OpenAI API Documentation
https://platform.openai.com/docs/models/overview
GPT 迭代过程
| 版本 | 发布时间 | 训练方案 | 参数量 | 是否开放接口 |
|---|---|---|---|---|
| GPT(GPT-1) | 2018 年 6 月 | 无监督学习 | 1.17 亿 | 是 |
| GPT-2 | 2019 年 2 月 | 多任务学习 | 15 亿 | 是 |
| GPT-3 | 2020 年 5 月 | 海量参数 | 1,750 亿 | 是 |
| ChatGPT(GPT-3.5) | 2022 年 12 月 | 针对对话场景优化 | 1,750 亿 | 是 |
| GPT-4 | 2023 年 3 月 | 万亿参数 | 100万亿 | 否 |
模型
概述
OpenAI API 由具有不同功能和价位的多种模型提供支持。您还可以通过微调针对您的特定用例对我们的原始基础模型进行有限的定制。
| 楷模 | 描述 |
|---|---|
|
GPT-4
有限公测
|
一组在 GPT-3.5 上改进的模型,可以理解并生成自然语言或代码 |
| GPT-3.5 | 一组在 GPT-3 上改进的模型,可以理解并生成自然语言或代码 |
|
DALL·E<
测试版
|
可以在给定自然语言提示的情况下生成和编辑图像的模型 |
|
Whisper
测试版
|
一种可以将音频转换为文本的模型 |
| Embeddings | 一组可以将文本转换为数字形式的模型 |
| Moderation | 可以检测文本是否敏感或不安全的微调模型 |
| GPT-3 | 一组可以理解和生成自然语言的模型 |
|
Codex
弃用
|
一组可以理解和生成代码的模型,包括将自然语言翻译成代码 |
我们还发布了开源模型,包括Point-E、Whisper、Jukebox和CLIP。
访问我们的研究人员模型索引,详细了解我们的研究论文中介绍了哪些模型以及 InstructGPT 和 GPT-3.5 等模型系列之间的差异。
模型端点兼容性
| 端点 | 型号名称 | |
|---|---|---|
| /v1/chat/completions | gpt-4、gpt-4-0314、gpt-4-32k、gpt-4-32k-0314、gpt-3.5-turbo、gpt-3.5-turbo-0301 | |
| /v1/completions | text-davinci-003、text-davinci-002、text-curie-001、text-babbage-001、text-ada-001 | |
| /v1/edits | 文本-davinci-edit-001,code-davinci-edit-001 | |
| /v1/audio/transcriptions | whisper-1 | |
| /v1/audio/translations< | whisper-1 | |
| /v1/fine-tunes | davinci, curie, babbage, ada | |
| /v1/embeddings | text-embedding-ada-002, text-search-ada-doc-001 | |
| /v1/moderations | text-moderation-stable, text-moderation-latest |
此列表不包括我们的第一代嵌入模型和我们的DALL·E 模型。
持续的模型升级
随着 的发布gpt-3.5-turbo,我们的一些模型现在正在不断更新。为了减少模型更改以意外方式影响我们用户的可能性,我们还提供将在 3 个月内保持静态的模型版本。随着模型更新的新节奏,我们还让人们能够贡献评估,以帮助我们针对不同的用例改进模型。如果您有兴趣,请查看OpenAI Evals存储库。
以下模型是将在指定日期弃用的临时快照。如果您想使用最新的模型版本,请使用标准模型名称,例如gpt-4或gpt-3.5-turbo。
| 型号名称 | 弃用日期 | |
|---|---|---|
| gpt-3.5-turbo-0301 | 2023 年 6 月 1 日 | |
| gpt-4-0314 | 2023 年 6 月 14 日 | |
| gpt-4-32k-0314 | 2023 年 6 月 14 日 |
GPT-4
