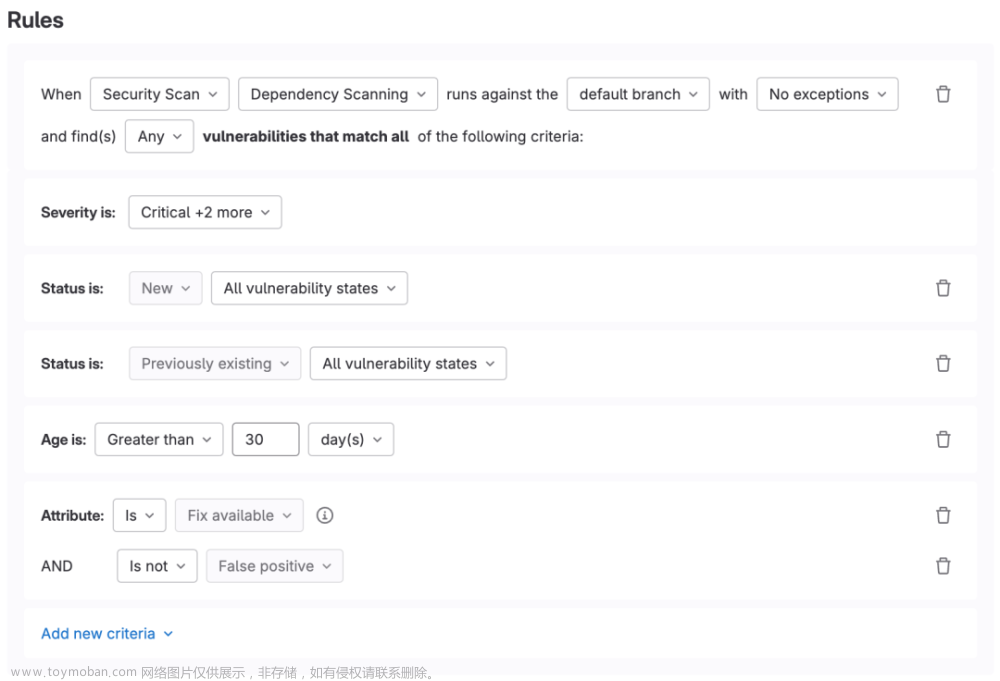
1 企业级AI应用的高昂成本
人工智能仍处于科技浪潮之巅…
随着智能芯片、大数据和云计算的发展,深度学习技术得到进一步升级。以ChatGPT为首的AIGC技术大放异彩:AI绘画、AI作曲、AI编程、AI写作…一系列AI产品赋能生产;边缘计算、联邦学习、多智能体等技术逐渐从学术界走向工业界,提高生产效率;传统计算机视觉、自然语言处理进一步深入人们的日常生活;智慧城市、智能家居、智能交通等概念不断提出。

在可预见的未来,人工智能技术的应用将会进一步扩展到更多领域。然而搭建企业级AI应用需要考虑多个方面,包括
- 数据准备:搜集业务数据并处理成格式化的数据,同时需要保护隐私并遵守法规。
- 数据清洗:对数据进行预处理、清洗、格式转换等操作,确保数据的质量和准确性。
- 特征工程:对数据进行特征提取和转换,以便为模型提供有用的信息。
- 模型设计:基于业务需求和数据分析结果选择合适的算法,进行模型设计和训练。
- 模型调优:对模型进行调优,包括调整超参数、选择合适的损失函数、优化算法等,以提高模型的性能。
- 模型部署:将训练好的模型部署到生产环境中,提供可靠、高效、安全的服务。
- 模型监控:对模型进行监控,确保模型的准确性和稳定性,并及时处理问题。
- 持续优化:不断地优化和改进模型,以满足业务需求和提高效果。
- …
对于非人工智能领域的应用行业而言,往往需要寻求专业团队或合作伙伴的支持,可以想象,这个过程耗费人力、物力、精力。因此,如何提供一个方便快捷的完整企业级人工智能解决方案,便于下游行业快速处理柔性商业业务成为一大需求。
幸运的是,亚马逊提供了这样一个平台——Amazon SageMaker,可以降低应用领域构建AI模型的门槛,提高生产效率
2 什么是Amazon SageMaker?
