读取文件每一行内容
while read line
do
echo $line
done < a.txt
文件是否存在
if [ ! -d "/data/" ];then
mkdir /data
else
echo "文件夹已经存在"
fi
说明
-e 判断对象是否存在
-d 判断对象是否存在,并且为目录
-f 判断对象是否存在,并且为常规文件
-L 判断对象是否存在,并且为符号链接
-h 判断对象是否存在,并且为软链接
-s 判断对象是否存在,并且长度不为0
-r 判断对象是否存在,并且可读
-w 判断对象是否存在,并且可写
-x 判断对象是否存在,并且可执行
-O 判断对象是否存在,并且属于当前用户
-G 判断对象是否存在,并且属于当前用户组
-nt 判断file1是否比file2新 [ "/data/file1" -nt "/data/file2" ]
-ot 判断file1是否比file2旧 [ "/data/file1" -ot "/data/file2" ]
数组定义和循环取值
arr=(a b c)
echo ${arr[0]} #获取第一个元素的值
echo ${arr[-1]} #获取最后一个元素的值
# 获取所有元素的值
echo ${arr[*]}
echo ${arr[@]}
# 统计数组的长度
echo ${#arr[*]}
# 打印数组的下标值
echo ${!arr[@]}
# 循环 方式一 直接取值
for i in ${arr[@]}
do
echo $i
done
# 循环 方式二 下标取值
for i in ${!arr[@]}
do
echo ${arr[i]}
done
# 循环 方式三
for((i=0;i<${#arr[@]};i++))
do
echo ${arra[i]}
done
变量循环
for i in $(seq 1 $1)
do
echo $i
done
for (( i = 1; i < $line; i++ ))
do
echo $i
done
流程控制语句:case
case $1 in
"start")
op start $2
;;
"stop")
op stop $2
;;
"status")
op status $2
;;
*)
echo "Usage: service $2 start|stop|status"
;;
esac
判断数值相等/大于/小于
# 整数比较
-eq 等于,如:if ["$a" -eq "$b" ]
-ne 不等于,如:if ["$a" -ne "$b" ]
-gt 大于,如:if ["$a" -gt "$b" ]
-ge 大于等于,如:if ["$a" -ge "$b" ]
-lt 小于,如:if ["$a" -lt "$b" ]
-le 小于等于,如:if ["$a" -le "$b" ]
< 小于(需要双括号),如:(("$a" < "$b"))
<= 小于等于(需要双括号),如:(("$a" <= "$b"))
> 大于(需要双括号),如:(("$a" > "$b"))
>= 大于等于(需要双括号),如:(("$a" >= "$b"))
判断字符串相等
if [ "$test"x = "test"x ]; then
# = 等于,如:if [ "$a" = "$b" ]
# == 等于,如:if [ "$a" == "$b" ],与 = 等价
这里的关键有几点:
- 使用单个等号
- 注意到等号两边各有一个空格:这是unix shell的要求
- 注意到"$test"x最后的x,这是特意安排的,因为当$test为空的时候,上面的表达式就变成了x = testx,显然是不相等的。而如果没有这个x,表达式就会报错:[: =: unary operator expected
awk求和、平均、最大、最小
# 科学计数法打印
bin/hdfs dfs -du /warehouse/hive/ | awk '{sum+=$1} END {print "Sum = ", sum/1024/1024}'
# 非科学计数法打印
bin/hdfs dfs -du /warehouse/hive/ | awk '{sum+=$1} END {printf("%d\n", sum/1024/1024)}'
1、求和
awk '{sum+=$1} END {print "Sum = ", sum}' number.txt
2、求平均
awk '{sum+=$1} END {print "Average = ", sum/NR}' number.txt
3、求最大值
awk 'BEGIN {max = 0} {if ($+0 > max+0) max=$1} END {print "Max=",max}' number.txt
4、求最小值(min的初始值设置一个超大数即可)
