引言:
北京时间:2023/3/27/7:05,哈哈哈,首先是开心,因为上篇博客热榜目前第15,让我初步掌握了上热榜的小妙招,不单单只是要日更,还有非常多的上榜小技巧,但是首先连续更新的占比还是比较大的,好像连续更新上榜的概率更大,所以让我们开始连续更新吧!今天我们就来学一学真正的基础IO、文件系统和承接上文的部分知识,如缓冲区、重定向等!So,here we go!

再谈缓冲区
回顾一切皆文件
当操作系统需要访问文件对象时,第一时间就是找到该进程对应的pcb,然后从该pcb中找到指向文件描述符表的指针,通过这个指针找到文件描述符表,进而找打文件描述符表中的各个文件对象的地址,所以在进程看来,它访问的都是一个一个的文件对象而已,根本没有和外设的驱动程序进行交互,因为这个工作已经被文件对象中的读写函数指针给搞定了,并且如果操作系统需要读写数据到相应的外设中,那么此时第一时间就是将数据拷贝到文件对象的文件缓冲区中,然后让文件对象中的相关函数指针去和外设的驱动程序进行交互,进而把数据读写到外设中,所以这就是为什么在Linux操作系统中一切皆文件的原因了,具体如下图所示:
这种结构或者说这样设计的好处就是:无论底层怎样差异化,我们通过文件对象中的函数指针的方式都可以很好的屏蔽这些差异,让操作系统通过进程,进程通过文件对象把数据准确无误的拷贝到相应的外设中或者是读取外设中的数据。并且这种做法就是传说中的多态,一个面向对象的过程;并且因为我们想用访问操作系统,只能通过进程的方式,所以无论我们用什么方式访问,我们都是用进程的方式去访问操作系统,然后因为进程只能看到文件,所以对于我们来说,我们看到的也就是一切皆文件
系统层面和语言层面相结合
首先,通过上述的知识,我们明白了,操作系统想要访问一个文件,就必须找到该文件对应的进程,找到进程对应的文件描述符表,最终根据地址找到文件对象,如果找不到文件对象,就访问不了相对应的外设,并且任何语言想要访问外设或者文件,必须贯穿体系结构,调用系统调用,经历操作系统,所以我们现在写代码使用的头文件本质都是在调用一个一个的库(C库),通过这些库的封装,去调用系统接口,进而通过操作系统到进程,通过进程到文件描述符表,最后在文件描述符表中找到对应的文件,所以明白,C库本质调用它时,它就会被放在一个可执行文件中,所以C库本质可以理解就是一个进程,用户通过进程就可以去调用操作系统,并且操作系统想要找到对应的文件,又需要根据该进程(此时就是C库),因为只有该进程中有指向文件描述符表的指针,进而操作系统通过该进程中的指针找到文件描述符表,然后找到文件,所以明白最重要的一个道理 , 就是我们的进程中一定是需要有指向文件描述符表的一个指针,并且因为此时C库就是调用操作系统的那个进程,所以明白,C库中一定有指向文件描述符表的指针, 明白这个道理之后,再明白一个道理:
深入FILE*