Amazon SageMaker是一个托管的机器学习服务,由亚马逊网站(AWS)提供。它使数据科学家和开发人员能够快速构建、培训和部署机器学习模型。
Amazon SageMaker提供了一系列工具和功能,使用户能够在一个集成的环境中完成整个机器学习过程,包括数据准备、模型训练、模型调优和部署。除此之外,Amazon SageMaker还提供了多种预构建的算法和框架,包括XGBoost、TensorFlow和PyTorch等。

Amazon SageMaker是一个全面的机器学习平台,有非常广泛的应用场景
-
企业级机器学习应用
Amazon SageMaker提供了自动模型调整、模型解释和模型部署等多种功能,使用户可以轻松构建和部署机器学习模型。例如
一个金融机构可以使用Amazon SageMaker来构建和部署一个欺诈检测模型,以识别信用卡欺诈行为。
-
云原生机器学习
Amazon SageMaker可以轻松地与其他AWS云服务集成。例如,用户可以使用AWS Lambda和Amazon API Gateway来创建一个API,使其他应用程序可以访问Amazon SageMaker模型的预测结果。
-
高性能机器学习
Amazon SageMaker提供了高性能的计算实例和GPU实例,可以处理大规模的机器学习数据集和复杂的深度学习模型。例如
一个医疗图像诊断应用可以使用Amazon SageMaker中的GPU实例来训练和部署一个深度学习模型,以识别患者的病情。
-
机器学习模型解释
Amazon SageMaker提供了模型解释功能,可以帮助用户理解机器学习模型的决策过程。例如
一个电商公司可以使用Amazon SageMaker来解释一个推荐系统模型的预测结果,以便更好地理解为什么该产品被推荐给了某个用户。
接下来基于Amazon SageMaker进行两个案例讲解
3 案例一:快速构建图像分类应用
3.1 卷积神经网络
基于生物神经理论的启发,产生了人工神经网络(neuron networks)模型,其是由具有适应性简单单元组成的广泛并行互连网络,能够模拟生物神经系统对外界输入进行智能交互反应。神经网络的基本组成单元称为神经元(Neuron),每个神经元与其他若干神经元相连组网。当神经元的输入超过偏置阈值,则它会被激活产生输出,将信号传递给神经网络中的其他部分。
卷积神经网络是包含了若干卷积层的神经网络结构。主要用于处理视觉任务。其基本原理是模板匹配与学习,即根据目的图像设计模板(卷积核),只有符合模板特征的原图像像素区域才能获得最大响应。通过网络学习的方式拟合卷积模板,提取图像特征信息,避免了显式的特征检测与计算。因此CNN对图像任务的泛化能力较强。
同时,根据平移不变性和局部性假设,输入卷积层特征图的所有像素共享同一个模板参数而与像素坐标无关,所以CNN整体可实现参数共享、并行学习,加快学习效率。举例而言,以一张二维图片为输入,则全连接网络的输入层神经元个数将非常庞大,再考虑每个神经元都与相邻层所有神经元相连,因此作为优化目标的连接权矩阵指数增长,带来无法接受的计算复杂度。而CNN通过卷积实现了高维信息的聚合与压缩,滤除了掺杂的大量冗余信息,大幅提高可学习性。
针对经典的MNIST手写数字图像分类实验,基于Amazon SageMaker框架自主设计神经网络,对比本地训练和Amazon SageMaker训练的网络性能。实验的流程如下:
- 搭建卷积神经网络;