awk 'BEGIN {min = 1999999} {if ($1<min) min=$1 fi} END {print "Min=", min}' number.txt
5. 输出排序最大值所在行内容
如下,以第一列排序
cat num.txt
858 mail
1858 nginx
8502 tomcat
1145 zabbix
3457 mongodb
1356 redis
974 Mysql
记录最大值的时候,同时记录一下当前行,后面输出这个变量即可 此处的的content可随意定义
awk 'BEGIN {max = 0} {if ($1+0 > max+0) {max=$1 ;content=$0} } END {print content}' num.txt
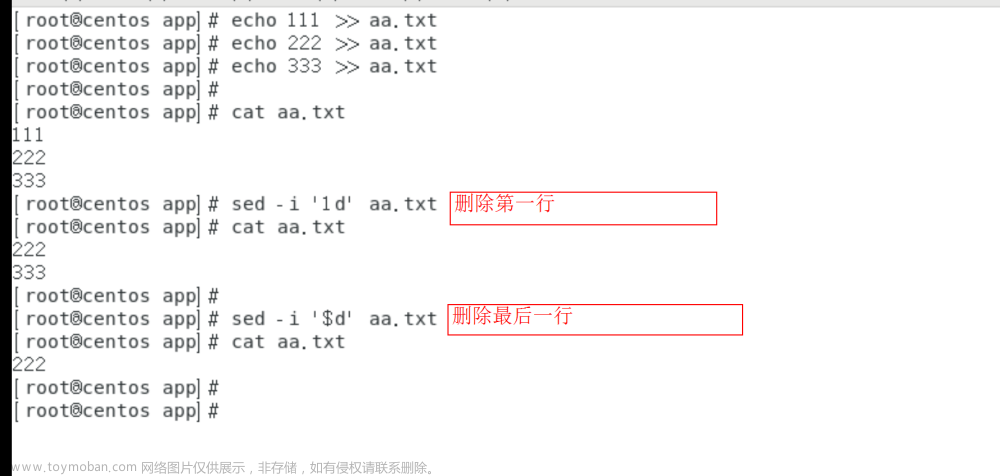
sed用法
# 取 1到3 行的内容 重定向到 b.txt
sed -n "1,3p" a.txt > b.txt
# 替换
sed -i "s/abc/def/g" ./a.txt
如果我们使用sed命令时,如果出现特殊字符,可能会报错,示例如下:
# /不可以作为界定符,因为会与里面的内容冲突
sed -i 's/flink//etc/g'
# 井号#不可以作为界定符,因为会与里面的内容冲突
sed -i 's#jdbc://127.0.0.1&password=1#aa$username=root#g'
# @不可以作为界定符,因为会与里面的内容冲突
sed -i 's@jdbc://127.0.0.1&password=1@aa$username=root@g'
那该如何解决呢?
我们得看来里面的内容来选择特定的界定符,例如:
里面含有"/",可以选择“#”或“ @”作为界定符;
里面含有“#”,可以选择“@”或“/”作为界定符;
里面含有“@”,可以选择“/”或“#”作为界定符。
那么如果都有以上的内容呢?只能在被替换文本中使用转义符号 “\”了,如:文章来源:https://www.toymoban.com/news/detail-414083.html
sed -i 's/oracle/\/etc\/oracle/g'
expr
expr支持普通的算术操作,算式表达式优先级低于字符串表达式,高于逻辑关系表达式。文章来源地址https://www.toymoban.com/news/detail-414083.html
- + - 加减运算。两端参数会转换为整数,如果转换失败则报错;
- * / % 乘,除,取模运算。两端参数会转换整数,如果转换失败则报错;
- () 可以用来表示优先级,但需要用反斜杠转义。
a=3
b=4
echo `expr $a + $b` #输出7
echo `expr $a - $b` #输出-1
echo `expr $a \* $b` #输出12,*需要转义
echo `expr $a / $b` #输出0,整除
echo `expr $a % $b` #输出3
echo `expr \($a + 1\)\*\($b+1\)` #输出20,值为(a+1)*(b+1)
bc计算器
echo '6.5/2.7' | bc
2
echo 'scale=5;6.5/2.7' | bc #其中scale是控制小数点位数
2.40740
echo "5+3" | bc
8
echo "(2+6)*3" | bc
24
#关系运算符
||, &&, !, =, ==
#基本数学运算
+, -, *, /, %, ^,
#自增,自减
++, --
#逻辑运算符
<, >, <=, >=, !=
length() #用于求表达式的结果长度
length(300)
3
scale() #用于获取表达式小数点后位数
scale(3.14)
2
sqrt() #求平方根
scale=6;sqrt(21)
4.582575
#如果使用了bc -l,可以将预置的数学运算导入
s(x) #sin函数,x为弧度
s(3.14)
.00159265291648695254
c(x) #cos函数
c(0)
1.00000000000000000000
a(x) #arctang函数
a(sqrt(2)/2)
0.61547970867038734106
l(x) #自然对数
l(10)
2.30258509299404568401
e(x) #自然数为底的指数函数
e(2)
7.38905609893065022723
j(n,x) #Basel函数,n阶
j(1,3)
0.33905895852593645892
到了这里,关于【运维】运维常用命令的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!