目录
一、kafka生产者原理
二、kafka异步发送
配置kafka
创建对象,发送数据
带回调函数的异步发送
同步发送
文章来源地址https://www.toymoban.com/news/detail-413572.html
三、kafka生产者分区
分区策略
指定分区:
指定key:
什么都不指定:
自定义分区器
四、生产者提高吞吐量
五、数据的可靠性
ACK应答级别
数据完全可靠条件
可靠性总结
代码中配置ACK
五、数据重复
幂等性
生产者事务
六、数据有序、乱序
数据有序
数据乱序
一、kafka生产者原理
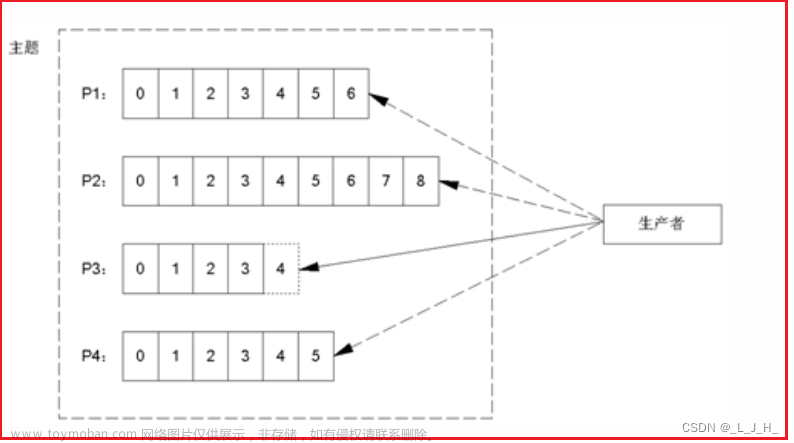
main线程中创建生产者对象,然后调用send方法来发送数据,根据生产环境的需求来判断是否要增加拦截器(一般建议不用),因为是跨节点通信,所以要对数据进行序列化,用kafka自带的序列化器处理,再由分区器来规定数据发送到哪个分区,先发送到了一个缓存队列当中,队列大小是32M,其中每个批次默认大小是16k,达到16k后就会进入sender线程发送到kafka集群,或者等待时间到了也会自动发送,每一个broker节点接受一个队列的消息,发送到分区后,分区最多缓存5个请求,如果达到5个请求都没有ack应答的话,那么接下来消息就会发送到别的分区上。
通过Selector将底层链路进行打通进行发送数据,集群收到后进行一个副本的同步,同步完成后进行ack应答。

应答成功后清理队列中的数据

应答失败会进行retry重试

二、kafka异步发送


创建Maven工程导入kafka客户端依赖

导包

配置kafka

创建对象,发送数据

带回调函数的异步发送

同步发送


三、kafka生产者分区

分区策略



指定分区:

指定key:

什么都不指定:

怎么把订单表的数据发送到kafka的指定分区中?
key 上写表名,表名的hashcode值一定会发送到同一个分区(生产环境通常将表名作为key)
自定义分区器




在生产者中关联自定义分区器

在生产环境中可以过滤一些脏数据!
四、生产者提高吞吐量

压缩类型:


五、数据的可靠性
ACK应答级别
0的时候,数据发过来还没落盘就应答,结果leader挂了导致了数据丢失。

1的时候,数据发送过来,leader落盘后就会应答,生产者收到ack应答认为信息已经发送成功,随后就会清除掉队列中的消息,但是此时follwer可能还没完成同步,这个时候leader挂掉,就会有一个follwer成为新的leader,可是生产者已经认为信息发送成功从队列中清除了消息,这就导致了数据的丢失。

-1(all):leader收到消息,并且所有follwer都完成消息同步后返回ack应答


 follwer挂掉的话,等时间达到阈值还没向Leader发送通信请求或同步数据就会被踢出ISR,意味着这个follwer就不是有效副本了!
follwer挂掉的话,等时间达到阈值还没向Leader发送通信请求或同步数据就会被踢出ISR,意味着这个follwer就不是有效副本了!

上面几种都有数据丢失的风险,如何真正保护数据的可靠性呢?
数据完全可靠条件

ack级别设置为-1,且至少1个leader+1个follwer,ISR里min.insync.replicas >= 2
可靠性总结

代码中配置ACK

五、数据重复

幂等性


生产者事务




六、数据有序、乱序
数据有序

数据乱序
 文章来源:https://www.toymoban.com/news/detail-413572.html
文章来源:https://www.toymoban.com/news/detail-413572.html
到了这里,关于Kafka 生产者的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!