- 加载数据集。下载MNIST手写数字数据集,划分训练集、验证集和测试集,并封装为可迭代的数据加载器对象;
- 训练模型。定义损失函数和优化方法,通过前向传播计算损失,再基于反向传播优化模型参数,迭代至训练误差收敛后保存模型到本地;
3.2 本地测试版本
如下所示,搭建卷积神经网络
class CNN(nn.Module):
'''
* @breif: 卷积神经网络
'''
def __init__(self):
super().__init__()
self.convPoolLayer_1 = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=10, kernel_size=5),
nn.MaxPool2d(kernel_size=2),
nn.ReLU()
)
self.convPoolLayer_2 = nn.Sequential(
nn.Conv2d(in_channels=10, out_channels=20, kernel_size=5),
nn.MaxPool2d(kernel_size=2),
nn.ReLU()
)
self.fcLayer = nn.Linear(320, 10)
def forward(self, x):
batchSize = x.size(0)
x = self.convPoolLayer_1(x)
x = self.convPoolLayer_2(x)
x = x.reshape(batchSize, -1)
x = self.fcLayer(x)
return x
使用pytorch提供的Dataset类进行MNIST数据集加载和预览
from abc import abstractmethod
import numpy as np
from torchvision.datasets import mnist
from torch.utils.data import Dataset
from PIL import Image
class mnistData(Dataset):
'''
* @breif: MNIST数据集抽象接口
* @param[in]: dataPath -> 数据集存放路径
* @param[in]: transforms -> 数据集变换
'''
def __init__(self, dataPath: str, transforms=None) -> None:
super().__init__()
self.dataPath = dataPath
self.transforms = transforms
self.data, self.label = [], []
def __len__(self) -> int:
return len(self.label)
def __getitem__(self, idx: int):
img = self.data[idx]
if self.transforms:
img = self.transforms(img)
return img, self.label[idx]
def loadData(self, train: bool) -> list:
'''
* @breif: 下载与加载数据集
* @param[in]: train -> 是否为训练集
* @retval: 数据与标签列表
