前言
一、单链表的概念
二、链表的创建
2.1链表的初始化
2.2 打印链表
2.3 获取链表的长度
2.4 判断链表是否为空
三、新增结点
3.1头插
3.2 指定下标插入
四、删除结点
4.1 头删
4.2 指定下标的删除
4.3 删除链表中的指定元素
五、单链表查找
六、附录
总代码
测试代码
总结

前言
前一小节内容,我们学习了有关线性表中顺序表的有关知识;今天我们将学习有关单链表的有关知识;单链表也是数据结构中的一大重点;今天就让我们来学习它吧!!!!!!!!!!
一、单链表的概念
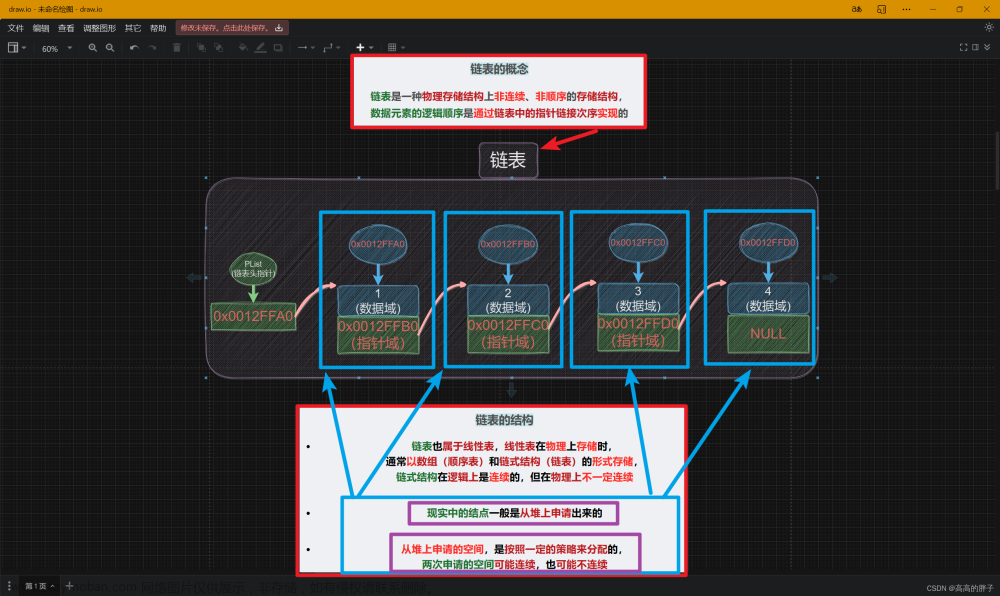
链表是一种物理存储结构上非连续、非顺序的存储结构,
整个链表就是通过对各个结点地址的链式储存来实现的 。(链表就是由一个一个结点所组成的)
举例说明:
链表的结构有点类似于火车,火车的每一节车厢都由插销,和钩子链接起来;
那么怎么这一个一个的结点是怎样链接起来呢?
在Java中他是通过引用所指向的地址来链接起来的。
什么意思呢?
就是说链表的每一个结点元素都分为连两部分,一部分用来储存数值,另一部分来储存地址。

储存的是谁的地址呀!就是下一个结点的地址。
比如说在链表中有三个结点,那么他们之间的关系是这样的:

既然说了,链表是由一个一个的结点组成的,那么在Java中结点是怎样定义的呢?
我们从上面也可以发现在每一个结点都是一个独立的小个体,我们不妨把他抽象为一个内部类,并放到单链表这个类的里面。这样我们就可以在单链表这个类里面使用我们结点这个小个体,并尝试把它串起来。
注意:本篇文章所讨论的单链表用到了两个文件:
- 单链表的构建文件MyLinkList.java
- 单链表的测试文件hLinkListTest.java