GPT-4 是一个大型多模态模型(今天接受文本输入并发出文本输出,将来会出现图像输入),由于其更广泛的常识和高级推理,它可以比我们以前的任何模型更准确地解决难题能力。与 GPT-4 一样gpt-3.5-turbo,GPT-4 针对聊天进行了优化,但也适用于使用聊天完成 API 的传统完成任务。在我们的聊天指南中了解如何使用 GPT-4 。
| 最新款 | 描述 | 最大tokens | 训练数据 |
|---|---|---|---|
| gpt-4 | 比任何 GPT-3.5 模型都更强大,能够执行更复杂的任务,并针对聊天进行了优化。将使用我们最新的模型迭代进行更新。 | 8,192 个tokens | 截至 2021 年 9 月 |
| gpt-4-0314 |
2023 年 3 月 14 日的快照gpt-4。与 不同的是gpt-4,此模型不会收到更新,并且只会在 2023 年 6 月 14 日结束的三个月内提供支持。
|
8,192 个tokens | 截至 2021 年 9 月 |
| gpt-4-32k |
与基本gpt-4模式相同的功能,但上下文长度是其 4 倍。将使用我们最新的模型迭代进行更新。
|
32,768 个tokens | 截至 2021 年 9 月 |
| gpt-4-32k-0314 |
2023 年 3 月 14 日的快照gpt-4-32。与 不同的是gpt-4-32k,此模型不会收到更新,并且只会在 2023 年 6 月 14 日结束的三个月内提供支持。
|
32,768 个tokens | 截至 2021 年 9 月 |
对于许多基本任务,GPT-4 和 GPT-3.5 模型之间的差异并不显着。然而,在更复杂的推理情况下,GPT-4 比我们之前的任何模型都更有能力。
GPT-3.5
GPT-3.5 模型可以理解并生成自然语言或代码。我们在 GPT-3.5 系列中功能最强大且最具成本效益的模型gpt-3.5-turbo已针对聊天进行了优化,但也适用于传统的完成任务。
| 最新款 | 描述 | 最大tokens | 训练数据 |
|---|---|---|---|
| gpt-3.5-turbo |
功能最强大的 GPT-3.5 模型,并针对聊天进行了优化,成本仅为text-davinci-003. 将使用我们最新的模型迭代进行更新。
|
4,096 个tokens | 截至 2021 年 9 月 |
| gpt-3.5-turbo-0301 |
2023 年 3 月 1 日的快照gpt-3.5-turbo。与 不同的是gpt-3.5-turbo,此模型不会收到更新,并且只会在 2023 年 6 月 1 日结束的三个月内提供支持。
|
4,096 个tokens | 截至 2021 年 9 月 |
| text-davinci-003 | 可以比curie, babbage, 或 ada 模型更好的质量、更长的输出和一致的指令遵循来完成任何语言任务。还支持在文本中插入补全。 | 4,097 个tokens | 截至 2021 年 6 月 |
| text-davinci-002 |
类似的能力,text-davinci-003但训练有监督的微调而不是强化学习
|
4,097 个tokens | 截至 2021 年 6 月 |
| code-davinci-002 | 针对代码完成任务进行了优化 | 8,001 个tokens | 截至 2021 年 6 月 |
我们建议使用gpt-3.5-turbo其他 GPT-3.5 模型,因为它的成本较低。
特定功能模型
虽然新gpt-3.5-turbo模型针对聊天进行了优化,但它非常适合传统的完成任务。原始的 GPT-3.5 模型针对文本补全进行了优化。
我们用于创建嵌入和编辑文本的端点使用它们自己的一组专用模型。
找到合适的模型
进行试验gpt-3.5-turbo是了解 API 功能的好方法。在您了解要实现的目标之后,您可以继续使用gpt-3.5-turbo或使用其他模型并尝试围绕其功能进行优化。
您可以使用GPT 比较工具,让您并排运行不同的模型来比较输出、设置和响应时间,然后将数据下载到 Excel 电子表格中。
DALL·E
DALL·E 是一个人工智能系统,可以根据自然语言的描述创建逼真的图像和艺术作品。我们目前支持在提示的情况下创建具有特定大小的新图像、编辑现有图像或创建用户提供的图像的变体的能力。
通过我们的 API 提供的当前 DALL·E 模型是 DALL·E 的第 2 次迭代,具有比原始模型更逼真、更准确且分辨率高 4 倍的图像。您可以通过我们的实验室界面或API进行试用。
