Hive是一个构建在Hadoop上的数据仓库框架,最初,Hive是由Facebook开发,后台移交由Apache软件基金会开发,并做为一个Apache开源项目。
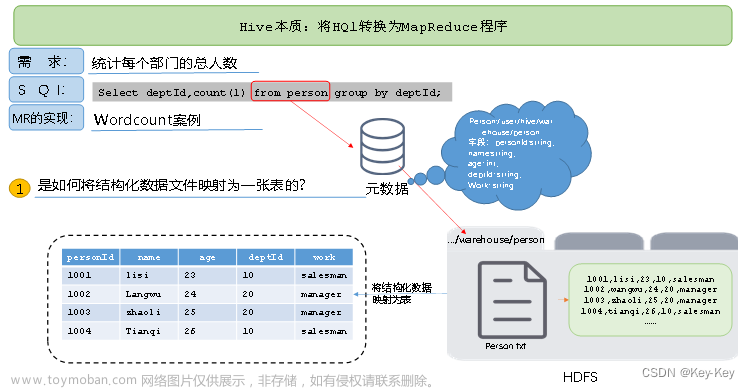
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。
Hive它能够存储很大的数据集,可以直接访问存储在Apache HDFS或其他数据存储系统(如Apache HBase)中的文件。
Hive支持MapReduce、Spark、Tez这三种分布式计算引擎。
Hive架构
Hive是建立在Hadoop上的数据仓库基础架构,它提供了一系列的工具,可以存储、查询、分析存储在分布式存储系统中的大规模数据集。Hive定义了简单的类SQL查询语言,通过底层的计算引擎,将SQL转为具体的计算任务进行执行。

客户端:写类SQL语句
Hive驱动器:解析、优化SQL
计算引擎:通过计算引擎来执行SQL
数据存储:存储源数据和结果数据
MapReduce
它将计算分为两个阶段,分别为Map和Reduce。对于应用来说,需要想办法将应用拆分为多个map、reduce,以完成一个完整的算法。
MapReduce整个计算过程会不断重复的往磁盘里读写中间结果。导致计算速度比较慢,效率比较低。

Tez
把Map/Reduce过程拆分成若干个子过程,同时可以把多个Map/Reduce任务组合成一个较大DAG任务,减少了Map/Reduce之间的文件存储。

Spark
Apache Spark是一个快速的,多用途的集群计算系统,相对于Hadoop MapReduce将中间结果保存在磁盘中,Spark使用了内存保存中间结果,能在数据尚未写入硬盘时在内存中进行计算,同时Spark提供SQL支持。 Spark 实现了一种叫RDDs的DAG执行引擎,其数据缓存在内存中可以进行迭代处理。
使用的是Hive+Spark计算引擎

Hive安全和启动
1、启动集群中所有的组件
cd /export/onekey
./start-all.sh
2、使用终端链接Hive
1)、进入到/export/server/spark-2.3.0-bin-hadoop2.7/bin目录中
2)、执行以下命令:./beeline
3)、输入:!connect jdbc:hive2://node1:10000,回车
4)、输入用户名:root
5)、直接回车,即可使用命令行连接到Hive,然后就可以执行HQL了。
[root@node1 onekey]# cd /export/server/spark-2.3.0-bin-hadoop2.7/bin
[root@node1 bin]# ./beeline
Beeline version 1.2.1.spark2 by Apache Hive
beeline> !connect jdbc:hive2://node1:10000
Connecting to jdbc:hive2://node1.itcast.cn:10000
Enter username for jdbc:hive2://node1.itcast.cn:10000: root
Enter password for jdbc:hive2://node1.itcast.cn:10000: 直接回车
2021-01-08 14:34:24 INFO Utils:310 - Supplied authorities: node1.itcast.cn:10000
2021-01-08 14:34:24 INFO Utils:397 - Resolved authority: node1.itcast.cn:10000
2021-01-08 14:34:24 INFO HiveConnection:203 - Will try to open client transport with JDBC Uri: jdbc:hive2://node1.itcast.cn:10000
Connected to: Spark SQL (version 2.3.0)
Driver: Hive JDBC (version 1.2.1.spark2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://node1.itcast.cn:10000> 。
连接成功的标志。
Hive的数据库和表
Hive数仓和传统关系型数据库类似,管理数仓数据也有数据库和表

Hive数据库操作
1)、创建数据库-默认方式
create database if not exists myhive;
show databases; #查看所有数据库
说明:
1、if not exists:该参数可选,表示如果数据存在则不创建(不加该参数则报错),不存在则创建
2、hive的数据库默认存放在/user/hive/warehouse目录
2)、创建数据库-指定存储路径
create database myhive2 location '/myhive2';
show databases; #查看所有数据库
说明:
1、location:用来指定数据库的存放路径。
3)、查看数据库详情信息
desc database myhive;
4)、删除数据库
删除一个空数据库,如果数据库下面有数据表,就会报错
drop database myhive;
强制删除数据库,包含数据库下面的表一起删除
drop database myhive2 cascade;
5)、创建数据库表语法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[LOCATION hdfs_path]6)、表字段数据类型