二、链表的创建
代码:
public class MyLinkList {
ListNode head = null; // 声明链表中的头结点
//创建单链表结构,将链表的每一个结点都定义成一个内部类
public class ListNode {
public int val; // 该结点的数值域,储存该结点的数值
public ListNode next; // 该结点的next域,储存的是下一个结点的地址,两个结点间正是通过next域产生关联
public ListNode(int val) { // 构造方法,给新生成的结点赋值,同时next默认为null
this.val = val;
}
}
}如图所示:我们定义了一个MyLinkList(单链表)类,同时在该类中还定义了一个内部类(结点类)。这样就创建了一个基本的链表结构。
但光这样肯定是不行的,我们对链表有一些基本的操作方法如下:
// 链表初始化
public ListNode listInit() { }
// 打印链表
public void linkedListPrint() { }
// 获取链表长度
public int getSize() { return -1; }
//判断该链表是否为空
private void isEmpty() { }2.1链表的初始化
首先我们要做的就是对我们的链表进行初始化的操作,那么怎么初始化呢?
当然是创建一些结点,并在每一个结点中都把下一个结点的地址给储存起来,然后相互链接起来的呀!
代码示例:
// 链表初始化 public ListNode listInit() { Scanner in = new Scanner(System.in); System.out.print("请输入你要构建的链表的初始长度:"); int n = in.nextInt(); System.out.print("请输入链表第1个元素的值:"); int firstVal = in.nextInt(); // this.head = new ListNode(firstVal); // 创建链表的第一个结点,将我们链表的头结点引用head指向链表的第一个结点 ListNode cur = head; // 创建一个引用cur去完成链表的初始化(头节点是整个链表的灵魂,不能直接使用,避免丢失链表) for (int i = 1; i < n; i++) { System.out.print("请输入链表第" + (i + 1) + "个元素的值:"); int val = in.nextInt(); ListNode node = new ListNode(val); // 当前结点的next域存放的是对下一个结点的引用变量node,node储存的就是下一个结点的地址 cur.next = node; // 当前结点的next域存放的是对下一个结点的引用变量node cur = node; // 将当前结点移向下一个结点 } return this.head; // 返回该链表的头结点 }
解析:
如图所示:
对于结点的链接:用的就是cur这个结点引用变量;
当我们的cur引用也指向第一个结点后,cur.next代表的就是第一个结点的next域,只要next域里储存了下一个结点的地址,这两个结点就链接起来了。
那要是再来个第三个结点node呢?
不要着急,我们只需要让cur = cur.next,cur.next = node就完成了结点间的链接;
当cur = cur.next 后,引用变量cur现在所引用的就变成了第二个结点,
那么cur.next = node的作用就是将第三个结点的地址储存到了第二个结点的next域里。
接下第四、第五个结点也大致是这样的操作;