Whisper
Whisper 是一种通用的语音识别模型。它在不同音频的大型数据集上进行训练,也是一个多任务模型,可以执行多语言语音识别以及语音翻译和语言识别。Whisper v2-large 模型目前可通过我们的 API 使用whisper-1模型名称获得。
目前, Whisper 的开源版本与通过我们的 API 提供的版本之间没有区别。然而,通过我们的 API,我们提供了一个优化的推理过程,这使得通过我们的 API 运行 Whisper 比通过其他方式运行要快得多。有关 Whisper 的更多技术细节,您可以阅读论文。
embedding
嵌入是文本的数字表示,可用于衡量两段文本之间的相关性。我们的第二代嵌入模型text-embedding-ada-002旨在以一小部分成本取代之前的 16 种第一代嵌入模型。嵌入可用于搜索、聚类、推荐、异常检测和分类任务。您可以在公告博客文章中阅读有关我们最新嵌入模型的更多信息。
moderation
审核模型旨在检查内容是否符合 OpenAI 的使用政策。这些模型提供了查找以下类别内容的分类功能:仇恨、仇恨/威胁、自残、性、性/未成年人、暴力和暴力/图片。您可以在我们的审核指南中找到更多信息。
审核模型接受任意大小的输入,该输入会自动分解以修复模型特定的上下文窗口。
| 模型 | 描述 |
|---|---|
| text-moderation-latest | 最有能力的审核模型。精度会比稳定模型略高 |
| text-moderation-stable | 几乎与最新型号一样强大,但稍旧一些。 |
GPT-3
GPT-3 模型可以理解和生成自然语言。这些模型被更强大的 GPT-3.5 代模型所取代。但是,原始 GPT-3 基本模型(davinci、curie、ada和babbage)是当前唯一可用于微调的模型。
| 最新款 | 描述 | 最大tokens | 训练数据 |
|---|---|---|---|
| text-curie-001 | 非常有能力,比达芬奇更快,成本更低。 | 2,049 个tokens | 截至 2019 年 10 月 |
| text-babbage-001 | 能够执行简单的任务,速度非常快,成本更低。 | 2,049 个tokens | 截至 2019 年 10 月 |
| text-ada-001 | 能够执行非常简单的任务,通常是 GPT-3 系列中最快的型号,而且成本最低。 | 2,049 个tokens | 截至 2019 年 10 月 |
| davinci | 功能最强大的 GPT-3 模型。可以完成其他模型可以完成的任何任务,而且通常质量更高。 | 2,049 个tokens | 截至 2019 年 10 月 |
| curie | 非常有能力,但比达芬奇更快,成本更低。 | 2,049 个tokens | 截至 2019 年 10 月 |
| babbage | 能够执行简单的任务,速度非常快,成本更低。 | 2,049 个tokens | 截至 2019 年 10 月 |
| ada | 能够执行非常简单的任务,通常是 GPT-3 系列中最快的型号,而且成本最低。 | 2,049 个tokens | 截至 2019 年 10 月 |
Codex
Codex 模型现已弃用。他们是我们 GPT-3 模型的后代,可以理解和生成代码。他们的训练数据包含自然语言和来自 GitHub 的数十亿行公共代码。了解更多。
他们最擅长 Python,精通 JavaScript、Go、Perl、PHP、Ruby、Swift、TypeScript、SQL 甚至 Shell 等十几种语言。
以下 Codex 模型现已弃用:
| 最新款 | 描述 | 最大tokens | 训练数据 |
|---|---|---|---|
| code-davinci-002 | 功能最强大的 Codex 型号。特别擅长将自然语言翻译成代码。除了补全代码,还支持在代码中插入补全。 | 8,001 个tokens | 截至 2021 年 6 月 |
| code-davinci-001 |
早期版本code-davinci-002
|
8,001 个tokens | 截至 2021 年 6 月 |
| code-cushman-002 | 几乎与 Davinci Codex 一样强大,但速度稍快。这种速度优势可能使其成为实时应用程序的首选。 | 最多 2,048 个tokens | |
