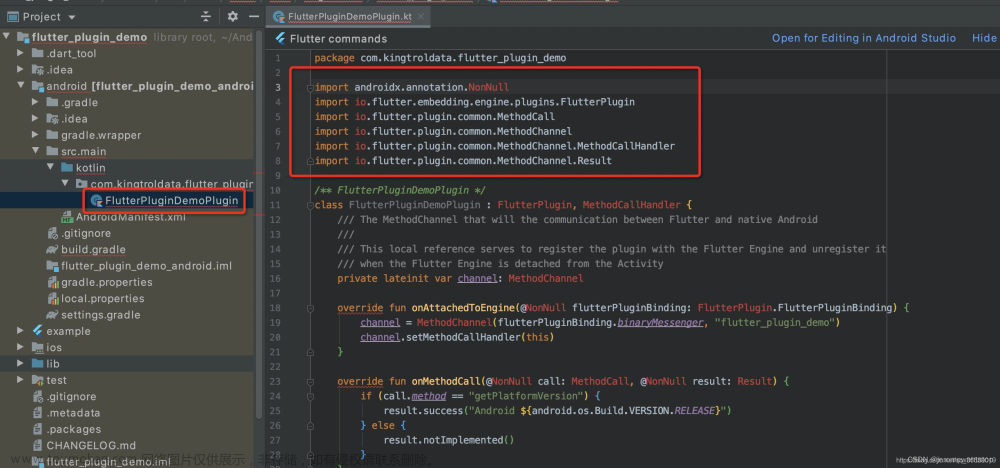
场景描述: classNotFound , 这是在项目中,引入版本不正确最经常遇到的问题了。 我们跟进报错类,找到顶部import导包处,假设我们红色涂抹部分报红,我们可以找到前一级目录(红色划线处) ,按住ctrl 键 再鼠标左键点击,找到所在jar包
解决方案: 将jar包升级(或降级)。
但很多时候,该jar包并不是我们直接通过maven依赖引入的,可能是通过其它组件内部引用的,这个时候我们就可以通过mvn dependency:tree 命令,将控制台打印信息复制到文本编辑器,在文本编辑器搜索 即可知道是哪个父包引入的


sql in条件查询时 将结果按照传入顺序排序
场景描述: 例如我们调用外部接口获取id, 再通过id去数据库查询,如果获取一条id 查一次库,是可以保证结果顺序和id传入顺序一致的;那此时我们希望优化一下下,等获取一批id时,再通过in条件查询的形式 :
select xx,xxx,xxxx from t where id in(5,1,4,2,3)
此时如何保证返回结果顺序与id传入顺序一致呢? 如上伪代码 id=5 时,希望返回记录在第一条
解决方案:
- sql层面处理
orcale : order by decode
mysql : order by field
2. 如果条件允许 不是直接sql开发,那么推荐是在java代码中去二次处理数据的,循环idList 根据id对比去重新组装结果即可。
数据库主从复制 主从不同步问题
场景描述: 由于网络延迟、负载、、自增主键不一致等等各种原因 导致主从数据不一致
解决方法: 线上真出现了问题,都到了需要集群数据库级别的项目 博主觉得吧 大部分还是手动修复数据吧 出现问题 谁都担不起…
言归正传:
- 锁主库 锁为只读状态
- 数据导出
- 停止从库
- 数据导入
- 重新开始同步
但是锁主库 停从库 这时候如果有数据来源 非常难处理,这时候最好的方式就是 业务对外公布维护了。
数据库读写分离 读写不一致
场景描述: 读写分离时,读从库时 数据和主库不一致
解决方法: 还是数据同步问题,看业务是否能容忍错误,能就不处理 不能容忍就手动修数据/重新同步。
临时解决方案为:强制路由(强制读取主库) 但博主还是认为,只要不是大面积出现问题,手动修数据都是比较稳妥的方案。
双写不一致问题 并发下数据库和缓存不一致
场景描述 : 在博主的 《从高并发场景下超卖问题到redis分布式锁》博客中 有提到过具体案例
解决方法:
-
延迟双删
优点: 博主个人认为优点不明显
缺点:博主认为在写多读少的场景下 没有一点用
写多读少场景下,在写入时删除缓存,读时更新缓存,此时延迟双删 不能解决任何问题 反而降低性能 -