7)、表字段数据类型-复杂类型

8)、 内部表操作-创建表
未被external修饰的内部表(managed table),内部表又称管理表,内部表不适合用于共享数据。
create database mytest; #创建数据库
user mytest; #选择数据库
create table stu(id int, name string);
show tables; #查询数据
创建表之后,Hive会在对应的数据库文件夹下创建对应的表目录。
9)、内部表操作-查看表结构/删除表
查看表结构
desc stu;#查看表结构基本信息
desc formatted stu;查看表结构详细信息
删除表
drop table stu;
Hive内部表操作-数据添加
1)、方式1-直接插入数据
对于Hive中的表,可以通过insert into 指令向表中插入数据
user mytest; #选择数据库
create table stu(id int, name string); # 创建表
# 向表中插入数据
insert into stu values(1, 'test1');
insert into stu values(2, 'test2');
select * from stu; #查询数据
2)、方式2-load数据加载
Load 命令用于将外部数据加载到Hive表中
语法:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1,partcol2=val2 ...)]
说明:
LOCAL 表示从本地文件系统加载,否则是从HDFS加载
应用1-本地加载
#创建表,同时指定文件的分隔符
create table if not exists stu2(id int ,name string)
row format delimited fields terminated by '\t’ ;
#向表加载数据
load data local inpath '/export/data/hivedatas/stu.txt' into table stu2;
应用2-HDFS加载
#创建表,同时指定文件的分隔符
create table if not exists stu3(id int ,name string)
row format delimited fields terminated by '\t’ ;
#向表加载数据
hadoop fs -mkdir -p /hivedatas
cd /export/data/hivedatas
hadoop fs –put stu.txt /hivedatas/
load data inpath '/hivedatas/stu.txt' into table stu3;
Hive内部表特点
1)、元数据
Hive是建立在Hadoop之上的数据仓库,存在hive里的数据实际上就是存在HDFS上,都是以文件的形式存在
Hive元数据用来记录数据库和表的特征信息,比如数据库的名字、存储路径、表的名字、字段信息、表文件存储路径等等
Hive的元数据保存在Mysql数据库中
2)、内部表特点
hive内部表信息存储默认的文件路径是在/user/hive/warehouse/databasename.db/tablename目录
hive 内部表在进行drop操作时,其表中的数据以及表的元数据信息均会被删除
内部表一般可以用来做中间表或者临时表
Hive外部表操作
1)、创建表
创建表时,使用external关键字修饰则为外部表,外部表数据可用于共享
#创建学生表
create external table student (sid string,sname string,sbirth string , ss ex string) row format delimited fields terminated by ‘\t’ location ‘/hive_table/student‘;
#创建老师表
create external table teacher (tid string,tname string) row format delimited fields terminated by '\t’ location ‘/hive_table/teacher‘;
创建表之后,Hive会在Location指定目录下创建对应的表目录。
2)、加载数据
外部表加载数据也是通过load命令来完成
#给学生表添加数据
load data local inpath '/export/data/hivedatas/student.txt' into table student;
#给老师表添加数据,并覆盖已有数据
load data local inpath '/export/data/hivedatas/teacher.txt' overwrite into table teacher;
#查询数据
select * from student;
select * from teacher;3)、外部表特点
外部表在进行drop操作的时候,仅会删除元数据,而不删除HDFS上的文件
外部表一般用于数据共享表,比较安全
4)、安装Visual Studio Code
开发Hive的时候,经常要编写类SQL,
Hive表操作-分区表
1)、介绍
在大数据中,最常用的一种思想是分治,分区表实际就是对应hdfs文件系统上的独立的文件的文件夹,该文件夹下是该分区所有数据文件。
分区可以理解为分类,通过分类把不同类型的数据放到不同的目录下。
Hive中可以创建一级分区表,也可以创建多级分区表
2)、创建一级分区表
create table score(sid string,cid string, sscore int) partitioned by (month string) row format delimited fields terminated by '\t';
3)、数据加载
load data local inpath '/export/data/hivedatas/score.txt' into table score partition (month='202006');4)、创建多级分区表
create table score2(sid string,cid string, sscore int) partitioned by (year string,month string, day string)
row format delimited fields terminated by '\t';
5)、数据加载
load data local inpath '/export/data/hivedatas/score.txt' into table score2 partition(year='2020',month='06',day='01');
加载数据之后,多级分区表会创建多级分区目录。
6)、查看分区
show partitions score;7)、添加分区
alter table score add partition(month='202008’);
alter table score add partition(month='202009') partition(month = '202010');8)、删除分区
alter table score drop partition(month = '202010');
9)、Array类型
Array是数组类型,Aarray中存放相同类型的数据
源数据:
zhangsan beijing,shanghai,tianjin,hangzhou
wangwu changchun,chengdu,wuhan,beijin建表数据:
create external table hive_array(name string, work_locations array<string>) row format delimited fields terminated by '\t’
collection items terminated by ','; 建表语句:文章来源:https://www.toymoban.com/news/detail-413433.html
load data local inpath '/export/data/hivedatas/array_data.txt' overwrite into table hive_array;查询语句:文章来源地址https://www.toymoban.com/news/detail-413433.html
-- 查询所有数据
select * from hive_array;
-- 查询loction数组中第一个元素
select name, work_locations[0] location from hive_array;
-- 查询location数组中元素的个数
select name, size(work_locations) location from hive_array;
-- 查询location数组中包含tianjin的信息
select * from hive_array where array_contains(work_locations,'tianjin');
到了这里,关于Hive概论、架构和基本操作的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!