| code-cushman-001 |
早期版本code-cushman-002
|
最多 2,048 个tokens |
有关更多信息,请访问我们的Codex 工作指南。
API
介绍下openai api的接口入参,并说明每个参数的用法
OpenAI API的接口入参因不同的任务类型而异,但是大多数任务都需要以下几个通用参数:
model: 模型名称,表示要使用的模型。例如:davinci, curie, ada等。每个模型的能力和用途不同,可以在OpenAI API的官方文档中查看各个模型的介绍和用途。
prompt: 输入文本,即需要进行自然语言处理的文本。不同任务可能对输入文本的格式有要求,例如:文本长度、标点符号等。
temperature: 生成文本的随机性程度。值越大,生成的文本就越随机,但同时也越不可控。通常情况下,这个参数的取值范围为0-1之间的浮点数,建议取值在0.5左右。
max_tokens: 生成文本的长度,即最大的生成文本的长度。这个参数通常用来控制生成的文本的长度,避免生成过于冗长的文本。
stop: 停止词,用来控制生成的文本是否停止在某个指定的词或短语处。当生成的文本中包含了指定的停止词或短语时,生成文本的过程就会停止。这个参数通常用来控制生成的文本的内容和方向。
n: 生成文本的数量,即需要生成的文本的数量。这个参数通常用来控制生成的文本的多样性和数量。
best_of: 最佳生成文本数量,即从多次生成文本中选取最佳的文本数量。这个参数通常用来控制生成文本的质量和可读性。
frequency_penalty: 频率惩罚,用来控制重复的单词和短语在生成文本中的出现频率。值越大,生成文本中出现重复单词和短语的概率越小。
presence_penalty: 存在惩罚,用来控制生成文本中出现新单词和短语的概率。值越大,生成文本中出现新单词和短语的概率越大。
best_of: 最佳文本数量,即从多次生成的文本中选取最佳的文本数量。这个参数通常用来控制生成文本的质量和可读性。
logprobs: 是否返回每个单词或短语的概率值。当这个参数设置为true时,生成文本中每个单词或短语的概率值会被返回。
echo: 是否返回输入文本。当这个参数设置为true时,输入文本也会被返回。
介绍下openai api的接口返回值,并说明用法
OpenAI API的接口返回值因不同的任务和模型而异。一般而言,返回值包括以下几个字段:
- id: 该请求的唯一标识符。
- object: 返回值的类型,通常为 “text_completion”,表示文本生成任务。
- created: 请求的创建时间。
- model: 使用的模型的标识符。
- choices: 一个包含所有可能输出结果的列表,每个结果包括以下字段:
- text: 模型生成的文本。
- index: 输出结果的排序位置。
- logprobs: 对于每个token,给出其概率分布及其对数概率。
- finish_reason: 完成原因。可能的值包括 “stop”,表示生成的文本达到了指定的长度或终止标记,或者 “max_turns”,表示已达到最大的文本生成轮数。
- prompt: 模型使用的输入提示。
- created: 输出结果的创建时间。 开发者可以根据自己的需求,使用返回值中的 text 字段获取模型生成的文本。同时,还可以使用 logprobs 字段获取模型对每个token的概率分布,这对于某些应用场景非常有用。
基本参数
- model: 要使用的模型的 ID,访问 OpenAI Docs Models 页面可以查看全部可用的模型
- prompt: 生成结果的提示文本,即你想要得到的内容描述
- max_tokens: 生成结果时的最大 tokens 数,不能超过模型的上下文长度,可以把结果内容复制到 OpenAI Tokenizer 来了解 tokens 的计数方式
- temperature: 控制结果的随机性,如果希望结果更有创意可以尝试 0.9,或者希望有固定结果可以尝试 0.0
- top_p: 一个可用于代替 temperature 的参数,对应机器学习中 nucleus sampling,如果设置 0.1 意味着只考虑构成前 10% 概率质量的 tokens
temperature可以简单得将其理解为“熵”,控制输出的混乱程度(随机性),而top-p可以简单将其理解为候选词列表大小,控制模型所能看到的候选词的多少。实际使用中大家要多尝试不同的值,从而获得最佳输出效果。
