原文:Numpy Essentials
协议:CC BY-NC-SA 4.0
译者:飞龙
六、NumPy 中的傅立叶分析
除其他事项外,傅立叶分析通常用于数字信号处理。 这要归功于它在将输入信号(时域)分离为以离散频率(频域)起作用的分量方面如此强大。 开发了另一种快速算法来计算离散傅里叶变换(DFT),这就是众所周知的快速傅里叶变换(FFT),它为分析及其应用提供了更多可能性。 NumPy 针对数字计算,也支持 FFT。 让我们尝试使用 NumPy 在应用上进行一些傅立叶分析! 注意,本章假定不熟悉信号处理或傅立叶方法。
本章将涉及的主题是:
- 傅立叶分析的基础
- 一维和二维傅立叶变换
- 频谱密度估计
- 时频分析
开始之前
众所周知,傅里叶分析将函数表示为周期分量的总和(正弦和余弦函数的组合),并且这些分量能够恢复原始函数。 它在数字信号处理(例如滤波,插值等)中具有广泛的应用,因此我们在不提供 NumPy 的任何应用细节的情况下就不想谈论 NumPy 中的傅立叶分析。 为此,我们需要一个可视化的模块。
Matplotlib 是我们将在本章中使用的可视化模块。 请从官方网站下载并安装它。 或者,如果您正在使用 Anaconda 之类的 Scientific Python 发行版,则应该已经包括了 matplotlib。
我们将编写一个名为show()的简单显示函数,以帮助我们了解本章中的练习示例。 函数输出如下图所示:

上图显示原始函数(信号),下图显示傅立叶变换。 请在 IPython 命令提示符下键入以下代码,或将其保存到.py文件并将其加载到提示符:
##### The Plotting Functions ####import matplotlib.pyplot as plt
import numpy as np
def show(ori_func, ft, sampling_period = 5):
n = len(ori_func)
interval = sampling_period / n
plt.subplot(2, 1, 1)
plt.plot(np.arange(0, sampling_period, interval), ori_func, 'black')
plt.xlabel('Time'), plt.ylabel('Amplitude')
plt.subplot(2,1,2)
frequency = np.arange(n / 2) / (n * interval)
nfft = abs(ft[range(int(n / 2))] / n )
plt.plot(frequency, nfft, 'red')
plt.xlabel('Freq (Hz)'), plt.ylabel('Amp. Spectrum')
plt.show()
这是一个名为show()的显示函数,它具有两个输入参数:第一个是原始信号函数(ori_func),第二个是其傅里叶变换(ft)。 此方法将使用matplotlib.pyplot模块创建两个折线图:顶部带有黑线的原始信号,其中 x 轴表示时间间隔(在我们所有的示例中,我们设置了默认值,信号采样周期为 5 秒), y 轴代表信号的幅度。 图表的下部是带有红线的傅里叶变换,其中 x 轴表示频率, y 轴代表振幅频谱。
在下一节中,我们将简单地介绍不同类型的信号波,并使用numpy.fft模块计算傅立叶变换。 然后我们调用show()函数以提供它们之间的视觉比较。
信号处理
在本节中,我们将使用 NumPy 函数来模拟多个信号函数并将其转换为傅立叶变换。 我们将重点介绍numpy.fft及其相关函数。 我们希望在本节之后,您将对在 NumPy 中使用傅立叶变换有所了解。 理论部分将在下一部分中介绍。
我们要使用的第一个示例是心跳信号,它是一系列正弦波。 频率为每分钟 60 次(1Hz),我们的采样周期为 5 秒长,采样间隔为 0.005 秒。 首先创建正弦波:
In [1]: time = np.arange(0, 5, .005)
In [2]: x = np.sin(2 * np.pi * 1 * time)
In [3]: y = np.fft.fft(x)
In [4]: show(x, y)
在此示例中,我们首先创建了采样时间间隔并将其保存到名为time的ndarray中。 然后,我们将time数组乘以2π并将其频率设为 1Hz 传递给numpy.sin()方法,以创建正弦波(x)。 然后将傅立叶变换应用于x并将其保存到y。 最后,我们使用预定义的方法show()与正弦波及其归一化的 Fourier 变换进行视觉比较,如下图所示:

上方的绿线代表心跳波; 因为我们使用 1Hz 持续 5 秒钟,所以获得了 5 个连续的正弦波。 这里要注意的一件事是,我们的采样间隔为 0.005 秒,这意味着我们使用 200 点(1 / 0.005)来模拟一个波形,因此它看起来相对平滑。 如果增加采样间隔(减少每个波的点数),我们将获得更强烈的正弦波。 图表的下部是基于频率(所谓的频谱)的标准化傅里叶变换的绝对值。 我们可以看到在 1Hz 处有一个高点,与我们的原始波频率相匹配。
接下来,我们将尝试计算多频正弦波并对其傅里叶变换进行计算。 在此之后,我们可能对傅立叶变换有了更清晰的了解。 以下代码显示了如何执行此操作:
In [8]: x2 = np.sin(2 * np.pi * 20 * time)
In [9]: x3 = np.sin(2 * np.pi * 60 * time)
In [10]: x += x2 + x3
In [11]: y = np.fft.fft(x)
In [12]: show(x, y)
首先,我们再创建两个频率不同的正弦波,频率为 20Hz 的x2和 60Hz 的x3,然后将它们添加到原始的 1Hz 正弦波x中。 然后我们将修改后的x传递给傅立叶变换,并使用预定义的show()绘制图形。 您可以在下图中看到它:

在上方的绿色折线图中,我们可以看到正弦波组合了不同的频率,但实际上很难区分它们。 但是,在计算傅立叶变换并将其转换到频域之后,我们可以在下部的红色折线图中清楚地看到已识别出三个高点,分别是 1Hz,20Hz 和 60Hz。 这与我们原始的正弦波频率匹配。
从这两个示例中,您必须能够对傅立叶变换有所了解。 接下来,我们将演示另外三种信号处理:一种用于正方形信号,一种用于脉冲,另一种用于随机信号。
首先,我们使用numpy.zeros()以相同的时间间隔(time)创建方波信号。 我们希望方波频率为 10Hz,幅度为 1,因此我们将每 20 个时间间隔(200/10)设置为值 1,来模拟波浪并将其传递给傅立叶变换,如下面的代码块所示:
In [13]: x = np.zeros(len(time))
In [14]: x[::20] = 1
In [15]: y = np.fft.fft(x)
In [16]: show(x, y)
此代码生成以下图形:

从上方的绿色折线图中,我们可以在 5 秒(10Hz)中看到 50 个连续的方波,但是当我们计算其傅立叶变换时,我们在频谱中获得了几个红色的高点,而不是 10Hz 时的一个红色高点。 您可能想知道方波是否也是周期函数,但是傅立叶变换为什么与正弦波有很大不同? 请记住,傅立叶变换将时域转换为频域,但是在引擎盖下,有一系列正弦和余弦函数可以分解原始函数。 我们仍然可以看到红色的高点是规则间隔的,间隔为 10Hz。
接下来,我们将生成一个没有任何频率的单脉冲信号,并且将要计算其傅立叶变换。 将其与以前的方波进行比较,您可能会对傅里叶变换有更好的了解:
In [17]: x = np.zeros(len(time))
In [18]: x[380:400] = np.arange(0, 1, .05)
In [19]: x[400:420] = np.arange(1, 0, -.05)
In [20]: y = np.fft.fft(x)
In [21]: show(x, y)
首先我们创建一个与时间变量大小相同的全零ndarray,然后生成一个单脉冲信号,该信号在 2 秒时发生(x数组的第 400 个元素 )。 我们在 2 秒左右的时间内占用了 40 个元素来模拟脉冲:20 个元素从 0 增加到 1,另一半从 1 减少到 0。我们将一个脉冲信号传递给傅里叶变换,并使用show()进行视觉比较。
下图中上部的绿色折线图是我们模拟的一脉冲信号,下部的红色折线图是其傅里叶变换。 我们可以看到下面图表中的最高点出现在等于 0 的频率上,这很有意义,因为我们的模拟信号没有任何频率。 但是,在零频率之后,我们仍然可以看到来自变换过程的两个不同频率的高点。

本节的最后一个示例是随机信号处理。 与前面的示例一样,我们还将 5 秒作为 100 个随机信号的总采样周期,该随机信号没有任何固定的频率与之关联。 然后,我们将随机信号传递给傅立叶变换,以获得其频域。 代码块如下:
In [22]: x = np.random.random(100)
In [23]: y = np.fft.fft(x)
In [24]: show(x, y)
以下是由代码生成的图形:

看完这些示例之后,我们知道如何在 NumPy(简称为numpy.fft.fft())中使用傅立叶变换-并且对傅立叶变换的外观有了一些了解。 在下一节中,我们将重点介绍理论部分。
傅立叶分析
定义 DFT 的方法很多。 但是,在 NumPy 实现中,DFT 定义为以下公式:

A[k]代表离散傅里叶变换,a[m]代表原始函数。 a[m] -> A[k]的转换是从配置空间到频率空间的转换。 让我们手动计算此方程,以更好地了解转换过程。 我们将使用具有 500 个值的随机信号:
In [25]: x = np.random.random(500)
In [26]: n = len(x)
In [27]: m = np.arange(n)
In [28]: k = m.reshape((n, 1))
In [29]: M = np.exp(-2j * np.pi * k * m / n)
In [30]: y = np.dot(M, x)
在此代码块中,x是我们的模拟随机信号,其中包含 500 个值,并且在公式中对应于a[m]。 根据x的大小,我们计算出:

然后将其保存到M。 最后一步是使用M和x之间的矩阵乘法来生成 DFT 并将其保存到y中。
让我们通过将其与内置numpy.fft进行比较来验证结果:
In [31]: np.allclose(y, np.fft.fft(x))
Out[31]: True
如我们所料,手动计算的 DFT 与 NumPy 内置模块相同。 当然,numpy.fft就像 NumPy 中的任何其他内置模块一样-已经过优化,并且已应用 FFT 算法。 让我们比较一下我们的手动 DFT 和numpy.fft的性能:
In [32]: %timeit np.dot(np.exp(-2j * np.pi * np.arange(n).reshape((n, 1)) * np.arange(n) / n), x)
10 loops, best of 3: 18.5 ms per loop
In [33]: %timeit np.fft.fft(x)
100000 loops, best of 3: 10.9 µs per loop
首先,我们将此方程式实现代码放在一行上,以测量执行时间。 我们可以看到它们之间的巨大性能差异。 在引擎盖下,NumPy 使用FFTPACK库执行傅立叶变换,该傅立叶变换在性能和准确性上都是非常稳定的库。
提示
如果您仍然觉得FFTPACK不够快,通常有一个FFTW库的性能要比FFTPACK好,但是从FFTPACK到FFTW的加速将不会那么快。
接下来,我们将计算逆 DFT。 iDFT 将频率序列映射回原始时间序列,该序列由以下公式定义:

我们可以看到反方程与 DFT 方程的不同之处在于指数参数的符号和通过1 / n进行归一化。 让我们再次进行手动计算。 由于指数参数的符号更改,我们可以重复使用先前代码中的m,k和n变量,只需重新计算M:
In [34]: M2 = np.exp(2j * np.pi * k * m / n)
In [35]: x2 = np.dot(y, M2) / n
再次,让我们用原始随机信号x验证计算出的逆 DFT 结果x2。 两者ndarray应该相同:
In [36]: np.allclose(x, x2)
Out[36]: True
当然,numpy.fft模块还支持逆 DFT 调用numpy.fft.ifft()以执行计算,如以下示例所示:
In [37]: np.allclose(x, np.fft.ifft(y))
Out[37]: True
您可能会注意到,在前面的示例中,我们始终使用一维数组作为输入信号。 这是否意味着numpy.fft仅处理一维数据? 当然不是; numpy.fft也可以处理二维或多维数据。 在开始这一部分之前,我们想谈谈返回的 FFT 数组的顺序和numpy.fft中的shift方法。
让我们创建一个包含 10 个随机整数的简单信号数组,并计算其傅里叶变换:
In [38]: a = np.random.randint(10, size = 10)
In [39]: a
Out[39]: array([7, 4, 9, 9, 6, 9, 2, 6, 8, 3])
In [40]: a.mean()
Out[40]: 6.2999999999999998
In [41]: A = np.fft.fft(a)
In [42]: A
Out[42]:
array([ 63.00000000 +0.00000000e+00j,
-2.19098301 -6.74315233e+00j,
-5.25328890 +4.02874005e+00j,
-3.30901699 -2.40414157e+00j,
13.75328890 -1.38757276e-01j,
1.00000000 -2.44249065e-15j,
13.75328890 +1.38757276e-01j,
-3.30901699 +2.40414157e+00j,
-5.25328890 -4.02874005e+00j,
-2.19098301 +6.74315233e+00j])
In [43]: A[0] / 10
Out[43]: (6.2999999999999998+0j)
In [44]: A[int(10 / 2)]
Out[44]: (1-2.4424906541753444e-15j)
在此示例中,a是我们的原始随机信号,A是a的傅立叶变换。 当我们调用numpy.fft.fft(a)时,结果ndarray遵循“标准”顺序,其中第一个值A[0]包含零频率项(信号的均值)。 进行归一化处理(将其除以原始信号数组的长度A[0] / 10)时,我们得到的值与计算信号数组的平均值(a.mean())时的值相同。
然后A[1:n/2]包含正频率项,A[n/2 + 1: n]包含负频率项。 在我们的示例中,当输入为偶数时,A[n/2]代表正数和负数。 如果要将零频率分量移到频谱中心,可以使用numpy.fft.fftshift() 例程。 请参见以下示例:
In [45]: np.fft.fftshift(A)
Out[45]:
array([ 1.00000000 -2.44249065e-15j,
13.75328890 +1.38757276e-01j,
-3.30901699 +2.40414157e+00j,
-5.25328890 -4.02874005e+00j,
-2.19098301 +6.74315233e+00j,
63.00000000 +0.00000000e+00j,
-2.19098301 -6.74315233e+00j,
-5.25328890 +4.02874005e+00j,
-3.30901699 -2.40414157e+00j,
13.75328890 -1.38757276e-01j])
从此示例中,您可以看到numpy.fft.fftshift()交换了数组中的半空间,因此零频率分量移到了中间。 numpy.fft.ifftshift是反函数,将顺序移回“标准”。
现在,我们要谈谈多维 DFT。 让我们从二维开始。 您可能会看到以下等式与一维 DFT 非常相似,而第二维以明显的方式扩展。 多维 DFT 的思想是相同的,较高维中的逆函数也是如此。 您也可以尝试修改先前的代码,以将一维 DFT 计算为二维或多维 DFT,以更好地理解过程。 但是,现在我们仅要演示如何将numpy.fft用于二维和多维傅里叶变换:

In [46]: x = np.random.random(24)
In [47]: x.shape = 2,12
In [48]: y2 = np.fft.fft2(x)
In [49]: x.shape = 1,2,12
In [50]: y3 = np.fft.fftn(x, axes = (1, 2))
从这些示例中,您可以看到我们将numpy.fft.fft2()用于二维傅立叶变换,将numpy.fft.fftn()称为多维。 axes参数是可选的; 它指示要计算 FFT 的轴。 对于二维,如果未指定轴,则使用最后两个轴。 对于多维,模块使用所有轴。 在前面的示例中,我们仅应用了最后两个轴,因此傅立叶变换结果将与二维轴相同。 让我们来看看:
In [51]: np.allclose(y2, y3)
Out[51]: True
傅立叶变换应用
在前面的部分中,您学习了如何将numpy.fft用于一个一维和多维ndarray,并在幕后了解了实现细节。 现在是一些应用的时候了。 在本节中,我们将使用傅立叶变换进行一些图像处理。 我们将分析频谱,然后对图像进行插值以将其放大到两倍大小。 首先,让我们从 Packt Publishing 网站博客文章中下载练习图像。 将映像另存为本地目录scientist.png。

这是 RGB 图像,这意味着,当我们将其转换为ndarray时,它将是三维的。 为了简化练习,我们使用matplotlib中的图像模块读取图像并将其转换为灰度:
In [52]: from matplotlib import image
In [53]: img = image.imread('./scientist.png')
In [54]: gray_img = np.dot(img[:,:,:3], [.21, .72, .07])
In [55]: gray_img.shape
Out[55]: (317L, 661L)
In [56]: plt.imshow(gray_img, cmap = plt.get_cmap('gray'))
Out[56]: <matplotlib.image.AxesImage at 0xa6165c0>
In [57]: plt.show()
您将得到以下图像作为结果:

预处理部分完成。 我们将图像读取到三维ndarray(img)中,并应用[亮度]公式使用0.21R + 0.72G + 0.07B将 RGB 图像转换为灰度图像 。 我们使用matplotlib中的pyplot模块显示灰度图像。 这里我们在图中未应用任何轴标签,但是从轴比例可以看到ndarray gray_img代表317 x 661像素的图像。
接下来,我们将进行傅立叶变换并显示频谱:
In [58]: fft = np.fft.fft2(gray_img)
In [59]: amp_spectrum = np.abs(fft)
In [60]: plt.imshow(np.log(amp_spectrum))
Out[60]: <matplotlib.image.AxesImage at 0xcdeff60>
In [61]: plt.show()
此代码将给出以下输出:

首先,我们对gray_img使用二维傅立叶变换,并使用对数刻度色图绘制幅度谱。 我们可以看到,由于零频率分量,拐角有所不同。 请记住,当我们使用numpy.fft.fft2()时,该顺序遵循标准的顺序,并且我们希望将零频分量置于中心。 因此,让我们使用shift例程:
In [62]: fft_shift = np.fft.fftshift(fft)
In [63]: plt.imshow(np.log(np.abs(fft_shift)))
Out[63]: <matplotlib.image.AxesImage at 0xd201dd8>
In [64]: plt.show()
这会将图像更改为:

现在我们可以看到零频率分量位于中心。 让我们转到本练习的最后一步:对图像进行插值以扩大尺寸。 我们在这里使用的技术非常简单。 我们将零频率插值到fft_shift数组中,并使它变成两倍大小。 然后我们将fft_shift逆转为标准阶数,并进行另一次逆转换回到原始域:
In [65]: m, n = fft_shift.shape
In [66]: b = np.zeros((int(m / 2), n))
In [67]: c = np.zeros((2 * m - 1, int(n / 2)))
In [68]: fft_shift = np.concatenate((b, fft_shift, b), axis = 0)
In [69]: fft_shift = np.concatenate((c, fft_shift, c), axis = 1)
In [70]: ifft = np.fft.ifft2(np.fft.ifftshift(fft_shift))
In [71]: ifft.shape
Out[71]: (633L, 1321L)
In [72]: ifft = np.real(ifft)
In [73]: plt.imshow(ifft, cmap = plt.get_cmap('gray'))
Out[73]: <matplotlib.image.AxesImage at 0xf9a0f98>
In [74]: plt.show()