'''
# 如果指定目录下不存在数据集则下载
dataSet = mnist.MNIST(self.dataPath, train=train, download=True)
# 初始化数据与标签
data = [ i[0] for i in dataSet ]
label = [ i[1] for i in dataSet ]
return data, label

考虑到该实践是多分类问题,因此最终网络的输出是十维向量并经过softmax转化为概率分布,损失函数设计为交叉熵,优化方法选择随机梯度下降算法。
for images, labels in trainBar:
images, labels = images.to(config.device), labels.to(config.device)
# 梯度清零
opt.zero_grad()
# 正向传播
outputs = model(images)
# 计算损失
loss = F.cross_entropy(outputs, labels)
# 反向传播
loss.backward()
# 模型更新
opt.step()

训练十分钟后,模型预测达到了89%的准确率
3.3 Amazon SageMaker版本
首先搭建卷积神经网络
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
接着加载数据集,可以看到,只要设置镜像并使用upload_data就可以自主下载数据集并把数据加载到Amazon SageMaker节点,用于后续训练,无需额外定义数据加载方式,调用更便捷、快速
from torchvision.datasets import MNIST
from torchvision import transforms
MNIST.mirrors = ["https://sagemaker-sample-files.s3.amazonaws.com/datasets/image/MNIST/"]
MNIST(
"data",
download=True,
transform=transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]
),
)
inputs = sagemaker_session.upload_data(path="data", bucket=bucket, key_prefix=prefix)
接着从Amazon SageMaker中导入Pytorch对象,并创建实例
from sagemaker.pytorch import PyTorch
estimator = PyTorch(
entry_point="mnist.py",
role=role,
py_version="py38",
framework_version="1.11.0",
instance_count=2,
instance_type="ml.c5.2xlarge",
hyperparameters={"epochs": 1, "backend": "gloo"},
)
一行代码即可开始训练
estimator.fit({"training": inputs})
四分钟左右模型完成训练,且测试集准确率达到91%
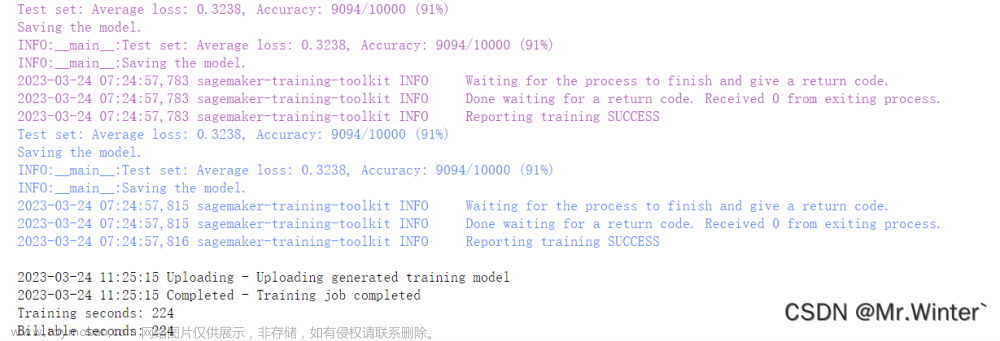