- frequency_penalty: [控制字符的重复度] -2.0 ~ 2.0 之间的数字,正值会根据新 tokens 在文本中的现有频率对其进行惩罚,从而降低模型逐字重复同一行的可能性(以恐怖故事为例)
- = -2.0:当早上黎明时,我发现我家现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在(频率最高字符是 “现”,占比 44.79%)
- = -1.0:他总是在清晨漫步在一片森林里,每次漫游每次每次游游游游游游游游游游游游游游游游游游游游游游游游游游游游游(频率最高字符是 “游”,占比 57.69%)
- = 0.0:当一道阴森的风吹过早晨的小餐馆时,一个被吓得发抖的人突然出现在门口,他的嘴唇上挂满血迹,害怕的店主决定给他一份早餐,却发现他的早餐里满是血渍。(频率最高字符是 “的”,占比 8.45%)
- = 1.0:一个熟睡的女孩被一阵清冷的风吹得不由自主地醒了,她看到了早上还未到来的黑暗,周围只有像诉说厄运般狂风呼啸而过。(频率最高字符是 “的”,占比 5.45%)
- = 2.0:每天早上,他都会在露台上坐着吃早餐。柔和的夕阳照耀下,一切看起来安详寂静。但是有一天,当他准备端起早食的时候发现胡同里清冷的风扑进了他的意识中并带来了不安全感…… (频率最高字符是 “的”,占比 4.94%)
- presence_penalty: [控制主题的重复度] -2.0 ~ 2.0 之间的数字,正值会根据到目前为止是否出现在文本中来惩罚新 tokens,从而增加模型谈论新主题的可能性(以云课堂的广告文案为例)
- -2.0:家长们,你们是否为家里的孩子学业的发展而发愁?担心他们的学习没有取得有效的提高?那么,你们可以放心,可以尝试云课堂!它是一个为从幼儿园到高中的学生提供的一个网络平台,可以有效的帮助孩子们提高学习效率,提升学习成绩,帮助他们在学校表现出色!让孩子们的学业发展更加顺利,家长们赶紧加入吧!(抓住一个主题使劲谈论)
- -1.0:家长们,你们是否还在为孩子的学习成绩担忧?云课堂给你们带来了一个绝佳的解决方案!我们为孩子提供了专业的学习指导,从幼儿园到高中,我们都能帮助孩子们在学校取得更好的成绩!让孩子们在学习中更轻松,更有成就感!加入我们,让孩子们拥有更好的学习体验!(紧密围绕一个主题谈论)
- 0.0:家长们,你们是否担心孩子在学校表现不佳?云课堂将帮助您的孩子更好地学习!云课堂是一个网络平台,为从幼儿园到高中的学生提供了全面的学习资源,让他们可以在学校表现出色!让您的孩子更加聪明,让他们在学校取得更好的成绩,快来云课堂吧!(相对围绕一个主题谈论)
- 1.0:家长们,你们的孩子梦想成为最优秀的学生吗?云课堂就是你们的答案!它不仅可以帮助孩子在学校表现出色,还能够提供专业教育资源,助力孩子取得更好的成绩!让你们的孩子一路走向成功,就用云课堂!(避免一个主题谈论的太多)
- 2.0:家长们,您有没有想过,让孩子在学校表现出色可不是一件容易的事?没关系!我们为您提供了一个优质的网络平台——云课堂!无论您的孩子是小学生、初中生还是高中生,都能够通过云课堂找到最合适的学习方法,帮助他们在学校取得优异成绩。快来体验吧!(最大程度避免谈论重复的主题)
- stop: 最大长度为 4 的字符串列表,一旦生成的 tokens 包含其中的内容,将停止生成并返回结果
//private final String path_base="https://api.openai.com/v1";
/**
* https://platform.openai.com/docs/api-reference/
* <p>
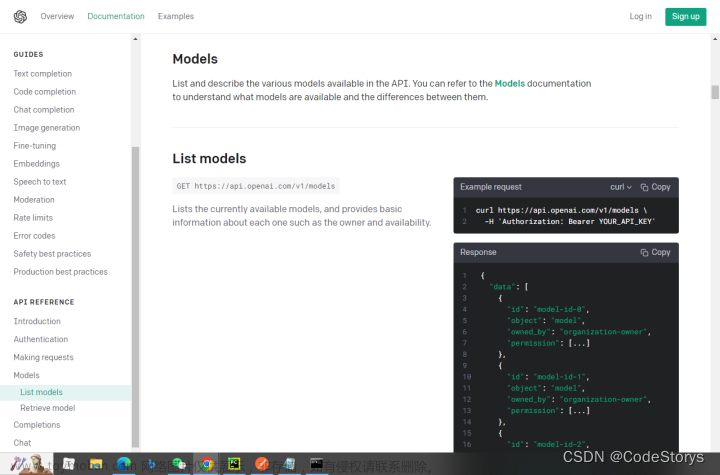
* models 列出 API 中可用的各种模型,并提供有关每个模型的基本信息,例如所有者和可用性。 * https://api.openai.com/v1/models
* completions 给定提示,模型将返回一个或多个预测完成,还可以返回每个位置的替代令牌的概率。 * https://api.openai.com/v1/completions
* edits 给定提示和指令,模型将返回提示的编辑版本。 * https://api.openai.com/v1/edits
* images/generations 创建映像,创建给定提示的图像。给定提示和/或输入图像,模型将生成一个新图像。* https://api.openai.com/v1/images/generations
