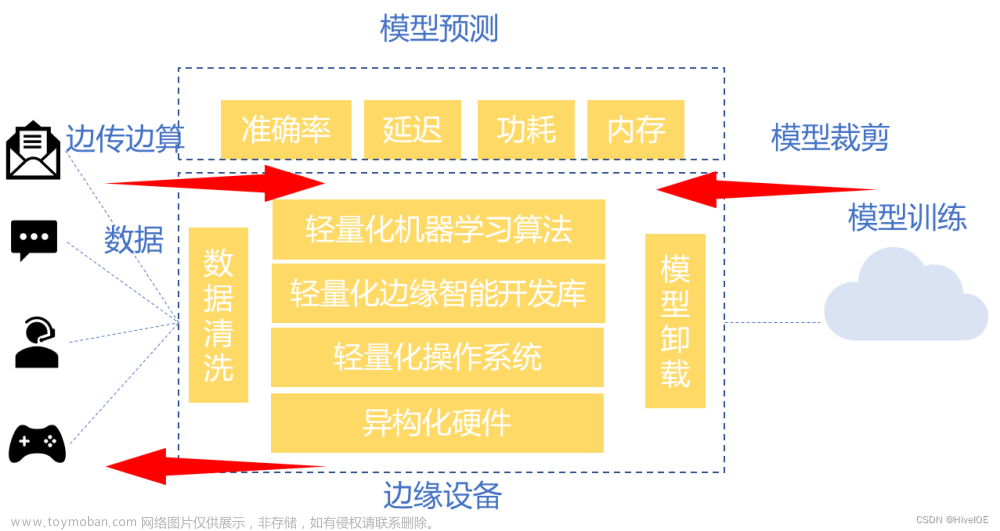
一、C++11简介
在2003年C++标准委员会曾经提交了一份技术勘误表(简称TC1),使得C++03这个名字已经取代了C++98称为C++11之前的最新C++标准名称。不过由于TC1主要是对C++98标准中的漏洞进行修复,语言的核心部分则没有改动,因此人们习惯性的把两个标准合并称为C++98/03标准。从C++0x到C++11,C++标准10年磨一剑,第二个真正意义上的标准珊珊来迟。相比于C++98/03,C++11则带来了数量可观的变化,其中包含了约140个新特性,以及对C++03标准中约600个缺陷的修正,这使得C++11更像是从C++98/03中孕育出的一种新语言。相比较而言,C++11能更好地用于系统开发和库开发、语法更加泛华和简单化、更加稳定和安全,不仅功能更强大,而且能提升程序员的开发效率,公司实际项目开发中也用得比较多,所以很值得我们作为一个重点学习。C++11增加的语法特性篇幅非常多,没办法一一讲解,所以在我的文章中只讲比较实用的语法。
大家可以看一下C++11的官方网站,在读这篇文章之前了解一下
C++11官方网站
其实,关于C++11还有一个小故事。1998年是C++标准委员会成立的第一年,本来计划以后每五年视实际需要更新一次标准,C++国际标准委员会在研究C++03的下一个版本的时候,一开始计划是2007年发布,所以最初这个版本标准较C++07.但是到06年的时候,官方觉得2007年肯定完不成C++07,而且官方觉得2008年可能也完不成。最后干脆叫C++0x了。x的意思是不知道到底能在07还是08还是09年完成。结果2010年的时候也没完成,最后再2011年终于万和城呢个了C++标准,所以最终定名为C++11。
二、列表初始化
2.1 C++98中{}的初始化问题
在C++98中,标准允许使用花括号{}对数组元素进行统一的列表初始值设定。比如:
int array1[] = {1,2,3,4,5};
int array2[5] = {0};
对于一些自定义的类型,却无法使用这样的初始化。比如:
vector<int> v{1,2,3,4,5};
就无法通过编译,导致每次定义vector时,都需要先把vector定义出来,然后使用循环对其赋初始值,非常不方便。C++11扩大了用大括号括起的列表(初始化列表)的使用范围,使其可用于所有的内置类型和用户自定义的类型,使用初始化列表时,可添加等号(=),也可不添加。
2.2 C++11中的列表初始化
C++11不同于C++98的变量初始化方法就体现在列表初始化上面,也就是说在C++11中,任何变量都可以直接用列表,在其创建是直接初始化,如下:
对于内置类型:
这么看来,好像也没厉害到那儿去,有一种脱了裤子放屁的感觉。
其实,C++11设着这个东西主要是为了在自定义类型的初始化中起作用。如下:
在C++98的标准中,对于自定义类型的变量,用动态管理的方式为它申请空间之后才能赋值。但在C++11标准中,可以直接用列表初始化。
注意,Point* p2 = new Point[2]{ {1,1},{2,2} };这种方式在VS2013中行不通,最后创建出来的变量还是没有初始化,可能是编译器的一个bug。要使用更高版本的编译器。
另外,C++11还可支持多个对象的列表初始化。
多个对象想要支持列表初始化,需给该类(模板类)添加一个带有initializer_list类型参数的构造函数即可。注意:initializer_list是系统自定义的类模板,该类模板中主要有三个方法:begin()、end()迭代器以及获取区间中元素个数的方法size()。如下:
举个例子:
int main()
{
auto li = { 1,2,3,4,5 };
cout << typeid(li).name() << endl;
return 0;
}