对于手写数字识别这种小任务,Amazon SageMaker的优势还不够明显,但已经能体会到构建人工智能学习模型的快速、训练的高效,不需要从底层实现一些数据读取、反向传播等,在应用方面可以大大提高工程效率
4 案例二:快速构建AI绘画应用
4.1 扩散模型简介
本节我们基于Amazon SageMaker和diffusion model快速构建一个AI绘画应用。
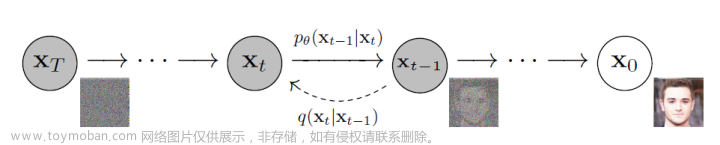
先简单介绍一下扩散模型diffusion model。这是一种生成式人工智能模型,用于生成高质量、高保真度的图像。它基于一种名为扩散过程的物理现象,利用偏微分方程描述像素值在时间和空间上的扩散和演化。
所谓扩散算法diffusion是指先将一幅画面逐步加入噪点,一直到整个画面都变成白噪声。记录这个过程,然后逆转过来给AI学习。AI看到的是什么?一个全是噪点的画面如何一点点变清晰直到变成一幅画,AI通过学习这个逐步去噪点的过程来学会作画。
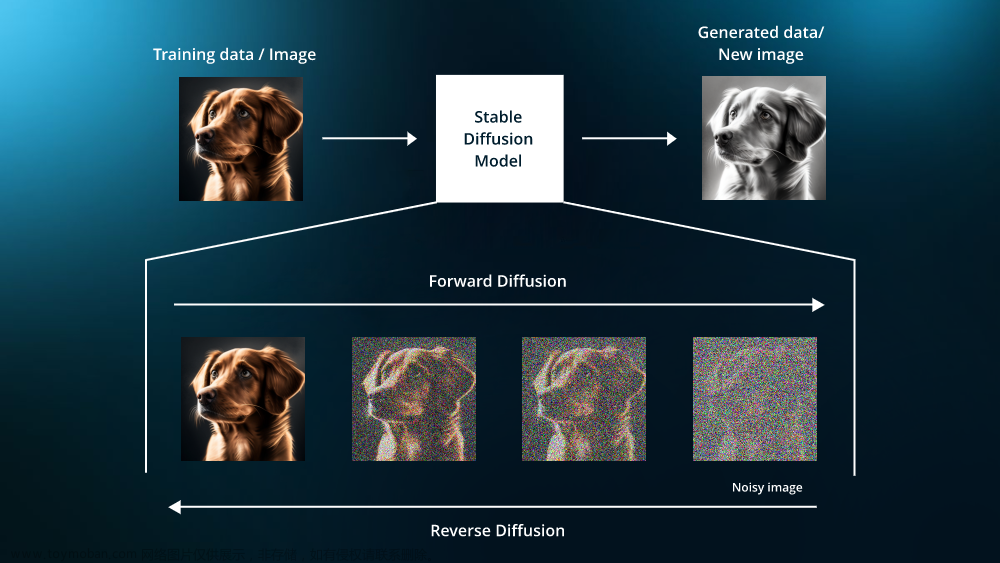
diffusion和之前大火的GAN模型相比,有什么优势呢?用OpenAI的一篇论文内容来讲,用diffusion生成的图像质量明显优于GAN模型;而且与GAN不同,diffusion不用在鞍点问题上纠结——涉及稳定性问题,只需要去最小化一个标准的凸交叉熵损失即可,这样就大大简化了模型训练过程中,数据处理的难度。
总结来说,目前的训练技术让diffusion直接跨越了GAN领域调模型的阶段,而是直接可以用来做下游任务,是一个新的数学范式在图像领域应用的实例。所以在应用方面,diffusion已被广泛应用于图像生成、图像修复、图像超分辨率等领域。通过使用文本输入作为条件信息,它可以根据文本的描述生成高质量的图像,例如基于文本描述生成动漫场景、自然风景等。
4.2 模型构建与部署
首先,在Amazon SageMaker里进行简单配置一个Notebook,我这里的配置如下
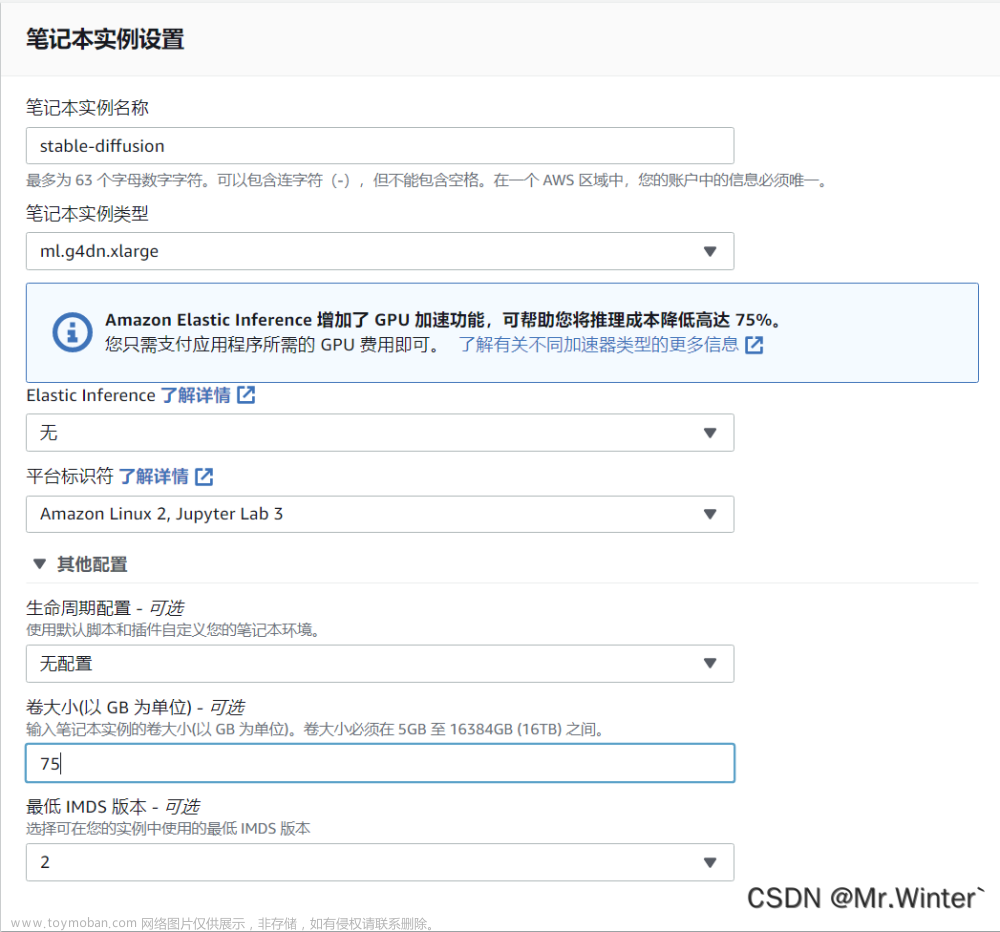
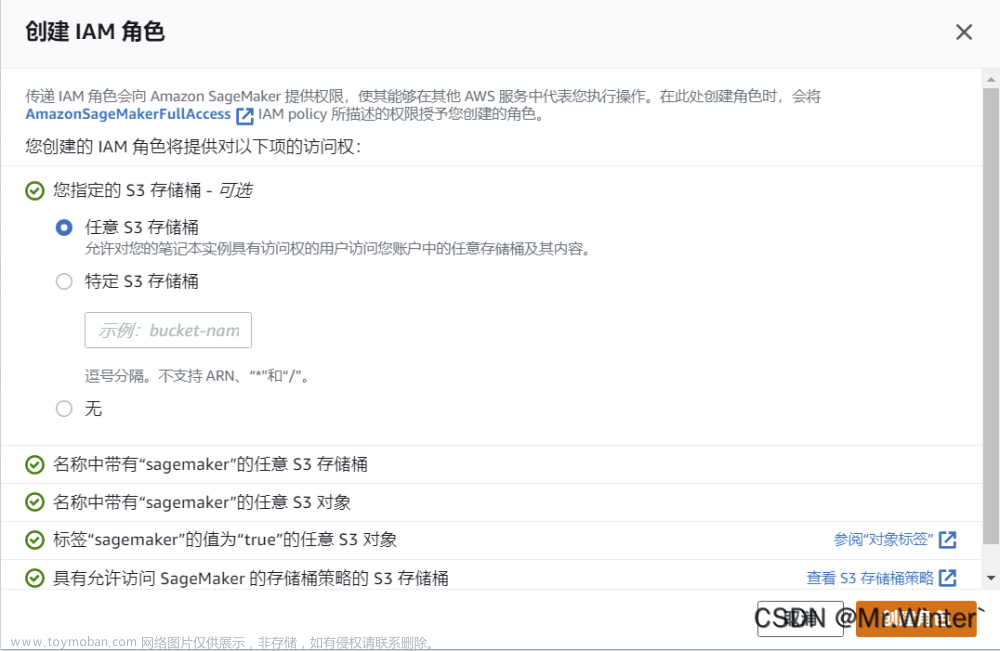
接着创建一个IAM角色,用于调用调用包括 Amazon SageMaker和 S3 在内的其他服务。例如上传模型,部署模型等,设置保持缺省即可。
构建和训练模型后,Amazon SageMaker允许我们将模型部署至终端节点,以中获取预测推理结果。
使用Amazon SageMaker托管服务部署模型有多种选择,例如
- Python 开发工具包 (Boto3)
- Amazon SageMakerPython 开发工具包
- AWS CLI
- Amazon SageMaker控制台交互部署
- …
这里我们以Python 开发工具包 (Boto3)为例构建这个AI绘画应用,主要包含以下步骤:
- 安装并检查依赖
- 在Notebook中配置模型
import torch import datetime from diffusers import StableDiffusionPipeline # Load stable diffusion pipe = StableDiffusionPipeline.from_pretrained(SD_MODEL, torch_dtype=torch.float16) - 编写初始化的Amazon SageMaker代码用于部署推理终端节点