* images/edits 创建图像编辑,在给定原始图像和提示的情况下创建编辑或扩展的图像。 * https://api.openai.com/v1/images/edits
* images/variations 创建图像变体,创建给定图像的变体。 * https://api.openai.com/v1/images/variations
* Embeddings 获取给定输入的向量表示形式,机器学习模型和算法可以轻松使用该表示形式。 * https://api.openai.com/v1/embeddings
* files 返回属于用户组织的文件列表。文件用于上传可与微调等功能一起使用的文档。 * https://api.openai.com/v1/files
* fine-tunes 管理微调作业,以根据特定训练数据定制模型。 * https://api.openai.com/v1/fine-tunes
* moderations 给定输入文本,如果模型将其归类为违反 OpenAI 的内容策略,则输出。 * https://api.openai.com/v1/moderations
* engines 提供对 API 中可用的各种引擎的访问。 * https://api.openai.com/v1/enginesCreate completion
(/docs/api-reference/completions/create) post https://api.openai.com/v1/completions Creates a completion for the provided prompt and parameters
Request body
| 参数名 | 类型 | 必填 | 默认值 | 说明 |
|---|---|---|---|---|
| model | string | Required | ||
| prompt | string or array | Optional | Defaults to </endoftext/> | |
| suffix | string | Optional | Defaults to null | |
| max_tokens | integer | Optional | Defaults to 16 | |
| temperature | number | Optional | Defaults to 1 | |
| top_p | number | Optional | Defaults to 1 | |
| n | integer | Optional | Defaults to 1 | |
| stream | boolean | Optional | Defaults to false | |
| logprobs | integer | Optional | Defaults to null | |
| echo | boolean | Optional | Defaults to false | |
| stop | string or array | Optional | Defaults to null | |
| presence_penalty | number | Optional | Defaults to 0 | |
| frequency_penalty | number | Optional | Defaults to 0 | |
| best_of | integer | Optional | Defaults to 1 | |
| logit_bias | map | Optional | Defaults to null | |
| user | string | Optional |
https://platform.openai.com/docs/api-reference/completions/文章来源:https://www.toymoban.com/news/detail-413327.html
model
- ID of the model to use. You can use the List models API to see all of your available models, or see our Model overview for descriptions of them.
