文章来源地址https://www.toymoban.com/news/detail-414889.html
文章来源:https://www.toymoban.com/news/detail-414889.html
到了这里,关于Spark大数据处理讲课笔记2.2 搭建Spark开发环境的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
这篇具有很好参考价值的文章主要介绍了Spark大数据处理讲课笔记2.2 搭建Spark开发环境。希望对大家有所帮助。如果存在错误或未考虑完全的地方,请大家不吝赐教,您也可以点击"举报违法"按钮提交疑问。
文章来源地址https://www.toymoban.com/news/detail-414889.html
文章来源:https://www.toymoban.com/news/detail-414889.html
到了这里,关于Spark大数据处理讲课笔记2.2 搭建Spark开发环境的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处: 如若内容造成侵权/违法违规/事实不符,请点击违法举报进行投诉反馈,一经查实,立即删除!

理解RDD持久化的必要性 了解RDD的存储级别 学会如何查看RDD缓存 Spark中的RDD是懒加载的,只有当遇到行动算子时才会从头计算所有RDD,而且当同一个RDD被多次使用时,每次都需要重新计算一遍,这样会严重增加消耗。为了避免重复计算同一个RDD,可以将RDD进行持久化。 Spark中
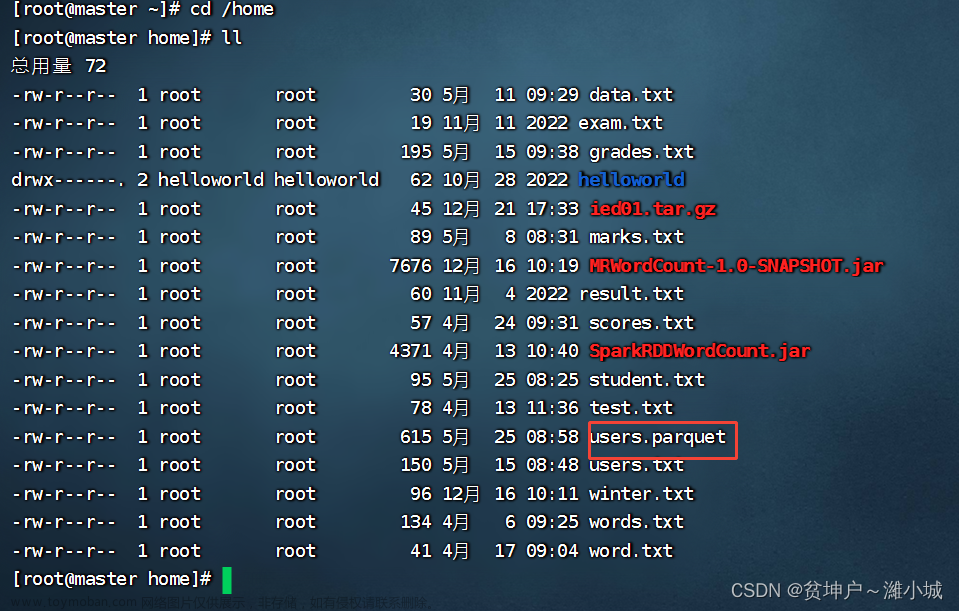
目录 零、本讲学习目标 一、基本操作 二、默认数据源 (一)默认数据源Parquet (二)案例演示读取Parquet文件 1、在Spark Shell中演示 2、通过Scala程序演示 三、手动指定数据源 (一)format()与option()方法概述 (二)案例演示读取不同数据源 1、读取房源csv文件 2、读取json,保

项目开始,首先要进行数据准备和数据预处理。 数据准备的核心是找到这些数据,观察数据的问题。 数据预处理就是去掉脏数据。 缺失值的处理,格式转换等。 延伸学习: 在人工智能(AI)的众多工作流程中,数据准备与预处理占据着举足轻重的地位。这两个步骤不仅影响

该文章主要为完成实训任务,详细实现过程及结果见【http://t.csdn.cn/0qE1L】 从Scala官网下载Scala2.12.15 - https://www.scala-lang.org/download/2.12.15.html 安装在默认位置 安装完毕 在命令行窗口查看Scala版本(必须要配置环境变量) 启动HDFS服务 启动Spark集群 在master虚拟机上创建单词文件

熟悉常用的Spark操作。 1.熟悉Spark Shell的使用; 2.熟悉常用的Spark RDD API、Spark SQL API和Spark DataFrames API。 操作系统:Linux Spark版本: 1.6 Hadoop版本: 3.3.0 JDK版本:1.8 使用Spark shell完成如下习题: a)读取Spark安装目录下的文件README.md(/usr/local/spark/README.md); b)统计包含“Spark”的单词
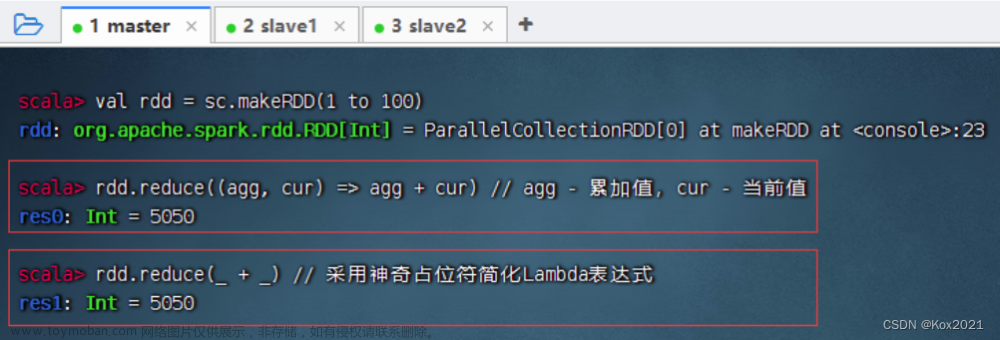
衔接上文:http://t.csdn.cn/Z0Cfj 功能: reduce()算子按照传入的函数进行归约计算 案例: 计算1 + 2 + 3 + …+100的值 计算1 × 2 × 3 × 4 × 5 × 6 的值(阶乘 - 累乘) 计算1 2 + 2 2 + 3 2 + 4 2 + 5**2的值(先映射,后归约) 功能: collect()算子向Driver以数组形式返回数据集的所有元素。通常对
文章目录 一、准备工作 1.1 准备文件 1.1.1 准备本地系统文件 在/home目录里创建test.txt 单词用空格分隔 1.1.2 启动HDFS服务 执行命令:start-dfs.sh 1.1.3 上传文件到HDFS 将test.txt上传到HDFS的/park目录里 查看文件内容 1.2 启动Spark Shell 1.2.1 启动Spark服务 执行命令:start-all.sh 1.2.2 启动Sp

目录 二、数据描述 1.描述数据中心趋势 1.1平均值和截断均值 1.2加权平均值 1.3中位数(Median)和众数(Mode) 2.描述数据的分散程度 2.1箱线图 2.2方差和标准差 2.3正态分布 3.数据清洗 3.1数据缺失的处理 3.2数据清洗 描述数据的方法,包括描述数据中心趋势的方法如 均值、中位
一、Spark开发环境准备工作 由于Spark仅仅是一种计算框架,不负责数据的存储和管理,因此,通常都会将Spark和Hadoop进行统一部署,由Hadoop中的HDFS、HBase等组件负责数据的存储管理,Spark负责数据计算。 安装Spark集群前,需要安装Hadoop环境 软件 版本 Linux系统 CentOS7.9版本 Hadoo