你可以会问:为啥非得要再定义一个结点的引用变量cur呢?我之间用head头结点引用来不断的改变指向,完成结点间的链接,不可以吗?
可以是可以,但你有没有想过,如果用head来操作结点的化,你在初始化链表后head还指向头节点吗?你还能找到头结点吗?
2.2 打印链表
// 打印链表 public void linkedListPrint() { ListNode cur = head; // 创建一个引用cur去完成链表的遍历打印(头节点是整个链表的灵魂,不能直接使用,避免丢失链表) while (cur != null) { System.out.print(cur.val + " "); // cur.val表示的就是当前结点的数值 cur = cur.next; // 打印完了当前结点,cur继续指向下一个结点,完成对下一个结点的打印 } System.out.println(); }
2.3 获取链表的长度
// 打印链表 public void linkedListPrint() { ListNode cur = head; // 创建一个引用cur去完成链表的遍历打印(头节点是整个链表的灵魂,不能直接使用,避免丢失链表) while (cur != null) { System.out.print(cur.val + " "); // cur.val表示的就是当前结点的数值 cur = cur.next; // 打印完了当前结点,cur继续指向下一个结点,完成对下一个结点的打印 } System.out.println(); }
2.4 判断链表是否为空
/** * 判断该链表是否为空 * 为空就抛出异常,终止程序 */ private void isEmpty() { // 判断链表是否为空,只是该类中使用,所有 if (head == null) { System.out.println("该链表为空!!!"); throw new NullPointerException(); // 如果抛出的是 RunTimeException 或者 RunTimeException 的子类,则可以不用处理,直接交给JVM来处理 //异常一旦抛出,其后的代码就不会执行,相当于就直接return了 } }
好了,现在我们就得到一个基本的链表了;
那么接下来就是对链表的操作了,那么一起来看看对链表都有那些操作吧!
// 在在链表头插入元素 public void addHead(int val) { } //在链表的指定下标中插入元素 public void addIndex(int index, int val) { } // 删除头节点 public void deleteHead() { } //删除指定下标的元素 public void deleteIndex(int index) { } // 删除链表中所有数值是key的元素 public void deleteKey(int key) { } // 判断元素key是否在当前链表中 public boolean contains(int key) { return false; }
三、新增结点
3.1头插
// 在在链表头插入元素 public void addHead(int val) { ListNode node = new ListNode(val); // 新插入的结点node node.next = head; // 直接将该结点node变成新的头结点 head = node; }
3.2 指定下标插入
/** * 在链表的指定下标中插入元素 * @param index 所指定的下标 * @param val 元素值 */ public void addIndex(int index, int val) { if (index < 0 || index > getSize()) { // 注意这里index == getSize也是可以的,此时相当于是在链表的结尾新增一个元素 System.out.println("index下标不合法"); return; } ListNode node = new ListNode(val); // 要新增的那个结点node if (index == 0) { // 当新增的是头结点的时候 addHead(val); return; } ListNode cur = head; for (int i = 0; i < index - 1; ++i) { // 这种情况包含了新增尾结点的时候 cur = cur.next; // 通过循环,让cur指向—>新增指定下标所对应的元素的前一个元素 } node.next = cur.next; // 把该结点插入链表,且放到指定下标中,从后往前走,先将node结点指向下一个结点 cur.next = node; }举例说明:
比如现在我们想在2下标插入我们新建的结点node,那么我们首先要找到要插入的结点的前一个结点->也就是下标为1的那个结点
然后呢🤔
你可能会说:这不就简单了!直接下标为1的结点的next储存新建的结点node的地址:0x7777,然后新建的node结点再指向我们原来下标为2的结点不就行了吗?
这样真的可以吗?一起来看看吧!
上面所说的就是这样的伪代码:
下标为1的结点.next = node; node.next = 下标为2的结点; 但这有一个问题: 首先在一开始的链表中存在这样的关系: 下标为1的结点.next = 下标为2的结点 那么就在上面的伪代码中node.next = 下标为2的结点; 就相等于是:node.next = 下标为1的结点.next; 但问题是此时的:下标为1的结点.next = node; 即node.next = node;这合理吗?不合理,所以我们要从后向前走 就是: node.next = 下标为2的结点; 下标为1的结点.next = node;所以说上面我们的那个想法是不合适的;

正确想法:

四、删除结点
4.1 头删
// 删除头节点 public void deleteHead() { isEmpty(); // 检查一下链表是否为空,为空的化就会抛出异常来终止程序 // 如果head头节点不是链表的最后一个元素时,直接将head的下一个结点变成新的头结点,原来的head头结点就被系统自动回收了 if (head.next != null) { this.head = this.head.next; } else this.head = null; // 当head结点是链表的最后一个元素时 }
4.2 指定下标的删除
在链表中,想要删除一个结点其实就是让该结点从链表中分离出来(没有其他任何的结点指向他 )
比如:
我们想删除1下标的结点,只需要找到1下标的前一个结点,也就是0下标。然后将0下标的next域里不再储存1下标的结点地址,而改成储存1下标的下一个结点->2下标的结点地址。这样就相等于1下标的结点被孤立下来了(就相等于是删除了)
/** * 删除指定下标的元素 * @param index 要删除的指定元素下标 */ public void deleteIndex(int index) { isEmpty(); // 检查一下链表是否为空,为空的化就会抛出异常来终止程序 if (index < 0 || index >= getSize()) { // 注意此时index不能等于getSize因为是删除不是新增,下标index最大是getSize - 1 System.out.println("要删除的下标不合法!删除失败!!"); return; // 直接返回 } if (index == 0) { deleteHead(); // 当index等于0时,相当于是删除的是头节点 return; } ListNode cur = head; // 创建一个引用cur去完成循环(头节点是整个链表的灵魂,不能直接使用,避免丢失链表) // 通过循环,让cur指向—>要删除元素的前一个元素 for (int i = 0; i < index - 1; ++i) { // 注意这里不能是i < index; 如果是i < index的话,cur就指向当前要删除的那个元素了 cur = cur.next; } cur.next = cur.next.next; }图片说明:

4.3 删除链表中的指定元素
// 删除链表中所有数值是key的元素 public void deleteKey(int key) { isEmpty(); // 检查一下链表是否为空,为空的化就会抛出异常来终止程序 while (this.head.val == key && head != null) { // 当 head.val == key,相当于删除头节点 deleteHead(); // 因为是删除链表中所有数值是key的元素,所以删除一个后不能直接返回,还要继续遍历 // 处理特殊情况,当链表的的最后一个元素被删除时 if (head == null) { return; // 直接return就好,此时head为空,如果再进行this.head.val == key的判断就会发生空指针异常 } } ListNode cur = head; // 创建一个引用cur去完成链表的遍历(头节点是整个链表的灵魂,不能直接使用,避免丢失链表) while (cur.next != null) { if (cur.next.val == key) { cur.next = cur.next.next; // 包含了删除尾结点的情况 } else { cur = cur.next; // cur引用指向下一个结点,以此来完成遍历链表 } }
五、单链表查找:
/** * 判断元素key是否在当前链表中 * @param key * @return 在链表中返回true,不在返回false */ public boolean contains(int key) { ListNode cur = this.head; while (cur != null) { if (cur.val == key) { return true; } else { cur = cur.next; } } return false; }
六、附录
总代码
//shift+回车,光标在任意位置都能换到下一行 // crl + z返回上一步,如果自己不小心误删了代码可以用这个快捷键找回刚才误删的代码 //import java.util.List; import java.util.Scanner; /** * 实现单链表的代码 */ //变量名,方法名首字母小写,如果名称由多个单词组成,除首字母外的每个单词的首字母都要大写. // 包名小写 public class MyLinkList { ListNode head = null; // 声明链表中的头结点 //创建单链表结构,将链表的每一个结点都定义成一个内部类 public class ListNode { public int val; // 该结点的数值域,储存该结点的数值 public ListNode next; // 该结点的next域,储存的是下一个结点的地址,两个结点间正是通过next域产生关联 public ListNode(int val) { // 构造方法,给新生成的结点赋值,同时next默认为null this.val = val; } } // 链表初始化 public ListNode listInit() { Scanner in = new Scanner(System.in); System.out.print("请输入你要构建的链表的初始长度:"); int n = in.nextInt(); System.out.print("请输入链表第1个元素的值:"); int firstVal = in.nextInt(); // this.head = new ListNode(firstVal); // 创建链表的第一个结点,将我们链表的头结点指向链表的第一个结点 ListNode cur = head; // 创建一个引用cur去完成链表的初始化(头节点是整个链表的灵魂,不能直接使用,避免丢失链表) for (int i = 1; i < n; i++) { System.out.print("请输入链表第" + (i + 1) + "个元素的值:"); int val = in.nextInt(); ListNode node = new ListNode(val); cur.next = node; cur = node; } return this.head; // 返回该链表的头结点 } // 打印链表 public void linkedListPrint() { ListNode cur = head; // 创建一个引用cur去完成链表的遍历打印(头节点是整个链表的灵魂,不能直接使用,避免丢失链表) while (cur != null) { System.out.print(cur.val + " "); // cur.val表示的就是当前结点的数值 cur = cur.next; // 打印完了当前结点,cur继续指向下一个结点,完成对下一个结点的打印 } System.out.println(); } // 获取链表长度 public int getSize() { int count = 0; ListNode cur = this.head; while (cur != null) { count++; cur = cur.next; } return count; } /** * 判断该链表是否为空 * 为空就抛出异常,终止程序 */ private void isEmpty() { // 判断链表是否为空,只是该类中使用,所有 if (head == null) { System.out.println("该链表为空!!!"); throw new NullPointerException(); // 如果抛出的是 RunTimeException 或者 RunTimeException 的子类,则可以不用处理,直接交给JVM来处理 //异常一旦抛出,其后的代码就不会执行,相当于就直接return了 } } // 在在链表头插入元素 public void addHead(int val) { ListNode node = new ListNode(val); node.next = head; head = node; } /** * 在链表的指定下标中插入元素 * @param index 所指定的下标 * @param val 元素值 */ public void addIndex(int index, int val) { if (index < 0 || index > getSize()) { // 注意这里index == getSize也是可以的,此时相当于是在链表的结尾新增一个元素 System.out.println("index下标不合法"); return; } ListNode node = new ListNode(val); // 要新增的那个结点node if (index == 0) { // 当新增的是头结点的时候 