import sagemaker import boto3 sagemaker_session_bucket=None if sagemaker_session_bucket is None and sess is not None: sagemaker_session_bucket = sess.default_bucket() ... sess = sagemaker.Session(default_bucket=sagemaker_session_bucket) - 构建推理脚本
import base64 import torch from io import BytesIO from diffusers import StableDiffusionPipeline def model_fn(model_dir): # Load stable diffusion and move it to the GPU pipe = StableDiffusionPipeline.from_pretrained(model_dir, torch_dtype=torch.float16) pipe = pipe.to("cuda") return pipe def predict_fn(data, pipe): ... - 打包上传模型
from sagemaker.s3 import S3Uploader sd_model_uri=S3Uploader.upload(local_path=f"{SD_MODEL}.tar.gz", desired_s3_uri=f"s3://{sess.default_bucket()}/stable-diffusion") - 使用HuggingFace将模型部署至Amazon SageMaker
predictor[SD_MODEL] = huggingface_model[SD_MODEL].deploy( initial_instance_count=1, instance_type="ml.g4dn.xlarge", endpoint_name=f"{SD_MODEL}-endpoint" )
至此就完成了模型的构建与部署,接下来我们就可以基于推理终端节点生成自定义图片
4.3 AI绘画测试(文生图)
输入以下测试代码
response = predictor[SD_MODEL].predict(data={
"prompt": [
"Eiffel tower landing on the Mars",
],
"height" : 512,
"width" : 512,
"num_images_per_prompt":1
}
)
#decode images
decoded_images = [decode_base64_image(image) for image in response["generated_images"]]
#visualize generation
for image in decoded_images:
display(image)
比如我们现在想生成一张《艾菲尔铁塔登陆火星》的图片,就可以获得

下面是《宇航员骑马》的生成绘图

下面是《卡通猴子玩电脑》的生成绘图

可以看出这个快速构建的应用还是很方便的!