其实,可以理解为,花括号中的东西是一个常量数组,是存在于常量区的。然后编译器会将其中的值一一赋值给li。赋值的方式也是调用迭代器。

于是乎,就可以定义以下变量:
三、各种小语法
3.1 auto
在C++98中auto是一个存储类型的说明符,表明变量是局部自动存储类型,但是局部域中定义局部的变量默认就是自动存储类型,所以auto就没什么价值了。C++11中废弃auto原来的用法,将其用于实现自动类型腿断。这样要求必须进行显示初始化,让编译器将定义对象的类型设置为初始化值的类型。
如下:
int main()
{
int i = 10;
auto p = &i;
auto pf = strcpy;
cout << typeid(p).name() << endl;
cout << typeid(pf).name() << endl;
map<string, string> dict = { {"sort", "排序"}, {"insert", "插入"} };
//map<string, string>::iterator it = dict.begin();
auto it = dict.begin();
return 0;
}

3.2 decltype
上文中出现的typeid只能输出变量的类型,却不能用它再定义一个变量,而decltype却可以。如下:
template<class T1, class T2>
void F(T1 t1, T2 t2)
{
decltype(t1 * t2) ret;
cout << typeid(ret).name() << endl;
}
int main()
{
const int x = 1;
double y = 2.2;
decltype(x * y) ret; // ret的类型是double
decltype(&x) p;// p的类型是int*
cout << typeid(ret).name() << endl;
cout << typeid(p).name() << endl;
F(1, 'a');
return 0;
}