prompt
- The prompt(s) to generate completions for, encoded as a string, array of strings, array of tokens, or array of token arrays.
- Note that <|endoftext|> is the document separator that the model sees during training, so if a prompt is not specified the model will generate as if from the beginning of a new document.
suffix
- The suffix that comes after a completion of inserted text.
max_tokens
- The maximum number of tokens to generate in the completion.
- The token count of your prompt plus
max_tokenscannot exceed the model’s context length. Most models have a context length of 2048 tokens (except for the newest models, which support 4096).
temperature
- What sampling temperature to use, between 0 and 2. Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic.
- We generally recommend altering this or
top_pbut not both.
top_p
- An alternative to sampling with temperature, called nucleus sampling, where the model considers the results of the tokens with top_p probability mass. So 0.1 means only the tokens comprising the top 10% probability mass are considered.
- We generally recommend altering this or
temperaturebut not both.
n
- How many completions to generate for each prompt.
- Note: Because this parameter generates many completions, it can quickly consume your token quota. Use carefully and ensure that you have reasonable settings for
max_tokensandstop.
stream
- Whether to stream back partial progress. If set, tokens will be sent as data-only server-sent events as they become available, with the stream terminated by a
data: [DONE]message.
logprobs文章来源地址https://www.toymoban.com/news/detail-413327.html
- Include the log probabilities on the
logprobsmost likely tokens, as well the chosen tokens. For example, iflogprobsis 5, the API will return a list of the 5 most likely tokens. The API will always return thelogprobof the sampled token, so there may be up tologprobs+1elements in the response.- The maximum value for
logprobsis 5. If you need more than this, please contact us through our Help center and describe your use case.
echo
- Echo back the prompt in addition to the completion
stop
- Up to 4 sequences where the API will stop generating further tokens. The returned text will not contain the stop sequence.
presence_penalty
- Number between -2.0 and 2.0. Positive values penalize new tokens based on whether they appear in the text so far, increasing the model’s likelihood to talk about new topics.
- See more information about frequency and presence penalties.
frequency_penalty
- Number between -2.0 and 2.0. Positive values penalize new tokens based on their existing frequency in the text so far, decreasing the model’s likelihood to repeat the same line verbatim.
- See more information about frequency and presence penalties.
best_of
- Generates
best_ofcompletions server-side and returns the “best” (the one with the highest log probability per token). Results cannot be streamed.- When used with
n,best_ofcontrols the number of candidate completions andnspecifies how many to return –best_ofmust be greater thann.- Note: Because this parameter generates many completions, it can quickly consume your token quota. Use carefully and ensure that you have reasonable settings for
max_tokensandstop.
logit_bias
- Modify the likelihood of specified tokens appearing in the completion.
- Accepts a json object that maps tokens (specified by their token ID in the GPT tokenizer) to an associated bias value from -100 to 100. You can use this tokenizer tool (which works for both GPT-2 and GPT-3) to convert text to token IDs. Mathematically, the bias is added to the logits generated by the model prior to sampling. The exact effect will vary per model, but values between -1 and 1 should decrease or increase likelihood of selection; values like -100 or 100 should result in a ban or exclusive selection of the relevant token.
- As an example, you can pass
{"50256": -100}to prevent the <|endoftext|> token from being generated.
user
- A unique identifier representing your end-user, which can help OpenAI to monitor and detect abuse. Learn more.
到了这里,关于OpenAI API的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!