上篇博客中,我们已经了解了语言层面的文件操作(fopen,fclose,fread等),但是我们会发现,无论使用什么接口,此时都需要使用一个FILE* 的指针来接收该接口的返回值,所以FILE* 到底是什么呢?通过上述对C库的理解,我们知道,C库中一定有一个指向文件描述符的指针,并且明白,C库中的文件操作函数是通过封装系统调用接口(open、close、read等)实现了**,所以我们可以推测FILE是一种数据类型,是一个结构体**,明白 FILE 就是C库里面封装的一个结构体,此时在该结构体中,就存在着各种系统接口的封装和指向文件描述符的指针, 并且在使用的时候,就是通过这个指向文件描述符的指针去找到对应的文件地址,然后把这个地址传给封装的接口(fopen),最后通过这个封装的接口,把地址传给系统调用的接口(open);如下图所示:就是Linux系统中C库中的FILE结构体封装
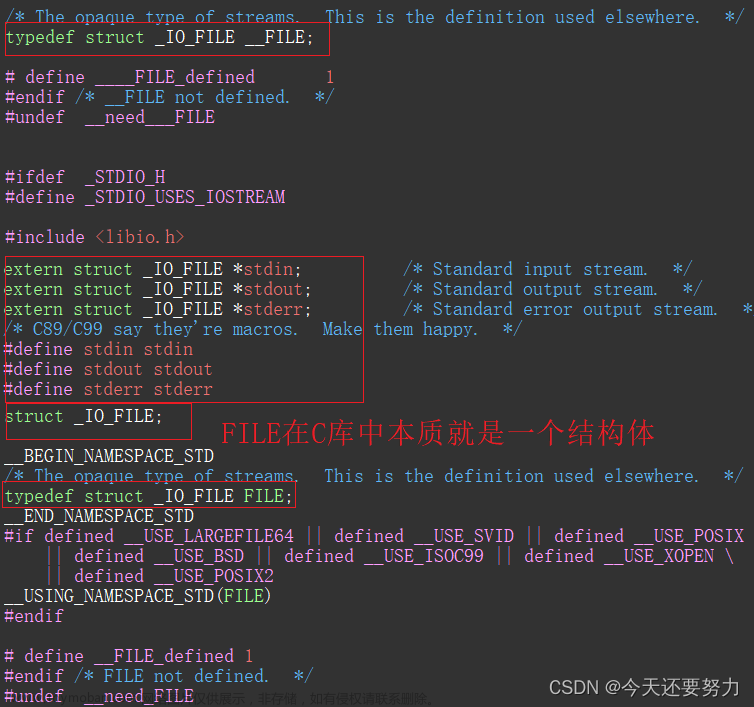
所以明白了这两点之后,我们就明白了语言层面的文件操作的具体原理了,如下图,证明我们的语言层面封装的库中存在指向文件描述符表的指针:
重定向的本质
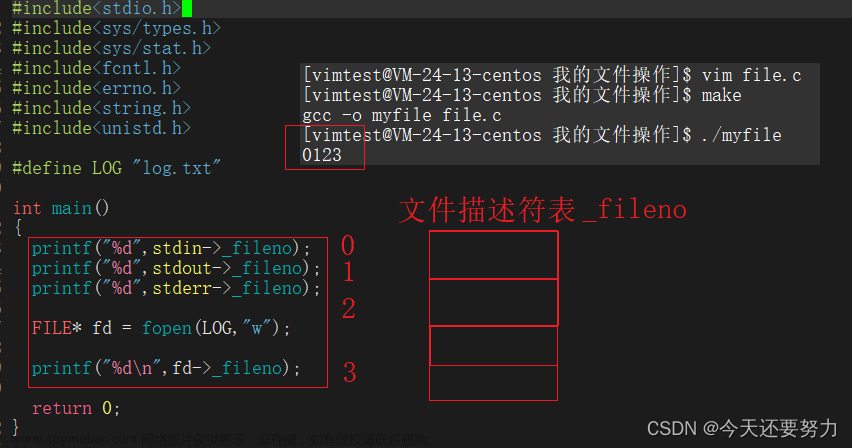
通过上篇博客中对文件描述符的认识,此时我们明白,当一个进程创建只是,操作系统是默认已经打开了三个文件:标准输入、标准输出和标准错误,并且知道,它们对应的在文件描述符表中的下标是0 1 2 ,并且明白一个道理,就是在进程中,如果该进程对应的代码数据,具有打开文件的操作,此时操作系统就会把在磁盘中对应的文件加载到内存,然后创景一个文件对象(struct file),并且会把该文件对象的地址给给文件描述符表保管(目的提高效率),并且在文件描述符表中存储该地址的时候,是按照一定的规律的,并不像是物理内存一样,放在一个随机的地方,而是按照统一原则,将最小的没有被使用的数组元素(也就是那个下标),分配给该被打开的文件对象的地址 ,如下图右侧所示,此时进行了5次文件的打开,所以在文件描述符表中,就是从0 1 2 之后的下标3 4 5 6 7 开始存放相应的文件对象地址(虽然是同一个文件,但是不影响,考虑的是打开该文件的次数),但是如果此时你像右边图片一样,把标准输入文件给关闭,也就是等于将文件描述符表下标为0中的地址给清空掉,此时操作系统就允许你往该下标中存放文件对象的地址,所以右图的打印就是0 3 4 5 6(文件描述符的下标对应的就是文件的返回值)
如图深入文件描述符表的理解:
输出重定向