使用队列 串行化
优点:避免不一致问题
缺点:效率低 -
分布式锁 串行化 如redislock 提供了读写锁
优缺点与第2点一致 -
使用canal中间件
博主未接触过 只是知道该中间件可以解决
java服务如何作为websocket客户端
场景描述: 有的时候 我们对接供应商/甲方接口,可能会遇到对方给的websocket接口,我们避免在前后端传输之间出现数据丢失问题 可能想在后端自己搭建websocket客户端。 注意是客户端,网上搜java websocket客户端,千篇一律都是搜出作为服务端的教程。
解决方法: 可以使用netty实现,博主目前在写自动重连和发送心跳时 遇到了问题 找了大佬写的比较好的代码 并经过测试 是可用的 具体的代码会单独发博客教程
spring事务失效问题
场景描述: 事务失效 出现异常不回滚 ,首先 @Transactional需要加上(rollbackFor = Exception.class),博主之前有单独文章介绍过为什么阿里规范要求加上
解决方法: 博主私认为 所有失效问题都是因为对spring代理对象机制理解不深导致的,失效只是自己没用对,欢迎在博主博客搜索事务 查看相应文章
数据库死锁问题
场景描述: 数据库死锁 导致系统卡爆
解决方法: 博主曾切身体会过,在老旧项目中,使用的是oracle 存储过程开发,由于大量的sql代码,且使用for update悲观锁,各处sql实在太多了,且未及时commit,引发了死锁,出现死锁我们需要在 v$session 中找到死锁进程 并杀死进程,解决核心是赶紧优化sql,简化或拆分逻辑。
在mysql中,使用replace into语句 也会引发死锁,建议使用select + insert方式替代,(据说mysql8.0已修复该bug 博主未亲测)
跨库分页问题
场景描述:
数据源来自不同的库,甚至不同类型的数据库(例如一部分来自mysql,部分来自于时序数据库)
大多数时候,只需要单独查不同的库就能满足业务,各司其职;但有一个页面 需要查看这两个库的数据 并实现分页功能。
解决方法:
首先能不跨库分页就不跨库分页,看业务是否真的不能妥协,数据源是否真的不能合并。
如果都不能,那只能考虑分页方案,下面是博主想到的方法:
将两个库的数据,同步至同一张大表中,记录好每次同步的最新那条数据的时间戳,下次同步时,同步这个时间戳以后的数据即可,大表只负责分页查询。
这时大表数据量虽然大些,但有分页在,效率不会过低。
(如果数据量过大 根据实际情况,考虑同步至es 、clickhouse等)
博主看到有人提过 canal可以同步mysql数据到es,还是要提醒:生产环境中不是我们demo写着玩,使用这种中间件 必须熟悉原理 否则重要数据丢失或出现问题 得不偿失!