但是这个东西真的不太常用(至少我还没用过)
3.3 nullptr
由于C++中NULL被定义成字面量0,这样就可能回带来一些问题,因为0既能指针常量,又能表示整形常量。所以出于清晰和安全的角度考虑,C++11中新增了nullptr,用于表示空指针。
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif
3.4 范围for
范围for的底层是一个迭代器,也是用来遍历一个容器(或者容器适配器),其用法比较简单,如下:
四、STL中的一些变化
C++11中增加了一些新容器,如下:
对于第一个array,本质上就是一个数组,与vector的区别是,vector是动态的,可以随时扩容。
array与vector和普通的数组最大的区别在于,它的越界访问机制非常严格,越界读和越界写都会被检查出来。而vector和普通数组对于越界读不做检查,对于越界写则采用抽查的方式。
(除此之外,array就没有什么太大的用处了)
读者也可以自己去cplusplus网站看一下它的用法,这里不再赘述。
下一个是forward_list,这是一个单向的链表。而list则是一个带头的双向循环链表。
相较于list,这个容器增加了头插和头删操作:
但是注意,它并不支持尾插尾删操作,因为这需要遍历找到尾结点,会导致效率大大降低。
对于另外的两个,感兴趣的读者可以自己去网站上看一看,这里不多解释了。另外,对于以上两个容器的介绍也不完整,大家也可以看一下。C++网站
五、左/右值引用和移动语义(本篇重点)
5.1 做值引用和右值引用
传统的C++语法中就有引用的语法,而C++11中新增了的右值引用语法特性,所以从现在开始我们之前学习的引用就叫做左值引用。无论左值引用还是右值引用,都是给对象取别名。
什么是左值,什么是左值引用?
左值是一个表示数据的表达式(如变量名或解引用的指针),我们可以获取它的地址+可以对它赋值,左值可以出现赋值符号的左边,右值不能出现在赋值符号左边。定义时const修饰符后的左值,不能给他赋值,但是可以取它的地址。左值引用就是给左值的引用,给左值取别名。
如下:
int main()
{
// 以下的p、b、c、*p都是左值
int* p = new int(0);
int b = 1;
const int c = 2;
// 以下几个是对上面左值的左值引用
int*& rp = p;
int& rb = b;
const int& rc = c;
int& pvalue = *p;
return 0;
}
什么是右值,什么是右值引用?
右值也是一个表示数据的表达式,如:字面常量、表达式返回值,函数返回值(这个不能是左值引用返回)等等,右值可以出现在赋值符号的右边,但是不能出现出现在赋值符号的左边,右值不能取地址。右值引用就是对右值的引用,给右值取别名。
如下:
int main()
{
double x = 1.1, y = 2.2;
// 以下几个都是常见的右值
10;
x + y;
fmin(x, y);
// 以下几个都是对右值的右值引用
int&& rr1 = 10;
double&& rr2 = x + y;
double&& rr3 = fmin(x, y);
// 这里编译会报错:error C2106: “=”: 左操作数必须为左值
10 = 1;
x + y = 1;
fmin(x, y) = 1;
return 0;
}
需要注意的是右值是不能取地址的,但是给右值取别名后,会导致右值被存储到特定位置,且可以取到该位置的地址,也就是说例如:不能取字面量10的地址,但是rr1引用后,可以对rr1取地址,也可以修改rr1。如果不想rr1被修改,可以用const int&& rr1 去引用。
int main()
{
double x = 1.1, y = 2.2;
int&& rr1 = 10;
const double&& rr2 = x + y;
rr1 = 20;
rr2 = 5.5; // 报错
return 0;
}
5.2 左值引用与右值引用比较
左值引用总结:
- 左值引用只能引用左值,不能引用右值。
- 但是const左值引用既可引用左值,也可引用右值。
int main()
{
// 左值引用只能引用左值,不能引用右值。
int a = 10;
int& ra1 = a; // ra为a的别名
//int& ra2 = 10; // 编译失败,因为10是右值
// const左值引用既可引用左值,也可引用右值。
const int& ra3 = 10;
const int& ra4 = a;
return 0;
}
右值引用总结:
- 右值引用只能右值,不能引用左值。
- 但是右值引用可以move以后的左值。
int main()
{
// 右值引用只能右值,不能引用左值。
int&& r1 = 10;
// error C2440: “初始化”: 无法从“int”转换为“int &&”
// message : 无法将左值绑定到右值引用
int a = 10;
int&& r2 = a;
// 右值引用可以引用move以后的左值
int&& r3 = std::move(a);
return 0;
}
对于上面代码中的move,下文中做出解释。
5.3 右值引用使用场景和意义
先来说一下引用的意义:
在函数传参和函数传返回值时,使用引用,可以达到减少拷贝的效果。
现在应该明白上面所说的引用,其实指的是左值引用。
左值引用有没有彻底解决问题?
答案是没有,要不然就没有右值引用什么事了。当某一个变量/对象出了作用域就不存在了,这种情况就不能用引用返回了,这是众所周知的。
而当需要返回的变量/对象是一个特别复杂的结构,就必须要传值返回,就要进行深拷贝,效率将大大降低。
而右值引用就将解决这个问题。
为了解释它解决问题的原理,需要先自己实现一个string类,以便观察它解决的具体过程。string类代码如下:
namespace sny
{
class string
{
public:
typedef char* iterator;
iterator begin()
{
return _str;
}
iterator end()
{
return _str + _size;
}
string(const char* str = "")
:_size(strlen(str))
, _capacity(_size)
{
//cout << "string(char* str)" << endl;
_str = new char[_capacity + 1];
strcpy(_str, str);
}
// s1.swap(s2)
void swap(string& s)
{
::swap(_str, s._str);
::swap(_size, s._size);
::swap(_capacity, s._capacity);
}
// 拷贝构造
string(const string& s)
:_str(nullptr)
{
cout << "string(const string& s) -- 深拷贝" << endl;
string tmp(s._str);
swap(tmp);
}
// 赋值重载
string& operator=(const string& s)
{
cout << "string& operator=(string s) -- 深拷贝" << endl;
string tmp(s);
swap(tmp);
return *this;
}
~string()
{
delete[] _str;
_str = nullptr;
}
char& operator[](size_t pos)
{
assert(pos < _size);
return _str[pos];
}
void reserve(size_t n)
{
if (n > _capacity)
{
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_capacity = n;
}
}
void push_back(char ch)
{
if (_size >= _capacity)
{
size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2;
reserve(newcapacity);
}
_str[_size] = ch;
++_size;
_str[_size] = '\0';
}
//string operator+=(char ch)
string& operator+=(char ch)
{
push_back(ch);
return *this;
}
const char* c_str() const
{
return _str;
}
private:
char* _str = nullptr;
size_t _size = 0;
size_t _capacity = 0; // 不包含最后做标识的\0
};
string to_string(int value)
{
bool flag = true;
if (value < 0)
{
flag = false;
value = 0 - value;
}
sny::string str;
while (value > 0)
{
int x = value % 10;
value /= 10;
str += ('0' + x);
}
if (flag == false)
{
str += '-';
}
std::reverse(str.begin(), str.end());
return str;
}
}
现在假设读者对上面类中的所有函数都已经理解了,然后再看下面这行代码:
int main()
{
sny::string ret = sny::to_string(-1234);
return 0;
}
这里注意,本来调用to_string函数最后返回值的时候,str到ret应该是两次拷贝----str出了作用域要销毁,所以会产生一个临时变量,然后再用这个变量拷贝给ret。但是编译器对于这种连续的拷贝作了优化,所以最后只会有一次拷贝。