搞懂了上述现象是为什么,此时我们就深入看看下图的现象,正式了解重定向的本质,可以发现,当我们把标准输入文件给关闭并且打开了一个log.txt文件,通过上述现象明白,因为标准输入被关闭,所以log.txt这个文件对象的地址,此时就是存储在文件描述符表中下标为1的位置,然后最后通过打印发现,如果不把标准输入关闭,那么此时的打印结果,就是向标准输入文件中打印(也就是打印到我们的显示器上),但是如果,我们把标准输入给关闭(就是文件描述符表下标为1),此时可以发现,当我们再一次执行程序的时候,显示器上就不会再打印出我想要的内容,反而当我们查看被打开文件log.txt(也就是此时存储在文件描述符表中下标1处的文件对象地址)此时该文件中的内容是我想要打印的内容,这是为什么呢?所以上述的这一些奇奇怪怪的现象,我们就把它称为输出重定向,将本应该在标准输出(显示器)上输出的数据通过重定向的方式在别的文件中输出(log.txt) ,具体如下图所示:
一图搞定输出重定向:
结论: 我们无论是去调用系统调用接口还是调用库函数,本质上这些接口都不关心它是否是向标准输出文件中打印数据,它们只关心在文件描述符表中下标为1的位置处有没有文件对象的地址给它打印,到底向那个文件对象打印,它根本不在乎。
重定向原理:在上层无法感知的情况下,在操作系统内部,更改进程对应的文件描述符表中的下标中指针指向的地址
输入重定向
明白了上述输出重定向的原理,此时如下图所示,输入重定向也是同理的,本质就是将系统默认打开的标准输入、标准输出和标准错误文件关闭,然后按照文件描述符表的规律,让该下标拥有一个新的文件,此时通过这个文件进行读写步骤
追加重定向
并且我们通过输出重定向可以明白一个点,就是当我们需要将数据输出到标准输入或者某个下标为1的文件中时,这个文件每次都是会被清理的,导致我们每次写入的数据都是重新开始的,所以此时我们的追加重定向的原理,本质上就是将打来文件的方式给变换一下,从原来的 int fd = open(LOG,O_WRONLY | O_CREAT | O_TRUNC,0666); 变成 int fd = open(LOG,O_WRONLY | O_CREAT | O_APPEND,0666); 如这两句代码一样,只要把 O_TRUNC(清理)改成O_APPEND(追加),这样我们就从输出重定向,直接就变成了一个追加重定向了,所以输出重定向和追加重定向So,So!
总:无论是输出重定向还是追加重定向,它们都是想文件描述符表中下标为1中写入数据文章来源:https://www.toymoban.com/news/detail-413918.html
北京时间:2023/3/27/23:22 文章来源地址https://www.toymoban.com/news/detail-413918.html
文章来源地址https://www.toymoban.com/news/detail-413918.html
总结:不能熬夜,作息要稍稍健康一些,所以睡觉啦!像什么基础IO和文件系统我直接摆烂,哈哈哈!
到了这里,关于学习系统编程No.11【重定向的本质】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!