此外 如果我们使用的sharding jdbc进行分库分表,那sharding jdbc自己就帮我们处理了分页问题,具体怎么处理的可以搜博主的sharding jdbc的文章。
分布式事务问题
场景描述:在分布式中 需要事务回滚
解决方法:可以引入seata中间件,seata中间件本身就是个事务调度器,基于mysql的undo日志;
如果不引入seata,也可以手动回滚,但这得严格要求代码及时调用,且不适用高并发场景,
仅适用于中小型项目, 伪代码如下:
// service A
public GoodsDO delete(Long id){
GoodsDO gs = database.getOne(id);
database.deleteById(id);
return gs;
}
public void insert(GoodsDO gs){
database.insert(gs);
}
// service B
@Autowired
private ServiceA serviceA;
public void handle(Long id){
try{
GoodsDO gs = serviceA.deleteById(id);
// do other things serviceB.xx();
}
catch(E e){
// 这里可以换成aop方式,也可以通过mq实现异步
serviceA.insert(gs);
}
}
如何避免多人同时修改问题
场景描述:例如管理系统中,管理人员可以修改员工的基本信息,员工自己也可以修改。员工在修改过程中,如果管理员已经修改并提交,员工随后提交,这就会将管理人员修改的内容覆盖。
解决方法:详情接口 加上乐观锁版本号,在点击编辑按钮时,调用一次详情接口,获取到当前的乐观锁版本号,例如员工点编辑时 version = 1,接下来管理员也点击了编辑,管理员得到的版本号也为1 (此时员工还没保存),接着管理员点击保存,前端将版本号传回后端,保存接口中去判断前端传入的版本号和当前数据库版本号是否一致(这个时候是一致的 都是1),管理员保存成功 修改乐观锁版本号。员工点击保存时,传入的版本号也为1,但此时数据库获取的版本号,已经变成2了,提示前端信息已被他人修改 刷新页面再进入。
netty中 发送多条指令 如何与回复内容进行对应
场景描述:netty中,向服务端发送多条指令,接收到回复时,如何确定哪条内容对应是哪条指令发送的
解决方法:可以在发送时,在数据头部添加一个请求ID字段,或者在尾部添加一个ack应答机制, 但这前提都是需要服务端进行配合。
参考代码如下:
// 客户端代码
public class ClientHandler extends ChannelInboundHandlerAdapter {
// 记录每个请求的请求ID
private final Map<Integer, String> requestMap = new ConcurrentHashMap<>();
// 记录每个请求对应的响应结果
private final Map<String, String> responseMap = new ConcurrentHashMap<>();
// 请求ID生成器
private final AtomicInteger requestIdGenerator = new AtomicInteger(0);
public void sendRequest(byte[] data) {
int requestId = requestIdGenerator.incrementAndGet();
ByteBuf buf = Unpooled.buffer(data.length + 4);
buf.writeInt(requestId);
buf.writeBytes(data);
channel.writeAndFlush(buf);
// 将请求ID和请求数据保存到请求映射表
requestMap.put(requestId, Arrays.toString(data));
}
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
if (msg instanceof ByteBuf) {
ByteBuf buf = (ByteBuf) msg;
int requestId = buf.readInt();
byte[] data = new byte[buf.readableBytes()];
buf.getBytes(buf.readerIndex(), data);
String request = requestMap.get(requestId);
if (request != null) {
// 将请求ID和响应数据保存到响应映射表
String response = Arrays.toString(data);
responseMap.put(request, response);
// 从请求映射表中删除请求ID
requestMap.remove(requestId);
}
}
}
}
ack:
public class MyClientHandler extends ChannelInboundHandlerAdapter {
// 记录上一次请求的ACK字段的值
private int lastAck = 1;
public void sendRequest(byte[] data) {
// 在请求数据末尾添加一个预留的ACK字段
byte[] requestData = Arrays.copyOf(data, data.length + 1);
requestData[data.length] = (byte) lastAck;
channel.writeAndFlush(requestData);
}
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
if (msg instanceof ByteBuf) {
ByteBuf buf = (ByteBuf) msg;
byte[] data = new byte[buf.readableBytes()];
buf.readBytes(data);
int ack = data[data.length - 1];
// 修改ACK字段的值为1
data[data.length - 1] = 1;
lastAck = 1;
// 处理服务端的响应
handleResponse(data);
}
}
public void handleResponse(byte[] data) {
// 处理服务端的响应
// ...