另外,一定是连续的拷贝才会被优化,否则不会优化,如下:
注意,这里出现三次而不是两次拷贝构造,是因为上面代码中的拷贝构造使用的是现代写法实现的,里面多了一次拷贝。
但是,就算是作了优化,但最后还是有一次拷贝,C++11的解决方法是什么呢?
答案是移动构造:
//移动构造
string(string&& s)
{
cout << "string(string&& s) -- 移动拷贝" << endl;
swap(s);
}
这段代码要放在上面的string类中。
这里再补充一点:
C++11中的右值又分为纯右值和将亡值。
纯右值一般指的是内置类型表达式的值;将亡值一般指的是自定义类型表达式的值。
顾名思义,将亡值就是快要嗝儿屁的值。既然都要嗝儿屁了,就没必要再将其内容拷贝一遍了,直接将其抢过来就行。(但这里的抢不是单纯地抢,而是将自己和它做交换)
所以,上面例子中,编译器做出的优化可以分为两部分----两次连续的构造合并为一次,以及返回的str被识别为右值。所以,就调用了移动构造。
但是这个东西要慎用,因为自己的东西也会被换给它,然后被它一起带到坟墓里。如下:
同样的,赋值构造也可以采用类似的做法:
// 移动赋值
string& operator=(string&& s)
{
cout << "string& operator=(string&& s) -- 移动赋值" << endl;
swap(s);
return *this;
}
注意!!!右值引用的工作机制是借助于移动语义(移动构造或移动赋值),进行资源转移,而不是延长将亡值的生命周期!(有一些文章中说延长生命周期毫无疑问是错的)
5.4 万能引用
虽然右值引用很厉害,但是左值引用只能引用左值,右值引用只能引用右值。当两个变量/类型需要完成相同的功能,但差别仅仅是一个是左值,一个是右值时,就不得不写两个版本的功能函数,造成了代码冗余。
所以,C++11又增加了一个万能引用,可以接收左值和右值,如下:
template<typename T>
void PerfectForward(T&& t)
{
//
}
int main()
{
PerfectForward(10);// 右值
int a;
PerfectForward(a);// 左值
PerfectForward(std::move(a)); // 右值
const int b = 8;
PerfectForward(b);// const 左值
PerfectForward(std::move(b)); // const 右值
return 0;
}

但是注意,如果传过去的参数属性为const,则模板内不能对其更改;若没有const属性的参数,则可以修改,如下:

5.5 完美转发
如果对于上面的模板中接收到的值,再一次传参,会怎么样呢?
首先,铺垫一个小知识点,任何右值引用的本质都是左值,比如:
int&& rr=10;
rr本身就是一个左值。因为10作为一个常量本来没有为其准备存储的地址,但是一旦被右值引用,就必须在内存中为它开一个空间进行存储,这时rr就成了左值。
所以,在上面的代码中,所有的t本质都是左值,如下:
如果将其move一下,就全都变成右值了。那到底如何将其以原来的属性传参呢?
这个时候就要用到完美转发了,它可以发在传参的过程中保留对象原生类型属性,如下:
完美转发原理如下:文章来源:https://www.toymoban.com/news/detail-413498.html
//完美转发原型
T&& forward(T&& t) { return static_cast<T&&>(t); }
// 用法: template<typename T>
void func1(T && val) { func2(std::forward<T>(val)); }
// 当传入左值引用
void func1(T& && val) { func2(static_cast<T& &&>(val)); }
// 引用折叠后:
void func1(T& val) { func2(static_cast<T&>(val)); }
// 当传入右值引用
void func1(T&& && val) { func2(static_cast<T&& &&>(val)); }
// 引用折叠后:
void func1(T&& val) { func2(static_cast<T&&>(val)); }
本篇完,青山不改,绿水长流!文章来源地址https://www.toymoban.com/news/detail-413498.html
到了这里,关于【C++11那些事儿(一)】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[apue] 进程环境那些事儿](https://imgs.yssmx.com/Uploads/2024/02/679141-1.png)
![[apue] 进程控制那些事儿](https://imgs.yssmx.com/Uploads/2024/04/844321-1.png)