addHead(val); return; } ListNode cur = head; for (int i = 0; i < index - 1; ++i) { // 这种情况包含了新增尾结点的时候 cur = cur.next; // 通过循环,让cur指向—>新增指定下标所对应的元素的前一个元素 } node.next = cur.next; // 把该结点插入链表,且放到指定下标中,从后往前走,先将node结点指向下一个结点 cur.next = node; } // 删除头节点 public void deleteHead() { isEmpty(); // 检查一下链表是否为空,为空的化就会抛出异常来终止程序 if (head.next != null) { this.head = this.head.next; } else this.head = null; // 当head结点是链表的最后一个元素时 } /** * 删除指定下标的元素 * @param index 要删除的指定元素下标 */ public void deleteIndex(int index) { isEmpty(); // 检查一下链表是否为空,为空的化就会抛出异常来终止程序 if (index < 0 || index >= getSize()) { // 注意此时index不能等于getSize因为是删除不是新增,下标index最大是getSize - 1 System.out.println("要删除的下标不合法!删除失败!!"); return; // 直接返回 } if (index == 0) { deleteHead(); // 当index等于0时,相当于是删除的是头节点 return; } ListNode cur = head; // 创建一个引用cur去完成循环(头节点是整个链表的灵魂,不能直接使用,避免丢失链表) // 通过循环,让cur指向—>要删除元素的前一个元素 for (int i = 0; i < index - 1; ++i) { // 注意这里不能是i < index; 如果是i < index的话,cur就指向当前要删除的那个元素了 cur = cur.next; } cur.next = cur.next.next; } // 删除链表中所有数值是key的元素 public void deleteKey(int key) { isEmpty(); // 检查一下链表是否为空,为空的化就会抛出异常来终止程序 while (this.head.val == key && head != null) { // 当 head.val == key,相当于删除头节点 deleteHead(); // 因为是删除链表中所有数值是key的元素,所以删除一个后不能直接返回,还要继续遍历 // 处理特殊情况,当链表的的最后一个元素被删除时 if (head == null) { return; // 直接return就好,此时head为空,如果再进行this.head.val == key的判断就会发生空指针异常 } } ListNode cur = head; // 创建一个引用cur去完成链表的遍历(头节点是整个链表的灵魂,不能直接使用,避免丢失链表) while (cur.next != null) { if (cur.next.val == key) { cur.next = cur.next.next; // 包含了删除尾结点的情况 } else { cur = cur.next; // cur引用指向下一个结点,以此来完成遍历链表 } } } /** * 判断元素key是否在当前链表中 * @param key * @return 在链表中返回true,不在返回false */ public boolean contains(int key) { ListNode cur = this.head; while (cur != null) { if (cur.val == key) { return true; } else { cur = cur.next; } } return false; } }
测试代码
/** * 对单链表进行测试的代码 */ public class LinkListTest { public static void main(String[] args) { MyLinkList myLinkList = new MyLinkList(); // 实例化一个链表对象 // 链表的初始化 myLinkList.listInit(); System.out.print("初始化链表后,链表的第一次打印:"); myLinkList.linkedListPrint(); System.out.println("==============="); myLinkList.addHead(1111); System.out.print("头插结点1111后,链表的第二次打印:"); myLinkList.linkedListPrint(); myLinkList.addIndex(2, 2222); System.out.print("再指定下标2出插入新结点2222后,链表的第三次打印:"); myLinkList.linkedListPrint(); System.out.println("================"); myLinkList.deleteIndex(2); System.out.print("删除指定下标2的结点2222后,链表的第四次打印:"); myLinkList.linkedListPrint(); myLinkList.deleteHead(); System.out.print("删除头节点后,链表的第五次打印:"); myLinkList.linkedListPrint(); myLinkList.deleteKey(2); System.out.print("删除链表中所有值是2的结点后,链表的第六次打印:"); myLinkList.linkedListPrint(); System.out.print("此时的链表长度为:"); System.out.println(myLinkList.getSize()); } }
测试结果:

总结
本节内容我们学习了有关链表中有关的各种操作,如插入删除等等;让我们堆链表有了更深刻的学习和认识;文章来源:https://www.toymoban.com/news/detail-414007.html
 文章来源地址https://www.toymoban.com/news/detail-414007.html
文章来源地址https://www.toymoban.com/news/detail-414007.html
到了这里,关于【数据结构初阶】第四节.链表详讲的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!