5 结语
5.1 实践体验与展望
整体体验Amazon SageMaker后,我发现它是一个非常强大且易于使用的机器学习平台。首先它提供了多种不同的机器学习框架中进行选择,这使得我可以轻松地选择我最熟悉或最适合我的需求的框架来构建、训练和部署机器学习模型,而无需考虑环境的问题。
在案例一中可以看到,SageMaker提供了许多预构建的机器学习算法,这些算法涵盖了各种不同的用例和问题类型。这让用户可以轻松地选择并使用适合我的需求的算法。在案例二中可以看到,SageMaker提供了多种集成部署选项,包括托管端点、托管容器、AWS Lambda函数等等。这让用户可以轻松地将模型部署到任何需要的环境中,无论是云上还是本地。此外,SageMaker的文档资源非常丰富和详细,这让用户在使用过程中遇到任何问题时都能够快速找到帮助和支持。Amazon SageMaker还具备高级的安全性和隐私保护机制,例如数据加密、身份验证和访问控制等。这些机制可以保护用户的数据和模型,保证机器学习应用的安全性和可信度。
总的来说,和现有的机器学习平台相比,Amazon SageMaker核心在于快速构建、训练和部署机器学习应用,非常适合和各个应用领域结合,快速提供搭建企业级AI模型的完整解决方案。

在体验过程中,也发现Amazon SageMaker有一些不足。最首要的是经济成本,使用Amazon SageMaker可能需要花费较高的费用,尤其是在处理大规模数据集或进行长时间的训练时。所以Amazon SageMaker并不适合那些较小需求的个人用户,而比较符合企业级AI应用搭建的定位。
其次,尽管Amazon SageMaker提供了易于使用的控制面板、API和文档,但因为涉及多个不同的技术和工具,其学习曲线可能较陡峭,对于没有经验的用户来说,仍可能需要较长时间的学习和试错,积累一定的技术知识。
另外,Amazon SageMaker在自定义方面缺乏一定自由度,Amazon SageMaker的许多功能和服务都是与Amazon生态系统紧密关联的。如果用户需要的特定算法或开源框架(如图神经网络、对抗性学习等)不在Amazon SageMaker提供的生态中,则可能需要花费更多的时间和精力进行自定义开发或集成。
未来,期待Amazon SageMaker继续向自动化机器学习功能(AutoML)功能发力,提供更加完善、更加智能、更加高效的模型设计和部署体验,减缓用户学习曲线。同时,对于快速迭代的产品,也期待Amazon SageMaker能够提供更加智能的模型管理和监控功能,特别是模型版本控制——这是团队协作时必然会碰到的需求,以更好地管理和优化模型,提高机器学习应用的可靠性和稳定性。
5.2 云上探索实验室
 文章来源:https://www.toymoban.com/news/detail-414006.html
文章来源:https://www.toymoban.com/news/detail-414006.html
最后,分享一下亚马逊最新的云上实验室活动,通过云上探索实验室,开发者可以用技术实验、产品体验、案例应用等方式,与其他开发者小伙伴。一同创造分享,互助启发,玩转云上技术,为技术实践提供无限可能。云上探索实验室不仅是体验的空间,更是分享的平台!欢迎各位加入~文章来源地址https://www.toymoban.com/news/detail-414006.html
到了这里,关于Amazon SageMaker:搭建企业级AI模型的完整解决方案的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!