性能优化
性能优化通常分为两个阶段:性能分析、性能优化
- 性能分析:查找性能瓶颈、热点代码,分析引发性能问题的原因。
- 性能优化:基于性能分析,进行性能优化。包括:算法优化(空间复杂度和时间复杂度的权衡)和代码优化(提高执行速度、减少内存占用)。
perf 概述
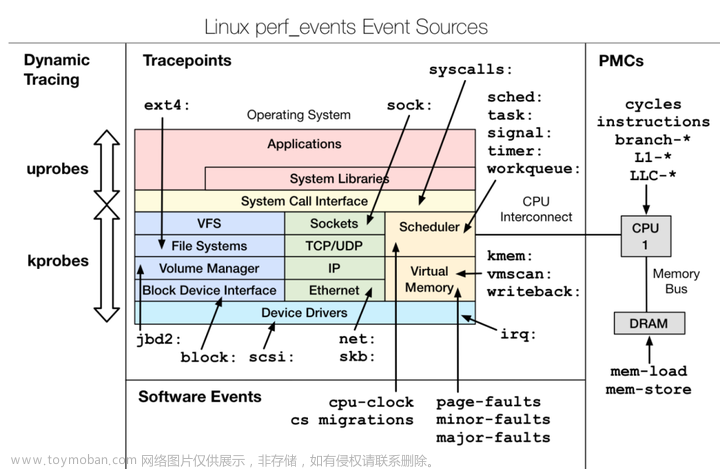
perf 是 Linux 下的一款性能分析工具,可以用来分析程序中热点函数的 CPU 占用率,从而定位性能瓶颈。
perf 核心功能由 Performance counters(性能计数器) 子系统实现,它提供一个性能分析框架,比如硬件(CPU、PMU(Performance Monitoring Unit))功能和软件(软件计数器、tracepoint)功能。
通过 perf,应用程序可以利用 PMU、tracepoint 和内核中的计数器来进行性能统计。
perf 可以对程序进行函数级和指令级的采样,从而了解程序的性能瓶颈在哪里。
基本原理:在采样时间内,每隔一个固定采样周期,在 CPU 上产生一个中断,看当前是哪个进程、哪个函数在运行,然后就给对应的进程和函数加一个统计值,这样就可以估算出这段采样时间内,CPU 有多少时间花在某个进程和某个函数上。
perf 工具功能非常多,今天我们就来学习最常使用的两个命令:perf record 和 perf report。其中,一个用来统计,一个用来展示。
示例
使用下面这个示例程序,来学习 perf record/report 命令的使用。
perftest.c
#include <stdio.h>
#include <math.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
void for_loop()
{
int i, j;
int x;
for (i = 0; i < 1000; i++) {
for (j = 0; j < 10000; j++) {
x = sin(i) + cos(j);
}
}
}
void loop_samll()
{
int i;
for (i = 0; i < 10; i++) {
for_loop();
}
}
void loop_big()
{
int i;
for (i = 0; i < 100; i++) {
for_loop();
}
}
int main(int argc, char *argv[])
{
printf("pid = %d\n", getpid());
loop_big();
loop_samll();
return EXIT_SUCCESS;
}
$ gcc -o perftest.out perftest.c -lm
$ ./perftest.out
pid = 826526
perf record
$ sudo perf record -p 826526 -a -g -F 99 -- sleep 10
Warning:
PID/TID switch overriding SYSTEM
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.082 MB perf.data (991 samples) ]
-p:分析指定进程
-a:对所有 CPU 进行采样
-g:启用调用追溯功能
-F:指定采样频率
-- sleep:采集时长
执行这个命令后,会在当前目录下产生一个 perf.data 文件,接下来就可以使用 perf report 命令来分析这份采样记录了。
perf report
$ sudo perf report

通过 perf report 命令可以展示采样记录,大概介绍下面板参数
- Samples:采样个数
- Event count:系统总共发生的事件数
- Symbol:函数名,其中 [.] 表示用户空间函数,[k] 表示内核函数
- Shared Objec:函数所在的共享库或所在的程序
- Command:进程名
- Self:该函数的 CPU 使用率
- Children:该函数的子函数的 CPU 使用率
那么,通过示例的展示面板,我们能得到的信息如下:
- 这次采样,是对 perftest.out 这个进程进行采样
- 总共采集到了 991 个事件(符合 -F 99 -- sleep 10,即,一秒钟采样 99 次,采样 10 秒钟)
- 第一行:__libc_start_main 函数,处于用户空间,处于共享库 libc-2.31.so 中,CPU 使用率为 0,其子函数的 CPU 使用率为 47.63%。(因为 __libc_start_main 只调用一次,实际使用 CPU 的都是其子函数)
- 第二行:main 函数同 __libc_start_main
- 第三行:loop_big 函数同 __libc_start_main
- 第四行:__sin_avx 函数,自身 CPU 使用率为 40.36%,子函数 CPU 使用率为 40.36%,说明其没有子函数。
- 第五行:__cos_avx 函数,CPU 使用率为 38.65%
- 第六行:for_loop 函数,CPU 使用率 20.99%
通过以上分析,可以知道 CPU 大部分时间都花在执行 sin() 和 cos() 这两个函数上,和示例代码吻合。文章来源:https://www.toymoban.com/news/detail-414099.html
以上分析中,有些参数还没理解透彻,后面还会继续对 perf 工具进行学习,逐步增强吧。文章来源地址https://www.toymoban.com/news/detail-414099.html
到了这里,关于perf record/report的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!