}
}
那如果服务端拒绝配合呢? 那我们只能在等接收到响应后,再发送下一条指令,思路如下
(但是注意 并发下会出现问题 如果有并发场景,必须得服务端配合做应答机制):
-
定义一个 指令下标 (我们以要发送10条指令为例) :
public static AtomicInteger index = new AtomicInteger(0); -
提供一个修改下标的方法
public static void setOtherIndex() { // 如果下标到了10 则清0 进行下一次的轮询 if (Objects.equals(cabinIndex.get(), 10)) { cabinIndex.set(0); } else { cabinIndex.getAndAdd(1); } } -
发送指令
if(index.get() == 0){ new byte[]{0x01} }else if (index.get() == 1){ new byte[]{0x02} } // ..... -
channelRead 方法中处理数据
// dosomething // 处理完毕后 下标偏移 setOtherIndex();
MQ消息重复消费问题
场景描述:MQ消息可能会被重复消费
解决方法:
-
消息幂等性设计: 保证消息的处理是幂等的,即多次处理同一条消息产生的效果和一次处理是一样的。这样,即使消息被重复消费,系统也不会产生错误的结果。
-
消息发送时,添加一个消息id , 可以用redis等去维护已经消费过的id,消费前去判断是否已经消费过。
(其实和幂等也类似)
MQ 消息堆积问题
场景描述:MQ消息大量堆积未被消费的消息
解决方法:
-
消息队列容量调整: 根据业务的实际需求,调整消息队列的容量。确保消息队列的容量足够,能够应对高峰期的消息产生。
-
优化消费者端:调整消费者的线程数, 确保消费者的线程数足够,能够满足高并发的需求,增加消费者
-
监控和报警: 设置监控和报警机制,及时发现消息堆积的情况并采取措施。通过监控系统,了解消息队列的状态,及时预警和处理问题。(辅助手段)
-
如果是RabbitMQ 可以结合业务是否允许 来缩短TTL时间 (time to live) ; 在rocketMQ中目前是不支持的,可能设计初就是只为了At least once (最少一次,消息绝不会丢失,但可能会重复传输), 我们可以看到rocketMQ的MessageConst类中是包含了TTL关键字的,不知道在未来是否会在Message类中提供修改方法。
接口重复调用问题(幂等)
场景描述:接口重复提交
解决方法:
- 前端首先要做禁止重复点击
- 生成一个UUID,后端处理请求后,将ID和结果存入缓存 ,下次如果有相同的id传入,直接从缓存中取出结果并返回。
(不一定是uuid,根据业务 也可能业务唯一标识即可) - 如果是修改接口,也可以用版本号(乐观锁思想),提交时先调用详情接口 获取到version, 传入后端 更新语句带上version
事务失效问题
场景描述:springboot中 事务未回滚
解决方法:我们spring单体项目中,一切事务失效问题 都是没正确使用代理对象的问题。
移步博主主页搜索博客: 事务回滚失败原因,事务的传播机制
分布式事务失效问题(seata回滚失败)
场景描述:微服务中 seata事务未回滚
解决方法:
移步博主主页博客搜索:seata失效
多线程中如何等待线程都执行完毕
传统多线程
我们先看不做处理的代码:
public static void main(String[] args) {
// 有name age字段的一个实体类
Ademo ademo = new Ademo();
Thread thread1 = new Thread(new Runnable() {
@Override
public void run() {
try {
// 模拟业务执行了2秒
Thread.sleep(2000);
// 模拟获取age
ademo.setAge(18);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
Thread thread2 = new Thread(new Runnable() {
@Override
public void run() {
try {
// 模拟业务执行了5秒
Thread.sleep(5000);
// 模拟获取name
ademo.setName("CSDN:孟秋与你");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
thread1.start();
thread2.start();
// 主业务获取name age 此时都为null 因为异步线程还没执行完
System.out.println("姓名: " + ademo.getName()+" 年龄:"+ademo.getAge());
}
解决方法: thread.join()
原理是join方法会通过while循环去判断线程是否存活,存活则一直等待
thread1.start();
thread2.start();
// 在主业务前 将需要等待执行结果的线程join
try {
thread1.join();
thread2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
// 主业务获取name age
System.out.println("姓名: " + ademo.getName()+" 年龄:"+ademo.getAge());

CompletableFuture
jdk8开始引入的特性,同样可以使用join()方法 或get()方法
public static void main(String[] args) {
// 有name age字段的一个实体类
Ademo ademo = new Ademo();
long start = System.currentTimeMillis();
// 默认是由ForkJoinPool实现的 ForkJoinPool就是为了 Fork-Join 模型设计的线程池
// 如果要返回值 使用 supplyAsync方法
CompletableFuture future1 = CompletableFuture.runAsync(new Runnable() {
@Override
public void run() {
try {
// 模拟业务执行了2秒
Thread.sleep(2000);
// 模拟获取age
ademo.setAge(18);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
CompletableFuture future2 = CompletableFuture.runAsync(new Runnable() {
