参考的demo:GitHub - ddiu8081/chatgpt-demo: A demo repo based on OpenAI API.
扭曲调教:
 openai提供的chat接口(https://api.openai.com/v1/chat/completions)由于其模型很大(什么1750亿个参数啥的),单次http请求很难完成处理,一些常用的做法是采取流返回的方式,一个字一个字往外蹦,然后一点一点渲染,例如demo里的代码:
openai提供的chat接口(https://api.openai.com/v1/chat/completions)由于其模型很大(什么1750亿个参数啥的),单次http请求很难完成处理,一些常用的做法是采取流返回的方式,一个字一个字往外蹦,然后一点一点渲染,例如demo里的代码:

export const parseOpenAIStream = (rawResponse: Response) => {
const encoder = new TextEncoder()
const decoder = new TextDecoder()
if (!rawResponse.ok) {
return new Response(rawResponse.body, {
status: rawResponse.status,
statusText: rawResponse.statusText,
})
}
const stream = new ReadableStream({
async start(controller) {
const streamParser = (event: ParsedEvent | ReconnectInterval) => {
if (event.type === 'event') {
const data = event.data
if (data === '[DONE]') {
controller.close()
return
}
try {
// response = {
// id: 'chatcmpl-6pULPSegWhFgi0XQ1DtgA3zTa1WR6',
// object: 'chat.completion.chunk',
// created: 1677729391,
// model: 'gpt-3.5-turbo-0301',
// choices: [
// { delta: { content: '你' }, index: 0, finish_reason: null }
// ],
// }
const json = JSON.parse(data)
const text = json.choices[0].delta?.content || ''
const queue = encoder.encode(text)
controller.enqueue(queue)
} catch (e) {
controller.error(e)
}
}
}
const parser = createParser(streamParser)
for await (const chunk of rawResponse.body as any)
parser.feed(decoder.decode(chunk))
},
})
return new Response(stream)
}类似于这样的处理方式。
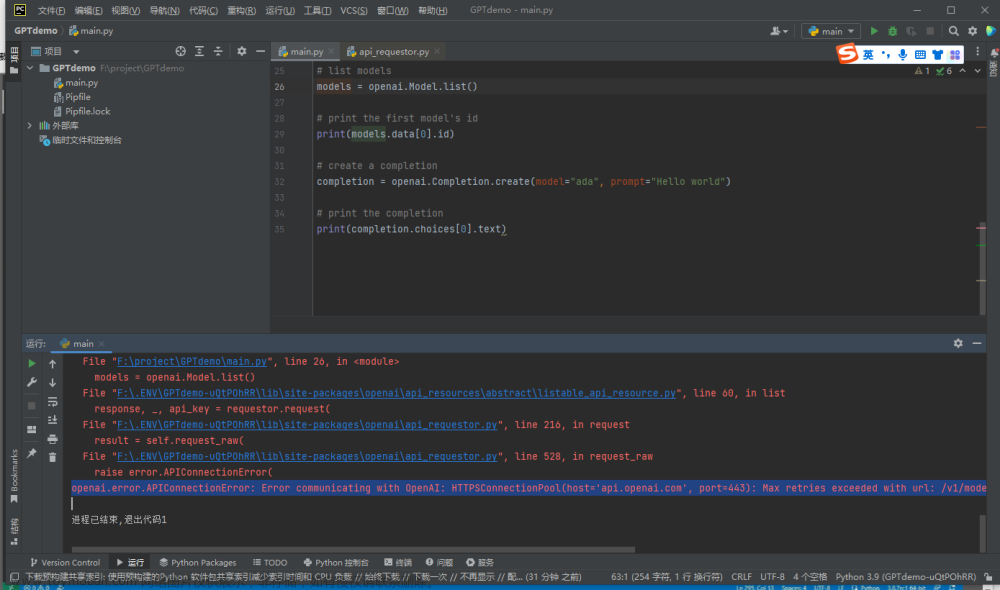
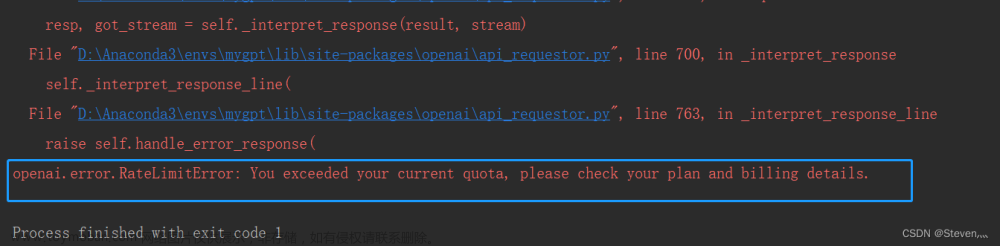
但流传输不一定适用于所有的业务,若将stream改成false,那么接口响应多半会超时。
因此需要一些优化的策略:
一、降智
选用低能一些的模型,不过我尝试了gpt3的模型,一概不说人话

而/v1/completions的接口里只有 text-davinci-003还可以接受

说明一下/v1/completions和v1/chat/completions的区别,/v1/chat/completions是传一个数组messages来完成上下文关联,而/v1/completions传的是一个字符串prompt参数,不过依然可以通过追加的方式,使其回答具有上下文关联性。
不过!! text-davinci-003费用是turbo的10倍!!!!!!!
这是决对不能接受的!!!

二、降低temperature参数

这个会有轻量的影响,如果你并不需要每次相同的问题都要回答不同的答案,那么可以降低此值,甚至可以降为0
三、优化返回长度
这个会影响最大,亲测最有效,在问题前面追加回答设置,例如,回答不要超过100字,请简洁的回答下列问题等。会最大程度的降低返回时间,因为接口是按调用词数和返回词数计费的(ChatGPT(GPT3.5)官方API模型名称为“gpt-3.5-turbo”和“gpt-3.5-turbo-0301”。API调用价格比GPT text-davinci-003模型便宜10倍。调用费用为0.002美元/1000tokens,折合下来差不多0.1元4000~5000字。这个字数包括问题和返回结果字数。),所以chatgpt保持着能多bb尽量多bb的原则,少让他多bb点还可以省钱。

 文章来源:https://www.toymoban.com/news/detail-414791.html
文章来源:https://www.toymoban.com/news/detail-414791.html
注意,参数里的max_tokens没必要设置,因为他只会无脑切割, 如果设置低了超过原本的输出答案,回答会不完整。文章来源地址https://www.toymoban.com/news/detail-414791.html
到了这里,关于openAi ChatGPT调用性能优化的一些小妙招的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!