在上一个代码块中,我们首先获取了fft_shift数组的形状(大小与gray_img相同)。 然后我们创建了两个零ndarrays并将它们沿四个方向填充到fft_shift数组中以将其放大。 因此,当我们将修改后的fft_shift数组逆回到标准阶数时,零频率将完美地位于中间。 当我们进行逆变换时,您可以看到形状已经加倍。 为了让pyplot模块绘制新数组,我们需要将数组转换为实数。 绘制新数组后,我们可以看到轴刻度是其大小的两倍。 而且,我们几乎不会丢失任何细节或图像模糊。 已使用傅立叶变换对图像进行插值。
总结
在本章中,我们介绍了一维和多维傅立叶变换的用法以及它们在信号处理中的应用方式。 现在,您了解了 NumPy 中离散傅立叶变换的实现,并且我们在手动实现的脚本与 NumPy 内置模块之间进行了性能比较。
我们还完成了图像插值的实际应用,并且由于了解matplotlib包的一些基础知识而获得了加号。
在下一章中,我们将看到如何使用numpy.distutils()子模块分发代码。
七、构建和分发 NumPy 代码
在现实世界中,您将编写一个应用,以将其分发到世界上或在其他各种计算机上重用。 为此,您希望应用以标准方式打包,以便社区中的每个人都能理解和遵循。 正如您现在已经注意到的那样,Python 用户主要使用名为pip的包管理器来自动安装其他程序员创建的模块。 Python 具有一个称为 PyPI(Python 包索引)的打包平台,该平台是 50,000 多个 Python 包的官方中央存储库。 一旦在 PyPi(又名 Cheese Shop)中注册了包,世界各地的其他用户都可以在使用pip等包管理系统对其进行配置后进行安装。 Python 随附了许多解决方案,可帮助您构建代码以准备分发给 Cheese Shop ,并且在本章中,我们将重点介绍两个此类工具,setuptools 和Distutils 除了这两个工具之外,我们还将研究 NumPy 提供的称为numpy.distutils的特定模块。 该模块使程序员更容易构建和分发特定于 NumPy 的代码。 该模块还提供了其他函数,例如用于编译 Fortran 代码,调用f2py等方法。 在本章中,我们将通过以下步骤来学习包装工作流程:
- 我们将建立一个小的但可行的设置
- 我们将说明将 NumPy 模块集成到您的设置中的步骤
- 我们将说明如何在互联网上注册和分发您的应用
Distutils 和 Setuptools 简介
在开始之前,首先让我们了解这些工具是什么以及为什么我们偏爱另一个工具。 Distutils是 Python 默认提供的框架,setuptools建立在标准Distutils的基础上,以提供增强的功能和特性。 在现实世界中,您将永远不会使用Distutils。 您可能想单独使用Distutils的唯一情况是setuptools不可用。 (良好的设置脚本应在继续之前检查setuptools的可用性。)在大多数情况下,用户最好安装setuptools,因为当今大多数包都是基于它们构建的。 在接下来的章节中,我们将使用setuptools来构建 Cython 代码; 因此,出于我们的目的,我们现在将安装setuptools并从现在开始广泛使用它。
接下来,让我们从安装必需的工具开始,以构建我们的第一个虚拟(但有效)安装程序。 安装程序正常运行后,我们将在 Pandas 脚本模块的真实脚本中深入介绍 NumPy 的更多功能。 我们将研究脚本中进行的检查,以使其更强大,以及在发生故障时如何提供更多信息。
准备工具
要在您的系统上安装setuptools,您需要先从这里下载系统中的ez_setup.py,然后从命令提示符处执行以下操作 :
$ python ez_setup.py
要测试setuptools的安装,请打开 Python shell 并键入以下内容:
> import setuptools
如果前面的导入没有给出任何错误,则说明我们已成功安装setuptools。
建立第一个有效的发行版
我们前面提到的所有工具(setuptools,Distutils和numpy.distutils)都围绕setup函数。 为了了解大多数包装要求,我们将研究一个简单的setup函数,然后研究一个成熟的安装程序。 要创建基本的安装程序,我们需要使用有关包的元数据调用setup函数。 让我们叫第一个包py_hello,它只有一个函数greeter,并且在调用时只打印一条消息。 可从 Bitbucket 存储库下载该包。该项目的目录结构如下:
py_hello
├── README
├── MANIFEST.in
├── setup.py
├── bin
│ └── greeter.bat
└── greeter
├── __init__.py
├── greeter.py
让我们在这里看一些标准文件:
-
README- 此文件用于存储有关您的项目的信息。 该文件不是系统所需的文件,如果没有该文件,您仍将获得安装程序的构建,但是将其保留在此处是一种很好的做法。 -
MANIFEST.in- 这是一个文本文件,Distutils使用该文本文件来收集项目中的所有文件。 这非常重要,只有此处列出的文件才会进入最终安装程序tar存档。 除了指定最终安装程序中应包含的文件之外,manifest还可以用于从项目目录中排除某些文件。manifest文件是必需的; 如果不存在,则在使用setup.py时会出现错误。 如果您具有svn设置,则可以使用sdist命令通过解析.svn文件并构建manifest.in文件来自动包含文件。 -
__init__.py- 该文件对于 Python 将该目录识别为模块很重要。 创建后可以将其留空。
要为此安装程序创建安装程序,我们在根目录中有setup.py,它使用setuptools中的setup函数:
from setuptools import setup
import os
description = open(os.path.join(os.path.dirname(__file__), 'README'), 'r').read()
setup(
name = "py_hello",
packages = ["greeter"],
scripts = ["bin/greeter.bat"],
include_package_data = True,
package_data = {
"py_hello":[]
},
version = "0.1.0",
description = "Simple Application",
author = "packt",
author_email = "packt@packt.com",
url = "https://bitbucket.org/tdatta/book/py_hello",
download_url = "https://bitbucket.org/tdatta/book/py_hello/zipball/master",
keywords = ["tanmay", "example_seutp", "packt" "app"],
install_requires=[
"setup >= 0.1"],
license='LICENSE',
classifiers = [
"Programming Language :: Python",
"Development Status :: release 0.1",
"Intended Audience :: new users",
"License :: Public",
"Operating System :: POSIX :: Linux",
"Topic :: Demo",
],
long_description = description
)
以下是安装程序中使用的选项:
-
name- 这是安装 TAR 归档文件的名称。 -
packages- 这是一个列出要包含的包的列表。 -
scripts- 这是要安装到/usr/bin.等标准位置的脚本的列表。在此特定情况下,仅存在一个 echo 脚本。 这样做的目的是向读者展示如何将包附带脚本。 -
package_data- 这是字典,具有与文件列表相关联的键(包)。 -
version- 这是您的项目的版本。 这将附加到安装程序名称的末尾。 -
long_description- 在 PyPI 网站上显示时,它将转换为 HTML。 它应该包含有关您的项目打算提供的信息。 您可以直接在脚本中编写它; 但是,最佳实践是维护README文件并从此处读取说明。 -
install_required- 这是用于添加安装依赖项的列表。 您将添加代码中使用的第三方模块的名称和版本。 请注意遵循约定以在此处指定版本。 -
classifiers- 当您在 PyPI 网站上上传包时,将选中此选项。 您应该从以下网站提供的选项中进行选择。
现在,使用build选项运行setup.py应该不会给您任何错误,并生成带有.egg-info后缀的文件夹。 此时,您可以使用sdist选项运行setup.py,并创建一个可以与世界共享的包。
您应该看到最终消息为创建 tar 归档文件,如下所示:

要测试该包,可以按照以下步骤将其安装在本地计算机上:
python setup.py install
并按以下所示检查它:

这时,在cmd/bash提示符下写greeter,您将看到一条消息does nothing。 该回显消息来自greeter.bat,我们将其放置在安装文件的scripts键中。
下一部分可以添加到此框架setup.py以包括NumPy特定的功能。
添加 NumPy 和非 Python 源代码
接下来,我们将研究一些特定于 NumPy 的代码,并了解如何提高设置的错误处理能力; 通常,我们将探索一些良好的编程习惯。 我们还将展示如何将非 Python 源(c,fortran或f2py)添加到安装程序中。 以下分析显示了完整代码的一部分,您可以在随附的代码文件中或在这个页面中找到这些代码:
if sys.version_info[0] < 3:
import __builtin__ as builtins
else:
import builtins
.....
.....
.....
For full sample look for setup.py file with the accompanying CD
.....
.....
##define a function to import numpy if available and return true else false
def is_numpy_installed():
try:
import numpy
except ImportError:
return False
return True
## next we will import setuptools feature here
## We need to do this here because setuptools will "Monkey patch" the setup function
##
SETUPTOOLS_COMMANDS = set([
'develop', 'release', 'bdist_egg','bdist_rpm',
'bdist_wininst', 'install_egg_info', 'build_sphinx',
'easy_install', 'upload', 'bdist_wheel',
'--single-version-externally-managed',
])
if SETUPTOOLS_COMMANDS.intersection(sys.argv):
import setuptools
extra_setuptools_args = dict(
zip_safe-False # Custom clean command to remove build artifacts
## The main function where we link everything
def setup_package():
# check NumPy and raise excpetions
if is_numpy_installed() is False:
raise ImportError("Numerical Python (NumPy) is not installed. The package requires it be installed. Installation instruction available at the NumPy website")
from numpy.distutils.core import setup, Extension
# add extension from Fortran
ext1 = Extension(name = "firstExt",
sources = ['firstExt.f'])
ext2 = Extension(name = "convolutedExt",
sources = ['convolutedExt.pyf, stc2.f'],
include_dir = ['paths to include'],
extra_objects = "staticlib.a")
metadata = dict(name = "yourPackage",
description="short desc",
license = "licence info here",
ext_modules = [ext1, ext2]
..
# metadata as we set previously
..
**extra_setuptools_args
)
setup(**metadata)
if __name__ == "__main__":
setup_package()
上面的脚本从完整的工作设置中删除,着重于几乎所有设置脚本中都可以找到的某些方面。 这些任务确保您已完成足够的错误处理,并且脚本在不解释/提示下一步操作的情况下不会失败:
- 检查是否已安装 NumPy。 此处用来确保已安装 NumPy 的模式是一种标准模式,您可以将其用于计划使用的所有模块,并且是安装程序所必需的。 为了执行此任务,我们首先构建一个函数
is_numpy_installed尝试导入numpy并返回一个布尔值。 您可能会为安装文件可能使用的所有外部包创建类似的函数。 高级用户可以使用 Python 装饰器来以更优雅的方式进行处理。 如果此函数返回错误值,则安装程序应输出警告/信息,以防没有此包无法完成安装。 - 将
Extensions添加到设置文件中。 -
Extension类是使我们能够向安装程序中添加非 Python 代码的对象。sources参数可能包含 Fortran 源文件列表。 但是,列表源可能最多包含一个f2py签名文件,然后扩展模块的名称必须与签名文件中使用的<module>匹配。f2py签名文件必须恰好包含一个 Python 模块块,否则安装程序将无法构建。 您可以决定不在sources参数中添加签名文件。 在这种情况下,f2py将扫描 Fortran 源文件以获取常规签名,以构造 Fortran 代码的包装器。 可以使用Extension类参数f2py_options来指定f2py进程的其他选项。 这些选项不在本书的讨论范围内,大多数读者不会使用它们。 有关更多详细信息,用户可以参考api文档中的numpy.distutils扩展类。
可以按以下方式测试安装文件:
$ python <setup.py file> build_src build_ext --help
这里的build_src参数用于构造 Fortran 包装器扩展模块。 这里假定用户在其计算机上安装了 C/C++ 和 Fortran 编译器。
测试您的包
非常重要的一点是,所构建的包可以在用户的计算机上正常运行/安装。 因此,您应该花时间测试包。 测试安装背后的总体思路是创建一个 VirtualEnv 并尝试安装该包或完全使用另一个系统。 在此阶段遇到的任何错误都应删除,并且作者应尝试确保更容易遵循这些异常。 异常也应尝试提供解决方案。 此阶段的常见错误是:
- 关于预装模块和库的假设。
- 开发人员可能会忘记在安装文件中包含依赖项。 如果使用新的 VirtualEnv 来测试安装程序,则会捕获此错误。
- 权限和提升权限的要求。
- 某些用户可能对计算机具有只读访问权限。 这很容易被忽略,因为大多数开发人员在自己的机器上都没有这种情况。 如果包的提供者遵循正确的方法来选择要写入的目录,则应该不会出现此问题。 通常,通过使用没有管理员访问权限的用户测试脚本来检查这种情况是一种很好的做法。
分发您的应用
完成模块/应用的所有开发并准备好完整的正常工作的应用和设置文件后,下一个任务就是与世界分享您的辛勤工作,使他人受益。 使用 PyPI 将其发布到全世界的步骤非常简单。 作为包作者,您需要做的第一件事就是注册自己。 您可以直接从命令行执行以下操作:
**$ python setup.py register
running register
running egg_info
....
....
We need to know who you are, so please choose either:
1\. use your existing login,
2\. register as a new user,
3\. have the server generate a new password for you (and email it to you), or
4\. quit
Your selection [default 1]:**
提示
如果setup.py中缺少任何文件的正确元数据信息,则此过程将失败。 确保首先工作setup.py。
最后,您可以通过执行以下操作在 PyPI 上上传您的发行版:
$ python setup.py sdist upload
希望,如果您正确键入了所有内容,您的应用将被打包并在 PyPI 上供世界使用。
总结
在本章中,我们介绍了用于打包和分发应用的工具。 我们首先看了一个更简单的setup.py文件。 您研究了setup函数的属性以及这些参数如何链接到最终安装程序。 接下来,我们添加了与 NumPy 相关的代码,并添加了一些异常处理代码。 最后,我们构建了安装程序并学习了如何在 Cheese Shop(PyPI 网站)上上传它。 在下一章中,您将研究通过将 Python 代码的一部分转换为 Cython 来进一步加速 Python 代码的方法。
八、使用 Cython 加速 NumPy
Python 与 NumPy 库相结合为用户提供了编写高度复杂的函数和分析的工具。 随着代码的大小和复杂性的增长,代码库中的低效率问题开始蔓延。一旦项目进入完成阶段,开发人员就应开始关注代码的性能并分析瓶颈。 Python 提供了许多工具和库来创建优化且性能更快的代码。
在本章中,我们将研究一种名为 Cython 的工具。 Cython 是 Python 和“Cython”语言的静态编译器,在从事科学库/数值计算的开发人员中特别流行。 许多用 Python 编写的著名分析库都大量使用 Cython(Pandas,SciPy,scikit-learn 等)。
Cython 编程语言是 Python 的超集,用户仍然喜欢 Python 所提供的所有功能和更高层次的结构。 在本章中,我们将研究 Cython 起作用的许多原因,并且您将学习如何将 Python 代码转换为 Cython。 但是,本章不是 Cython 的完整指南。
在本章中,我们将介绍以下主题:
- 在我们的计算机上安装 Cython
- 将少量 Python 代码重写为 Cython 版本并进行分析
- 学习在 Cython 中使用 NumPy
优化代码的第一步
每个开发人员在优化其代码时应注意的问题如下:
- 您的代码执行多少个函数调用?
- 有多余的调用吗?
- 该代码使用了多少内存?
- 是否存在内存泄漏?
- 瓶颈在哪里?
前四个问题主要由分析器工具回答。 建议您至少学习一种分析工具。 分析工具将不在本章中介绍。 在大多数情况下,建议先尝试优化函数调用和内存使用,然后再使用低级方法,例如 Cython 或汇编语言(使用 C 衍生语言)。
一旦确定了瓶颈,并且解决了算法和逻辑的所有问题,Python 开发人员便可以进入 Cython 的世界,以提高应用的速度。
设置 Cython
Cython 是一个将类型定义的 Python 代码转换为 C 代码的编译器,该代码仍在 Python 环境中运行。 最终输出是本机代码,其运行速度比 Python 生成的字节码快得多。 在大量使用循环的代码中,Python 代码加速的幅度更加明显。 为了编译 C 代码,首要条件是在计算机上安装 C/C++ 编译器,例如gcc(Linux)或mingw(Windows)。
第二步是安装 Cython。 Cython 与其他带有 Python 模块的库一样,可以使用任何首选的方法(PIP,EasyInstall 等)进行安装。 完成这两个步骤后,您可以通过尝试从 Shell 调用 Cython 来测试设置。 如果收到错误消息,则说明您错过了第二步,需要重新安装 Cython 或从 Cython 官方网站下载 TAR 归档文件,然后从这次下载的root文件夹中运行以下命令:
python setup.py install
正确完成所有操作后,您可以继续使用 Cython 编写第一个程序。
Cython 中的 Helloworld
Cython 程序看起来与 Python 程序非常相似,但大多带有附加的类型信息。 让我们看一个简单的程序,该程序计算给定n的第n个斐波那契数:
defcompute_fibonacchi(n):
"""
Computes fibonacchi sequence
"""
a = 1
b = 1
intermediate = 0
for x in xrange(n):
intermediate = a
a = a + b
b = intermediate
return a
让我们研究一下该程序,以了解在调用带有某些数字输出的函数时幕后的情况。 假设compute_fibonacchi(3)。
众所周知,Python 是一种解释性和动态语言,这意味着您无需在使用变量之前声明变量。 这意味着在函数调用开始时,Python 解释器无法确定n将保留的值的类型。 当您使用某个整数值调用函数时,Python 会通过名为装箱和拆箱的过程自动为您进行类型推断。
在 Python 中,一切都是对象。 因此,当您输入1或hello时,Python 解释器将在内部将其转换为对象。 在许多在线材料中,此过程也称为拳击。 该过程可以可视化为:

那么当您将函数应用于对象时会发生什么呢? Python 解释器必须做一些额外的工作来推断类型并应用函数。 在一般意义上,下图说明了add函数在 Python 中的应用。 Python 是一种解释型语言,它在优化函数调用方面做得并不出色,但是可以使用 C 或 Cython 很好地优化它们:

这种装箱和拆箱不是免费的,需要花费宝贵的计算时间。 当这样的操作被循环执行多次时,效果变得更加显着。
在n = 20上运行时,以下程序在 IPython 笔记本上每个循环大约需要 1.8 微秒:

现在让我们将该程序重写为 Cython:
defcompute_fibonacchi_cython(int n):
cdefint a, b, intermediate, x
a, b= 1, 1
intermediate, x = 0, 0
for x in xrange(n):
intermediate = a
a = a+b
b = intermediate
return a
该程序每个循环花费64.5纳秒:

提示
尽管在此示例代码中提高速度非常重要,但这不是您将遇到的实际代码,因此您应始终记住首先在代码上运行分析器并确定需要优化的部分。 同样,在使用 Cython 时,开发人员应考虑在使用静态类型和灵活性之间进行权衡。 使用类型会降低灵活性,有时甚至会降低可读性。
通过删除xrange并改用for循环,可以进一步改进此代码。 当您对模块的所有组件/功能都满意并且没有错误后,用户可以将这些函数/过程存储在扩展名为.pyx的文件中。 这是 Cython 使用的扩展名。 将此代码与您的应用集成的下一步是在安装文件中添加信息。
在这里,出于说明目的,我们将代码存储在名为fib.pyx的文件中,并创建了一个构建该模块的安装文件:
from distutils.core import setup, Extension
from Cython.Build import cythonize
from Cython.Distutils import build_ext
setup(
ext_modules=[Extension('first', ['first.pyx'])],
cmdclass={'build_ext': build_ext}
)
在这里,请注意扩展名first 的名称与模块的名称完全匹配。 如果您无法保持相同的名称,则将收到一个神秘的错误:

多线程代码
您的应用可能会使用多线程代码。 由于全局解释器锁(GIL),Python 不适合多线程代码。 好消息是,在 Cython 中,您可以显式解锁 GIL,并使您的代码真正成为多线程。 只需在您的代码中放置一个with nogil:语句即可。 您以后可以在代码中使用with gil获取 GIL:
with nogil:
<The code block here>
function_name(args) with gil:
<function body>
NumPy 和 Cython
Cython 具有内置支持,可提供对 NumPy 数组的更快访问。 这些功能使 Cython 成为优化 NumPy 代码的理想人选。 在本节中,我们将研究用于计算欧式期权价格的代码,欧式期权是一种使用蒙特卡洛技术的金融工具。 不期望有金融知识; 但是,我们假设您对蒙特卡洛模拟有基本的了解:
defprice_european(strike = 100, S0 = 100, time = 1.0,
rate = 0.5, mu = 0.2, steps = 50,
N = 10000, option = "call"):
dt = time / steps
rand = np.random.standard_normal((steps + 1, N))
S = np.zeros((steps+1, N));
S[0] = S0
for t in range(1,steps+1):
S[t] = S[t-1] * np.exp((rate-0.5 * mu ** 2) * dt
+ mu * np.sqrt(dt) * rand[t])
price_call = (np.exp(-rate * time)
* np.sum(np.maximum(S[-1] - strike, 0))/N)
price_put = (np.exp(-rate * time)
* np.sum(np.maximum(strike - S[-1], 0))/N)
returnprice_call if option.upper() == "CALL" else price_put
以下是前面示例的 Cython 化代码:
import numpy as np
def price_european_cython(double strike = 100,doubleS0 = 100,
double time = 1.0, double rate = 0.5,
double mu = 0.2, int steps = 50,
long N = 10000, char* option = "call"):
cdef double dt = time / steps
cdefnp.ndarray rand = np.random.standard_normal((steps + 1, N))
cdefnp.ndarray S = np.zeros([steps+1, N], dtype=np.float)
#cdefnp.ndarrayprice_call = np.zeroes([steps+1,N], dtype=np.float)
S[0] = S0
for t in xrange(1,steps+1):
S[t] = S[t-1] * np.exp((rate-0.5 * mu ** 2) * dt
+ mu * np.sqrt(dt) * rand[t])
price_call = (np.exp(-rate * time)
* np.sum(np.maximum(S[-1] - strike, 0))/N)
price_put = (np.exp(-rate * time)
* np.sum(np.maximum(strike - S[-1], 0))/N)
return price_call if option.upper() == "CALL" else price_put
与此相关的安装文件如下所示:
from distutils.core import setup, Extension
from Cython.Build import cythonize
from Cython.Distutils import build_ext
import numpy.distutils.misc_util
include_dirs = numpy.distutils.misc_util.get_numpy_include_dirs()
setup(
name="numpy_first",
version="0.1",
ext_modules=[Extension('dynamic_BS_MC',
['dynamic_BS_MC.pyx'],
include_dirs = include_dirs)],
cmdclass={'build_ext': build_ext}
)
虽然通过 Cython 代码获得的加速效果非常好,并且您可能会倾向于在 Cython 中编写大多数代码,但建议仅将性能至关重要的部分转换为 Cython。 NumPy 在优化对数组的访问和执行更快的计算方面做得非常出色。 该代码可以视为描述该代码的理想候选者。 前面的代码有很多“松散的结果”,可以当作练习来解决 Python 中的性能问题,并在采用 Cython 方式之前先最佳地使用 NumPy。 由于 Python 的动态特性,盲目地对 NumPy 代码进行 Cython 化的速度提升可能不如具有真正问题的最优编写代码那样快。
最后,我们介绍在 Cython 中开发模块时应遵循的以下内容:
- 用纯 Python 编写代码并进行测试。
- 运行分析器并确定要关注的关键区域。
- 创建一个新模块以保存 Cython 代码(
<module_name>.pyx)。 - 将这些区域中的所有变量和循环索引转换为它们的 C 对应物。
- 使用以前的测试设置进行测试。
- 将扩展添加到安装文件中。
总结
在本章中,我们了解了如何将 Python 代码隐蔽到 Cython 中。 我们还研究了一些涉及 NumPy 数组的示例 Python 代码。 我们简要介绍了 Python 语言中装箱和拆箱的概念以及它们如何影响代码性能。 我们还说明了如何显式解锁臭名昭著的 GIL。 为了进一步深入研究 Cython,我们建议《Cython 编程学习手册》,Philip Herron,Packt Publishing。 在下一章中,您将了解 NumPy C API 以及如何使用它。
九、NumPy C-API 简介
NumPy 是一个通用库,旨在满足科学应用开发人员的大多数需求。 但是,随着应用的代码库和覆盖范围的增加,计算也随之增加,有时用户需要更具体的操作和优化的代码段。 我们已经展示了 NumPy 和 Python 如何具有诸如 F2PY 和 Cython 之类的工具来满足这些需求。 这些工具可能是将函数重写为本地编译代码以提高速度的绝佳选择。 但是在某些情况下(利用 C 库,例如 NAG 编写一些分析),您可能想做一些更根本的事情,例如为您自己的库专门创建新的数据结构。 这将要求您有权访问 Python 解释器中的低级控件。 在本章中,我们将研究如何使用 Python 及其扩展名 NumPy C-API 提供的 C-API 进行此操作。 C-API 本身是一个非常广泛的主题,可能需要一本书才能完全涵盖它。 在这里,我们将提供简短的介绍和示例,以帮助您开始使用 NumPy C-API。
本章将涉及的主题是:
- Python C-API 和 NumPy C-API
- 扩展模块的基本结构
- 一些特定于 NumPy 的 C-API 函数的简介
- 使用 C-API 创建函数
- 创建一个可调用的模块
- 通过 Python 解释器和其他模块使用模块
Python 和 NumPy C-API
我们使用的 Python 实现是 Python 解释器的基于 C 的实现。 NumPy 专用于此基于 C 的 Python 实现。 Python 的此实现带有 C-API,它是解释器的基础,并向其用户提供低级控制。 NumPy 通过提供丰富的 C-API 进一步增强了这一功能。
用 C/C++ 编写函数可以为开发人员提供灵活性,以利用这些语言提供的一些高级库。 但是,就必须在解析输入周围编写太多样板代码以构造返回值而言,代价显而易见。 此外,开发人员在引用/解引用对象时必须格外小心,因为这最终可能会导致讨厌的错误和内存泄漏。 随着 C-API 的不断发展,还存在代码未来兼容性的问题。 因此,如果开发人员想要迁移到更高版本的 Python,则他们可能需要为这些基于 C-API 的扩展进行大量维护工作。 由于这些困难,大多数开发人员选择尝试其他优化技术。 (例如 Cython 或 F2PY),然后再探索这条路径。 但是,在某些情况下,您可能想重用 C/C++ 中的其他现有库,这可能适合您的特定目的。 在这些情况下,最好为现有函数编写包装并公开 Python 项目。
接下来,我们将看一些示例代码,并在本章继续介绍时解释其关键函数和宏。 此处提供的代码与 Python 2.X 版本兼容,可能不适用于 Python 3.X。 但是,转换过程应该相似。
提示
开发人员可以尝试使用称为 cpychecker 的工具来检查模块中的引用计数时的常见错误。 请访问这里了解更多详细信息。
扩展模块的基本结构
用 C 编写的扩展模块将包含以下部分:
- 标头段,其中包含所有外部库和
Python.h - 初始化段,您可以在其中定义模块名称和 C 模块中的函数
- 方法结构数组,用于定义模块中的所有函数
- 一个实现部分,您在其中定义要公开的所有函数
标头段
标题片段是非常标准的,就像普通的 C 模块一样。 我们需要包括Python.h头文件,以使我们的 C 代码可以访问 C-API 的内部。 该文件位于<path_to_python>/include中。 我们将在示例代码中使用数组对象,因此我们也包含了numpy/arrayobject.h头文件。 我们不需要在此处指定头文件的完整路径,因为路径解析是在setup.py中处理的,我们将在后面进行介绍:
/*
Header Segment
*/
##include <Python.h>
##include <math.h>
##include <numpy/arrayobject.h>
Initialization Segment
初始化段
初始化段从以下内容开始:
- 调用
PyMODINIT_FUNC宏。 此宏在 Python 标头中定义,并且在开始定义模块之前总是会被调用。 - 下一行定义了初始化函数,并在加载该函数时由 Python 解释器调用。 函数名称必须为
init<module_name>格式,C 代码将要公开的模块和函数的名称。
该函数的主体包含对Py_InitModule3的调用,该调用定义模块的名称和模块中的函数。 该函数的一般结构如下:
(void)Py_InitModule3(name_of_module, method_array, Docstring)
对import_array()的最终调用是特定于 NumPy 的函数,如果您的函数正在使用 Numpy 数组对象,则需要此函数。 这样可以确保加载 C-API,以便如果您的 C++ 代码使用 C-API,则 API 表可用。 未能调用此函数和使用其他 NumPy API 函数将很可能导致分段错误错误。 建议您阅读 NumPy 文档中的import_array()和import_ufunc():
/*
Initialization module
*/
PyMODINIT_FUNC
initnumpy_api_demo(void)
{
(void)Py_InitModule3("numpy_api_demo", Api_methods,
"A demo to show Python and Numpy C-API");
import_array();
}
方法结构数组
在此部分中,您将定义模块将要公开给 Python 的方法数组。 我们在这里定义了两个函数以求其平方。 一种方法将普通的 Python double值作为输入,第二种方法对 Numpy 数组进行操作。 PyMethodDef结构可以在 C 中定义如下:
Struct PyMethodDef {
char *method_name;
PyCFunction method_function;
int method_flags;
char *method_docstring;
};
这是此结构的成员的描述:
-
method_name:函数的名称在此处。 这将是函数向 Python 解释器公开的名称。 -
method_function:此变量保存在 Python 解释器中调用method_name时实际调用的 C 函数的名称。 -
method_flags:这告诉解释器我们的函数正在使用三个签名中的哪个。 该标志的值通常为METH_VARARGS。 如果要允许关键字参数进入函数,可以将该标志与METH_KEYWORDS组合。 它也可以具有METH_NOARGS的值,这表明您不想接受任何参数。 -
method_docstring:这是函数的文档字符串。
该结构需要以一个由NULL和 0 组成的标记终止,如以下示例所示:
/*
Method array structure definition
*/
static PyMethodDefApi_methods[] =
{
{"py_square_func", square_func, METH_VARARGS, "evaluate the squares"},
{"np_square", square_nparray_func, METH_VARARGS, "evaluates the square in numpy array"},
{NULL, NULL, 0, NULL}
};
实现部分
实现部分是最直接的部分。 这就是方法的 C 定义所要去的地方。 在这里,我们将研究两个函数来平方它们的输入值。 这些函数的复杂度保持在较低水平,以便您专注于方法的结构。
使用 Python C-API 创建数组平方函数
Python 函数将对自身的引用作为第一个参数,然后是赋予该函数的真实参数。 PyArg_ParseTuple函数用于将 Python 函数中的值解析为 C 函数中的局部变量。 在此函数中,我们将值强制转换为双精度,因此我们将d用作第二个参数。 您可以在这个页面上查看此函数接受的字符串的完整列表。
使用Py_Buildvalue返回计算的最终结果,它使用类似类型的格式字符串从您的答案中创建 Python 值。 我们在这里使用f表示浮点数,以证明对double和float的处理方式类似:
/*
Implementation of the actual C funtions
*/
static PyObject* square_func(PyObject* self, PyObject* args)
{
double value;
double answer;
/* parse the input, from python float to c double */
if (!PyArg_ParseTuple(args, "d", &value))
return NULL;
/* if the above function returns -1, an appropriate Python exception will
* have been set, and the function simply returns NULL
*/
answer = value*value;
return Py_BuildValue("f", answer);
}
使用 NumPy C-API 创建数组平方函数
在本节中,我们将创建一个函数以对 NumPy 数组的所有值求平方。 这里的目的是演示如何在 C 语言中获取 NumPy 数组,然后对其进行迭代。 在现实世界中,可以使用映射或通过向量化平方函数以更简单的方式完成此操作。 我们正在使用与O!格式字符串相同的PyArg_ParseTuple函数。 该格式字符串具有(object) [typeobject, PyObject *]签名,并以 Python 类型对象作为第一个参数。 用户应阅读官方 API 文档,以查看允许使用其他格式的字符串以及哪种字符串适合他们的需求:
注意
如果传递的值的类型不同,则引发TypeError。
以下代码段说明了如何使用PyArg_ParseTuple解析参数。
// Implementation of square of numpy array
static PyObject* square_nparray_func(PyObject* self, PyObject* args)
{
// variable declarations
PyArrayObject *in_array;
PyObject *out_array;
NpyIter *in_iter;
NpyIter *out_iter;
NpyIter_IterNextFunc *in_iternext;
NpyIter_IterNextFunc *out_iternext;
// Parse the argument tuple by specifying type "object" and putting the reference in in_array
if (!PyArg_ParseTuple(args, "O!", &PyArray_Type, &in_array))
return NULL;
......
......
下一步是创建一个数组以存储其输出值和迭代器,以便在 Numpy 数组上进行迭代。 请注意,创建对象时,每个步骤都有一个{handle failure}代码。 这是为了确保如果发生任何错误,我们可以通过调试来确定错误代码的位置:
//Construct the output from the new constructed input array
out_array = PyArray_NewLikeArray(in_array, NPY_ANYORDER, NULL, 0);
// Test it and if the input is nothing then just return nothing.
{handle failure}
// Create the iterators
in_iter = NpyIter_New(in_array, NPY_ITER_READONLY, NPY_KEEPORDER,
NPY_NO_CASTING, NULL);
// {handle failure}
out_iter = NpyIter_New((PyArrayObject *)out_array, NPY_ITER_READWRITE,