@Override
public void run() {
try {
// 模拟业务执行了5秒
Thread.sleep(5000);
// 模拟获取name
ademo.setName("CSDN:孟秋与你");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
// 注意 allOf本身只是做个合并
CompletableFuture<Void> allFuture = CompletableFuture.allOf(future1, future2);
// 如果换成allFuture.get() 则需要手动对 allFuture.get进行try catch
allFuture.join();
/**
* 上面两行代码 相当于
* future1.join();
* future2.join();
**/
// 主业务获取name age
System.out.println("姓名: " + ademo.getName() + " 年龄:" + ademo.getAge());
System.out.println(System.currentTimeMillis() - start);
}
线程池
CountDownLatch
解决方案:CountDownLatch
public static void main(String[] args) {
// 有name age字段的一个实体类
Ademo ademo = new Ademo();
// 实际使用 需要手动创建 防止OOM
ExecutorService executorService = Executors.newFixedThreadPool(2);
// 严格控制构造参数数量 参数大于实际线程数 将会陷入无限等待!
CountDownLatch countDownLatch = new CountDownLatch(2);
long start = System.currentTimeMillis();
executorService.execute(new Runnable() {
@Override
public void run() {
try {
// 模拟业务执行了5秒
Thread.sleep(5000);
// 模拟获取name
ademo.setName("CSDN:孟秋与你");
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
// 需要保证countDown正确执行
countDownLatch.countDown();
}
}
});
executorService.execute(() -> {
try {
// 模拟业务执行了2秒
Thread.sleep(2000);
// 模拟获取age
ademo.setAge(18);
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
// 需要保证countDown正确执行
countDownLatch.countDown();
}
});
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
// 主业务获取name age
System.out.println("姓名: " + ademo.getName() + " 年龄:" + ademo.getAge());
System.out.println(System.currentTimeMillis() - start);
}
CyclicBarrier
类似的 解决方案还有 CyclicBarrier
public static void main(String[] args) {
// 有name age字段的一个实体类
Ademo ademo = new Ademo();
// 实际使用 需要手动创建 防止OOM
ExecutorService executorService = Executors.newFixedThreadPool(2);
// 严格控制构造参数数量 参数大于实际线程数 将会陷入无限等待!
CyclicBarrier cyclicBarrier = new CyclicBarrier(2);
long start = System.currentTimeMillis();
executorService.execute(new Runnable() {
@Override
public void run() {
try {
// 模拟业务执行了5秒
Thread.sleep(5000);
// 模拟获取name
ademo.setName("CSDN:孟秋与你");
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
cyclicBarrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
System.out.println("姓名: " + ademo.getName() + " 年龄:" + ademo.getAge());
}
});
executorService.execute(() -> {
try {
// 模拟业务执行了2秒
Thread.sleep(2000);
// 模拟获取age
ademo.setAge(18);
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
cyclicBarrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
System.out.println("姓名: " + ademo.getName() + " 年龄:" + ademo.getAge());
});
}
CountDownLatch 和 CyclicBarrier 的区别
如果我们去网上搜索区别 得到一些概念性的东西,并不能帮助我们理解,结合博主上面两个例子,应该就能很好的理解了文章来源:https://www.toymoban.com/news/detail-413073.html
除了CyclicBarrier可以重复使用外,它们之间的区别:
CountDownLatch : 会阻塞主线程 倾向于所有线程都执行完成 汇聚到主线程再往下
CyclicBarrier :阻塞子线程 倾向于所有子线程都到了同一进度 再继续各自执行文章来源地址https://www.toymoban.com/news/detail-413073.html
到了这里,关于【java】 java开发中 常遇到的各种难点 思路方案的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!