NPY_KEEPORDER, NPY_NO_CASTING, NULL);
{handle failure}
in_iternext = NpyIter_GetIterNext(in_iter, NULL);
out_iternext = NpyIter_GetIterNext(out_iter, NULL);
{handle failure}
double ** in_dataptr = (double **) NpyIter_GetDataPtrArray(in_iter);
double ** out_dataptr = (double **) NpyIter_GetDataPtrArray(out_iter);
A simple handle failure module is like
// {Start handling failure}
if (in_iter == NULL)
// remove the ref and return null
Py_XDECREF(out_array);
return NULL;
// {End handling failure}
看了前面的样板代码之后,我们终于来到了发生所有实际动作的部分。 那些熟悉 C++ 的人会发现迭代方法与向量迭代相似。 我们之前定义的in_iternext函数在这里派上用场,用于迭代 Numpy 数组。 在while循环之后,我们确保在两个迭代器上都调用了NpyIter_Deallocate,在输出数组上调用了Py_INCREF; 未能调用这些函数是导致内存泄漏的最常见错误类型。 内存泄漏问题通常非常微妙,通常在具有长时间运行的代码(例如服务或守护程序)时才会出现。 要抓住这些问题,不幸的是,没有比使用调试器更深入的方法容易的方法了。 有时,只需要编写几个printf语句即可输出总内存使用情况:
/* iterate over the arrays */
do {
out_dataptr =pow(**in_dataptr,2);
} while(in_iternext(in_iter) && out_iternext(out_iter));
/* clean up and return the result */
NpyIter_Deallocate(in_iter);
NpyIter_Deallocate(out_iter);
Py_INCREF(out_array);
return out_array;
构建和安装扩展模块
成功编写函数后,下一步是构建模块并在我们的 Python 模块中使用它。 setup.py文件看起来像以下代码片段:
from distutils.core import setup, Extension
import numpy
## define the extension module
demo_module = Extension('numpy_api_demo', sources=['numpy_api.c'],
include_dirs=[numpy.get_include()])
## run the setup
setup(ext_modules=[demo_module])
由于我们使用特定于 NumPy 的标头,因此我们需要在include_dirs变量中具有numpy.get_include函数。 要运行此安装文件,我们将使用一个熟悉的命令:
python setup.py build_ext -inplace
前面的命令将在目录中创建一个numpy_api_demo.pyd文件,供我们在 Python 解释器中使用。
为了测试我们的模块,我们将打开一个 Python 解释器测试,并尝试像我们对用 Python 编写的模块所做的一样,从该模块调用这些函数:
>>>import numpy_api_demo as npd
>>> import numpy as np
>>>npd.py_square_func(4)
>>> 16.0
>>> x = np.arange(0,10,1)
>>> y = npd.np_square(x)
总结
在本章中,我们向您介绍了另一种使用 Python 和 NumPy 提供的 C-API 优化或集成 C/C++ 代码的方法。 我们解释了该代码的基本结构以及其他示例代码,开发人员必须编写这些代码才能创建扩展模块。 之后,我们创建了两个函数,这些函数计算出一个数字的平方,并将该平方函数从math.h库映射到一个 Numpy 数组。 这里的目的是使您熟悉如何利用 C/C++ 编写的数字库,以最少的代码重写来创建自己的模块。 编写 C 代码的范围比这里描述的要广泛得多。 但是,我们希望本章使您有信心在需要时利用 C-API。
十、扩展阅读
NumPy 是 Python 中功能强大的科学模块; 希望在前九章中,我们已经向您展示了足以向您证明这一点的内容。 ndarray是所有其他 Python 科学模块的核心。 使用 NumPy 的最佳方法是使用numpy.ndarray作为基本数据格式,并将其与其他科学模块组合以进行预处理,分析,计算,导出等。 在本章中,我们的重点是向您介绍可以与 NumPy 一起使用的两个模块,并使您的工作/研究效率更高。
在本章中,我们将讨论以下主题:
- Pandas
- scikit-learn
- netCDF4
- SciPy
Pandas
到目前为止,pandas 是 Python 中最可取的数据预处理模块。 它处理数据的方式与 R 非常相似。它的数据框不仅为您提供视觉上吸引人的表打印输出,而且还允许您以更直观的方式访问数据。 如果您不熟悉 R,请尝试考虑以编程方式使用电子表格软件(例如 Microsoft Excel 或 SQL 表)。 这涵盖了 Pandas 所做的很多事情。
您可以从 Pandas 官方网站下载并安装 Pandas。 一种更可取的方法是使用 pip 或安装 Python 科学发行版,例如 Anaconda。
还记得我们如何使用numpy.genfromtxt()读取第 4 章, “Numpy 核心和子模块”中的csv数据吗? 实际上,使用 Pandas 来读取表格并将经过预处理的数据传递给ndarray(简单地执行np.array(data_frame)会将数据帧转换为多维ndarray)对于分析来说是更可取的工作流程。 在本节中,我们将向您展示 Pandas 的两个基本数据结构:Series(用于一维)和DataFrame(用于二维或多维)。然后,我们将向您展示如何使用 Pandas 来读取表并将数据传递给它。
然后,我们将向您展示如何使用 Pandas 读取表并将数据传递给ndarray进行进一步分析。 让我们从pandas.Series开始:
In [1]: import pandas as pd
In [2]: py_list = [3, 8, 15, 25, 11]
In [3]: series = pd.Series(py_list)
In [4]: series
Out[4]:
0 3
1 8
2 15
3 25
4 11
dtype: int64
在前面的示例中,您可以看到我们已经将 Python 列表转换为 Pandasseries,并且在打印series时,这些值完美对齐并具有与之关联的索引号(0 到 4)。 当然,我们可以指定自己的索引(以1开头或以字母形式)。 看下面的代码示例:
In [5]: indices = ['A', 'B', 'C', 'D', 'E']
In [6]: series = pd.Series(py_list, index = indices)
In [7]: series
Out[7]:
A 3
B 8
C 15
D 25
E 11
dtype: int64
我们将索引从数字更改为从A-E的字母。 更方便的是,当我们将 Python 词典转换为 Pandas Series时,执行此操作所需的键将自动成为索引。 尝试练习转换字典。 接下来,我们将探索DataFrame,这是 Pandas 中最常用的数据结构:
In [8]: data = {'Name': ['Brian', 'George', 'Kate', 'Amy', 'Joe'],
...: 'Age': [23, 41, 26, 19, 35]}
In [9]: data_frame = pd.DataFrame(data)
In [10]: data_frame
Out[10]:
Age Name
0 23 Brian
1 41 George
2 26 Kate
3 19 Amy
4 35 Joe
在前面的示例中,我们创建了DataFrame,其中包含两列:第一个是Name,第二个是Age。 您可以从打印输出中看到它看起来像一张表格,因为它的格式正确。 当然,您也可以更改数据帧的索引。 但是,数据帧的优势远不止于此。 我们可以访问每列中的数据或对其进行排序(按列名,访问data_frame.column_name或data_frame[column_name]需要两个符号); 我们甚至可以分析汇总统计信息。 为此,请看以下代码示例:
In [11]: data_frame = pd.DataFrame(data)
In [12]: data_frame['Age']
Out[12]:
0 23
1 41
2 26
3 19
4 35
Name: Age, dtype: int64
In [13]: data_frame.sort(columns = 'Age')
Out[13]:
Age Name
3 19 Amy
0 23 Brian
2 26 Kate
4 35 Joe
41 George
In [14]: data_frame.describe()
Out[14]:
Age
count 5.000000
mean 28.800000
std 9.011104
min 19.000000
25% 23.000000
50% 26.000000
75% 35.000000
max 41.000000
在前面的示例中,我们仅获得Age列,并按Age对DataFrame进行排序。 当我们使用describe()时,它将计算所有数字字段的摘要统计信息(包括计数,均值,标准差,最小值,最大值和百分位数)。在本节的最后部分,我们将使用 Pandas 读取
在本节的最后部分,我们将使用 Pandas 读取csv文件并将一个字段值传递给ndarray以进行进一步的计算。 example.csv文件来自国家统计局(ONS)。 请访问这里了解更多详细信息。 我们将在 ONS 网站上使用Sale counts by dwelling type and local authority, England and Wales(房屋类型和地方当局(英格兰和威尔士)的销售计数)。 您可以按主题名称搜索它,以访问下载页面或选择您感兴趣的任何数据集。在以下示例中,我们将示例数据集重命名为sales.csv:
In [15]: sales = pd.read_csv('sales.csv')
In [16]: sales.shape
Out[16]: (348, 97)
In [17]: sales.columns[:3]
Out[17]: Index([u'LA_Code', u'LA_Name', u'1995_COUNT_ALL_TYPES'], dtype='object')
In [18]: sales['1995_COUNT_ALL_TYPES'].head()
Out[18]:
0 1,188
1 1,652
2 1,684
3 2,314
4 1,558
Name: 1995_COUNT_ALL_TYPES, dtype: object
首先,我们将sale.csv读入名为sales的DataFrame对象; 当我们打印销售的shapes时,我们发现数据框中有 384 条记录和 97 列。 DataFrame column属性的返回列表是一个普通的 Python 列表,我们在数据中打印了前三列:LA_Code,LA_Name和1995_COUNT_ALL_TYPES。 然后,我们使用head()函数在1995_COUNT_ALL_TYPES中打印了前五个记录(tail()函数将打印后五个记录)。
同样,pandas 是 Python 中一个功能强大的预处理模块(通常,其数据处理能力超过其预处理功能,但在前面的示例中,我们仅介绍了预处理部分),并且它具有许多方便的功能来帮助您清理数据并准备数据。 您的分析。 本节仅作介绍; 由于空间限制,我们无法涵盖很多内容,例如数据透视,datetime等。 希望您能理解并开始提高脚本的效率。
scikit-learn
Scikit 是 SciPy 工具包的缩写,它是 SciPy 的附加包。 它提供了广泛的分析模块,而 scikit-learn 是其中之一。 这是迄今为止最全面的 Python 机器学习模块。 scikit-learn 提供了一种简单有效的方法来执行数据挖掘和数据分析,并且它拥有非常活跃的用户社区。
您可以从 scikit-learn 的官方网站下载并安装它。 如果您使用的是 Python 科学发行版(例如 Anaconda),则也包含在其中。
现在,是时候使用 scikit-learn 进行一些机器学习了。 scikit-learn 的优点之一是它提供了一些用于实践的样本数据集(演示数据集)。 让我们首先加载糖尿病数据集。
In [1]: from sklearn.datasets import load_diabetes
In [2]: diabetes = load_diabetes()
In [3]: diabetes.data
Out[3]:
array([[ 0.03807591, 0.05068012, 0.06169621, ..., -0.00259226,
0.01990842, -0.01764613],
[-0.00188202, -0.04464164, -0.05147406, ..., -0.03949338,
-0.06832974, -0.09220405],
[ 0.08529891, 0.05068012, 0.04445121, ..., -0.00259226,
0.00286377, -0.02593034],
...,
[ 0.04170844, 0.05068012, -0.01590626, ..., -0.01107952,
-0.04687948, 0.01549073],
[-0.04547248, -0.04464164, 0.03906215, ..., 0.02655962,
0.04452837, -0.02593034],
[-0.04547248, -0.04464164, -0.0730303 , ..., -0.03949338,
-0.00421986, 0.00306441]])
In [4]: diabetes.data.shape
Out[4]: (442, 10)
我们从sklearn.datasets中加载了一个名为diabetes的样本数据集; 它包含 442 个观测值,10 个维度,范围从 -2 到 2。 Toy数据集还提供了标记数据用于监督学习(如果您不熟悉机器学习,请尝试将标记数据视为类别)。 在我们的示例中,可以从diabetes.target调用diabetes数据集中的标记数据,范围为 25 到 346。
还记得我们在第 5 章, “numpy 中的线性代数”中如何进行线性回归吗? 我们将使用 scikit-learn 再次执行它。 同样,我建议您在开发脚本以帮助您进行研究或分析时,请使用 NumPy ndarray作为常规数据格式; 但是,对于计算,使用 scipy,scikit-learn 或其他科学模块会更好。 机器学习的优势之一是模型评估(您可以在其中训练和测试结果)。 使用此方法,我们将数据分为两个数据集:训练数据集和测试数据集,然后将这两个数据集传递给线性回归:
In [5]: from sklearn.cross_validation import train_test_split
In [6]: X_train, X_test, y_train, y_test =
train_test_split(diabetes.data,
diabetes.target,
random_state = 50)
在前面的示例中,我们使用train_test_split()函数将糖尿病数据集分为训练和测试数据集(针对数据及其类别)。 前两个参数是我们要拆分的数组。 random_state参数是可选的,这意味着伪随机数生成器状态用于随机采样。 默认拆分率是 0.25,这意味着 75% 的数据拆分为训练集,而 25% 的数据拆分为测试集。 您可以尝试打印出我们刚刚创建的训练/测试数据集,以查看其分布情况(在前面的代码示例中,X_train代表糖尿病数据的训练数据集,X_test代表糖尿病测试数据,y_train代表分类的糖尿病训练数据,y_test代表分类的糖尿病测试数据。
接下来,我们将数据集拟合为线性回归模型:
In [7]: from sklearn.linear_model import LinearRegression
In [8]: lr = LinearRegression()
In [9]: lr.fit(X_train, y_train)
Out[9]: LinearRegression(copy_X = True, fit_intercept = True,
Normalize = False)
In [10]: lr.coef_
Out[10]:
array([ 80.73490856, -195.84197988, 474.68083473, 371.06688824,
-952.26675602, 611.63783483, 174.40777144, 159.78382579,
832.01569658, 12.04749505])
首先,我们从sklearn.linear_model创建了一个LinearRegression对象,并使用fit()函数拟合了X_train和y_train数据集。 我们可以通过调用coef_属性来检查线性回归的估计系数。 此外,我们可以使用拟合的线性回归进行预测。 看下面的例子:
In [11]: lr.predict(X_test)[:10]
Out[11]:
array([ 71.96974998, 82.55916305, 265.71560021, 79.37396336,
72.48674613, 47.01580194, 149.11263906, 185.36563936,
94.88688296, 132.08984366])
predict()函数用于基于我们拟合训练数据集的线性回归来预测测试数据集; 在前面的示例中,我们打印了前 10 个预测值。 这是y的预测值和测试值的图:

In [12]: lr.score(X_test, y_test)
Out[12]: 0.48699089712593369
然后,我们可以使用score()函数检查预测的确定 R 平方。
这几乎是 scikit-learn 中的标准拟合和预测过程,并且非常直观且易于使用。 当然,除了回归之外,scikit-learn 还可以执行许多分析,例如分类,聚类和建模。 希望本节对您的脚本有所帮助。
netCDF4
netCDF4 是 netCDF 库的第四个版本,该库是在 HDF5(分层数据格式,旨在存储和组织大量数据)的基础上实现的,从而可以管理非常大和复杂的多维数据。 netCDF4 的最大优点是,它是一种完全可移植的文件格式,对集合中数据对象的数量或大小没有限制,并且在可归档的同时也可以追加。 许多科研组织将其用于数据存储。 Python 还具有访问和创建此类数据格式的接口。
您可以从官方文档页面,或从这里下载并安装该模块。 它不包含在标准的 Python 科学发行版中,但已内置在 NumPy 中,可以与 Cython 一起构建(建议但并非必需)。
对于以下示例,我们将使用 Unidata 网站上的示例netCDF4文件,该文件位于这里,并且我们将以气候系统模型为例:sresa1b_ncar_ccsm3-example.nc
首先,我们将使用netCDF4模块稍微探索一下数据集,并提取我们需要进行进一步分析的值:
In [1]: import netCDF4 as nc
In [2]: dataset = nc.Dataset('sresa1b_ncar_ccsm3-example.nc', 'r')
In [3]: variables = [var for var in dataset.variables]
In [4]: variables
Out[4]:
['area', 'lat', 'lat_bnds', 'lon', 'lon_bnds', 'msk_rgn', 'plev',
'pr', 'tas', 'time', 'time_bnds', 'ua']
我们导入了 python netCDF4模块,并使用Dataset()函数读取了示例netCDF4文件。 r参数表示文件处于只读模式,因此当我们要附加文件或w创建新文件时,我们也可以指定a。 然后,我们获得了存储在数据集中的所有变量,并将它们保存到名为变量的列表中(请注意,variables属性将返回变量对象的 Python 字典)。 最后,我们使用以下命令在数据集中打印出变量:
In [5]: precipitation = dataset.variables['pr']
In [6]: precipitation.standard_name
Out[6]: 'precipitation_flux'
In [7]: precipitation.missing_value
Out[7]: 1e+20
In [8]: precipitation.ndim
Out[8]: 3
In [9]: precipitation.shape
Out[9]: (1, 128, 256)
In [10]: precipitation[:, 1, :10]
Out[10]:
array([[ 8.50919207e-07, 8.01471970e-07, 7.74396426e-07,
7.74230614e-07, 7.47181844e-07, 7.21426375e-07,
7.19294349e-07, 6.99790974e-07, 6.83397502e-07,
6.74683179e-07]], dtype=float32)
在前面的示例中,我们选择了一个名为pr的变量并将其保存到precipitation中。 众所周知netCDF4是一种自我描述的文件格式; 您可以创建和访问存储在变量中的任何用户定义属性,尽管最常见的是standard_name,它告诉我们该变量代表降水通量。 我们检查了另一个常用属性missing_value,该属性表示存储在netCDF4文件中的无数据值。 然后,我们通过ndim来打印降水量的维数,并通过shape属性来打印形状。 最后,我们要获取第 1 行的值,即netCDF4文件中的前 10 列; 为此,只需像往常一样使用索引。
接下来,我们将介绍创建netCDF4文件并将三维 NumPy ndarray作为变量存储的基础知识:
In [11]: import numpy as np
In [12]: time = np.arange(10)
In [13]: lat = 54 + np.random.randn(8)
In [14]: lon = np.random.randn(6)
In [15]: data = np.random.randn(480).reshape(10, 8, 6)
首先,我们准备了一个三维ndarray(数据)以存储在netCDF4文件中; 数据建立在三个维度中,分别是时间(time,大小为 10),纬度(lat,大小为 8)和经度(lon,大小为 6)。 在netCDF4中,时间不是datetime对象,而是从定义的开始时间(在unit属性中指定)开始的时间单位数(可以是秒,小时,天等)。 稍后再向您解释)。 现在,我们拥有了要存储在文件中的所有数据,因此让我们构建 netCDF 结构:
In [16]: output = nc.Dataset('test_output.nc', 'w')
In [17]: output.createDimension('time', 10)
In [18]: output.createDimension('lat', 8)
In [19]: output.createDimension('lon', 6)
In [20]: time_var = output.createVariable('time', 'f4', ('time',))
In [21]: time_var[:] = time
In [22]: lat_var = output.createVariable('lat', 'f4', ('lat',))
In [23]: lat_var[:] = lat
In [24]: lon_var = output.createVariable('lon', 'f4', ('lon',))
In [25]: lon_var[:] = lon
我们通过指定文件路径并使用w写入模式来初始化netCDF4文件。 然后,我们使用createDimension()构建结构以指定尺寸:time,lat和lon。 每个尺寸都有一个变量来表示其值,就像轴的刻度一样。 接下来,我们将把三维数据保存到文件中:
In [26]: var = output.createVariable('test', 'f8', ('time', 'lat', 'lon'))
In [27]: var[:] = data
变量的创建始终从createVariable()函数开始,并指定变量名称,变量数据类型以及与其关联的维。 第二步是将ndarray 的相同形状传递到声明的变量中。 现在我们已经将整个数据存储在文件中,我们可以指定属性以帮助描述数据集。 以下示例使用time变量说明如何指定属性:
In [28]: time_var.standard_name = 'Time'
In [29]: time_var.units = 'days since 2015-01-01 00:00:00'
In [30]: time_var.calendar = 'gregorian'
因此,现在时间变量已与单位和日历相关联,因此ndarray时间将根据我们指定的单位和日历转换为日期; 这类似于所有变量。 完成netCDF4文件的创建后,最后一步是关闭文件连接:
In [31]: output.close()
上面的代码向您展示了 Python netCDF4 API 的用法,以便读取和创建netCDF4文件。 该模块不包含任何科学计算(因此它不包含在任何 Python 科学发行版中),但是目标位于文件 I/O 的接口中,该接口可以是研究和分析的第一阶段或最后阶段。
SciPy
SciPy 是一个着名的 Python 库,专注于科学计算(它包含用于优化,线性代数,积分,内插以及诸如 FFT,信号和图像处理等特殊功能的模块)。 它建立在 NumPy 数组对象的基础上,并且 NumPy 是整个 SciPy 栈的一部分(请记住,我们在第 1 章, “NumPy 简介”)。 但是,SciPy 模块包含各种主题,而我们不能仅在一个部分中进行介绍。 让我们看一个图像处理(降噪)示例,以帮助您了解 SciPy 可以做什么:
In [1]: from scipy.misc import imread, imsave, ascent
In [2]: import matplotlib.pyplot as plt
In [3]: image_data = ascent()
首先,我们从 SciPy 的其他例程中导入三个函数:imread,imsave和ascent。 在下面的示例中,我们使用内置图像ascent,它是512 x 512灰度图像。 当然,您可以使用自己的图像。 只需调用imread('your_image_name'),它将作为ndarray加载。
我们在此处导入的matplotlib模块的pyplot结果仅用于显示图像; 我们在第 6 章,“在 NumPy 中进行傅里叶分析”这样做了。 这是内置图像ascent:

现在,我们可以为图像添加一些噪点,并使用pyplot模块显示噪点图像:
In [4]: import numpy as np
In [5]:noise_img = image_data + image_data.std() * np.random.random(image_data.shape)
In [6]: imsave('noise_img.png', noise_img)
In [7]: plt.imshow(noise_img)
Out[7]: <matplotlib.image.AxesImage at 0x20066572898>
In [8]: plt.show()
在此代码段中,我们导入numpy以根据图像形状生成一些随机噪声。 然后,将噪点图像保存到noise_img.png。 噪点图像如下所示:

接下来,我们将使用 SciPy scipy.ndimage中的多维图像处理模块对噪波图像应用滤镜以使其平滑。 ndimage模块提供各种过滤器; 有关详细列表,请参考这里,但是在以下示例中,我们将仅使用高斯和均匀滤波器:
In [9]: from scipy import ndimage
In [10]: gaussian_denoised = ndimage.gaussian_filter(noise_img, 3)
In [11]: imsave('gaussian_denoised.png', gaussian_denoised )
In [12]: plt.imshow(gaussian_denoised)
Out[12]: <matplotlib.image.AxesImage at 0x2006ba54860>
In [13]: plt.show()
In [14]: uniform_denoised = ndimage.uniform_filter(noise_img)
In [15]: imsave('uniform_denoised.png', uniform_denoised)
In [16]: plt.imshow(gaussian_denoised)
Out[17]: <matplotlib.image.AxesImage at 0x2006ba80320>
In [18]: plt.show()

首先,我们从 SciPy 导入ndimage,在noise_image上应用高斯滤波器,将sigma(高斯内核的标准偏差)设置为3,然后将其保存到gaussian_denoised.png。 查看上一张图片的左侧。 通常,sigma越大,图像将越平滑,这意味着细节丢失。 我们应用的第二个过滤器是均匀过滤器,并采用了所有参数的默认值,这将导致上一张图像的右侧。 尽管统一滤波器保留了原始图像的更多细节,但图像仍包含噪点。
上一个示例是使用 SciPy 的简单图像处理示例。 但是,SciPy 不仅可以处理图像处理,还可以执行许多类型的分析/科学计算。 有关详细信息,请参阅《SciPy 数值和科学计算学习手册第二版》,Packt Publishing。
总结
NumPy 当然是使用 Python 进行科学计算的核心:许多模块都基于 NumPy。 尽管有时您可能会发现 NumPy 没有分析模块,但它无疑为您提供了一种接触广泛科学模块的方法。文章来源:https://www.toymoban.com/news/detail-413248.html
我们希望本书的最后一章为您提供了一个关于将这些模块与 NumPy 一起使用的好主意,并使您的脚本更加有效(本书中无法涵盖很多便捷的 NumPy 模块;仅在 GitHub 或 PyPI 上度过一个下午,您可能会发现其中的少数几个)。 最后但并非最不重要的一点,感谢您花时间与我们一起完成许多功能。 现在与 NumPy 一起玩吧!文章来源地址https://www.toymoban.com/news/detail-413248.html
到了这里,关于NumPy 基础知识 :6~10的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!





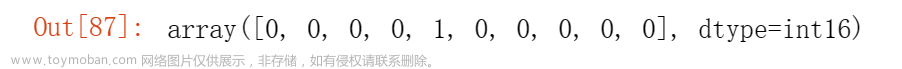
![系统学习Numpy(一)——numpy的安装与基础入门[向量、矩阵]](https://imgs.yssmx.com/Uploads/2024/02/594520-1.png)





